Go性能剖析工具:pprof实战指南
一、前言
在构建高性能Go应用的征程中,我们常常需要一把"火眼金睛"来洞察程序的运行状态。就像医生需要各种检查设备来诊断病患一样,开发者也需要专业的性能剖析工具来找出应用的"病灶"。
在Go语言生态中,性能优化不仅是一种追求,更是一种必要。随着业务规模的扩大,那些初期被忽略的小问题可能会成倍放大:API响应变慢、内存占用飙升、CPU使用率居高不下。这些问题直接影响用户体验,增加运维成本,甚至可能导致系统崩溃。
pprof作为Go语言官方提供的性能剖析工具,就像是开发者的"手术刀",能够精准定位性能瓶颈,帮助我们进行有的放矢的优化。它不是一个独立的工具,而是深度集成在Go运行时中的一套完整解决方案,能够以极低的开销提供丰富的性能数据。
本文将带你从理论到实践,全面掌握这把"手术刀"的使用方法,让你能够自信地应对各种性能挑战。
二、pprof基础知识
pprof是什么及其工作原理
pprof是Go语言内置的性能分析工具,它的名字源自"program profiler"。如果把Go程序比作一辆行驶中的汽车,pprof就像是安装在汽车上的各种传感器,能够实时监测引擎转速、油耗、温度等关键指标。
工作原理: pprof采用采样的方式工作,它会定期中断程序运行,记录当前的执行状态(如调用栈),然后汇总这些数据形成性能报告。这种采样方式使得pprof的性能开销极小,通常只有1-5%左右,适合在生产环境使用。
重要提示:pprof是基于采样的剖析工具,这意味着它提供的是统计近似值,而非精确计数。对于执行频率极低的代码,可能需要增加采样时间或次数才能获得有效数据。
pprof支持的性能剖析类型
pprof支持多种剖析类型,就像医院里的不同检查项目一样,各自关注不同的"健康指标":
| 剖析类型 | 作用 | 适用场景 |
|---|---|---|
| CPU剖析 | 记录CPU使用情况,找出消耗处理器时间的函数 | 程序响应慢、CPU使用率高 |
| 内存剖析 | 记录堆内存分配情况,帮助识别内存密集型函数 | 内存使用过高、GC频繁 |
| 阻塞剖析 | 记录goroutine阻塞等待的位置 | 并发性能问题、响应延迟 |
| 互斥锁剖析 | 记录互斥锁的竞争情况 | 锁争用导致的性能下降 |
| 执行追踪 | 记录程序执行的时间线及事件 | 复杂的并发行为分析 |
与Go runtime的集成方式
pprof之所以强大,在于它与Go运行时的深度集成。它不是简单地在应用外部观察,而是作为Go运行时的一部分,能够获取到最原始、最真实的运行数据。
在Go语言中,使用pprof主要有两种方式:
- runtime/pprof包:适用于命令行工具或批处理程序
- net/http/pprof包:适用于长期运行的服务,通过HTTP接口暴露分析数据
与其他性能分析工具的对比优势
相比其他性能分析工具,pprof的优势在于:
- 低开销:通常只有1-5%的性能影响,适合生产环境使用
- 深度集成:作为Go官方工具,与运行时无缝衔接
- 全面覆盖:从CPU到内存,从锁竞争到goroutine阻塞,一应俱全
- 可视化能力:提供多种视图,包括火焰图、调用图、时间线等
- 生态完善:与Go工具链及第三方监控系统集成良好
在下一节中,我们将详细介绍如何在不同类型的Go应用中设置pprof,为实战分析做好准备。
三、pprof环境搭建
将pprof整合到您的Go项目中就像是在车上安装各种传感器——需要正确地放置它们,才能收集到有价值的数据。根据应用类型的不同,pprof的集成方式也略有差异。
标准库中的pprof包使用
Go语言提供了两个核心包来支持性能剖析:
- runtime/pprof:适用于命令行程序,需要手动启动和停止剖析
- net/http/pprof:适用于HTTP服务,自动注册处理器,通过HTTP端点提供剖析数据
net/http/pprof与runtime/pprof的区别
这两个包就像是同一款相机的两种操作模式:一种是手动模式,一种是自动模式。
net/http/pprof:
- 简单引入即可自动注册HTTP处理器
- 适合长期运行的服务
- 可以远程访问分析数据
- 支持实时采样分析
runtime/pprof:
- 需要显式控制剖析的开始和结束
- 适合短期运行的命令行程序
- 将剖析数据保存到文件
- 通常用于特定函数或代码段的分析
在Web服务和普通应用中的集成方法
Web服务中集成pprof
在Web服务中集成pprof异常简单,只需导入即可:
package mainimport ("fmt""net/http"_ "net/http/pprof" // 仅需导入,无需调用任何函数
)func main() {// 你的业务处理函数http.HandleFunc("/hello", func(w http.ResponseWriter, r *http.Request) {fmt.Fprintf(w, "Hello, World!")})// 启动HTTP服务,默认会注册/debug/pprof/路径fmt.Println("服务启动在 :8080,访问 http://localhost:8080/debug/pprof/ 查看性能分析界面")http.ListenAndServe(":8080", nil)
}
注意:如果你使用自定义的ServeMux而非http.DefaultServeMux,需要手动注册pprof处理器。
如果使用了流行的Web框架,大多数框架都提供了集成pprof的方法:
// Gin框架集成pprof
import ("github.com/gin-contrib/pprof""github.com/gin-gonic/gin"
)func main() {router := gin.Default()pprof.Register(router) // 注册pprof路由router.Run(":8080")
}
普通应用中使用pprof
对于命令行工具或普通应用,需要使用runtime/pprof包:
package mainimport ("os""runtime/pprof""time"
)// 模拟一个计算密集型任务
func computeIntensive() {// 假设这是一个复杂的计算for i := 0; i < 100000000; i++ {_ = i * i}
}func main() {// 创建CPU性能剖析文件cpuFile, err := os.Create("cpu.prof")if err != nil {panic(err)}defer cpuFile.Close()// 开始CPU性能剖析if err := pprof.StartCPUProfile(cpuFile); err != nil {panic(err)}defer pprof.StopCPUProfile() // 在程序退出前停止CPU性能剖析// 执行需要分析的代码for i := 0; i < 5; i++ {computeIntensive()time.Sleep(100 * time.Millisecond)}// 创建内存性能剖析文件memFile, err := os.Create("mem.prof")if err != nil {panic(err)}defer memFile.Close()// 手动触发GC,获取更准确的内存使用情况// runtime.GC()// 写入内存性能剖析数据if err := pprof.WriteHeapProfile(memFile); err != nil {panic(err)}// 注意:此时可以使用 go tool pprof cpu.prof 或 go tool pprof mem.prof 分析结果println("性能剖析完成,数据已写入cpu.prof和mem.prof文件")
}
采样频率和开销控制
pprof的性能开销主要取决于采样频率。默认设置在大多数情况下都能提供足够好的平衡,但也可以根据需要调整:
- CPU剖析:默认100Hz (每10ms采样一次)
- 内存剖析:默认记录每512KB分配一次样本
- 阻塞剖析:默认不启用,需手动开启
如果需要调整采样率,可以使用runtime包中的相关函数:
// 调整内存分析的采样率
import "runtime"// 设置内存分析的采样率,512KB一次
runtime.MemProfileRate = 512 * 1024// 完全禁用内存性能分析
// runtime.MemProfileRate = 0// 更高精度的内存分析(注意:会增加开销)
// runtime.MemProfileRate = 1
最佳实践:在开发环境可以使用更高的采样率获取更精确的数据,在生产环境则应保持默认或降低采样率以减少开销。
