LLMs基础学习(八)强化学习专题(1)
LLMs基础学习(八)强化学习专题(1)
文章目录
- LLMs基础学习(八)强化学习专题(1)
- 学习资料资源
- 强化学习是什么
- 强化学习一句话精准定义
- 强化学习与其他学习类型的对比
- 强化学习 vs 监督学习
- 强化学习 vs 非监督学习
- 三者总结对比
- 损失函数 对比
- 强化学习发展历史梳理
- 传统强化学习阶段(1950s - 2000s)
- 1. 动态规划(Dynamic Programming, DP)
- 2. 蒙特卡罗方法(Monte Carlo, MC)
- 3. 时序差分学习(Temporal Difference, TD)
- 策略优化与深度强化学习阶段(2000s - 2010s)
- 1. 策略梯度(Policy Gradient, PG)
- 2. A - C 方法(Actor - Critic)
- 3. 深度 Q 网络(Deep Q - Network, DQN, 2013)
- 深度强化学习扩展与优化(2010s - 至今)
- 1. 改进型 DQN 算法
- 2. 策略优化进阶
- 3. 模仿学习与逆强化学习
- 算法改进核心逻辑(技术演进脉络)
- 小结
- 强化学习中不同方法的对比总结表
- 根据智能体动作选取方式分类
- 基于价值的方法(Value-Based)
- 基于策略的方法(Policy-Based)
- 结合价值与策略的方法(Actor-Critic)
- 强化学习中不同方法的对比总结表
- 马尔可夫决策过程(MDP)
- MDP 整体定位
- 核心概念
- 1. 马尔可夫(Markov)
- 2. 马尔可夫最重要性质
- 3. 马尔可夫过程(Markov Process,简称 MP)
- 4. 马尔可夫决策过程(Markov Decision Process,MDP)
- MDP小结
视频链接:https://www.bilibili.com/video/BV1MQo4YGEmq/?spm_id_from=333.1387.upload.video_card.click&vd_source=57e4865932ea6c6918a09b65d319a99a
学习资料资源
这部分是为想学习强化学习的人准备的 “知识储备库”,提供不同形式的学习素材:
- 书籍资料
- 权威著作:2024 年图灵奖得主 Richard S. Sutton 和 Andrew G. Barto 的相关作品(如《BartoSutton.pdf》 ),是强化学习领域经典理论奠基读物,能帮读者搭建扎实理论基础。
- 实验室资料:西湖大学智能无人系统实验室(WINDY Lab)赵世钰分享的资料(仓库地址 https://github.com/MathFoundationRL/Book-Mathematical-Foundation-of-Reinforcement-Learning ),可从数学视角深入剖析强化学习底层逻辑,适合想钻研理论深度的学习者。
- 视频资料:提到 “强化学习的数学原理” 相关视频(未给出具体链接,但可推测是从数学推导、公式逻辑角度讲解强化学习,帮学习者理解算法背后数学支撑 )。
- 博客资料:给出博客链接 https://www.cnblogs.com/pinard/p/9385570.html ,这类技术博客通常会用更通俗、案例化的方式讲解强化学习概念、算法实践,适合辅助理解理论知识。
强化学习是什么
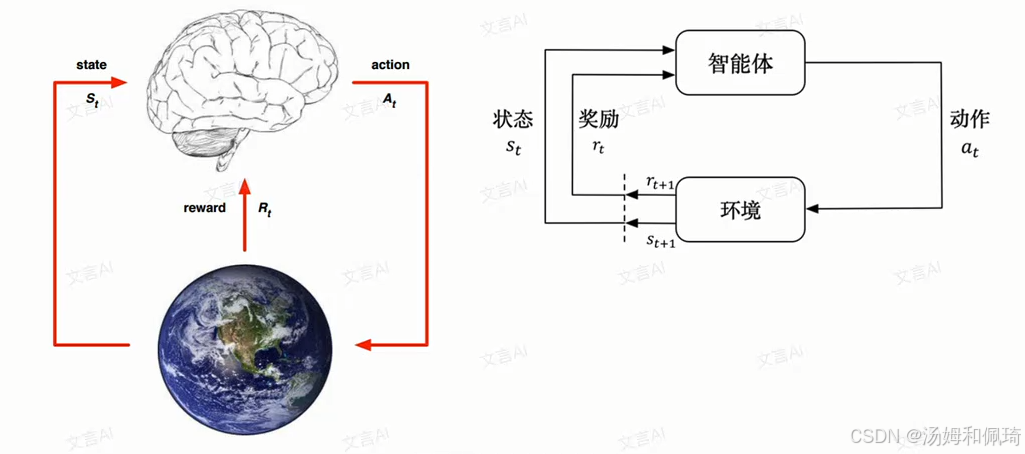
- 核心问题:研究智能体(agent)在复杂、不确定的环境(environment) 里,如何通过一系列交互,最大化自身能获得的奖励 。简单说,就是教智能体在多变环境中 “做对的事”,拿到最多 “好处”。
- 组成要素:由智能体(agent) 和环境(environment) 两部分构成,二者持续交互推动学习过程。
- 交互流程
- 智能体行动:智能体先从环境中获取当前状态(state) ,基于这个状态,输出一个动作(action) ,也叫 “决策(decision)” 。比如机器人(智能体)在房间(环境)里感知到自己在角落(状态),就会输出 “移动到中间” 的动作。
