GPU虚拟化
引言
现有如下环境(注意相关配置:只有一个k8s节点,且该节点上只有一张GPU卡):
// k8s版本
$ kubectl version
Client Version: version.Info{Major:"1", Minor:"22", GitVersion:"v1.22.7", GitCommit:"b56e432f2191419647a6a13b9f5867801850f969", GitTreeState:"clean", BuildDate:"2022-02-16T11:50:27Z", GoVersion:"go1.16.14", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"22", GitVersion:"v1.22.7", GitCommit:"b56e432f2191419647a6a13b9f5867801850f969", GitTreeState:"clean", BuildDate:"2022-02-16T11:43:55Z", GoVersion:"go1.16.14", Compiler:"gc", Platform:"linux/amd64"}// k8s节点信息
$ kubectl get node
NAME STATUS ROLES AGE VERSION
desktop-72rd6ov Ready control-plane,master 419d v1.22.7
$ kubectl get node desktop-72rd6ov -oyaml | grep nvidia.com -A 1 -B 6allocatable:cpu: "16"ephemeral-storage: "972991057538"hugepages-1Gi: "0"hugepages-2Mi: "0"memory: 16142536Kinvidia.com/gpu: "1"pods: "110"capacity:cpu: "16"ephemeral-storage: 1055762868Kihugepages-1Gi: "0"hugepages-2Mi: "0"memory: 16244936Kinvidia.com/gpu: "1"pods: "110"// nvidia k8s-device-plugin版本
// nvidia k8s-device-plugin使用默认配置运行
root@nvidia-device-plugin-daemonset-wtqrg:/# nvidia-device-plugin --version
NVIDIA Device Plugin version 42a0fa92
commit: 42a0fa92ce166592ab5702a1143ddecd891c8e5e// nvidia-container-toolkit版本
$ nvidia-container-toolkit --version
NVIDIA Container Runtime Hook version 1.17.4
commit: 9b69590c7428470a72f2ae05f826412976af1395// nvidia GPU及driver信息
$ nvidia-smi
Mon Jun 2 10:51:49 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 560.35.02 Driver Version: 560.94 CUDA Version: 12.6 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4060 Ti On | 00000000:01:00.0 On | N/A |
| 0% 42C P8 8W / 165W | 690MiB / 16380MiB | 3% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------++-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 25 G /Xwayland N/A |
+-----------------------------------------------------------------------------------------+// cuda版本
$ nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2024 NVIDIA Corporation
Built on Tue_Oct_29_23:50:19_PDT_2024
Cuda compilation tools, release 12.6, V12.6.85
Build cuda_12.6.r12.6/compiler.35059454_0
在上述单节点的k8s环境中,我先用如下配置了使用GPU的yaml起一个pod:
# nginx-pod.yaml
apiVersion: v1
kind: Pod
metadata:name: gpu-pod-1
spec:restartPolicy: Nevercontainers:- name: nginximage: nginx:latestimagePullPolicy: IfNotPresentresources:limits:nvidia.com/gpu: 1securityContext:capabilities:add: ["SYS_ADMIN"]tolerations:- key: nvidia.com/gpuoperator: Existseffect: NoSchedule- effect: NoSchedulekey: node-role.kubernetes.io/masteroperator: Exists
可以看到pod正常运行:
$ kubectl apply -f nginx-pod.yaml
pod/gpu-pod-1 created
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
gpu-pod-1 1/1 Running 0 64s 10.244.0.221 desktop-72rd6ov <none> <none>
$ kubectl exec -ti gpu-pod-1 -- bash
root@gpu-pod-1:/# nvidia-smi --version
NVIDIA-SMI version : 560.35.02
NVML version : 560.35
DRIVER version : 560.94
CUDA Version : 12.6
如果再用上述yaml起一个gpu-pod-2,会发现pod一直Pending,因为节点上已经没有剩余可用的GPU资源可用:
$ kubectl apply -f nginx-pod.yaml
pod/gpu-pod-2 created
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
gpu-pod-1 1/1 Running 0 13m 10.244.0.221 desktop-72rd6ov <none> <none>
gpu-pod-2 0/1 Pending 0 4m20s <none> <none> <none> <none>
但是试想一种场景:我有多个任务需要使用GPU资源计算,但是GPU资源数量明显少于任务数量,而且某些任务运行过程中也并不是一直会使用GPU资源。为了充分利用GPU资源,我们希望任务能公用这些GPU资源,这也就引出了本文的主题:GPU虚拟化。
一、GPU虚拟化技术概览
1.1 为什么需要GPU虚拟化?