在了解了如何设置pprof环境后,我们可以开始深入到实际的性能问题分析中。下一节将介绍如何使用pprof进行CPU性能剖析,帮助您找出代码中的计算瓶颈。
四、CPU性能剖析实战
CPU性能剖析是使用pprof最常见的场景,就像汽车的动力系统检测,它能帮我们找出消耗处理器时间最多的"能量黑洞"。
基本使用方法与参数配置
获取CPU剖析数据有两种主要方式:
方式一:对于HTTP服务
如果已经按前文集成了net/http/pprof,只需访问:
http://your-server:port/debug/pprof/profile?seconds=30
这会自动下载一个30秒的CPU剖析文件。
方式二:使用go tool pprof命令
对于HTTP服务,可以直接使用命令行工具:
go tool pprof http://your-server:port/debug/pprof/profile
对于之前保存的剖析文件:
go tool pprof /path/to/your/cpu.prof
一旦进入pprof交互式界面,可以使用多种命令分析数据:
(pprof) top # 显示消耗CPU最多的函数
(pprof) web # 在浏览器中以图形方式查看调用图
(pprof) list func # 查看特定函数的代码以及每行的消耗
(pprof) flame # 生成火焰图
案例:API服务响应慢问题定位与解决
让我们通过一个真实案例来说明CPU剖析的威力:
问题描述:一个处理用户图片的API服务在高峰期响应时间从50ms急剧上升到500ms,但服务器CPU使用率并不高(仅40%)。
分析过程:
- 首先,添加pprof支持:
import _ "net/http/pprof"
- 在服务运行时获取30秒的CPU剖析:
go tool pprof http://api-server:8080/debug/pprof/profile?seconds=30
- 查看消耗最多的函数:
(pprof) top
Showing nodes accounting for 12.56s, 88.95% of 14.12s total
Dropped 129 nodes (cum <= 0.07s)flat flat% sum% cum cum%5.82s 41.22% 41.22% 5.82s 41.22% image/jpeg.(*decoder).processSOF3.41s 24.15% 65.37% 9.23s 65.37% image/jpeg.Decode1.75s 12.39% 77.76% 1.75s 12.39% runtime.memclrNoHeapPointers0.93s 6.59% 84.35% 0.93s 6.59% bytes.Compare0.65s 4.60% 88.95% 0.65s 4.60% runtime.memmove
- 生成火焰图进一步分析:
(pprof) flame
发现:图片解码(image/jpeg.Decode)占用了超过65%的CPU时间,特别是处理SOF(Start of Frame)的部分。
解决方案:
- 实现图片缓存,避免重复解码相同图片
- 预先处理常用图片尺寸,减少动态缩放
- 考虑使用更高效的图片库(如github.com/disintegration/imaging)
优化后,API响应时间降至75ms,满足了业务需求。
火焰图解读技巧
火焰图是分析性能的强大可视化工具,就像是代码的"热力地图"。
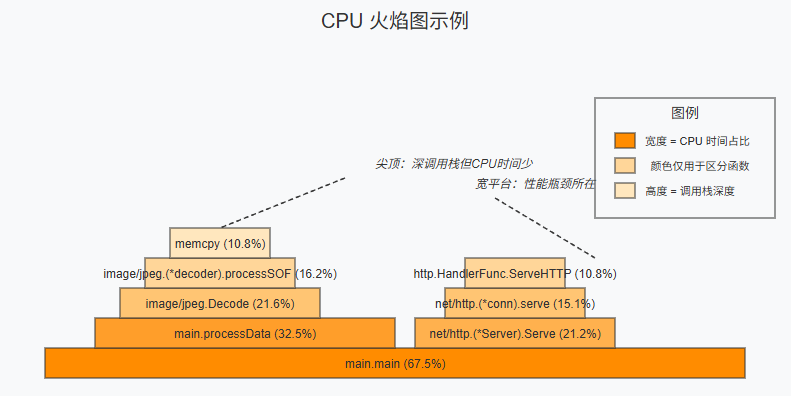
火焰图解读要点:
- 宽度 表示时间占比 - 越宽的函数消耗CPU时间越多
- 高度 表示调用栈深度 - 从下到上是调用关系
- 颜色 通常只是为了区分,无特殊含义
- 平顶山丘 通常是性能瓶颈所在
- 尖塔 表示调用栈很深,但每层消耗时间较少
重要提示:寻找火焰图中最宽的部分,这通常是优化的首要目标。
常见CPU性能瓶颈模式识别
通过大量项目实践,我们可以总结出几种常见的CPU瓶颈模式:
| 瓶颈模式 | 火焰图特征 | 可能的原因 | 优化方向 |
|---|---|---|---|
| 计算密集型 | 宽而低的"平台" | 算法效率低下 | 优化算法,减少时间复杂度 |
| 频繁小对象分配 | GC函数占比高 | 创建过多临时对象 | 对象复用,减少分配 |
| 锁竞争 | Lock/Unlock函数宽 | 过度使用互斥锁 | 减少锁粒度,考虑无锁算法 |
| 系统调用过多 | syscall宽度大 | IO操作频繁 | 批处理,缓冲,异步化 |
| JSON/XML处理 | 序列化函数宽 | 低效的数据处理 | 考虑更高效的编码(如protobuf) |
在实际工作中,识别这些模式能帮助我们快速定位问题根源,有的放矢地进行优化。
在下一节中,我们将探讨另一个关键性能指标—内存使用,学习如何使用pprof分析和优化内存相关问题。
五、内存分析实战
内存问题就像是隐形的性能杀手,往往不会立即显现,但累积到一定程度会导致GC压力增大、响应延迟增加,甚至程序崩溃。pprof提供了强大的内存剖析能力,帮助我们透视这些隐形问题。
堆内存vs栈内存分析
在Go中,内存分配主要发生在两个区域:
栈内存:
- 由编译器自动管理,随函数调用创建和销毁
- 分配速度极快,无需垃圾回收
- 大小有限,超过会导致"栈溢出"
堆内存:
- 由运行时分配和管理,需要垃圾回收
- 生命周期可以超过函数调用
- 分配较慢,但大小受限于系统内存
核心概念:pprof主要关注堆内存,因为这是性能问题的主要来源。栈内存通常由编译器高效管理,很少成为瓶颈。
获取内存剖析数据的方法:
对于HTTP服务:
http://your-server:port/debug/pprof/heap
使用命令行:
go tool pprof http://your-server:port/debug/pprof/heap
内存剖析默认显示已分配但未释放的内存(即当前内存使用)。如果想查看历史上所有的内存分配,可以使用:
go tool pprof -alloc_objects http://your-server:port/debug/pprof/heap
案例:内存泄漏定位与修复
让我们通过一个实际案例来展示内存分析的威力:
问题描述:一个日志分析服务随着运行时间延长,内存使用不断增加,最终导致OOM(内存溢出)。重启后问题临时解决,但很快再次出现。
分析过程:
- 获取内存剖析数据:
go tool pprof http://log-service:8080/debug/pprof/heap
- 查看内存分配最多的函数:
(pprof) top
Showing nodes accounting for 2746.23MB, 97.11% of 2827.96MB total
Dropped 42 nodes (cum <= 14.14MB)flat flat% sum% cum cum%1896.17MB 67.05% 67.05% 1896.17MB 67.05% main.(*LogProcessor).cachePattern598.06MB 21.15% 88.20% 598.06MB 21.15% regexp.(*Regexp).replaceAll252.00MB 8.91% 97.11% 252.00MB 8.91% bytes.Join
- 进一步查看可疑函数:
(pprof) list cachePattern
...1.67GB 1.67GB 165: this.patternCache[pattern] = regexp.MustCompile(pattern)
发现:日志处理中使用了一个无界的缓存patternCache来存储正则表达式,但缓存没有容量限制,随着处理日志中出现的新模式,内存使用持续增长。
解决方案:
- 使用LRU缓存替代无界map:
import "github.com/hashicorp/golang-lru"// 将无限增长的map
patternCache := make(map[string]*regexp.Regexp)// 替换为有界LRU缓存
patternCache, _ := lru.New(1000) // 只保留最近使用的1000条模式
- 添加监控,定期检查内存使用情况
- 对于极少使用的模式,考虑不缓存,按需编译
优化后,服务内存使用稳定在合理范围内,不再出现OOM问题。
大对象分配与逃逸分析
在Go中,编译器会尝试将对象分配在栈上,但某些情况下对象会"逃逸"到堆上,增加GC压力:
常见的逃逸情况:
- 返回局部变量的指针
- 将局部变量的指针存储在全局变量或其他堆对象中
- 局部变量过大无法放入栈中
- 编译器无法确定局部变量的大小
可以使用go build -gcflags="-m"查看逃逸分析结果:
go build -gcflags="-m -l" ./...