- 环境反馈:智能体的动作在环境中执行后,环境会给出两部分反馈:一是下一个状态(next state) (比如机器人移动后,新的位置状态);二是当前动作带来的奖励(reward) (若移动到中间能充电,奖励就是 “获得能量” )。
- 目标导向:智能体持续重复 “感知状态→输出动作→接收反馈” 循环,最终目的就是尽可能多地从环境中获取奖励 ,让自己的 “收益” 最大化。
强化学习一句话精准定义
这部分用简洁表述,把强化学习本质提炼出来:
- 英文原版:“Reinforcement learning is learning what to do – how to map situations to actions – so as to maximize a numerical reward signal.” 直接翻译是 “强化学习是学习做什么(即如何把当前情境映射成动作),从而最大化数值化的奖励信号” 。
强化学习与其他学习类型的对比
强化学习 vs 监督学习
| 对比维度 | 监督学习特点 | 强化学习特点 |
|---|---|---|
| 数据与输出值 | 有预先准备好的训练数据输出值(带标签数据,比如分类任务里的类别标签 ) | 无预先输出值,只有延迟给出的奖励值(不是事先确定,是交互后环境反馈的 ) |
| 学习模式 | 基于静态带标签数据学习,数据间独立无时间依赖(比如图像分类,每张图标签独立 ) | 在实践交互中学习,每一步与时间顺序、前后状态紧密关联(如走路学习,一步影响下一步 ) |
| 反馈机制 | 即时标签反馈(模型预测后,立刻对比标签知道对错 ) | 延迟奖励反馈(动作执行后,需等环境后续反馈奖励,比如走路摔倒后才收到负面奖励 ) |
| 举 例 | 图像分类:输入猫的图片,标签直接告诉模型 “这是猫”,模型学预测规则 | 学走路:摔倒(动作)后,过一会大脑给负面奖励;走对步(动作),后续给正面奖励 |
强化学习 vs 非监督学习
| 对比维度 | 非监督学习特点 | 强化学习特点 |
|---|---|---|
| 数据与反馈 | 无输出值、无奖励值,只有数据特征(比如聚类任务里的样本特征 ) | 有延迟奖励值,基于交互反馈 |
| 数据依赖关系 | 数据间独立无时间 / 前后依赖(比如对一批用户行为数据聚类,每条数据独立 ) | 数据(交互过程)与时间顺序、前后状态强关联(如游戏里每一步操作影响下一步 ) |
| 核心目标 | 发现数据结构规律(比如聚类成不同群体、降维提炼关键特征 ) | 最大化累积奖励,通过与环境交互优化决策 |
三者总结对比
| 维度 | 监督学习 | 无监督学习 | 强化学习 |
|---|---|---|---|
| 数据 | 带标签的静态数据 | 无标签的静态数据 | 动态交互生成的数据 |
| 反馈 | 即时标签反馈 | 无显式反馈 | 延迟奖励信号 |
| 目标 | 预测准确率最大化 | 数据结构发现 | 累积奖励最大化 |
| 应用 | 分类、回归(如图像识别、预测) | 聚类、降维(如用户分群) | 决策优化、控制(如游戏、机器人) |
| 复杂度 | 中(依赖标注质量,标注成本高) | 低(无需标注) | 高(需处理长期依赖、动态交互) |
损失函数 对比
| 对比维度 | 深度学习损失函数特点 | 强化学习损失函数特点 |
|---|---|---|
| 核心目标 | 最小化预测值与真实值的差距(比如分类任务里的分类错误 ) | 最大化总奖励的期望(让智能体获得更多累积奖励 ) |
| 数据性质 | 静态、独立同分布(比如训练集里的样本相互独立 ) | 动态生成、时序相关(交互过程产生,一步影响一步 ) |
| 动态性 | 固定(如交叉熵损失,形式相对固定 ) | 随策略 / 环境变化(如贝尔曼误差会动态更新 ) |
| 优化对象 | 模型输出(如分类概率、回归预测值 ) | 策略、价值函数或其组合(优化智能体的决策逻辑 ) |
| 依赖环境 | 无需交互,依赖静态数据训练(拿标注数据直接训 ) | 需与环境交互获取奖励信号(边试边学,依赖环境反馈 ) |
强化学习发展历史梳理
强化学习(Reinforcement Learning, RL)作为机器学习重要分支,核心目标是智能体通过与环境交互,学会最大化累积奖励,其发展历经多阶段,以下按时间线与关键节点拆解:
传统强化学习阶段(1950s - 2000s)
聚焦基础理论与经典方法,为后续发展奠基,包含三类核心技术:
1. 动态规划(Dynamic Programming, DP)
- 原理:用递归分解问题,计算每个状态最优价值函数(如价值迭代),或直接优化策略(如策略迭代)。
- 特点:首次将数学规划引入决策,需完整环境模型(如状态转移概率);但计算复杂度高,仅适用于小规模问题。
2. 蒙特卡罗方法(Monte Carlo, MC)
- 原理:通过随机采样轨迹(如 “玩完一局游戏”)估计价值函数,无需环境模型。
- 特点:解决 DP 依赖模型的问题,但需完整轨迹,存在方差大、收敛慢问题;如蒙特卡罗策略迭代,靠经验平均更新策略,数据利用率低。
3. 时序差分学习(Temporal Difference, TD)
- 代表算法:Q - learning(1989)、SARSA(State - Action - Reward - State - Action,1994)。
- 原理:结合 DP(利用模型)与 MC(采样轨迹),通过单步更新(如 Q - learning 的 “当前奖励 + 未来估计”)在线学习。
- 特点:Q - learning 是 “免模型” 算法,支持在线学习;但受限于离散状态动作空间,难处理高维问题。
策略优化与深度强化学习阶段(2000s - 2010s)
引入策略梯度、深度学习,突破传统方法局限,迈向更复杂场景:
1. 策略梯度(Policy Gradient, PG)
- 原理:直接优化策略(如动作概率分布),靠梯度上升最大化期望奖励。
- 特点:适配连续动作空间(如机器人控制);但梯度估计方差大、训练不稳定。REINFORCE 算法(1992 年 Williams 提出)是早期代表,通过整条轨迹更新策略,样本效率低。
2. A - C 方法(Actor - Critic)
- 原理:结合 “策略梯度(Actor,负责生成动作)” 与 “值函数(Critic,评估动作价值)”。
- 特点:Critic 可减少梯度方差,提升训练效率;如 A3C(Asynchronous Advantage Actor - Critic)支持并行训练,优化训练流程。
3. 深度 Q 网络(Deep Q - Network, DQN, 2013)
- 原理:用深度神经网络近似 Q 值函数,结合经验回放(存储历史数据)、固定目标网络(稳定训练)。
- 特点:首次在 Atari 游戏中超越人类水平,解决高维状态(如图像输入) 表示问题;但动作空间仍需离散,限制应用场景。
深度强化学习扩展与优化(2010s - 至今)
在前期基础上迭代创新,覆盖更多复杂任务,核心方向包括:
1. 改进型 DQN 算法
- 代表算法:Double DQN(解决 Q 值高估)、Dueling DQN(分离状态价值与动作优势)。
- 特点:通过结构优化,提升算法稳定性与泛化能力,适配更多场景。
2. 策略优化进阶
- 代表算法:TRPO(Trust Region Policy Optimization,信任域策略优化)、PPO(Proximal Policy Optimization,近端策略优化)、GRPO(Group Relative Policy Optimization)。
- 特点:约束策略更新幅度,避免训练崩溃,适配复杂任务(如机器人行走),平衡训练效率与稳定性。
3. 模仿学习与逆强化学习
- 原理:模仿专家行为(如自动驾驶),或从数据反推奖励函数。
- 特点:减少智能体 “探索成本”,提升安全性与可解释性,让强化学习更贴近实际应用(如工业控制、自动驾驶)。
算法改进核心逻辑(技术演进脉络)
从传统到现代,强化学习算法优化围绕四大方向突破:
- 模型依赖→免模型:DP 需完整环境模型,Q - learning、DQN 等免模型算法更通用,适配未知环境。
- 离散空间→连续空间:Q - learning 局限于离散动作,策略梯度支持连续控制,拓展机器人、自动驾驶等场景。
- 低效采样→高效利用:蒙特卡罗需完整轨迹,TD、Actor - Critic 实现单步更新;经验回放技术进一步提升数据利用率。
- 单一方法→混合融合:Actor - Critic 结合值函数与策略梯度;深度强化学习融合深度学习特征提取能力,处理高维复杂输入。
