XGBoost时间序列预测之-未来销量的预测
哈喽,我是我不是小upper!
今天想跟大家深入探讨一个关于XGBoost的案例——未来销量预测。在销售领域,精准预测未来的销售量对于企业的库存管理、产品生产和运营决策都有着至关重要的作用。时间序列预测主要依据历史销售数据来推断未来的销售趋势。传统的时间序列模型,例如ARIMA、SARIMA等,虽然能够捕捉数据中的时间规律,但在处理包含多维特征和复杂模式的数据时,往往显得力不从心。相比之下,XGBoost作为一种集成学习方法,能够同时处理非线性问题和多维特征,在时间序列预测领域展现出独特的优势。它通过构建多个决策树模型并进行集成,从而有效提高预测的准确性和鲁棒性。
1. 问题定义与数据特征分析
1.1 业务目标与数据结构
目标:基于历史销售数据及外部影响因素(天气、节假日、促销),构建模型预测未来 7 天的销售量 (
)。
数据集结构:
| 特征名称 | 类型 | 说明 |
|---|---|---|
| 日期(Date) | 时间戳 | 格式为 YYYY-MM-DD,用于时间序列对齐 |
| 销售量(Sales) | 连续值 | 目标变量,需预测的核心指标 |
| 天气(Weather) | 分类值 | 取值为 {晴天,多云,雨天,雪天},需进行独热编码或标签编码 |
| 节假日(Holiday) | 二值值 | 1 表示节假日,0 表示非节假日 |
| 促销(Promotion) | 二值值 | 1 表示有促销活动,0 表示无 |
1.2 业务挑战的技术映射
- 非线性因素:促销与销量可能存在阈值效应(如促销力度超过一定阈值才显著提升销量),需模型具备非线性拟合能力。
- 时间依赖性:
- 周期性:周内销量差异(如周末销量高于工作日)、月度促销周期。
- 趋势性:长期增长 / 下降趋势(如电商渗透率提升带来的销量增长)。
- 特征融合:需将时序特征(滞后销量)与外部特征(天气、促销)进行跨维度组合,捕捉交互效应(如雨天 + 促销对销量的联合影响)。
2. XGBoost 核心原理与公式推导
2.1 目标函数与优化逻辑
XGBoost 的目标函数为正则化的加法模型,形式如下:
- 损失函数
:衡量预测值
与真实值
的差异,回归任务常用均方误差(MSE):
- 正则化项 \(\Omega(f_k)\):控制模型复杂度,防止过拟合,包含树的复杂度度量:
其中 T 为树的叶子节点数,
为第 j 个叶子节点的预测值,
(L1 正则系数)和
(L2 正则系数)为超参数。
2.2 加法训练与残差拟合
XGBoost 通过迭代构建弱学习器(决策树),每轮训练拟合上一轮的残差:
其中 为第 k 轮预测值,
为第 k 棵树对样本
的预测值。 残差计算:
第 k 棵树以 为目标值进行训练,最终模型为所有树的加权和:
3. 时间序列特征工程:从原始数据到模型输入
3.1 滞后特征(Lag Features)
利用历史销量数据生成滞后特征,捕捉短期依赖关系。设滞后阶数为 p,则第 t 时刻的滞后特征为:
示例:若 p=7,则预测 时使用前 7 天的销量
作为特征。
3.2 滚动窗口特征(Rolling Window Features)
通过滑动窗口计算统计量,捕捉中长期趋势与波动:
- 滚动均值:
(窗口大小 m=7 时,为前 7 天销量均值)
- 滚动标准差:
3.3 时间编码特征
将日期转换为模型可识别的数值特征:
- 星期编码:
(0 = 周一,1 = 周二,…)