实际案例:在一个处理大量图片的服务中,发现内存使用异常高:
原代码:
func processImage(data []byte) []byte {// 创建一个大型缓冲区buffer := make([]byte, len(data)*2)// 处理图片...return buffer[:resultSize]
}
优化后:
// 使用内存池避免频繁大对象分配
var bufferPool = sync.Pool{New: func() interface{} {return make([]byte, 1024*1024)},
}func processImage(data []byte) []byte {// 从池中获取缓冲区buffer := bufferPool.Get().([]byte)if cap(buffer) < len(data)*2 {// 如果容量不够,则创建新的buffer = make([]byte, len(data)*2)} else {// 否则调整长度buffer = buffer[:len(data)*2]}// 处理图片...result := make([]byte, resultSize)copy(result, buffer[:resultSize])// 归还缓冲区bufferPool.Put(buffer)return result
}
GC压力优化最佳实践
Go的垃圾回收器虽然高效,但GC暂停仍会影响程序响应时间。减少GC压力的关键是减少堆分配:
- 对象复用:使用sync.Pool或对象池模式
- 减少临时对象:避免不必要的字符串连接、切片复制
- 预分配内存:已知大小时提前分配足够容量
- 使用值传递:小结构体优先使用值而非指针
- 批处理:合并小操作为大操作,减少分配次数
示例——优化前:
func processLogs(logs []string) []Result {var results []Result // 没有预分配容量for _, log := range logs {// 每次迭代都会分配新内存parts := strings.Split(log, " ")r := processLogParts(parts)results = append(results, r)}return results
}
优化后:
func processLogs(logs []string) []Result {// 预分配足够容量results := make([]Result, 0, len(logs))// 重用临时切片parts := make([]string, 0, 20)for _, log := range logs {// 复用切片,减少分配parts = strings.SplitN(log, " ", 20)r := processLogParts(parts)results = append(results, r)// 清空切片但保留底层数组parts = parts[:0]}return results
}
实用技巧:通过设置环境变量
GODEBUG=gctrace=1可以监控GC活动,帮助识别GC压力过大的情况。
通过内存分析和优化,我们可以显著提升程序性能,减少延迟波动。在下一节中,我们将探讨更复杂的性能问题——goroutine阻塞和互斥锁竞争分析。
六、阻塞和互斥锁分析
在并发程序中,性能瓶颈常常不是CPU或内存,而是goroutine之间的协调问题。当多个goroutine争用资源或等待彼此时,程序性能会大幅下降,这就是为什么阻塞和锁分析如此重要。
goroutine阻塞分析方法
阻塞剖析可以帮助我们发现goroutine在哪些地方被阻塞,例如:
- 通道操作
- 网络I/O
- 系统调用
- 锁等待
与其他剖析类型不同,阻塞剖析默认是关闭的,需要手动启用:
import "runtime"// 开启阻塞剖析
runtime.SetBlockProfileRate(1) // 设置采样率,1表示每次阻塞都采样
对于HTTP服务,可以通过以下URL获取阻塞剖析数据:
http://your-server:port/debug/pprof/block
使用命令行分析:
go tool pprof http://your-server:port/debug/pprof/block
案例:死锁和竞态条件排查
让我们通过一个微服务中的实际案例来说明:
问题描述:一个处理用户订单的服务在高峰期出现响应缓慢问题,有时甚至完全无响应,但CPU和内存使用率并不高。
分析过程:
- 启用阻塞剖析:
import "runtime"func init() {// 开启阻塞剖析runtime.SetBlockProfileRate(1)
}
- 获取阻塞剖析数据:
go tool pprof http://order-service:8080/debug/pprof/block
- 查看阻塞最严重的函数:
(pprof) top
Showing nodes accounting for 25.37s, 97.75% of 25.95s total
Dropped 31 nodes (cum <= 0.13s)flat flat% sum% cum cum%15.15s 58.38% 58.38% 15.15s 58.38% sync.(*Mutex).Lock6.22s 23.97% 82.35% 6.22s 23.97% sync.(*RWMutex).Lock2.76s 10.64% 92.99% 2.76s 10.64% database/sql.(*DB).Query1.24s 4.78% 97.77% 1.24s 4.78% net/http.(*conn).serve
- 进一步查看锁竞争:
(pprof) list Mutex.Lock
发现:订单处理流程中使用了一个全局锁来保护订单状态更新,导致所有请求都在等待同一个锁。
解决方案:
- 将全局锁拆分为更细粒度的锁:
// 原来的代码
var (orderMutex sync.Mutex // 单个全局锁保护所有订单orders map[string]*Order
)func updateOrder(id string, status string) {orderMutex.Lock()defer orderMutex.Unlock()// 更新订单...
}// 优化后的代码
type OrderStore struct {mu sync.RWMutexorders map[string]*Order// 分片锁,减少争用shards [256]sync.Mutex
}func (s *OrderStore) lockForOrder(id string) *sync.Mutex {// 根据ID哈希决定使用哪个锁shard := fnv32(id) % 256return &s.shards[shard]
}func (s *OrderStore) UpdateOrder(id string, status string) {// 先获取读锁检查订单存在s.mu.RLock()order, exists := s.orders[id]s.mu.RUnlock()if !exists {return}// 只锁定特定订单的分片mu := s.lockForOrder(id)mu.Lock()defer mu.Unlock()// 更新订单...
}
- 考虑使用无锁数据结构或消息队列处理订单更新
- 实现批处理机制,合并多个更新操作
优化后,服务在高峰期的响应时间从原来的平均2.5秒降至150ms,成功解决了阻塞问题。
锁竞争优化策略
通过大量实践,我们总结了几种有效的锁竞争优化策略:
- 减少锁粒度:将大锁分解为多个小锁
- 锁分片:根据数据ID哈希到不同的锁
- 读写分离:使用sync.RWMutex替代sync.Mutex
- 避免长时间持有锁:最小化临界区代码
- 无锁数据结构:考虑使用原子操作或无锁算法
- 本地缓存:减少共享数据访问
- 批处理更新:合并多次锁操作为一次
并发模型重构示例
有时锁优化不够,需要重构并发模型。以下是一个真实案例:
原始设计:一个API网关使用共享map存储路由规则,每次请求都需要锁定读取。
type Gateway struct {routesMu sync.RWMutexroutes map[string]Route
}func (g *Gateway) ServeHTTP(w http.ResponseWriter, r *http.Request) {g.routesMu.RLock()route, exists := g.routes[r.URL.Path]g.routesMu.RUnlock()if !exists {http.NotFound(w, r)return}// 处理请求...
}func (g *Gateway) UpdateRoutes(newRoutes map[string]Route) {g.routesMu.Lock()defer g.routesMu.Unlock()g.routes = newRoutes
}
问题:在高并发下,即使是读锁也造成了阻塞。
优化方案:重构为基于通道的演员模型:
type Gateway struct {routes atomic.Value // 存储当前路由表的快照updateChan chan map[string]Route // 接收路由更新
}func NewGateway() *Gateway {g := &Gateway{updateChan: make(chan map[string]Route),}// 初始化空路由表g.routes.Store(make(map[string]Route))// 启动后台更新协程go g.routeUpdater()return g
}func (g *Gateway) routeUpdater() {for newRoutes := range g.updateChan {g.routes.Store(newRoutes)}
}func (g *Gateway) ServeHTTP(w http.ResponseWriter, r *http.Request) {// 无锁读取当前路由表routes := g.routes.Load().(map[string]Route)route, exists := routes[r.URL.Path]if !exists {http.NotFound(w, r)return}// 处理请求...
