【多线程初阶】阻塞队列 生产者消费者模型
文章目录
- 一、阻塞队列
- 二、生产者消费者模型
- (一)概念
- (二)生产者消费者的两个重要优势(阻塞队列的运用)
- 1) 解耦合(不一定是两个线程之间,也可以是两个服务器之间)
- 2) 削峰填谷
- (三)生产者消费者模型付出的代价
- 三、标准库中的阻塞队列
- (一)观察模型的运行效果
- (二)观察阻塞效果
- 1) 队列为空的阻塞效果
- 2) 队列为满的阻塞效果
- 四、模拟实现阻塞队列
- 1) 实现要点
- 2) 基于数组实现普通队列
- 3) 添加所需字段
- 4) 循环队列逻辑
- 5) 实现 put()
- 6) 实现take()
- 7) 对 put 和 take 实现阻塞效果
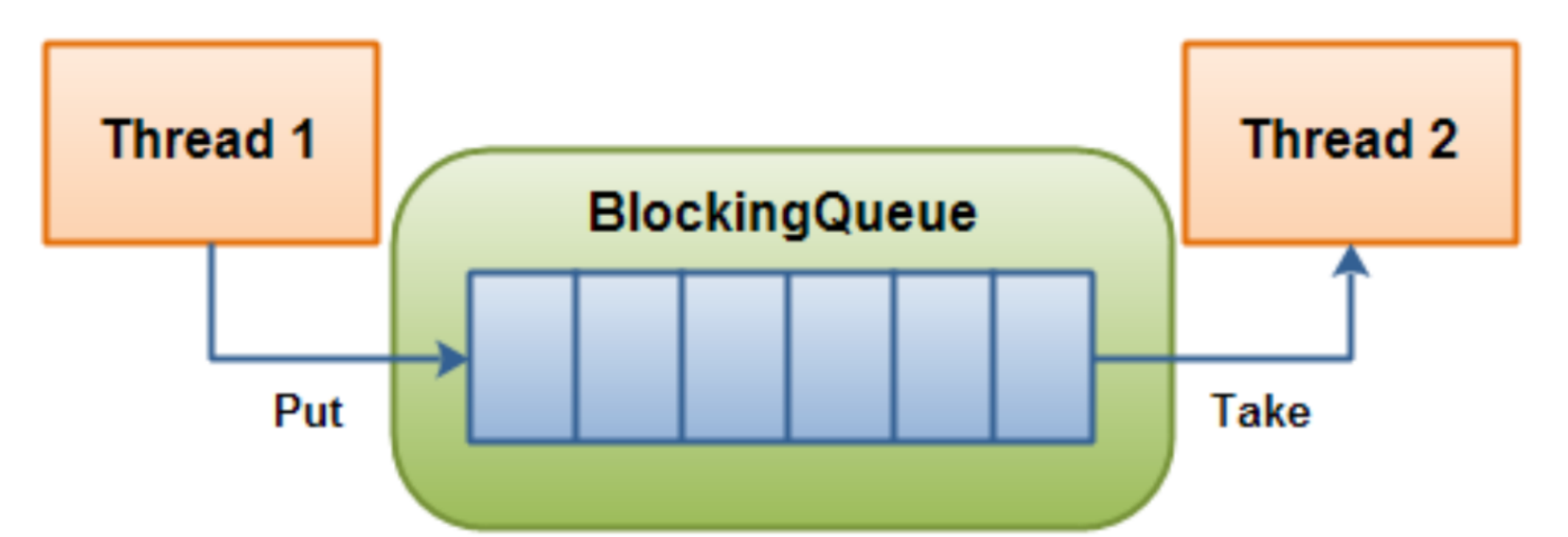
一、阻塞队列
在数据结构学习集合类是我们接触了队列、优先级队列,都是一些很重要的数据结构,尤其是现在搞后端开发,经常会使用分布式系统,微服务框架等等
- 阻塞队列,是一种更加复杂的队列
- 也遵守"先进先出"的原则
- 阻塞队列是一种线程安全的数据结构
- 阻塞特性:
-
- 队列为空时,尝试出队列,出队列操作就会阻塞,阻塞到其他线程添加元素为止