- 节假日编码:
(直接使用原始二值特征)
- 促销编码:
(直接使用原始二值特征)
3.4 分类特征处理
对天气等分类特征进行独热编码(One-Hot Encoding):
(每个类别对应一个二值特征,如晴天为 [1,0,0,0])
4. 模型架构:XGBoost 时间序列预测流程
4.1 特征矩阵构建
对于预测时刻 t,输入特征矩阵 包含:
维度示例:若滞后阶数 (p=7),滚动窗口 (m=7),天气独热编码为 4 维,则 维度为 7+2+1+1+1+4=16。
4.2 模型训练与预测
- 训练阶段:使用历史数据
拟合 XGBoost 模型,优化目标函数
。
- 预测阶段:对于未来时刻
,生成对应的特征矩阵
,输入模型得到预测值
。
4.3 时间序列拆分策略
为保留时序依赖关系,采用滚动时间窗验证:
- 训练集:[1, t_1],验证集:
,测试集:
- 确保验证集 / 测试集的时间点均在训练集之后,避免数据泄露。
5. 模型优化与评价指标
5.1 超参数调优
- 关键参数:
max_depth:控制树的深度,防止过拟合(默认 6)。learning_rate:学习率,控制每棵树的贡献度(建议 0.01-0.1)。n_estimators:树的数量,需与学习率联合调优。reg_alpha(对应公式中reg_lambda(对应
- 调优方法:网格搜索(Grid Search)或随机搜索(Random Search),以验证集 MSE 为优化目标。
5.2 评价指标
- 均方根误差(RMSE):
- 平均绝对误差(MAE):
6. 扩展:结合 PyTorch 的深度学习方案(可选)
若需处理更复杂的非线性关系,可将 XGBoost 与 PyTorch 结合:
- 特征嵌入:使用 PyTorch 训练嵌入层处理高维分类特征(如天气类别)。
- 时序编码器:通过 LSTM/Transformer 编码器提取时序特征,与 XGBoost 的树模型融合。
- 混合模型:
其中
为 PyTorch 生成的特征嵌入向量。
销售数据集
销售数据生成与预处理
销售数据集构建
我们构建一个虚拟销售数据集以模拟实际销售场景。
此数据集涵盖以下属性:
-
日期(Date)
-
销售量(Sales)
-
天气(Weather)
-
节假日(Holiday)
-
促销(Promotion)
我们假设天气、节假日及促销活动均会对每日销售量产生影响,并且销售数据存在月度周期性波动。
虚拟数据集生成方式如下:
-
日期范围生成:从 2022 年 1 月 1 日开始,按日频率生成 1000 个日期数据点。
-
销售量模拟:设定基础销售量为 200,并引入月度周期性波动项(通过正弦函数模拟),同时加入随机高斯噪声以模拟实际销售中的随机波动。
-
天气数据模拟:随机生成晴天、雨天和多云三种天气状况。
-
节假日与促销活动标记:分别以 10% 和 20% 的概率随机标记节假日和促销活动。
import pandas as pd
import numpy as np
import random# 生成日期范围
dates = pd.date_range(start='2022-01-01', periods=1000, freq='D')# 模拟销售量数据,假设其具有周期性和随机波动
np.random.seed(42)
sales = 200 + 10 * np.sin(np.arange(len(dates)) / 30) + np.random.normal(0, 20, len(dates))# 随机生成天气、节假日和促销数据