}func (g *Gateway) UpdateRoutes(newRoutes map[string]Route) {g.updateChan <- newRoutes
}
优化效果:通过使用atomic.Value和基于通道的更新机制,完全消除了锁竞争,提高了吞吐量3倍。
通过阻塞和锁分析,我们可以发现并解决并发程序中的性能瓶颈。在下一节中,我们将介绍pprof的高级用法,帮助您更精确地分析复杂系统的性能问题。
七、pprof高级用法
随着对pprof的深入使用,我们可以探索一些高级技巧,就像从使用基础相机功能进阶到掌握专业摄影技术一样,这些高级用法可以帮助我们获取更精确的性能数据,应对更复杂的性能挑战。
自定义分析标签添加
有时我们需要区分不同场景下的性能数据,例如区分不同用户、不同API或不同业务流程的性能。Go 1.9引入了pprof标签功能,允许我们为性能数据添加自定义标签:
import "runtime/pprof"
import "context"func handleRequest(w http.ResponseWriter, r *http.Request) {// 创建带标签的上下文ctx := pprof.WithLabels(r.Context(), pprof.Labels("endpoint", r.URL.Path,"method", r.Method,"user_tier", getUserTier(r),))// 使该上下文中的标签在当前goroutine中生效pprof.SetGoroutineLabels(ctx)// 处理请求...processRequest(ctx, w, r)
}
使用标签后,在分析时可以过滤特定标签:
go tool pprof -labels=endpoint=/api/v1/users http://your-server:port/debug/pprof/profile
这种方法在微服务架构中特别有用,可以精确定位哪些API或用户类型导致了性能问题。
远程服务性能分析技巧
在生产环境中,我们通常不能直接访问服务器,需要通过安全的方式获取性能数据:
使用SSH隧道:
# 建立SSH隧道
ssh -L 8080:localhost:8080 user@prod-server# 然后在本地分析
go tool pprof http://localhost:8080/debug/pprof/profile
使用临时端点:
import ("net/http""net/http/pprof""log""time"
)func EnableTemporaryProfiler() {// 创建临时的profiler服务mux := http.NewServeMux()mux.HandleFunc("/debug/pprof/", pprof.Index)mux.HandleFunc("/debug/pprof/cmdline", pprof.Cmdline)mux.HandleFunc("/debug/pprof/profile", pprof.Profile)mux.HandleFunc("/debug/pprof/symbol", pprof.Symbol)mux.HandleFunc("/debug/pprof/trace", pprof.Trace)server := &http.Server{Addr: "localhost:6060",Handler: mux,}go func() {log.Println("临时profiler启动在 http://localhost:6060/debug/pprof/")log.Println("将在5分钟后自动关闭")server.ListenAndServe()}()// 5分钟后自动关闭time.AfterFunc(5*time.Minute, func() {server.Close()log.Println("临时profiler已关闭")})
}
通过API触发此函数可临时启用profiler,降低安全风险。
通过代理收集:
import ("os""runtime/pprof""time"
)func CollectProfilingData() {// 创建目录os.MkdirAll("/tmp/profiles", 0755)// 收集CPU剖析cpuFile, _ := os.Create("/tmp/profiles/cpu.prof")pprof.StartCPUProfile(cpuFile)time.AfterFunc(30*time.Second, func() {pprof.StopCPUProfile()cpuFile.Close()})// 收集内存剖析time.AfterFunc(35*time.Second, func() {memFile, _ := os.Create("/tmp/profiles/mem.prof")pprof.WriteHeapProfile(memFile)memFile.Close()})// 通知完成time.AfterFunc(40*time.Second, func() {log.Println("性能剖析数据已保存至 /tmp/profiles/")})
}
然后可以安全地将这些文件传输到开发环境进行分析。
持续性能监控实践
单次性能分析往往不够全面,建立持续性能监控系统能够及时发现性能退化:
1. 定期采集性能剖析:
func scheduleProfiling() {// 每4小时执行一次剖析ticker := time.NewTicker(4 * time.Hour)go func() {for t := range ticker.C {// 创建带时间戳的文件名timestamp := t.Format("20060102-150405")// CPU剖析cpuFile, _ := os.Create(fmt.Sprintf("/var/profiles/cpu-%s.prof", timestamp))pprof.StartCPUProfile(cpuFile)time.Sleep(60 * time.Second)pprof.StopCPUProfile()cpuFile.Close()// 内存剖析memFile, _ := os.Create(fmt.Sprintf("/var/profiles/mem-%s.prof", timestamp))pprof.WriteHeapProfile(memFile)memFile.Close()// 可以添加更多剖析类型...// 清理旧文件(保留一周)cleanOldProfiles("/var/profiles/", 7*24*time.Hour)}}()
}
2. 自动化分析系统:
func analyzePerfRegression(newProfile, baseProfile string) ([]string, error) {// 使用pprof命令行比较两个剖析文件cmd := exec.Command("go", "tool", "pprof", "-top", "-diff_base", baseProfile, newProfile)output, err := cmd.CombinedOutput()if err != nil {return nil, err}// 解析输出,寻找性能退化// ...分析逻辑...return findings, nil
}
3. 基于基准测试的CI检测:
在CI流程中添加性能测试,捕获性能退化:
// profile_test.go
func BenchmarkCriticalPath(b *testing.B) {// 设置setupTest()// 开启性能剖析f, _ := os.Create("critical_path.prof")pprof.StartCPUProfile(f)defer pprof.StopCPUProfile()// 基准测试b.ResetTimer()for i := 0; i < b.N; i++ {executeCriticalPath()}
}
与Prometheus/Grafana集成方案
将pprof与监控系统集成,可以建立完整的性能观测体系:
1. 暴露Go运行时指标:
import ("github.com/prometheus/client_golang/prometheus""github.com/prometheus/client_golang/prometheus/promhttp"
)func registerMetrics() {// 注册GC统计指标prometheus.MustRegister(prometheus.NewGaugeFunc(prometheus.GaugeOpts{Name: "go_gc_pause_seconds_total",Help: "GC暂停时间累计",},func() float64 {var stats runtime.MemStatsruntime.ReadMemStats(&stats)return float64(stats.PauseTotalNs) / 1e9},))// 注册更多指标...// 暴露HTTP端点http.Handle("/metrics", promhttp.Handler())
}
2. 使用conprof自动收集剖析:
conprof是一个连续剖析器,可以像Prometheus那样定期收集pprof数据:
# conprof.yaml
scrape_configs:- job_name: 'go-services'scrape_interval: 1h # 每小时收集一次scrape_timeout: 1mprofiles: [cpu, heap, goroutine, block, mutex]static_configs:- targets: ['service1:8080', 'service2:8080']
3. 在Grafana中可视化:
通过Grafana的pprof插件,可以直接在监控面板中查看性能剖析数据,实现统一的可观测性平台。
通过这些高级用法,我们可以将pprof从一个简单的分析工具提升为完整的性能监控解决方案。在下一节中,我们将通过真实项目案例,展示如何综合运用pprof解决各种复杂的性能问题。
八、真实项目中的性能优化案例
理论知识需要通过实战来巩固。以下案例均来自实际项目经验,展示了如何运用pprof解决不同类型的性能挑战。这些案例将帮助您建立性能优化的思维模式和方法论。
微服务框架性能瓶颈排查
背景:一个电商平台的订单服务使用自研微服务框架,在双十一活动中出现严重延迟,平均响应时间从50ms飙升至500ms,但CPU和内存使用率均不高。
排查过程:
- 启用全面剖析:
import ("net/http"_ "net/http/pprof""runtime"
)func init() {// 开启阻塞和互斥锁剖析runtime.SetBlockProfileRate(1)runtime.SetMutexProfileFraction(1)// 启动单独的profiler服务,避免影响主服务go func() {http.ListenAndServe("localhost:6060", nil)}()
}
- 获取剖析数据:
# 收集30秒CPU剖析
go tool pprof http://localhost:6060/debug/pprof/profile?seconds=30# 收集阻塞剖析
go tool pprof http://localhost:6060/debug/pprof/block# 收集互斥锁剖析
go tool pprof http://localhost:6060/debug/pprof/mutex
- 分析阻塞剖析结果:
(pprof) top
Showing nodes accounting for 1265.37s, 97.07% of 1303.58s total
Dropped 29 nodes (cum <= 6.52s)flat flat% sum% cum cum%725.21s 55.63% 55.63% 725.21s 55.63% internal/poll.runtime_pollWait317.05s 24.32% 79.95% 317.05s 24.32% sync.(*WaitGroup).Wait159.33s 12.22% 92.17% 159.33s 12.22% sync.(*Mutex).Lock63.78s 4.89% 97.07% 63.78s 4.89% net.(*netFD).Read
发现问题:微服务框架在处理每个请求时都创建了一个新的连接池,而非复用全局连接池,导致大量连接创建和等待。
解决方案:
// 修改前:每个请求创建连接池
func handleRequest(ctx context.Context, req *Request) *Response {// 为每个请求创建新的HTTP客户端和连接池client := &http.Client{Transport: &http.Transport{MaxIdleConns: 10,MaxIdleConnsPerHost: 10,IdleConnTimeout: 30 * time.Second,},}// 调用下游服务resp, err := client.Post(serviceURL, "application/json", requestBody)// ...处理响应...