-
- 队列为满时,尝试入队列,入队列操作就会阻塞,阻塞到其他线程取走元素为止
阻塞队列的一个典型应用场景就是"生产者消费者模型",这是一种非常典型的开发模型
二、生产者消费者模型
(一)概念
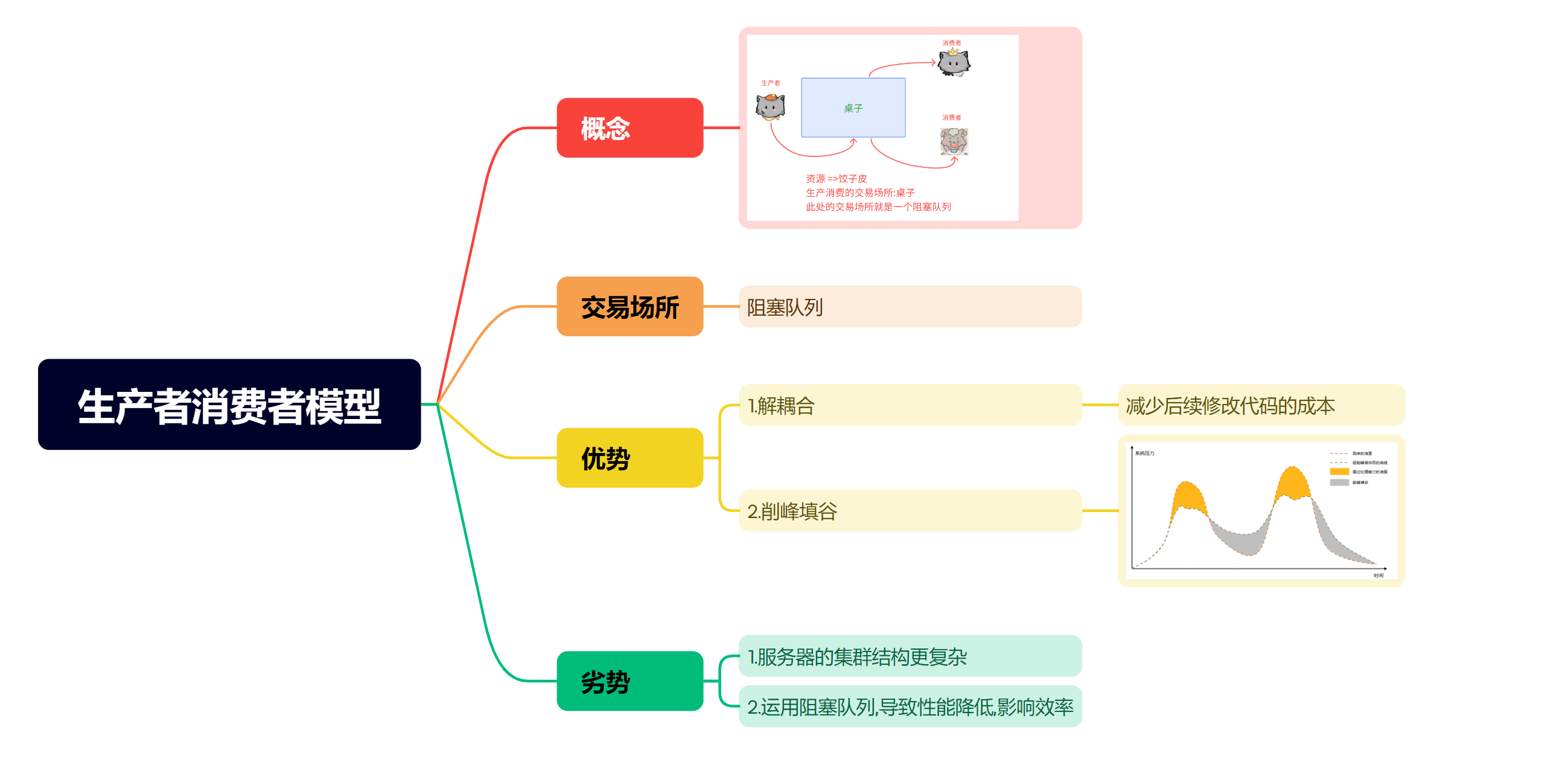
- 生产者消费者模型就是通过一个容器来解决生产者和消费者的强耦合问题
- 生产者和消费者彼此之间不直接通讯,而是通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取
对于上述描述,举个例子,方便理解~~
请出我们的老三位,朝新,朝望,小舟,三个人包饺子
- 两个包饺子的方案
-
- 三个人,每个人都分别擀一个饺子皮,包一个饺子
- 这个方案三个线程就会竞争同一个资源 =>擀面杖,造成阻塞等待
-
- 朝新专门负责擀饺子皮,另外两个人负责包饺子
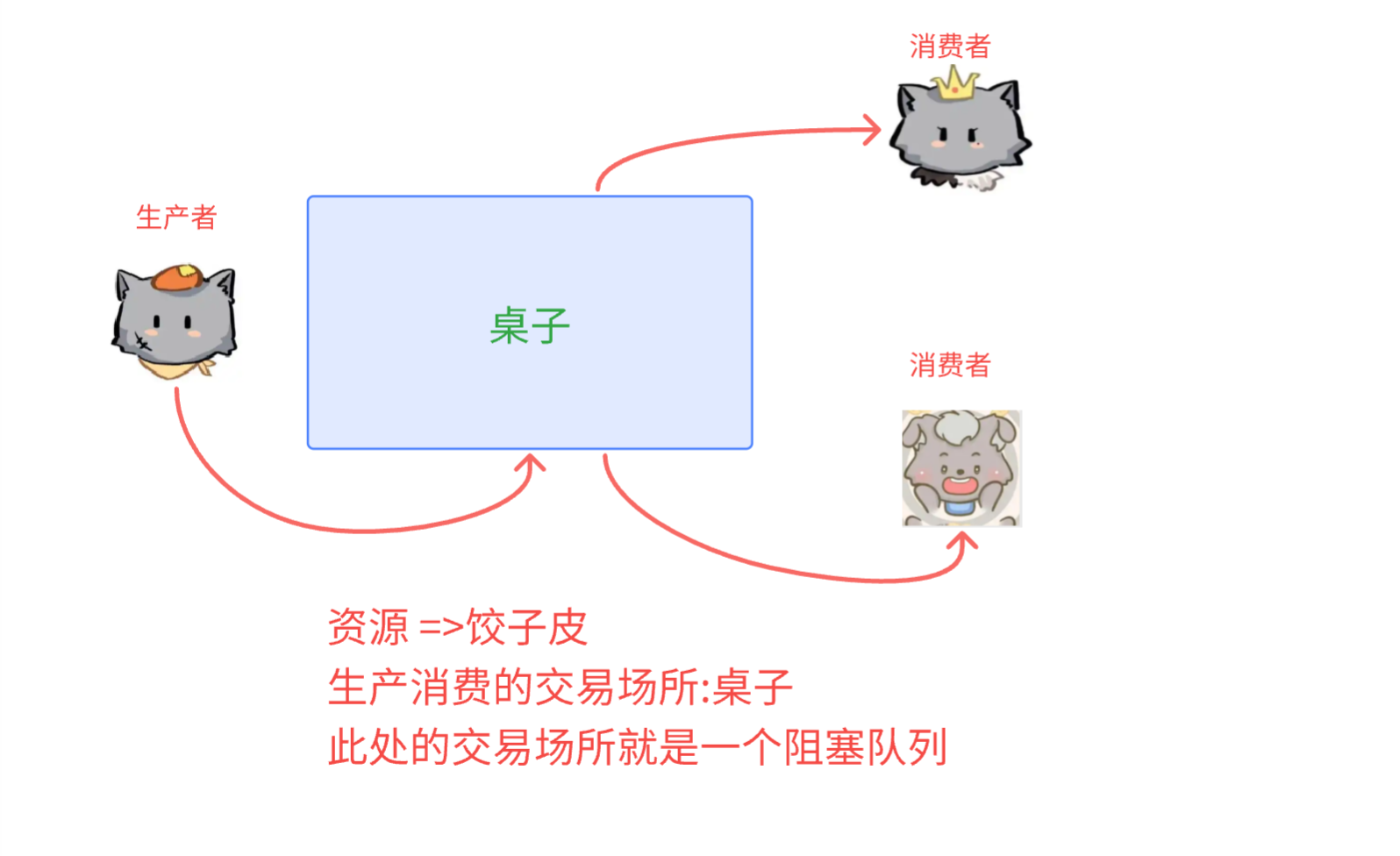
- 当朝新擀饺子皮,擀得飞起~~,会出现阻塞太多了,消费者来不及消费,造成桌子上没地方放饺子皮了,就阻塞了
- 诶? 上面第一个方案就是因为阻塞等待才pass的,这里产生阻塞怎么就行呢?