小结
强化学习发展历经 “传统方法奠基→深度强化学习突破→扩展优化落地” 路径,核心是平衡环境适配性、训练效率与任务复杂度。从依赖环境模型到免模型、从离散到连续空间、从低效采样到高效利用,每一步突破都推动其在机器人、游戏、自动驾驶等领域落地,未来仍会围绕 “更高效、更稳定、更易解释” 持续演进 。
强化学习中不同方法的对比总结表
根据智能体动作选取方式分类
依据学习目标不同
基于价值的方法(Value-Based)
- 核心思想:优化价值函数(状态值函数 (V(s))、动作值函数 (Q(s,a)) )间接找最优策略,选动作时追求未来累积奖励最大。
- 代表算法:
- Q - Learning:用贝尔曼方程迭代更新 Q 表,适配离散状态 / 动作空间 。
- DQN:神经网络拟合 Q 值函数,靠经验回放、目标网络解决训练不稳定,适用于高维状态空间。
- 特点与局限:
- 优点是采样效率高、收敛稳定,适配离散动作场景;
- 缺点是难处理连续动作空间,策略依赖价值函数估计精度;
- 数学基础为贝尔曼方程驱动价值迭代 。
基于策略的方法(Policy-Based)
- 核心思想:直接优化策略函数 ( π ( a ∣ s ) (\pi(a|s) (π(a∣s)(状态到动作的概率分布 ),不用显式算价值函数,靠策略梯度上升最大化长期回报。
- 代表算法:
- REINFORCE:用蒙特卡洛采样估计梯度,但高方差让收敛慢。
- PPO:剪切实例目标函数限制策略更新幅度,平衡探索和利用,在工业界(像 ChatGPT 训练 )常用。
- TRPO:引入 KL 散度约束策略更新,保障训练稳定。
- 特点与局限:
- 优点:适配连续动作空间,策略表达(概率分布形式 )灵活。
- 缺点:高方差使样本效率低,易陷入局部最优。
- 数学基础:策略梯度定理(Policy Gradient Theorem )支撑。
结合价值与策略的方法(Actor-Critic)
- 核心思想:融合价值函数和策略函数优势,“演员(Actor)” 生成策略,“评论家(Critic)” 评估动作价值,协同优化策略 。
- 代表算法:
- A2C/A3C:多线程异步更新加速训练,Critic 算优势函数指导 Actor 优化。
- SAC:引入熵正则化鼓励探索,适配复杂连续控制任务(如机器人行走 )。
- 特点与局限:
- 优点:平衡探索与利用,训练效率高,适合复杂任务。
- 缺点:结构复杂,要同时调优 Actor 和 Critic 网络。
- 数学基础:TD 误差(Temporal Difference Error )联合优化策略与价值函数。
强化学习中不同方法的对比总结表
从策略生成方式、动作空间适用性、训练稳定性和典型算法四个维度,对比了基于价值的方法、基于策略的方法、Actor - Critic 方法 :
| 维度 | 基于价值的方法 | 基于策略的方法 | Actor - Critic 方法 |
|---|---|---|---|
| 策略生成方式 | 间接(贪心选择 Q 值最大) | 直接(输出动作概率) | 策略与价值函数联合优化 |
| 动作空间适用性 | 离散 | 连续 / 离散 | 连续 / 离散 |
| 训练稳定性 | 高(低方差) | 低(高方差) | 中等(需平衡两者) |
| 典型算法 | Q - Learning、DQN | REINFORCE、PPO | A2C、SAC |
参考资料为《强化学习算法与应用综述 - 李茹杨.pdf》(1.26MB ),可辅助深入了解这些强化学习方法 。
马尔可夫决策过程(MDP)
MDP 整体定位
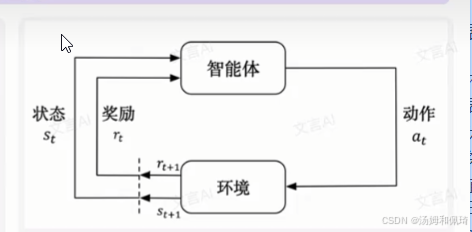
强化学习里,智能体与环境交互流程(智能体感知状态→执行动作→环境转移状态并反馈奖励 ),可用马尔可夫决策过程(MDP)建模,它是强化学习的基础理论框架。
核心概念
1. 马尔可夫(Markov)
- 定义:一种 “无记忆性”(Memoryless Property),即未来状态仅由当前状态决定,和过去历史状态无关 。
- 举例:天气预报中,若 “明天天气只看今天,不受昨天及更早影响”,就符合马尔可夫性。
- 起源:俄国数学家 Andrey Andreevich Markov 提出马尔可夫链,发现随机系统 “未来仅与当前相关” 的特性,为 MDP 奠定数学基础。