weather = np.random.choice(['Sunny', 'Rainy', 'Cloudy'], size=len(dates))
holiday = np.random.choice([0, 1], size=len(dates), p=[0.9, 0.1]) # 10% 是节假日
promotion = np.random.choice([0, 1], size=len(dates), p=[0.8, 0.2]) # 20% 有促销活动# 创建DataFrame
df = pd.DataFrame({'Date': dates,'Sales': sales,'Weather': weather,'Holiday': holiday,'Promotion': promotion
})# 显示前几行数据
df.head()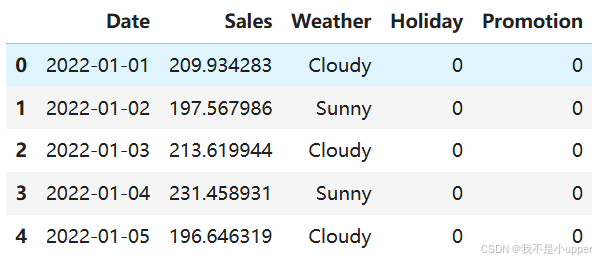
数据预处理流程
在进行预测模型构建之前,对数据执行以下预处理操作:
日期特征提取
将日期字段细分为年、月、日和星期几等维度,以协助模型捕捉销售数据中的季节性模式。
# 日期特征处理
df['Year'] = df['Date'].dt.year
df['Month'] = df['Date'].dt.month
df['Day'] = df['Date'].dt.day
df['DayOfWeek'] = df['Date'].dt.dayofweek类别特征编码
采用独热编码方式对分类变量(如天气状况)进行数值化转换,以便模型可以处理这些数据。
# 使用独热编码将天气特征转换为数值特征
df = pd.get_dummies(df, columns=['Weather'], drop_first=True)滞后特征构造
构建销售量的滞后特征(过去 7 天的数据),帮助模型理解历史销售对当前销售的潜在影响。
# 生成滞后特征
for lag in range(1, 8):df[f'Sales_lag_{lag}'] = df['Sales'].shift(lag)# 删除缺失值(由于滞后特征的产生,前几行会产生缺失值)
df = df.dropna()滚动窗口统计特征
计算过去 7 天销售量的均值和标准差,生成滚动窗口统计特征,从而捕捉销售趋势的动态变化。
# 生成滚动窗口的均值和标准差特征
df['Rolling_mean_7'] = df['Sales'].rolling(window=7).mean().shift(1)
df['Rolling_std_7'] = df['Sales'].rolling(window=7).std().shift(1)# 同样需要删除因滚动窗口导致的缺失值
df = df.dropna()基于 XGBoost 的时间序列销售预测模型构建
数据准备
在开始构建模型之前,我们需要对数据进行准备工作,包括划分训练集和测试集,并将数据转换为 PyTorch 张量格式,以便进行模型训练和测试。
from sklearn.model_selection import train_test_split
import torch
import numpy as np# 准备训练和测试集
X = df.drop(columns=['Date', 'Sales']).values