这里我们提到的阻塞是一个"极端情况",生产者消费者之间速度不协调才会出现,一般情况下,都是不会出现阻塞的
(二)生产者消费者的两个重要优势(阻塞队列的运用)
-
- 解耦合 : 阻塞队列也能是生产者和消费者之间解耦,降低耦合是为了让后续修改的时候成本低~
-
- 削峰填谷 : 阻塞队列相当于一个缓冲区,平衡了生产者和消费者的处理能力
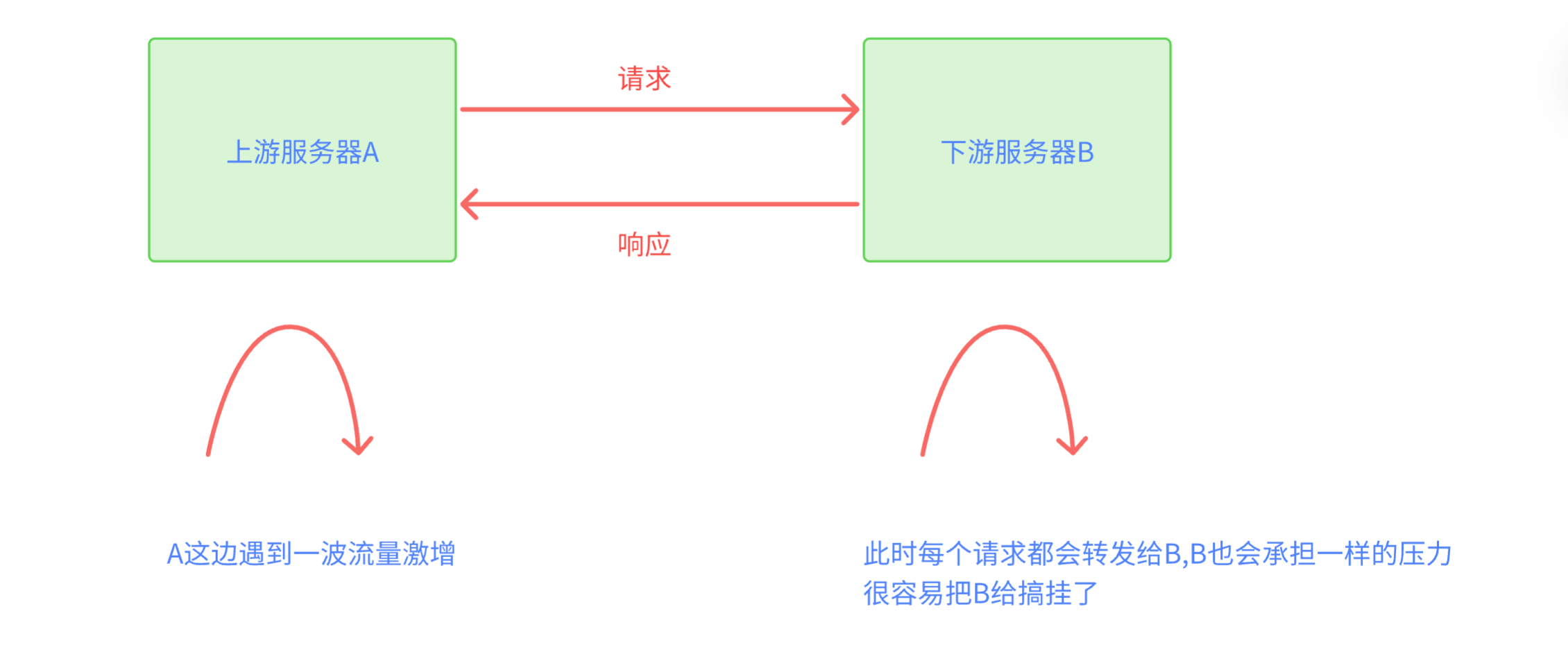
比如在"秒杀"场景下,服务器同一时刻可能会收到大量的支付请求,如果直接处理这些支付请求,服务器可能扛不住(每个支付请求处理都需要比较复杂的流程),这个时候就可以把这些请求都放到一个阻塞队列中,然后再由消费者线程慢慢的按照自己的节奏来处理每个支付请求,不至于下游服务器直接崩溃