1.1.1 物理GPU的固有特点
- 资源利用率低下:传统GPU独占模式下,AI推理/轻量计算任务仅占用10%-30%算力,大量资源闲置
- 成本与扩展性瓶颈:企业需为每个用户/应用单独采购GPU硬件(如设计师工作站);云服务商无法通过共享降低租户算力成本
- 多租户隔离缺失:多个任务竞争同一GPU导致性能抖动(如显存溢出影响邻位应用)
1.2 两大核心模式对比
1.2.1 一虚多(1 GPU → N个实例)
本质:单物理GPU分割为多个逻辑虚拟GPU
实现原理:
- 时分复用(Time-Slicing):GPU时间片轮转调度(如每10ms切换任务),代表方案:NVIDIA vGPU、开源GPU-PV,适用场景:图形渲染、轻量计算
- 空间分区(Spatial Partitioning):物理切割GPU计算单元/显存(如NVIDIA MIG),适用场景:AI推理、高隔离性任务
架构示意图:
Physical GPU → Hypervisor层(vGPU Manager)→ 虚拟GPU实例(vGPU1/vGPU2/...) → VM/Container
1.2.2 多虚一(N GPU → 1实例)
本质:聚合多个GPU资源服务单个计算密集型应用
实现原理:
- 设备级聚合:通过NVLink互联多卡(如DGX服务器的8-GPU Cube Mesh)
- 节点级聚合:GPUDirect RDMA跨节点通信(InfiniBand网络)
典型架构:
App (e.g. LLM训练) → 聚合框架 (NCCL/DDP) → GPU Pool (本地多卡/跨节点集群)
1.2.3 关键特性对比表
| 维度 | 一虚多 (1→N) | 多虚一 (N→1) |
|---|---|---|
| 核心目标 | 资源分片共享 | 算力聚合加速 |
| 隔离性 | 中-高(MIG为物理隔离) | 无(所有资源协同工作) |
| 延迟敏感性 | 低(毫秒级调度) | 高(微秒级通信延迟影响显著) |
| 典型硬件 | Tesla T4/vWS, A100 (MIG) | A100/H100 + NVLink Switch |
| 适用场景 | 云游戏、VDI、AI推理 | 大模型训练、科学计算 |
| 代表技术 | NVIDIA vGPU, MIG, GPU-PV | NVLink, NCCL, GPUDirect RDMA |
1.2.4 技术演进里程碑
- 2013:NVIDIA GRID K1首发vGPU技术(针对虚拟桌面)
- 2020:安培架构推出MIG(首个硬件级多实例GPU)
- 2022:Hopper架构支持机密计算vGPU(加密显存保护数据)
- 2023:vGPU 2.0支持动态资源分配(运行时调整vGPU显存/算力)
二、一虚多(1 GPU → N个实例)技术解析
2.1 实现原理
2.1.1 硬件辅助虚拟化(NVIDIA vGPU 技术栈):
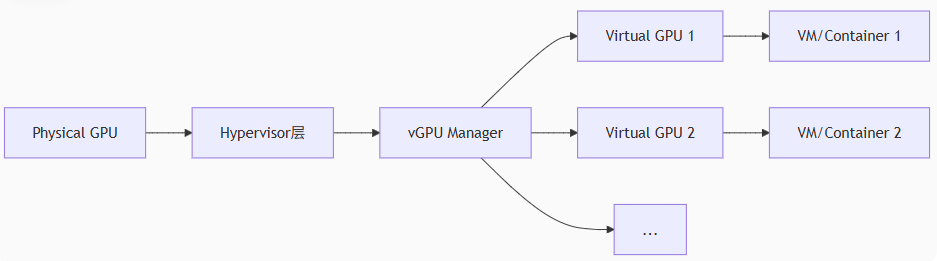
核心组件:
- Hypervisor驱动与调度器:GPU内部的任务队列管理单元(如Ampere架构的GSP调度引擎)
- vGPU Manager:驻留在Hypervisor的驱动层,负责GPU资源切分与调度
- Guest驱动:虚拟机/容器内识别虚拟GPU的标准驱动(与物理驱动兼容)
2.1.2 资源分割的两大范式
| 类型 | 时分复用(Time-Slicing) | 空间分区(MIG) |
|---|---|---|
| 原理 | GPU时间片轮转服务多个任务 | 物理切割GPU为独立计算单元 |
| 隔离级别 | 软件级(易受干扰) | 硬件级(显存/缓存/计算单元隔离) |
| 调度粒度 | 毫秒级(通常10-50ms) | 永久性分区(需重启生效) |