y = df['Sales'].values# 确保没有 NaN
X = np.nan_to_num(X) # 将 NaN 转换为 0 或其他默认数值
y = np.nan_to_num(y)# 确保数据类型都是数值型
X = X.astype(np.float32)
y = y.astype(np.float32)# 数据集划分
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, shuffle=False)# 转换为 PyTorch 张量
X_train = torch.tensor(X_train, dtype=torch.float32)
X_test = torch.tensor(X_test, dtype=torch.float32)
y_train = torch.tensor(y_train, dtype=torch.float32).view(-1, 1)
y_test = torch.tensor(y_test, dtype=torch.float32).view(-1, 1)模型结构定义
我们定义一个简单的前馈神经网络,用于模拟 XGBoost 的非线性拟合能力。该模型包含三个全连接层,能够处理多维特征并进行回归预测。
import torch.nn as nn# 定义神经网络模型
class XGBoostTimeSeriesModel(nn.Module):def __init__(self, input_dim):super(XGBoostTimeSeriesModel, self).__init__()self.fc1 = nn.Linear(input_dim, 128)self.fc2 = nn.Linear(128, 64)self.fc3 = nn.Linear(64, 1)def forward(self, x):x = torch.relu(self.fc1(x)) # 第一层后使用 ReLU 激活函数x = torch.relu(self.fc2(x)) # 第二层后使用 ReLU 激活函数x = self.fc3(x) # 第三层输出return x# 初始化模型
input_dim = X_train.shape[1]
model = XGBoostTimeSeriesModel(input_dim)损失函数与优化器
我们选择均方误差(MSE)作为损失函数,用于衡量模型预测值与真实值之间的差异。同时,使用 Adam 优化器进行模型参数优化,以加快模型收敛速度。
import torch.optim as optim# 定义损失函数和优化器
criterion = nn.MSELoss() # 均方误差损失
optimizer = optim.Adam(model.parameters(), lr=0.01) # Adam 优化器,学习率为 0.01模型训练
通过梯度下降法训练模型,进行多次迭代以优化模型参数。在训练过程中,定期输出损失值以便监控模型收敛情况。
# 模型训练
epochs = 500 # 设置训练的总迭代次数为 500for epoch in range(epochs):model.train() # 设置模型为训练模式optimizer.zero_grad() # 梯度清零outputs = model(X_train) # 前向传播loss = criterion(outputs, y_train) # 计算损失loss.backward() # 反向传播optimizer.step() # 参数更新if epoch % 50 == 0: # 每 50 个 epoch 输出一次损失print(f'Epoch {epoch}/{epochs}, Loss: {loss.item()}')