这样做可以有效进行"削峰",防止服务器被突然到来的一波请求直接冲垮
1) 解耦合(不一定是两个线程之间,也可以是两个服务器之间)
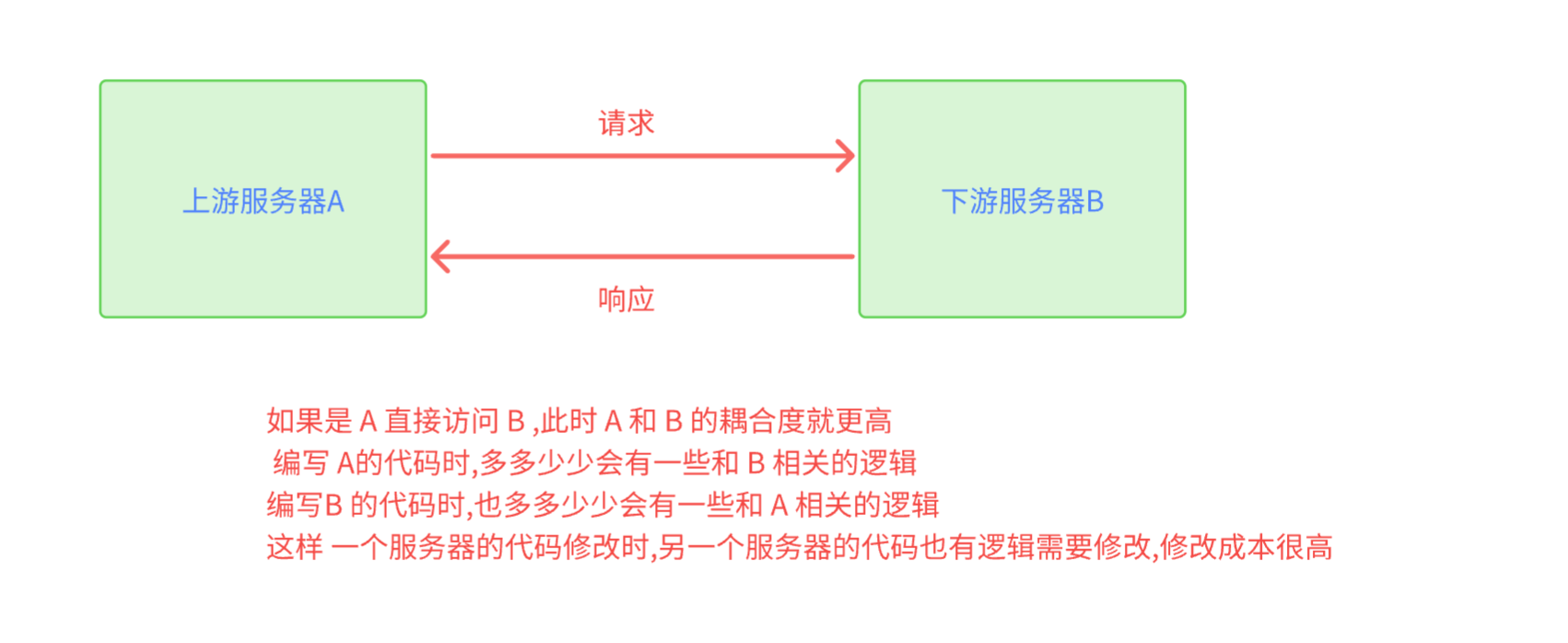
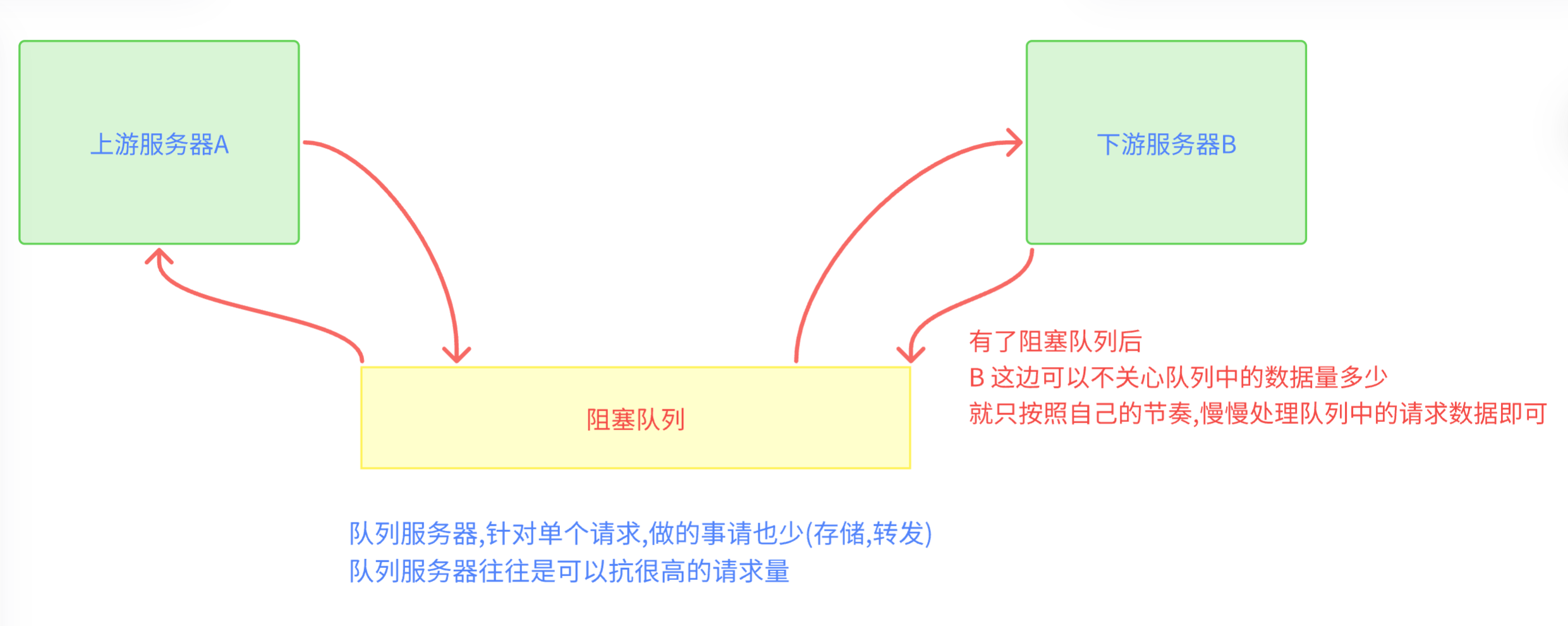
当我们在两个服务器之间引入 阻塞队列后
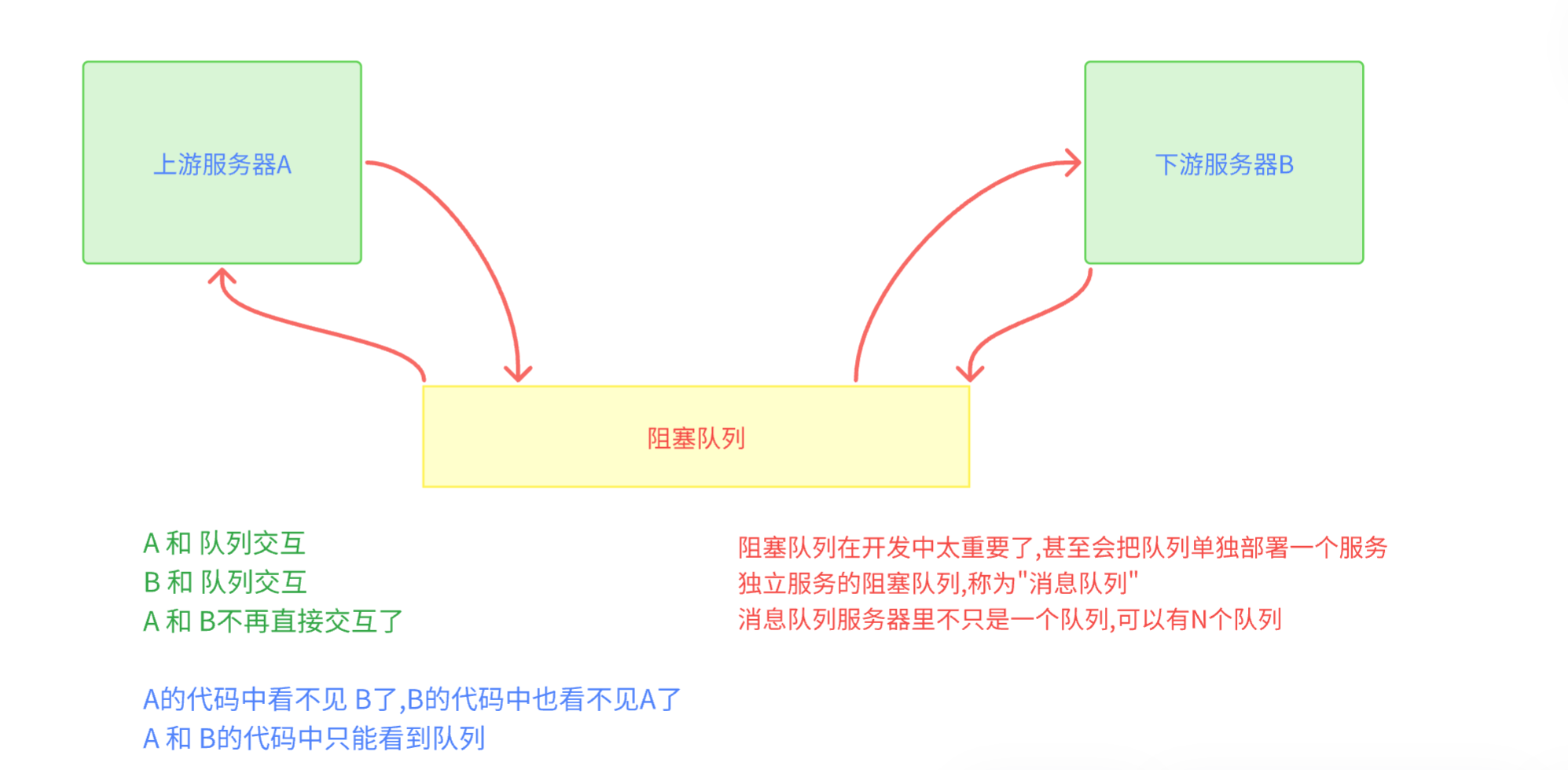
- 本来是 A 和 B耦合,现在是 A和队列耦合,B和队列耦合
- 同样是耦合,为什么单单与队列耦合,就是我们所希望的呢?