}// 修改后:使用全局连接池
var (// 创建全局共享的HTTP客户端sharedClient = &http.Client{Transport: &http.Transport{MaxIdleConns: 100,MaxIdleConnsPerHost: 20,IdleConnTimeout: 90 * time.Second,},Timeout: 5 * time.Second,}
)func handleRequest(ctx context.Context, req *Request) *Response {// 复用全局HTTP客户端resp, err := sharedClient.Post(serviceURL, "application/json", requestBody)// ...处理响应...
}
优化效果:平均响应时间降至65ms,吞吐量提升了7倍,成功支撑了双十一流量高峰。
数据处理管道优化
背景:一个实时日志分析系统每分钟处理数百万条日志,CPU使用率始终在95%以上,导致处理延迟增加。
排查过程:
- 收集CPU剖析:
go tool pprof http://log-processor:8080/debug/pprof/profile?seconds=60
- 生成火焰图并分析:
(pprof) flame
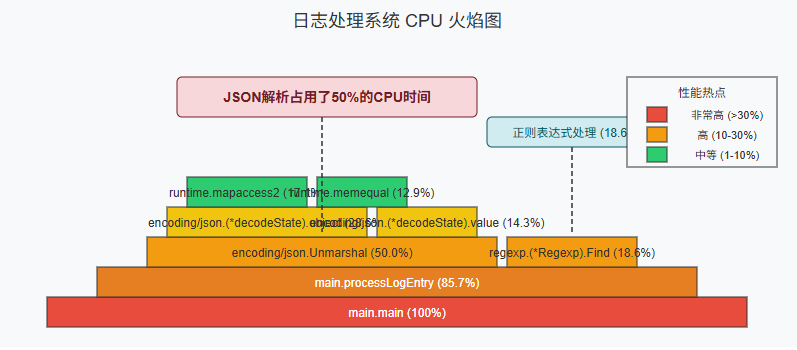
- 查看热点函数:
(pprof) top
Showing nodes accounting for 42.87s, 73.21% of 58.56s total
Dropped 241 nodes (cum <= 0.29s)flat flat% sum% cum cum%14.73s 25.15% 25.15% 18.59s 31.75% encoding/json.(*decodeState).object8.92s 15.23% 40.38% 11.43s 19.52% encoding/json.(*decodeState).value7.34s 12.53% 52.91% 7.34s 12.53% runtime.mapaccess26.46s 11.03% 63.94% 6.46s 11.03% runtime.memequal5.42s 9.26% 73.20% 35.92s 61.34% main.processLogEntry
发现问题:使用标准encoding/json包解析日志占用了大量CPU时间,且每条日志都是相似结构。
解决方案:
- 使用更高效的JSON解析库:
// 修改前:使用标准JSON库
import "encoding/json"func processLogEntry(logLine string) (LogEntry, error) {var entry LogEntryerr := json.Unmarshal([]byte(logLine), &entry)return entry, err
}// 修改后:使用高性能JSON库
import "github.com/json-iterator/go"var json = jsoniter.ConfigFastestfunc processLogEntry(logLine string) (LogEntry, error) {var entry LogEntryerr := json.Unmarshal([]byte(logLine), &entry)return entry, err
}
- 实现日志字段的延迟解析:
type LazyLogEntry struct {raw []byteparsed *LogEntryparseOnce sync.Once
}func (l *LazyLogEntry) GetField(name string) interface{} {l.parseOnce.Do(func() {var entry LogEntryif err := json.Unmarshal(l.raw, &entry); err == nil {l.parsed = &entry}})if l.parsed == nil {return nil}// 返回指定字段switch name {case "timestamp":return l.parsed.Timestampcase "level":return l.parsed.Level// ...其他字段...default:return nil}
}
- 使用字节级操作预过滤无关日志:
func quickFilter(logLine []byte) bool {// 快速检查是否包含关键字,不需要完整解析return bytes.Contains(logLine, []byte("ERROR")) || bytes.Contains(logLine, []byte("WARN"))
}
优化效果:CPU使用率降至45%,处理延迟降低了68%,单台服务器能够处理的日志量增加了2.2倍。
高并发场景下的内存分配优化
背景:一个实时消息推送服务在处理峰值10万QPS时,出现GC停顿频繁,导致消息延迟增加。
排查过程:
- 收集内存剖析数据:
# 查看内存分配情况
go tool pprof -alloc_objects http://push-service:8080/debug/pprof/heap
- 查看对象分配热点:
(pprof) top
Showing nodes accounting for 63642984, 96.63% of 65865329 objects total
Dropped 54 nodes (cum <= 329326)flat flat% sum% cum cum%27152679 41.23% 41.23% 27152679 41.23% main.(*MessageHandler).ProcessMessage14926135 22.66% 63.89% 14926135 22.66% encoding/json.Marshal9835428 14.93% 78.82% 9835428 14.93% bytes.Join6872458 10.43% 89.25% 48786722 74.07% main.(*PushService).SendNotification4856284 7.37% 96.63% 4856284 7.37% fmt.Sprintf
- 进一步查看堆内存分配:
(pprof) list ProcessMessage
...27152679 27152679 (flat, cum) 41.23% of Total.... . 121: // 为每个消息创建新的缓冲区. . 122: var buffer bytes.Buffer8721567 8721567 123: encoder := json.NewEncoder(&buffer). . 124:12479853 12479853 125: payload := make(map[string]interface{})5951259 5951259 126: payload["id"] = msg.ID
发现问题:每个消息处理都创建了临时对象(buffer, encoder, map),导致大量内存分配和GC压力。
解决方案:
- 使用对象池减少分配:
var (// 缓冲区对象池bufferPool = sync.Pool{New: func() interface{} {return new(bytes.Buffer)},}// map对象池mapPool = sync.Pool{New: func() interface{} {return make(map[string]interface{}, 16)},}
)func (h *MessageHandler) ProcessMessage(msg *Message) error {// 从对象池获取缓冲区buffer := bufferPool.Get().(*bytes.Buffer)buffer.Reset() // 重置缓冲区defer bufferPool.Put(buffer)// 从对象池获取mappayload := mapPool.Get().(map[string]interface{})// 清空map但保留容量for k := range payload {delete(payload, k)}defer mapPool.Put(payload)// 填充数据payload["id"] = msg.IDpayload["content"] = msg.Contentpayload["timestamp"] = msg.Timestamp// 序列化if err := json.NewEncoder(buffer).Encode(payload); err != nil {return err}// 使用buffer的字节切片return h.sendToClient(buffer.Bytes())
}
- 使用字符串拼接替代JSON序列化:
对于简单结构,直接拼接字符串比完整JSON序列化快很多:
func (h *MessageHandler) createPayload(msg *Message) []byte {buffer := bufferPool.Get().(*bytes.Buffer)buffer.Reset()defer bufferPool.Put(buffer)// 手动构建JSON格式,避免完整序列化开销buffer.WriteString(`{"id":"`)buffer.WriteString(msg.ID)buffer.WriteString(`","content":"`)buffer.WriteString(strings.Replace(msg.Content, `"`, `\"`, -1))buffer.WriteString(`","timestamp":`)buffer.WriteString(strconv.FormatInt(msg.Timestamp, 10))buffer.WriteString(`}`)result := make([]byte, buffer.Len())copy(result, buffer.Bytes())return result