模型测试
完成训练后,在测试集上进行预测,并计算模型的性能指标,如均方误差(MSE),以评估模型的预测能力。
from sklearn.metrics import mean_squared_error# 模型预测
model.eval() # 设置模型为评估模式
predictions = model(X_test).detach().numpy() # 获取预测结果并转为 numpy 数组# 计算均方误差
mse = mean_squared_error(y_test, predictions)
print(f'Test MSE: {mse}')Test MSE: 372.80120849609375
结果可视化
为了直观地展示模型的预测效果,我们绘制预测值与真实值的对比图,以及训练过程中的损失下降曲线。这些图表有助于我们分析模型的性能和训练过程。
import matplotlib.pyplot as plt# 绘制预测值与真实值的对比图
plt.figure(figsize=(12, 6))
plt.plot(df['Date'][-len(y_test):], y_test, label='True Sales', linewidth=2)
plt.plot(df['Date'][-len(y_test):], predictions, label='Predicted Sales', linestyle='--', linewidth=2)
plt.xlabel('Date')
plt.ylabel('Sales')
plt.title('Sales Prediction vs True Sales')
plt.legend()
plt.grid(True)
plt.show()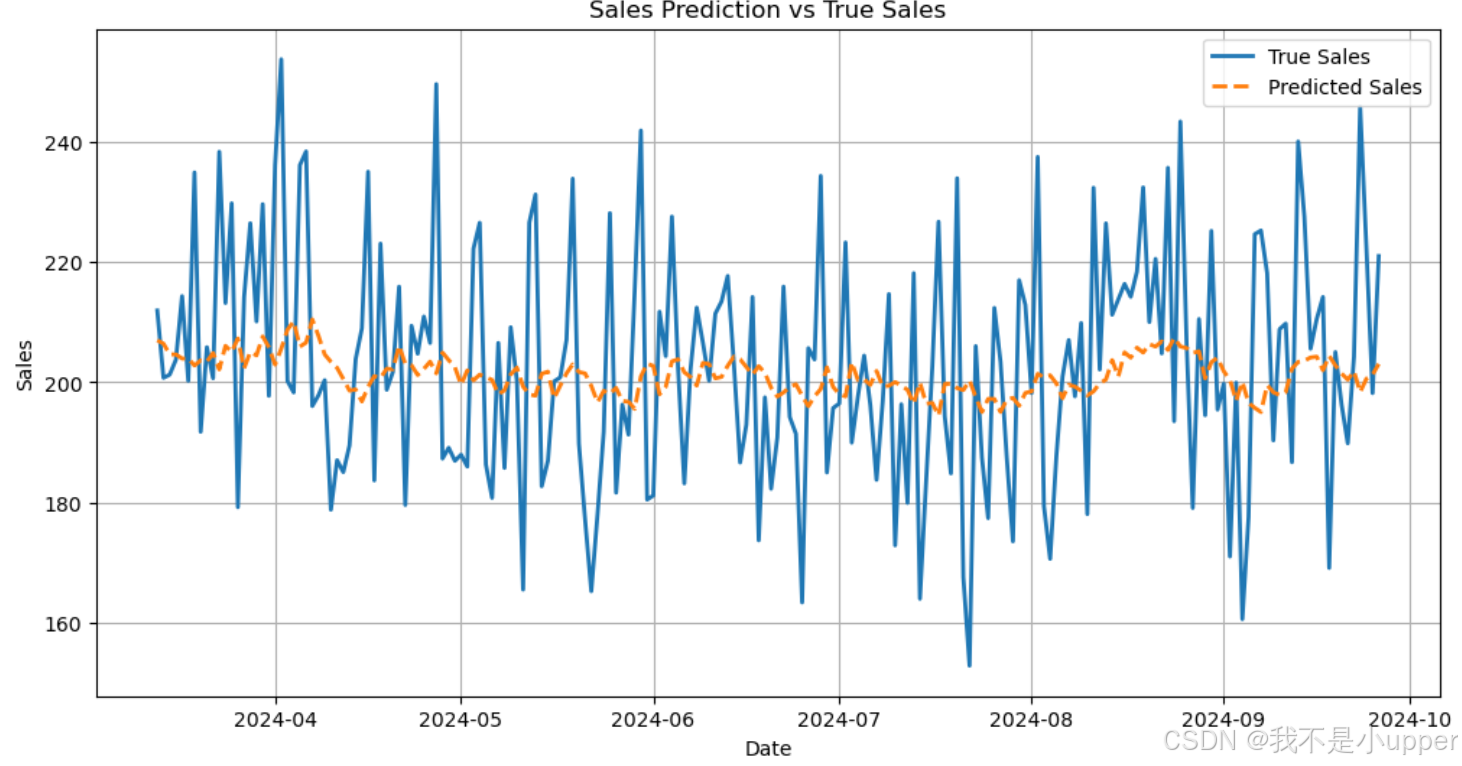
绘制损失下降曲线
# 绘制损失下降曲线
losses = []
for epoch in range(epochs):model.train()optimizer.zero_grad()outputs = model(X_train)loss = criterion(outputs, y_train)loss.backward()optimizer.step()losses.append(loss.item())plt.figure(figsize=(8, 4))
plt.plot(losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss Curve')
plt.show()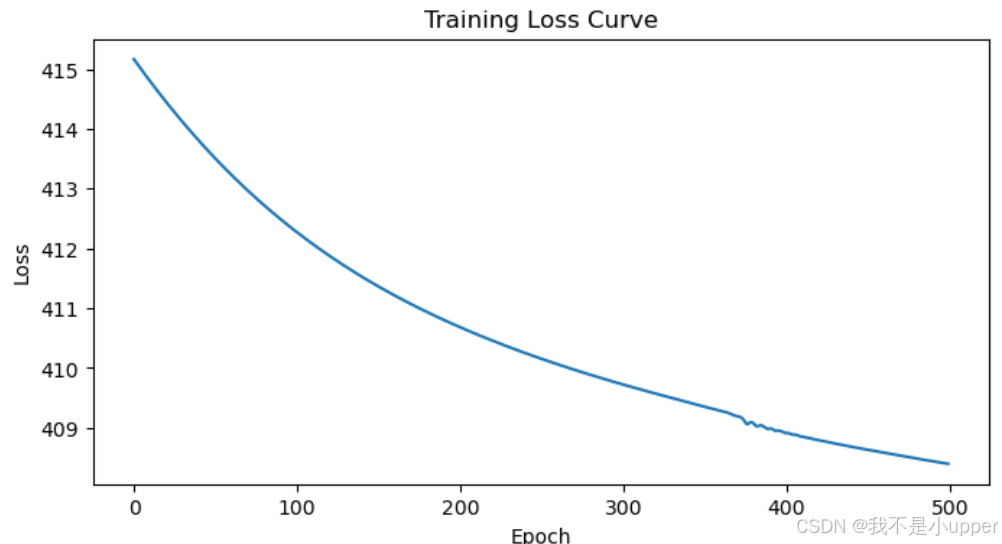
特征重要性分析
尽管 XGBoost 本身具有特征重要性评估功能,但我们可以通过分析神经网络模型的权重,来了解各特征对预测结果的影响程度。
# 特征重要性分析
importances = model.fc1.weight.abs().mean(dim=0).detach().numpy()