- 因为队列的作用基本上是入队列,出队列,功能单一,固定,一般不会涉及到修改,大大降低了耦合,后续修改服务器代码,成本低
2) 削峰填谷
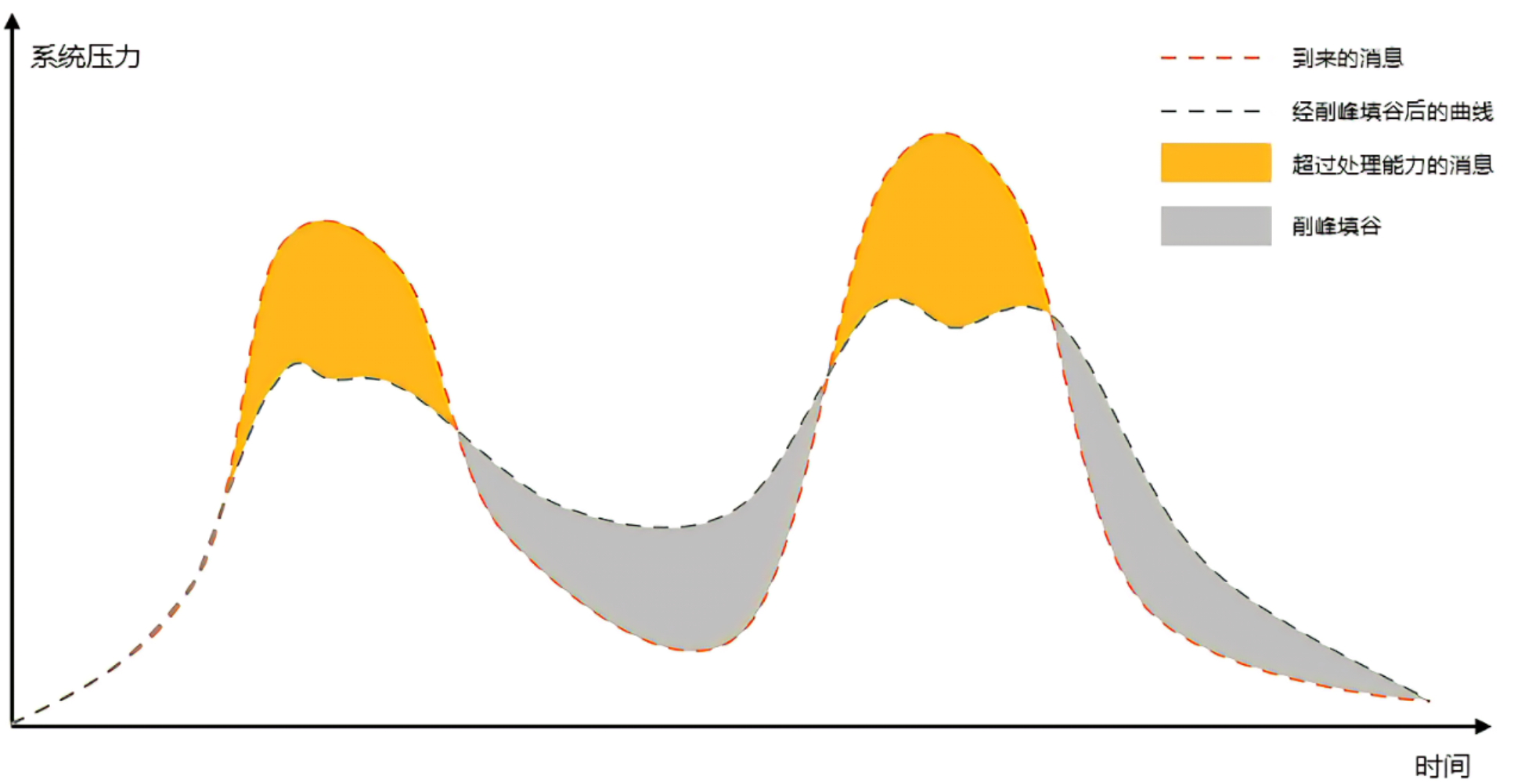
这张图可以理解为服务器收到的请求量的曲线图
-
一般来说 A这种上游的服务器,尤其是 入口的服务器,干的活更简单,单个请求消耗的资源数少
-
像 B这种下游的服务器,同行承担更重的任务量,复杂的计算/存储 工作,单个请求消耗的资源数更多
-
日常工作中,确实会给 B这样角色的服务器分配更好的机器,即使如此,也很难保证 B 承担的访问量能够比 A更高
-
服务器会什么会挂呢? 比如每次选课时,选课系统就会卡的进不去
-
服务器每个请求的时候,都是需要消耗一定的硬件资源
-
包括不限于 CPU,内存,硬盘,网络带宽的资源
-
同时有N个请求呢? 消耗的量*N
-
一旦消耗的总量,超出了机器硬件资源的上限,此时,对应的进程就可能崩溃或者操作系统产生卡顿 =>挂了
-
提供的量 < 消耗的量 ,就会挂~
当我们在两个服务器之间引入 阻塞队列后
- 一般来说,请求量激增是突发,时间也会短
- 趁着峰值过去了,B 仍然继续消费数据,利用波谷的时间,阿里赶紧消费之前积压的数据
(三)生产者消费者模型付出的代价
-
- 引入队列后,整体的结构会更复杂,此时,就需要更多的机器,进行部署,生产环境的结构会更复杂,管理起来更加麻烦
-
- 运用阻塞队列,导致性能降低,效率会有影响
三、标准库中的阻塞队列