| 代表技术 | NVIDIA vGPU, GPU-PV | NVIDIA MIG(仅安培/霍珀架构) |
| 适用场景 | 图形渲染、轻量级AI推理 | 高SLA要求的AI推理/科学计算 |
2.2 主流方案简介
2.2.1 NVIDIA vGPU/vWS(企业级方案)
架构流程:
GPU硬件分片 → 虚拟GPU(vGPU) → 虚拟机
关键特性:
- Profile配置表(以NVIDIA A100 40GB为例)
| Profile名称 | 显存 | CUDA核心 | 最大实例数 |
|---|---|---|---|
| A100-1B | 1GB | 1/7 | 7 |
| A100-2B | 2GB | 1/7 | 7 |
| A100-3B | 3GB | 1/7 | 4 |
| A100-4B | 4GB | 1/7 | 3 |
| A100-7B | 7GB | 1/7 | 1 |
- 许可证机制:
需连接nvidia-licence-server(默认端口7070)
许可证类型:vWS(图形工作站)、vCS(计算加速)、vPC(基础办公)
2.2.2 NVIDIA MIG(Multi-Instance GPU)(硬件级隔离方案):
物理切割原理:
- 安培架构GPU(如A100)含7个GPC(图形处理集群)
- 每个MIG实例独占:
- 独立计算单元(SMs子集)
- 专用L2缓存切片
- 隔离的显存通道
7种实例规格(A100 40GB):
限制:总实例数≤7,显存总和≤物理显存
| 实例类型 | 算力占比 | 显存 | 适用场景 |
|---|---|---|---|
| 1g.5gb | 1/7 | 5GB | 轻量推理 |
| 1g.10gb | 1/7 | 10GB | 中等模型推理 |
| 2g.20gb | 2/7 | 20GB | 大模型推理 |
| 3g.40gb | 3/7 | 40GB | 训练/高负载推理 |
2.2.3 开源方案:GPU-PV(容器/虚拟机场景轻量虚拟化)(如Kubevirt + vGPU)
实现原理:
- 通过Kubernetes Device Plugin暴露分时GPU
- 无硬件虚拟化支持,依赖CUDA MPS(多进程服务)
2.3 性能隔离与QoS保障
| 资源类型 | 隔离方案 | 技术实现 |
|---|---|---|
| 计算单元 | vGPU:时间片轮转 MIG:物理隔离 | GPU调度器(GSP) 硬件分区 |
| 显存 | 静态分区 | 每个vGPU/MIG实例固定显存配额 |
| 显存带宽 | 令牌桶算法限流 | NVIDIA Frame Rate Limiter (FRL) |
| PCIe带宽 | 权重分配 | SR-IOV VF流量控制 |
三、多虚一(N GPU → 1实例)技术概览
3.1 核心应用场景
| 场景 | 需求特征 | 典型案例 |
|---|---|---|
| 大语言模型训练 | 千亿参数加载/显存需求>80GB | GPT-4训练需128张H100 GPU集群 |
| 科学计算仿真 | 双精度浮点性能>100 TFLOPS | CFD流体模拟(10亿网格粒子) |
| 实时渲染农场 | 4K@120fps实时光线追踪 | 电影级场景渲染(《阿凡达2》) |
| 基因组学分析 | TB级数据并行处理 | 癌症基因组序列比对 |
3.2 核心实现方案
3.2.1 硬件互联层:打破通信瓶颈
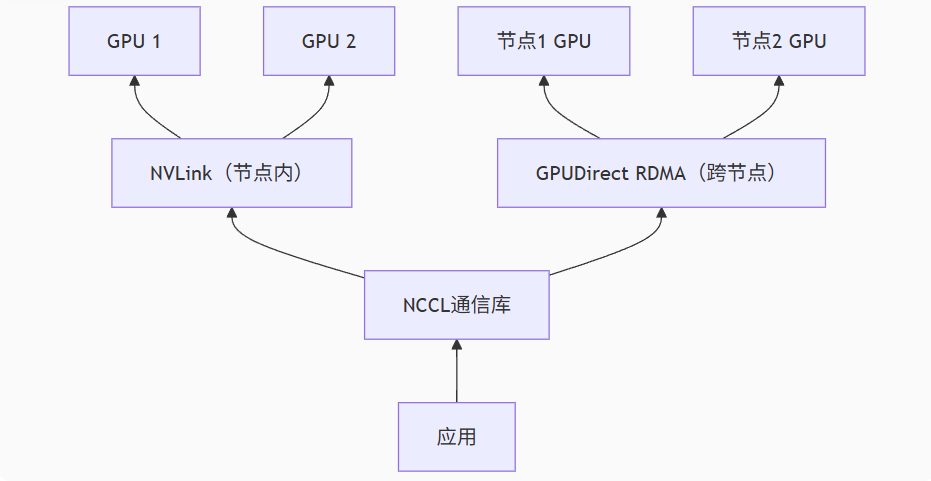
NVLink拓扑架构(以DGX H100为例):
- 全连接带宽:900 GB/s(NVLink 4.0)
- 8卡互连延迟:<500 ns
- 对比PCIe 5.0:仅128 GB/s,延迟>2 μs
GPUDirect RDMA关键技术:
- 绕过CPU直接访问远端GPU显存