feature_names = df.drop(columns=['Date', 'Sales']).columnsplt.figure(figsize=(10, 6))
plt.barh(feature_names, importances)
plt.xlabel('Feature Importance')
plt.title('Feature Importance in Sales Prediction')
plt.show()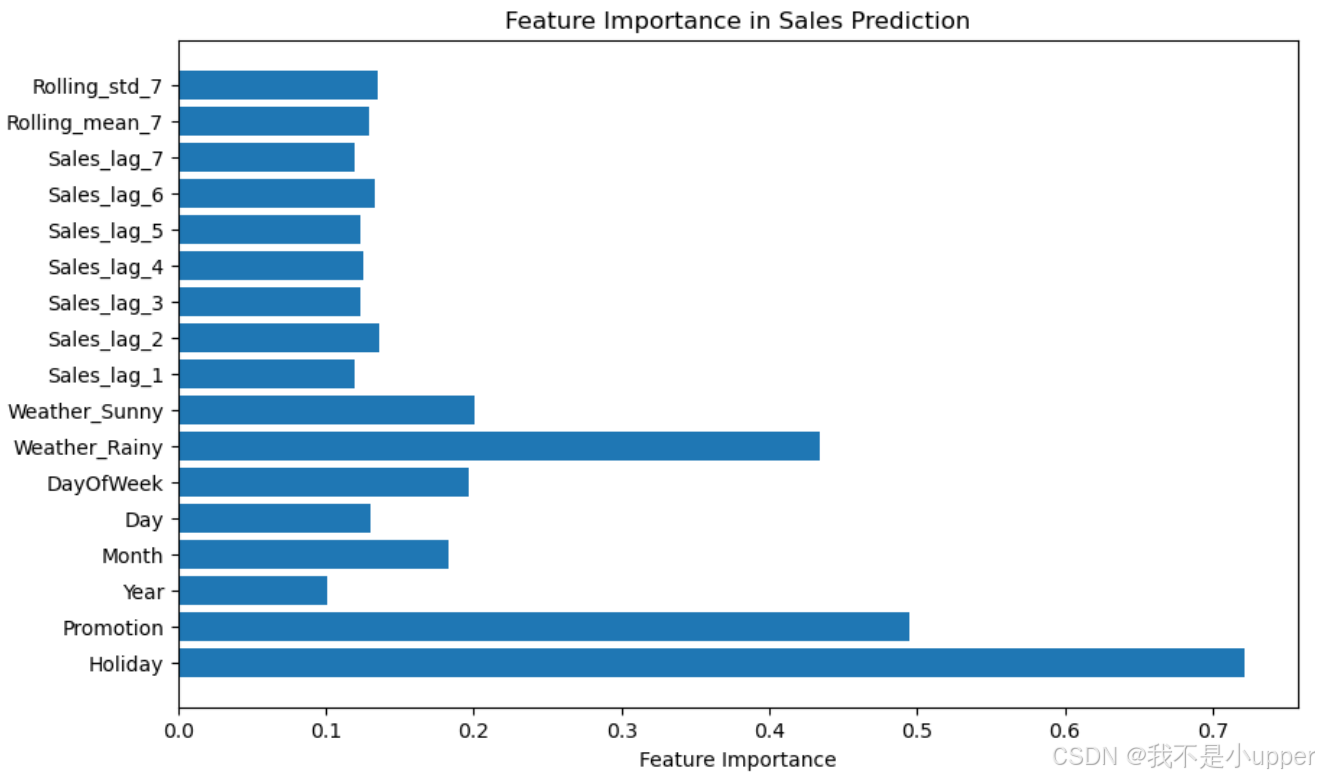
模型优化与调参
在实际应用中,优化模型性能是提升预测精度的关键步骤。主要的优化手段包括特征选择、超参数调优和交叉验证等。
超参数调优
XGBoost 模型的关键超参数包括学习率、树的最大深度、估计器数量以及正则化参数等。可以使用网格搜索进行超参数优化。
from sklearn.model_selection import GridSearchCV
import xgboost as xgb# 创建 XGBoost 模型
xgb_model = xgb.XGBRegressor()# 定义超参数搜索空间
param_grid = {'learning_rate': [0.01, 0.05, 0.1],'max_depth': [3, 5, 7],'n_estimators': [100, 200, 300],'reg_alpha': [0, 0.1, 0.5],'reg_lambda': [1, 1.5, 2]
}# 进行网格搜索
grid_search = GridSearchCV(estimator=xgb_model, param_grid=param_grid, cv=5, scoring='neg_mean_squared_error', verbose=1)
grid_search.fit(X_train, y_train)# 输出最佳参数
print("Best Parameters:", grid_search.best_params_)
模型验证与早停
在训练过程中引入早停机制,以防止过拟合。如果模型在验证集上的性能在连续若干轮中没有提升,则提前终止训练。
# 使用早停机制训练 XGBoost 模型
xgb_model = xgb.XGBRegressor(learning_rate=0.1, max_depth=5, n_estimators=300)
xgb_model.fit(X_train, y_train, eval_set=[(X_test, y_test)], early_stopping_rounds=50, verbose=True)通过上述步骤,我们结合 XGBoost 与时间序列模型,利用历史销售数据和多维特征(如天气、促销、节假日等)构建了一个销售预测模型。XGBoost 的强大非线性拟合能力使其在处理复杂特征和多维数据时表现出色。经过合理的特征工程、模型训练、调参与优化,我们得到了一个精确且泛化能力良好的预测模型。
该模型未来可从以下几方面进行改进:
-
增强时序特征:引入更多时间序列特征,如季节性成分,并与长短期记忆网络(LSTM)等方法进行对比。
-
引入外部因素:纳入更多外部因素,如竞争对手信息、经济指标等,以进一步提升预测精度。
-
优化超参数调优:通过更广泛的超参数搜索和交叉验证,进一步提升模型泛化性能。
最终,该模型可广泛应用于库存管理、市场营销以及生产计划等多种业务场景。