在Java标准库中内置了阻塞队列,如果我们需要在一些程序中使用阻塞队列,直接使用标准库中的即可
- BlockingQueue 是一个接口,真正实现的类是 LinkedBlockingQueue
- put方法用于阻塞式的入队列,take用于阻塞式出队列
- BlockingQueue 也有offer ,poll,peek等方法,但是这些方法不带有阻塞特性
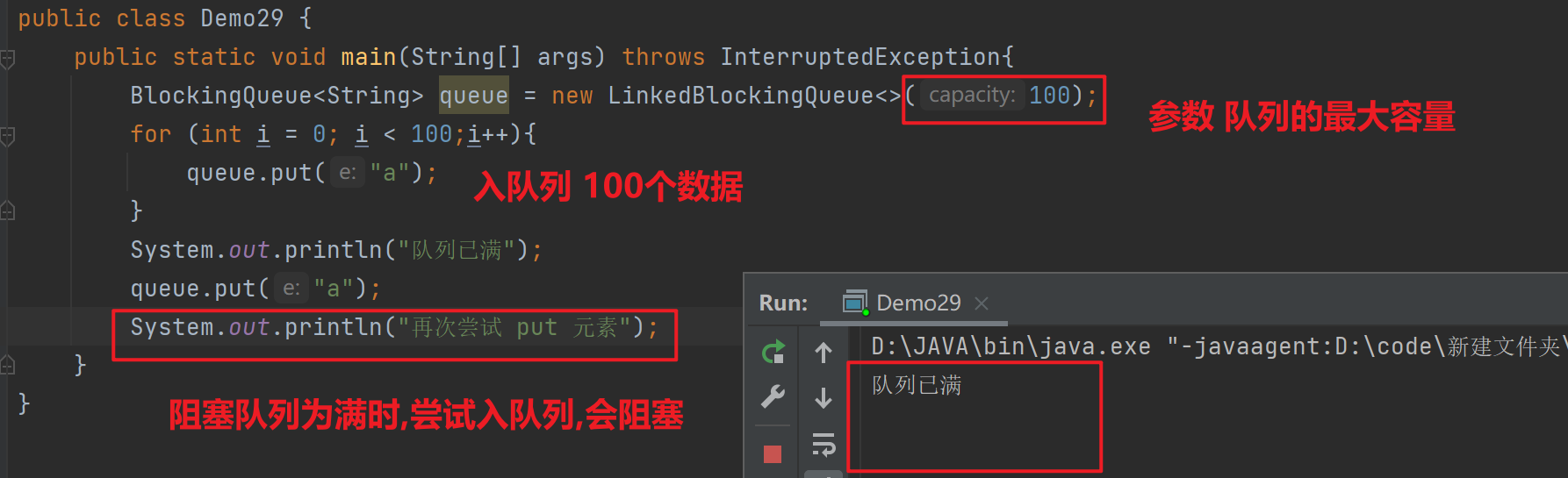
public class Demo29 {public static void main(String[] args) throws InterruptedException{BlockingQueue<String> queue = new LinkedBlockingQueue<>(100);for (int i = 0; i < 100;i++){queue.put("a");}System.out.println("队列已满");queue.put("a");System.out.println("再次尝试 put 元素");}
}使用jconsole观察线程状态
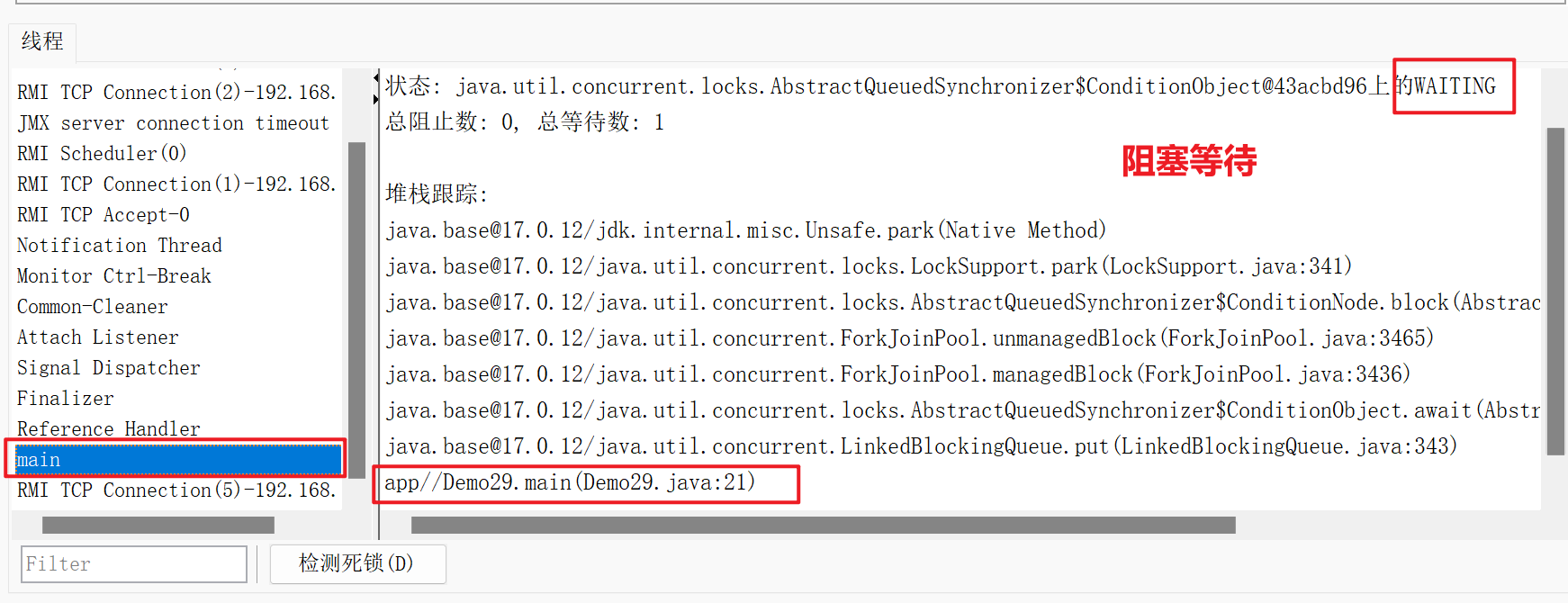
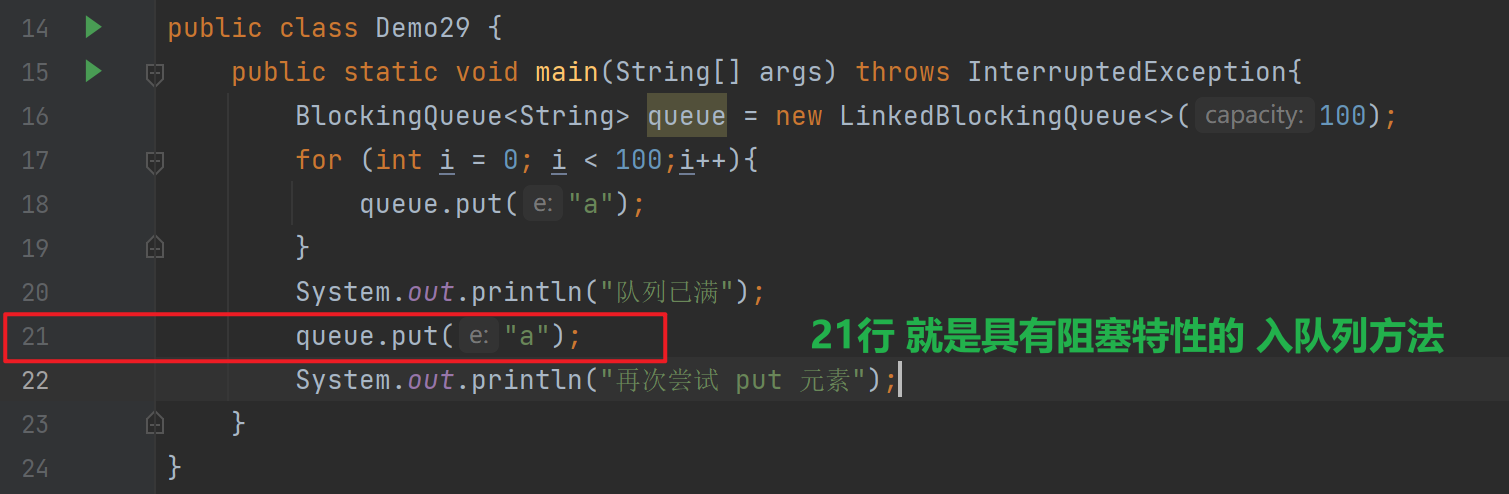
- 其中我们添加了阻塞队列的参数capacity =>最多能容纳多少元素
- 如果不设置capacity,默认是一个非常大的值
- 实际开发中,一般建议大家能够设置上要求的最大值