2. 马尔可夫最重要性质
- 核心:无记忆性,让建模 / 计算复杂度大幅降低 —— 无需记录完整历史,仅关注当前状态即可。
- 应用:在强化学习、排队论、自然语言处理等领域广泛应用,是马尔可夫模型的理论基石。
- 数学表达: ( P ( S t + 1 ∣ S t , S t − 1 , . . . , S 0 ) = P ( S t + 1 ∣ S t ) (P(S_{t+1} | S_t, S_{t-1}, ..., S_0) = P(S_{t+1} | S_t) (P(St+1∣St,St−1,...,S0)=P(St+1∣St) 直观体现 “未来仅由现在决定,与过去无关”。
3. 马尔可夫过程(Markov Process,简称 MP)
- 定义:满足马尔可夫性的随机过程,由两部分组成:
- 状态集合(State Space):系统所有可能状态(如天气模型里的 {晴天、雨天} )。
- 状态转移概率矩阵(Transition Probability Matrix):定义当前状态→下一状态的转移概率(如天气模型中,晴天→晴天概率 0.9、晴天→雨天概率 0.1 等 )。
- 举例(天气模型):
- 状态集合:{Sunny(晴天), Rainy(雨天)}
- 转移概率矩阵: (\begin{bmatrix} 0.9 & 0.1 \ 0.5 & 0.5 \end{bmatrix}) (第一行:晴天保持晴天概率 0.9、转雨天概率 0.1;第二行:雨天保持雨天概率 0.5、转晴天概率 0.5 )
4. 马尔可夫决策过程(Markov Decision Process,MDP)
-
定义:马尔可夫过程的扩展,引入智能体的 “动作” 和 “奖励机制”,用于建模序贯决策问题。核心元素用
⟨ S , A , P , R , γ ⟩ \langle S, A, P, R, \gamma \rangle ⟨S,A,P,R,γ⟩表示:
- S(状态集合):环境所有可能状态(如天气模型的 {Sunny, Rainy} )。
- A(动作集合):智能体可采取的动作(如天气模型里的 {带伞、不带伞} )。
- P(转移函数): P ( s ′ ∣ s , a ) P(s' | s, a) P(s′∣s,a) 表示 “状态 s 下执行动作 a,转移到状态 (s’) 的概率”(天气模型中,转移由自然规律决定,与动作无关,仍用之前的转移矩阵 )。
- R(奖励函数): R ( s , a , s ′ R(s, a, s' R(s,a,s′) 表示 “状态 s 执行动作 a 并转移到 (s’) 时,获得的即时奖励”(如天气模型里,晴天带伞获 -1 奖励、晴天不带伞获 0 奖励等 )。
- γ \gamma γ(折扣因子):未来奖励的衰减系数,平衡 “当前奖励” 和 “未来奖励” 的重要性(如更看重眼前收益,或长期累积收益 )。
-
目标:找到最优策略(Policy)—— 即从 “状态→动作” 的映射,最大化长期累积奖励。求解方法包括动态规划、蒙特卡洛方法、时序差分学习等。
-
举例(天气模型深化):
- 状态集合(S):{Sunny, Rainy}(天气的两种可能状态 )。
- 动作集合(A):{带伞(Umbrella), 不带伞(No_Umbrella)}(智能体在天气下的行为选择 )。
- 转移函数(P):同马尔可夫过程,天气转移由自然规律决定,与动作无关,转移矩阵不变。
- 奖励函数(R):
- 晴天(Sunny):带伞→奖励 -1(携带不便);不带伞→奖励 0(舒适)。
- 雨天(Rainy):带伞→奖励 2(避免淋雨,抵消携带不便);不带伞→奖励 -3(被淋湿)。
MDP小结
| 概念 | 核心特点 |
|---|---|
| 马尔可夫性质 | 未来仅依赖当前状态,无记忆性(基础特性) |
| 马尔可夫过程(MP) | 状态 + 转移概率,被动观测状态演变(无动作干预) |
| MDP | 在 MP 基础上,增加动作和奖励,实现主动决策 |
简言之,MDP 以 “马尔可夫无记忆性” 为基石,先通过马尔可夫过程描述状态的随机演变,再扩展引入 “动作” 和 “奖励”,让智能体可主动决策、优化长期收益,是强化学习建模序贯决策问题的核心工具。