- 支持InfiniBand/ROCEv2网络(要求≥100 Gbps)
- 带宽利用率达95%(传统TCP/IP仅40%)
3.2.2 软件聚合层:并行计算框架
| 框架 | 通信机制 | 适用场景 |
|---|---|---|
| PyTorch DDP | 环状AllReduce | 动态图模型训练 |
| TensorFlow MirroredStrategy | Hierarchical Copy | 静态图分布式训练 |
| DeepSpeed ZeRO | 显存分片+梯度聚合 | 千亿参数模型训练 |
| NVIDIA NCCL | GPU-GPU直接通信 | 底层集合通信库 |
3.3 性能优化关键
3.3.1 通信-计算重叠
梯度压缩:
- FP16混合精度(节省50%通信量)
- 1-bit Adam(通信量降至1/32)
流水线并行(Pipeline Parallelism):
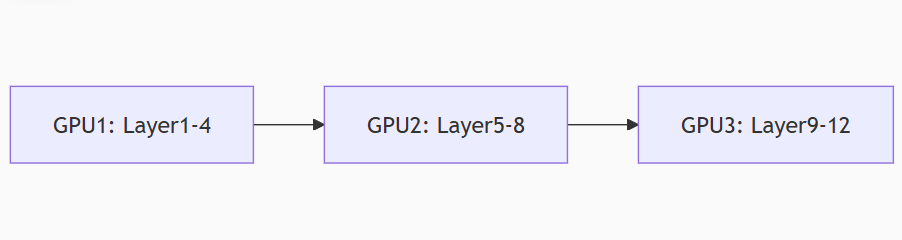
- 微批次(Micro-batching)隐藏通信延迟
- Megatron-LM实现千卡训练效率>52%
3.3.2 拓扑感知调度
NVIDIA DGX SuperPOD架构:
- 32节点(256 GPU)通过InfiniBand分层交换
- 通信热点区域带宽保障
Kubernetes调度策略:
# 要求GPU同节点拓扑
affinity:nodeAffinity:requiredDuringSchedulingIgnoredDuringExecution:nodeSelectorTerms:- matchExpressions:- key: topology.kubernetes.io/zoneoperator: Invalues: [ "nvlink-group-1" ]
3.4 与一虚多技术的协同模式
混合架构案例:AI云服务平台:
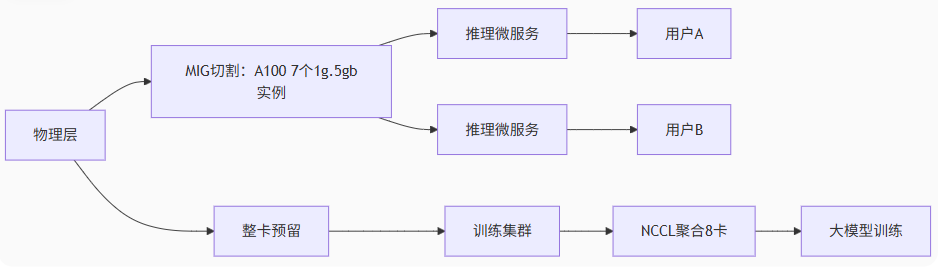
优势:
- 推理任务:MIG隔离保障SLA
- 训练任务:多虚一突破单卡限制
资源调度:Kubernetes实现自动扩缩容
四、GPU虚拟化示例
基于文章开头单节点单GPU无法部署多个使用GPU的pod场景,来看看可以怎么操作实现多pod使用一块GPU。这里我们使用Time-Slicing方案,官方参考文档:
About Configuring GPU Time-Slicing
Shared Access to GPUs
4.1 准备configMap
准备如下configMap用于Time-Slicing配置:
# cm.yaml
apiVersion: v1
kind: ConfigMap
metadata:name: nvidia-device-plugin-confignamespace: kube-system
data:config.yaml: |version: v1flags:migStrategy: nonefailOnInitError: truenvidiaDriverRoot: /sharing:timeSlicing:resources:- name: nvidia.com/gpureplicas: 5 # 将1个GPU拆分成5个虚拟实例,如果有n个GPU,则会拆分成5*n个实例
创建该configMap:
$ kubectl apply -f cm.yaml
configmap/nvidia-device-plugin-config created
4.2 修改nvidia k8s-device-plugin(daemonSet)
使用kubectl -n kube-system edit ds nvidia-device-plugin-daemonset命令修改nvidia k8s-device-plugin配置:
...