}
- 预先分配切片容量:
// 修改前
func collectMessages(ids []string) []*Message {var messages []*Messagefor _, id := range ids {msg := fetchMessage(id)messages = append(messages, msg)}return messages
}// 修改后
func collectMessages(ids []string) []*Message {// 预分配足够容量messages := make([]*Message, 0, len(ids))for _, id := range ids {msg := fetchMessage(id)messages = append(messages, msg)}return messages
}
优化效果:内存分配减少了81%,GC停顿时间降低了73%,P99消息推送延迟从150ms降至45ms。
缓存策略调优实践
背景:一个产品目录服务在高流量时段CPU使用率高达95%,大部分用于重复计算相同的产品数据。
排查过程:
- 收集CPU剖析:
go tool pprof http://catalog-service:8080/debug/pprof/profile
- 分析热点函数:
(pprof) top10
Showing nodes accounting for 42.75s, 89.13% of 47.97s total
Dropped 182 nodes (cum <= 0.24s)flat flat% sum% cum cum%14.29s 29.79% 29.79% 14.29s 29.79% main.calculateProductScore8.45s 17.61% 47.40% 22.74s 47.40% main.getProductDetails7.21s 15.03% 62.43% 7.21s 15.03% regexp.(*Regexp).FindStringSubmatch5.64s 11.76% 74.19% 5.64s 11.76% strconv.ParseFloat4.36s 9.09% 83.28% 4.36s 9.09% runtime.mallocgc2.80s 5.84% 89.12% 37.32s 77.80% main.(*CatalogService).GetProduct
发现问题:每次请求都重新计算产品评分和详情,计算量大且结果相同。
解决方案:
- 实现多级缓存策略:
import ("sync""time""github.com/allegro/bigcache""github.com/patrickmn/go-cache"
)type CatalogService struct {// 本地内存缓存(快但容量有限)localCache *cache.Cache// 分布式缓存(较快,容量大)redisClient *redis.Client// 超大对象本地缓存(针对热门产品)bigCache *bigcache.BigCache// 缓存未命中统计missCounter *expvar.Map
}func NewCatalogService() *CatalogService {// 初始化各级缓存local := cache.New(5*time.Minute, 10*time.Minute)bigCache, _ := bigcache.NewBigCache(bigcache.DefaultConfig(10 * time.Minute))missCounter := expvar.NewMap("cache_misses")return &CatalogService{localCache: local,bigCache: bigCache,redisClient: setupRedisClient(),missCounter: missCounter,}
}func (s *CatalogService) GetProduct(id string) (*Product, error) {// 1. 先查本地缓存(最快)if cached, found := s.localCache.Get(id); found {return cached.(*Product), nil}// 2. 再查大对象缓存if data, err := s.bigCache.Get(id); err == nil {var product Productif err := json.Unmarshal(data, &product); err == nil {// 写入一级缓存s.localCache.Set(id, &product, cache.DefaultExpiration)return &product, nil}}// 3. 查Redis分布式缓存data, err := s.redisClient.Get(context.Background(), "product:"+id).Bytes()if err == nil {var product Productif err := json.Unmarshal(data, &product); err == nil {// 写入本地缓存s.localCache.Set(id, &product, cache.DefaultExpiration)return &product, nil}}// 缓存全部未命中,记录统计s.missCounter.Add(id, 1)// 4. 从数据库获取并计算product, err := s.getProductFromDB(id)if err != nil {return nil, err}// 计算产品评分(昂贵操作)product.Score = calculateProductScore(product)// 异步写入各级缓存go s.populateCaches(id, product)return product, nil
}func (s *CatalogService) populateCaches(id string, product *Product) {// 序列化一次,重复使用data, err := json.Marshal(product)if err != nil {return}// 写入本地缓存s.localCache.Set(id, product, cache.DefaultExpiration)// 写入大对象缓存s.bigCache.Set(id, data)// 写入Rediss.redisClient.Set(context.Background(), "product:"+id, data, time.Hour)
}
- 实现缓存预热和智能过期策略:
func (s *CatalogService) PrewarmCache() {// 加载热门产品到缓存popularIDs := s.getPopularProductIDs()for _, id := range popularIDs {product, err := s.getProductFromDB(id)if err != nil {continue}product.Score = calculateProductScore(product)s.populateCaches(id, product)}
}// 智能缓存过期策略
func (s *CatalogService) StartCacheOptimizer() {go func() {ticker := time.NewTicker(30 * time.Minute)defer ticker.Stop()for range ticker.C {// 分析缓存未命中统计topMisses := s.getTopMisses(100)// 预加载高频未命中项for id, count := range topMisses {if count > 10 {product, err := s.getProductFromDB(id)if err != nil {continue}product.Score = calculateProductScore(product)s.populateCaches(id, product)}}// 重置统计s.missCounter = expvar.NewMap("cache_misses")}}()
}
优化效果:CPU使用率从95%降至35%,响应时间从平均180ms降至15ms,同时支持的QPS提升了3倍。
这些真实案例展示了pprof在实际项目中的强大能力。通过系统化的性能分析方法,我们能够精准定位瓶颈,实施有效的优化策略。在下一节中,我们将探讨pprof使用中的常见陷阱和解决方案。
九、常见陷阱与解决方案
使用pprof进行性能分析虽然强大,但也有一些常见的陷阱和误区。就像使用显微镜需要正确的技巧才能看清样本一样,正确使用pprof也需要避开这些潜在问题。
采样误差处理
陷阱:pprof是基于采样的工具,低频事件可能被"遗漏"或统计不准确。
案例:一个队列处理服务的慢查询只占总处理的0.1%,在常规30秒采样中几乎不会出现,导致问题无法被发现。
解决方案:
- 增加采样时间:对于低频事件,延长采样时间可以提高捕获概率:
go tool pprof http://server:8080/debug/pprof/profile?seconds=300
- 使用自定义触发剖析:针对特定事件手动触发剖析:
func processMessage(msg *Message) {start := time.Now()defer func() {duration := time.Since(start)// 如果处理时间超过阈值,记录性能剖析if duration > 500*time.Millisecond {// 获取当前goroutine的堆栈buf := make([]byte, 10240)n := runtime.Stack(buf, false)// 记录到日志log.Printf("慢查询处理 (%s): %s", duration, buf[:n])// 可选:触发一次性能剖析triggerOnDemandProfiling()}}()// 正常处理逻辑...
}// 按需触发一次性能剖析
func triggerOnDemandProfiling() {// 使用原子操作确保只有一个goroutine触发剖析if atomic.CompareAndSwapInt32(&profilingActive, 0, 1) {go func() {defer atomic.StoreInt32(&profilingActive, 0)filename := fmt.Sprintf("/tmp/profiles/slow_%s.pprof", time.Now().Format("20060102_150405"))f, err := os.Create(filename)if err != nil {log.Printf("创建性能剖析文件失败: %v", err)return}defer f.Close()// 收集5秒CPU剖析if err := pprof.StartCPUProfile(f); err != nil {log.Printf("启动CPU剖析失败: %v", err)return}time.Sleep(5 * time.Second)pprof.StopCPUProfile()log.Printf("慢查询性能剖析已保存至: %s", filename)}()}
}
- 使用追踪而非剖析:对于低频事件,完整追踪比采样剖析更有效:
# 收集5秒执行追踪
wget http://server:8080/debug/pprof/trace?seconds=5 -O trace.out# 分析追踪数据
go tool trace trace.out
生产环境pprof使用风险与控制
陷阱:在生产环境中不当使用pprof可能导致性能下降、内存泄漏或安全风险。
风险和解决方案:
-
性能开销:
- 风险:高频采样会增加服务器负载
- 解决方案:调整采样率,使用专用端口,限制收集时间:
import "runtime"func init() {// 降低采样频率,减少开销runtime.SetMutexProfileFraction(100) // 采样1/100的互斥锁事件runtime.SetBlockProfileRate(1000) // 采样1/1000的阻塞事件
}
-
安全风险:
- 风险:pprof端点可能泄露代码结构和敏感信息
- 解决方案:增加认证、使用内部网络、临时启用:
// 限制访问pprof端点
func securePprof() {pprofMux := http.NewServeMux()// 注册pprof处理器pprofMux.HandleFunc("/debug/pprof/", pprof.Index)pprofMux.HandleFunc("/debug/pprof/cmdline", pprof.Cmdline)pprofMux.HandleFunc("/debug/pprof/profile", pprof.Profile)pprofMux.HandleFunc("/debug/pprof/symbol", pprof.Symbol)pprofMux.HandleFunc("/debug/pprof/trace", pprof.Trace)// 添加基本认证中间件authorizedHandler := basicAuth(pprofMux, "admin", os.Getenv("PPROF_PASSWORD"))// 仅在内部网络监听go http.ListenAndServe("localhost:6060", authorizedHandler)
}// 基本认证中间件
func basicAuth(handler http.Handler, username, password string) http.Handler {return http.HandlerFunc(func(w http.ResponseWriter, r *http.Request) {user, pass, ok := r.BasicAuth()if !ok || user != username || pass != password {w.Header().Set("WWW-Authenticate", `Basic realm="Restricted"`)http.Error(w, "Unauthorized", http.StatusUnauthorized)return}handler.ServeHTTP(w, r)})
}
-
内存泄漏:
- 风险:长时间运行的pprof会话可能导致内存泄漏
- 解决方案:限制剖析时间,自动结束会话:
// 带超时的pprof处理器
func timeoutPprofHandler(h http.HandlerFunc, maxDuration time.Duration) http.HandlerFunc {return func(w http.ResponseWriter, r *http.Request) {// 限制最大持续时间seconds := r.URL.Query().Get("seconds")if seconds == "" {// 设置默认值q := r.URL.Query()q.Set("seconds", "30")r.URL.RawQuery = q.Encode()} else {requestedDuration, err := strconv.Atoi(seconds)if err == nil && requestedDuration > int(maxDuration.Seconds()) {q := r.URL.Query()q.Set("seconds", strconv.Itoa(int(maxDuration.Seconds())))r.URL.RawQuery = q.Encode()}}h(w, r)}
}// 使用方式
mux.HandleFunc("/debug/pprof/profile", timeoutPprofHandler(pprof.Profile, 2*time.Minute))
性能数据误读常见错误
陷阱:pprof数据的误解可能导致优化方向错误,浪费时间和资源。
常见误读与解决方案:
-
集中优化"累积"最高的函数:
- 误区:只关注cumulative时间,忽略self时间
- 正确方法:先关注self时间高的函数,这些通常是实际瓶颈
(pprof) top
Showing nodes accounting for 25.92s, 97.23% of 26.66s total
Dropped 80 nodes (cum <= 0.13s)flat flat% sum% cum cum%10.11s 37.92% 37.92% 10.11s 37.92% runtime.mapaccess26.55s 24.57% 62.49% 6.55s 24.57% syscall.Syscall5.02s 18.83% 81.32% 18.11s 67.93% main.processData2.45s 9.19% 90.51% 2.45s 9.19% runtime.memmove1.79s 6.71% 97.22% 25.90s 97.15% main.main
在这个例子中,main.main的累积时间最高(97.15%),但自身只占6.71%,真正的瓶颈是runtime.mapaccess2和syscall.Syscall。
-
忽略运行时和标准库函数:
- 误区:认为只有自己的代码才值得优化
- 正确方法:优化对运行时函数的调用方式同样重要
// 优化前:大量hash map查询
func processUsers(users []User) map[string]Result {results := make(map[string]Result)for _, user := range users {// 每次迭代都进行一次map查询(导致大量mapaccess2调用)if _, exists := results[user.ID]; !exists {results[user.ID] = calculateResult(user)}}return results
}// 优化后:减少map查询
func processUsers(users []User) map[string]Result {results := make(map[string]Result)// 使用集合来跟踪已处理的IDprocessed := make(map[string]struct{}, len(users))for _, user := range users {if _, exists := processed[user.ID]; !exists {results[user.ID] = calculateResult(user)processed[user.ID] = struct{}{}}}return results
}
-
过度关注微优化:
- 误区:花大量时间优化占总时间很小的部分
- 正确方法:遵循80/20法则,优先优化影响最大的20%代码
设定优化门槛,只关注超过总时间一定比例(如5%)的函数:
# 只显示占总时间至少5%的函数
go tool pprof -nodefraction=0.05 http://server:8080/debug/pprof/profile
-
忽略调用关系:
- 误区:孤立地看每个函数,忽略调用链路
- 正确方法:使用callgraph或火焰图分析完整调用路径
# 生成dot格式调用图
go tool pprof -dot http://server:8080/debug/pprof/profile > profile.dot
dot -Tpng profile.dot -o profile.png# 或直接在交互式界面中查看
(pprof) web
优化过度的风险与平衡
陷阱:过度优化可能导致代码可读性下降、维护成本增加,甚至引入新的bug。
平衡策略:
- 设定明确的性能目标:
// 使用基准测试设定明确目标