spec:template:spec:- containers:name: nvidia-device-plugin-ctrargs: # 新增args配置- --config-file=/etc/nvidia-device-plugin/config.yaml...volumeMounts:- mountPath: /etc/nvidia-device-plugin # 新增configMap的mountPathname: device-plugin-config...volumes:- name: device-plugin-config # 新增configMap volumeconfigMap:name: nvidia-device-plugin-config
...
修改完daemonSet pod会自动重建:
$ kubectl -n kube-system get pod | grep nvidia
nvidia-device-plugin-daemonset-nn9dc 1/1 Running 0 47s
4.3 查看node上的GPU资源
可以看到nvidia k8s-device-plugin完成了GPU资源的上报,并把GPU资源数量修改为了5个(物理层面只有一个)。
$ kubectl get node
NAME STATUS ROLES AGE VERSION
desktop-72rd6ov Ready control-plane,master 425d v1.22.7$ kubectl get node desktop-72rd6ov -oyaml| grep nvidia.com -A 1 -B 6allocatable:cpu: "16"ephemeral-storage: "972991057538"hugepages-1Gi: "0"hugepages-2Mi: "0"memory: 16142544Kinvidia.com/gpu: "5"pods: "110"capacity:cpu: "16"ephemeral-storage: 1055762868Kihugepages-1Gi: "0"hugepages-2Mi: "0"memory: 16244944Kinvidia.com/gpu: "5"pods: "110"
4.4 创建pod验证
还是使用文章开头的nginx pod yaml创建多个pod:
// 先删除旧pod
$ kubectl delete pod gpu-pod-1
pod "gpu-pod-1" deleted
$ kubectl delete pod gpu-pod-2
pod "gpu-pod-2" deleted// 修改yaml中pod名称重新创建6个
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
gpu-pod-1 1/1 Running 0 41s 10.244.0.236 desktop-72rd6ov <none> <none>
gpu-pod-2 1/1 Running 0 31s 10.244.0.237 desktop-72rd6ov <none> <none>
gpu-pod-3 1/1 Running 0 24s 10.244.0.238 desktop-72rd6ov <none> <none>
gpu-pod-4 1/1 Running 0 19s 10.244.0.239 desktop-72rd6ov <none> <none>
gpu-pod-5 1/1 Running 0 12s 10.244.0.240 desktop-72rd6ov <none> <none>
gpu-pod-6 0/1 Pending 0 6s <none> <none> <none> <none>// 进入2个pod验证
$ kubectl exec -ti gpu-pod-1 -- bash
root@gpu-pod-1:/# nvidia-smi --version
NVIDIA-SMI version : 560.35.02
NVML version : 560.35
DRIVER version : 560.94
CUDA Version : 12.6$ kubectl exec -ti gpu-pod-4 -- bash
root@gpu-pod-4:/# nvidia-smi --version
NVIDIA-SMI version : 560.35.02
NVML version : 560.35
DRIVER version : 560.94
CUDA Version : 12.6
root@gpu-pod-4:/#
总结
本文简单介绍了nvidia GPU虚拟化的常见方法,包含“一虚多”和“多虚一”场景。以“一虚多”为例,本文以nvidia k8s-device-plugin支持的Time-Slicing方案演示了多个pod使用一张GPU的应用,但实际使用过程中,Time-Slicing存在多应用互相影响的风险,在某些业务场景是无法接受的,生产中一般会按cuda核心和显存大小切割成不同的实例避免应用相互影响,但这又可能降低GPU资源的利用率,总之针对不同场景、不同应用可能需要选择不同的GPU虚拟化方案,GPU虚拟化也有待更深入地探索。