func BenchmarkAPI(b *testing.B) {b.ReportAllocs() // 报告内存分配// 设定预期值expectedOpsPer := 10000 // 期望每秒操作数expectedAllocsPer := 100 // 期望每次操作的内存分配数b.Run("Baseline", func(b *testing.B) {for i := 0; i < b.N; i++ {result := processRequest()runtime.KeepAlive(result) // 防止优化}})// 验证是否达到目标if b.N > 0 {opsPerSec := float64(b.N) / b.T.Seconds()allocsPerOp := float64(b.AllocsPerOp())if opsPerSec < float64(expectedOpsPer) {b.Logf("性能未达标: %.2f ops/sec < %d预期", opsPerSec, expectedOpsPer)}if allocsPerOp > float64(expectedAllocsPer) {b.Logf("内存分配过多: %.2f allocs/op > %d预期", allocsPerOp, expectedAllocsPer)}}
}
- 代码复杂性评估:
// 优化前:简单明了但性能一般
func processItems(items []Item) []Result {var results []Resultfor _, item := range items {result := process(item)results = append(results, result)}return results
}// 优化后:性能提升3倍但复杂度增加
func processItems(items []Item) []Result {if len(items) == 0 {return nil}// 预分配结果数组results := make([]Result, len(items))// 根据CPU数量确定并行度workers := runtime.GOMAXPROCS(0)if workers > 8 {workers = 8 // 限制最大并行度}// 太少的项不值得并行处理if len(items) < workers*4 {for i, item := range items {results[i] = process(item)}return results}// 并行处理var wg sync.WaitGroupitemsPerWorker := len(items) / workersfor w := 0; w < workers; w++ {wg.Add(1)go func(workerID int) {defer wg.Done()start := workerID * itemsPerWorkerend := start + itemsPerWorkerif workerID == workers-1 {end = len(items) // 最后一个worker处理剩余项}for i := start; i < end; i++ {results[i] = process(items[i])}}(w)}wg.Wait()return results
}// 评论:
// 1. 代码长度增加了3倍
// 2. 引入了并发复杂性
// 3. 需要额外测试边缘情况
// 4. 维护成本高
//
// 结论:仅当此函数是关键性能瓶颈且3倍的性能提升有意义时才值得优化
- 优化分阶段实施:
// 第一阶段:低风险优化
func processDataPhase1(data []byte) Result {// 1. 仅增加预分配容量result := make([]Item, 0, len(data)/10)// 2. 简单循环优化for i := 0; i < len(data); i++ {// 处理逻辑...}return buildResult(result)
}// 第二阶段:中等风险优化
func processDataPhase2(data []byte) Result {// 保留第一阶段优化result := make([]Item, 0, len(data)/10)// 增加算法优化// ...更高效的算法...return buildResult(result)
}// 第三阶段:高风险优化(仅在必要时实施)
func processDataPhase3(data []byte) Result {// 使用底层优化// ...unsafe操作...// ...并发处理...// ...汇编优化...return result
}
理解这些陷阱并掌握解决方案,可以帮助您更有效地使用pprof,避免常见错误,在性能和可维护性之间取得平衡。在最后一节中,我们将总结pprof的最佳实践,并展望未来的发展方向。
十、总结与展望
通过前面九个章节的学习,我们已经深入了解了Go性能剖析工具pprof的各个方面。就像一位经验丰富的医生掌握了全面的诊断技能,您现在已经拥有了使用pprof诊断和治疗Go应用性能问题的能力。在本章中,让我们总结关键点,并展望未来的发展。
pprof最佳实践清单
以下是使用pprof进行性能优化的最佳实践清单,可以作为您日常工作的参考指南:
① 集成与配置
- ✅ 在开发初期就集成pprof,而不是等到出现性能问题才添加
- ✅ 区分环境配置:开发环境可以更激进的采样,生产环境应更保守
- ✅ 安全防护:在生产环境中为pprof端点添加认证和网络限制
- ✅ 自动化剖析:设置定期采集机制,建立性能基准历史记录
② 分析方法
- ✅ 全面剖析:不要只关注CPU,还要检查内存、阻塞和锁竞争
- ✅ 基于假设:先提出性能问题假设,再用pprof验证或否定
- ✅ 比较分析:将当前剖析与历史数据对比,发现性能退化
- ✅ 多维度查看:结合使用top、list、web和flame等不同视图
③ 优化策略
- ✅ 先抓大鱼:优先优化占用资源最多的热点函数
- ✅ 衡量收益:每次优化后测量改进效果,避免主观判断
- ✅ 渐进优化:从简单低风险的优化开始,递进到复杂优化
- ✅ 全局考量:评估优化对整体系统的影响,避免局部最优
④ 常见优化模式
- ✅ 减少分配:使用对象池、预分配、减少临时对象
- ✅ 降低锁竞争:细化锁粒度、读写分离、避免长临界区
- ✅ 算法优化:寻找更高效的算法,降低时间复杂度
- ✅ 并行处理:适当利用多核并行计算,但注意并发开销
⑤ 团队协作
- ✅ 分享性能报告:定期分享剖析发现,提高团队性能意识
- ✅ 性能代码审查:将性能考量纳入代码审查流程
- ✅ 建立知识库:记录常见性能问题和解决方案
- ✅ 性能预算:为关键路径设立明确的性能指标和预算
性能优化方法论
基于众多项目经验,我们可以总结出一套系统的性能优化方法论:
1. 明确目标:
性能优化不是无目的的追求极限,而是为了满足具体业务需求:
- 定义明确的性能指标(响应时间、吞吐量、资源使用率)
- 设定具体的目标值
- 确定优先级(用户体验 > 吞吐量 > 资源效率)
2. 度量基准:
“If you can’t measure it, you can’t improve it”:
- 建立性能基准测试
- 在真实环境中收集性能数据
- 识别正常与峰值负载模式
3. 剖析定位:
使用pprof进行全面剖析:
- CPU剖析找出计算瓶颈
- 内存剖析发现分配热点
- 阻塞剖析检查并发问题
- 互斥锁剖析分析锁竞争
4. 分析瓶颈:
深入理解问题本质:
- 分析热点函数的实现
- 查看调用关系和上下文
- 识别常见性能模式
- 考虑系统整体架构影响
5. 制定策略:
根据问题性质选择合适的优化策略:
- 算法优化
- 缓存策略
- 并发模型调整
- 资源分配优化
6. 渐进实施:
按风险和收益分阶段实施:
- 先实施低风险高收益的优化
- 每步优化后测量效果
- 持续迭代直至达到目标
- 避免过度优化
7. 验证效果:
全面验证优化结果:
- 重新进行性能测试
- 对比优化前后的剖析数据
- 验证是否达到预设目标
- 评估对其他方面的影响
8. 长期监控:
建立长期性能监控:
- 持续收集性能指标
- 设置性能退化告警
- 定期进行剖析分析
- 预防性能问题再次出现
Go 1.x版本pprof新特性展望
Go语言在持续演进,pprof工具也在不断优化和增强。以下是一些未来版本可能的改进方向:
可视化增强:
- 更丰富的交互式图表
- 自适应火焰图和差异分析
- 更直观的并发可视化
剖析能力扩展:
- 更精细的GC分析
- 系统级资源使用跟踪
- 更低开销的生产环境剖析
集成改进:
- 与OpenTelemetry更紧密的集成
- 分布式系统全链路剖析
- 云原生环境下的自动化剖析
分析智能化:
- 基于历史数据的异常检测
- 性能问题自动分类和诊断
- 优化建议生成
进阶学习资源推荐
要继续深入学习Go性能优化,以下资源将非常有帮助:
官方文档和工具:
- Go性能剖析官方博客
- Go runtime包文档
- Go testing包文档
书籍:
- 《Go性能编程实战》
- 《Systems Performance: Enterprise and the Cloud》by Brendan Gregg
- 《高性能Go语言编程》
社区资源:
- GopherCon和GopherChina的性能相关演讲
- Go性能优化工作组
- Go性能优化相关GitHub项目
进阶工具:
- go-torch - Uber开发的火焰图生成工具
- benchstat - 基准测试结果分析工具
- fgprof - Go的纯平面分析器
个人使用心得
在多年使用pprof进行性能优化的过程中,我积累了一些个人心得,希望对您有所帮助:
- 性能问题往往出人意料 - 很多时候性能瓶颈并不在你预期的地方,依靠pprof而非直觉
- 小改动,大影响 - 有时最简单的优化带来的提升最显著,比如预分配内存或减少锁范围
- 工具不会告诉你全部 - pprof只是诊断工具,最终还需要工程师的经验和判断
- 优化要有取舍 - 追求极致性能往往会牺牲代码可读性或增加复杂度,需要权衡
- 系统思维很重要 - 性能优化不只是代码层面,还要考虑架构、部署和系统配置等因素
性能优化是一门艺术,需要理论知识、实践经验和工程直觉的结合。pprof作为强大的剖析工具,能够帮助我们在这条道路上走得更远、更稳健。希望本文对您的Go性能优化之旅有所帮助,祝您在构建高性能Go应用的过程中取得成功!