- 否则,队列可能变得非常大,导致把内存耗尽,产生内存超出范围这样的异常
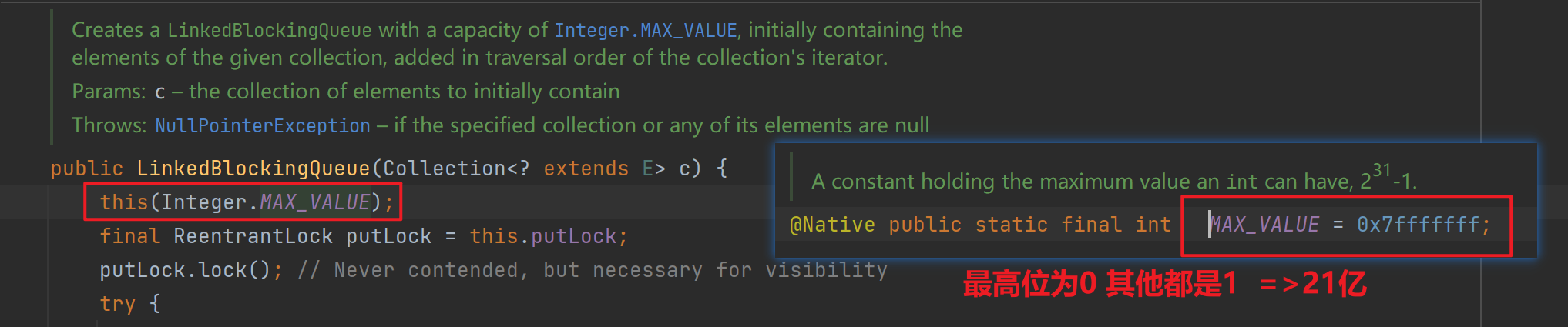
- 填满也没事,队列最多21亿个数据,每个元素是一个int(4个字节)
- 极端情况 80亿个字节 => 8G,打满了消耗 8GB内存
- 我们电脑都是 16G 32G 倒是能消耗得起
- 不过会影响效率,最好还是设置capacity
- 一个JVM进程也不一定能够利用机器所有的内存,是可以在运行JVM的时候通过一定的参数指定JVM最多消耗多少内存
- 如果实际消耗的内存,超过了JVM运行时候的限制上限,确实会挂~
- Thousand 千 => K
- Million 百万 => M
- Billion 十亿 => G
(一)观察模型的运行效果
public class Demo30 {// 生产者一个线程 消费者一个线程public static void main(String[] args) {BlockingQueue<Integer> queue = new LinkedBlockingQueue<>();Thread producer = new Thread(() -> {int n = 0;while (true) {try {queue.put(n);//Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}System.out.println("生产元素 " + n);n++;}}, "producer");Thread consumer = new Thread(() -> {while(true){try {Integer n = queue.take();System.out.println("消费元素 " + n);//Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}}}, "consumer");producer.start();consumer.start();}
}
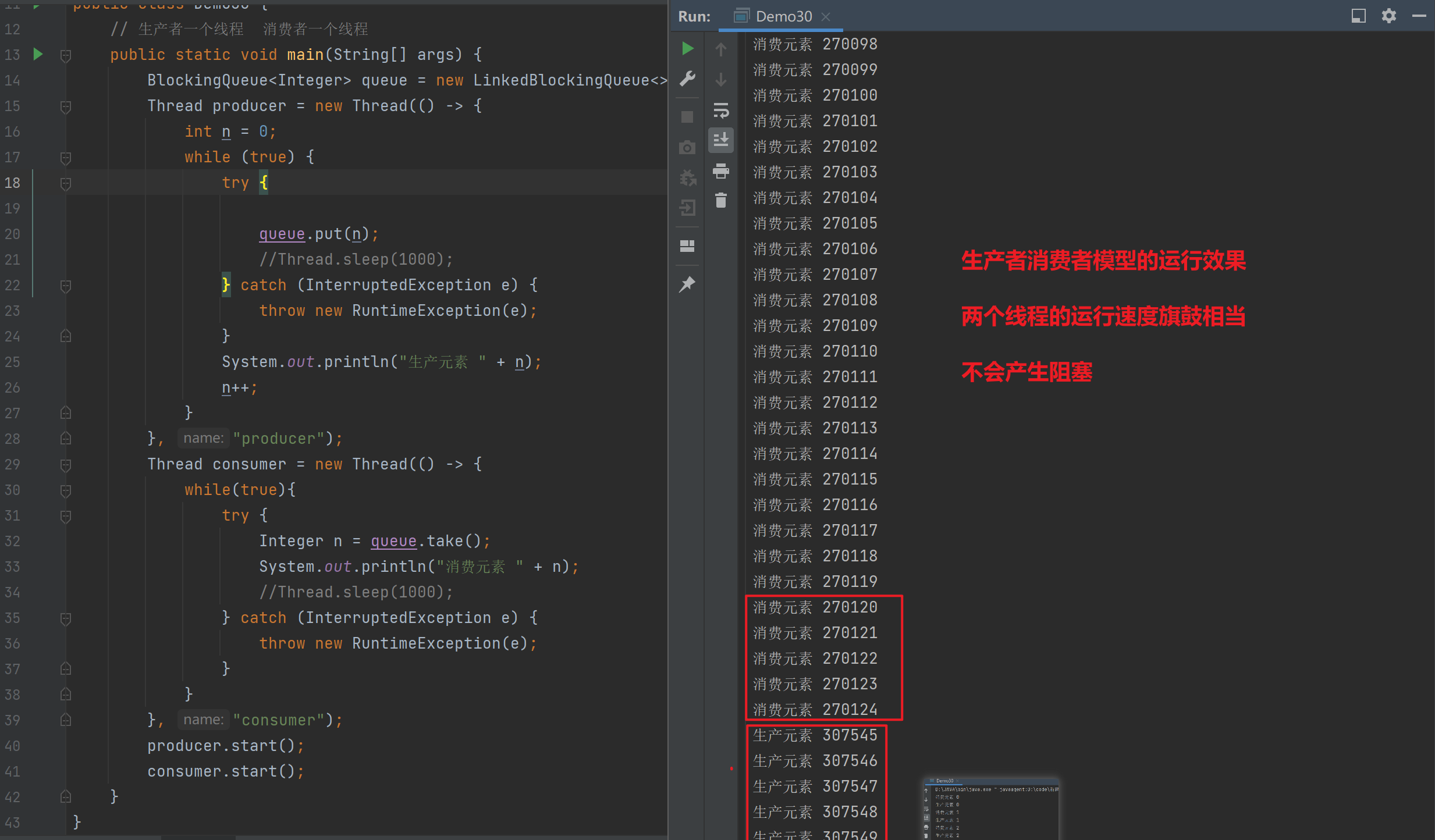
- 通过打印的日志信息,可以观察到,两个线程的执行速度旗鼓相当,并没有产生阻塞
- 这就是开发中的典型情况,虽然模型是会出现阻塞的,但是只要我们协调好生产和消费的速度,两个线程执行速度相差不大,程序就会高效的运行
(二)观察阻塞效果
1) 队列为空的阻塞效果
- 上述的 producer 和 consumer 两个线程的速度旗鼓相当,很难观察到阻塞
- 我们添加sleep,使得两线程速度相差较大,来观察阻塞队列产生的阻塞效果
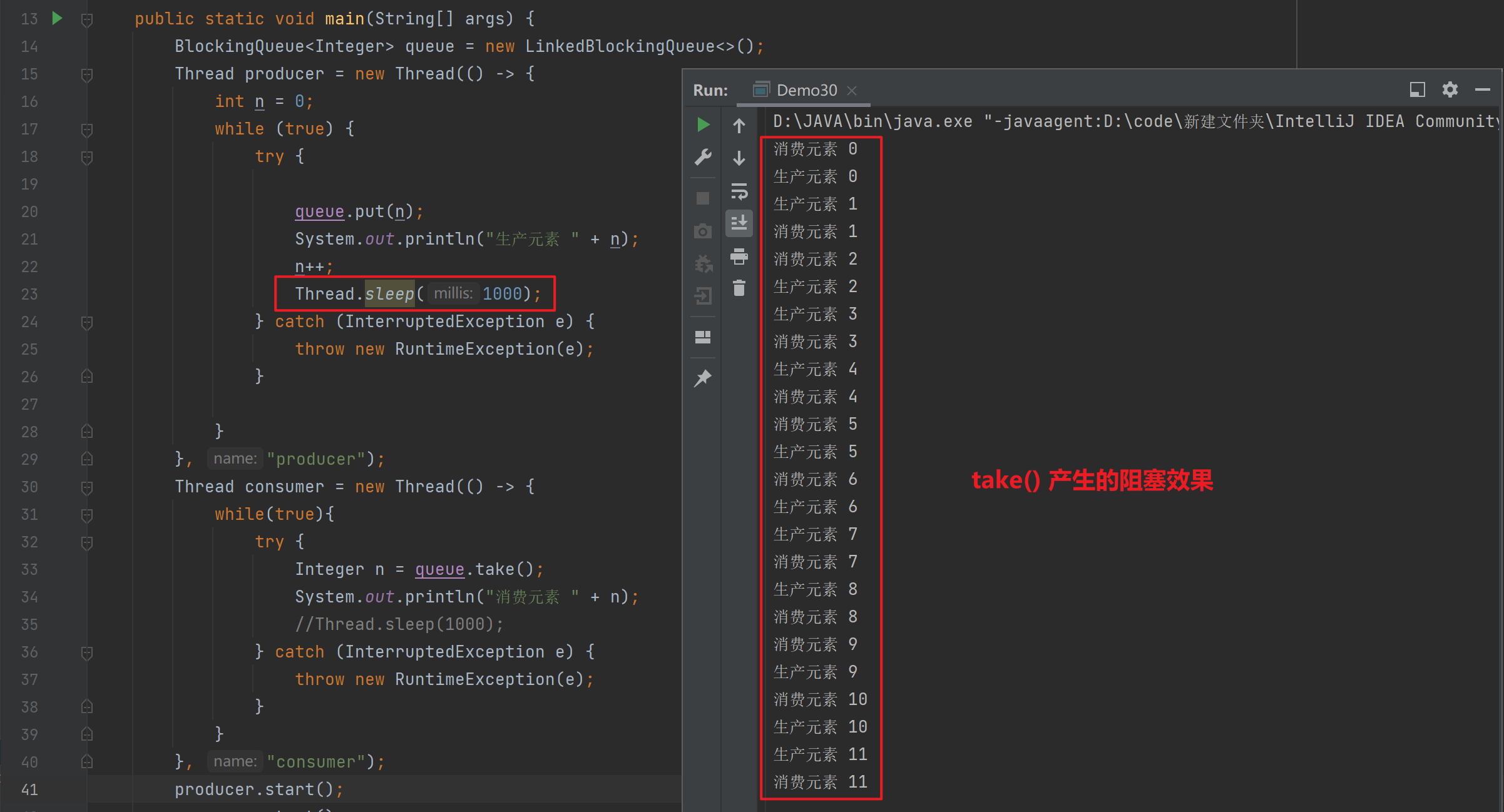
通过降低producer调用 put() 的速度,阻塞队列中的元素被消耗的速度远远大于生产的速度,进而使阻塞队列对 consumer的take() 产生阻塞效果
2) 队列为满的阻塞效果
- 降低 consumer的消费速度,观察阻塞队列对producer的阻塞效果
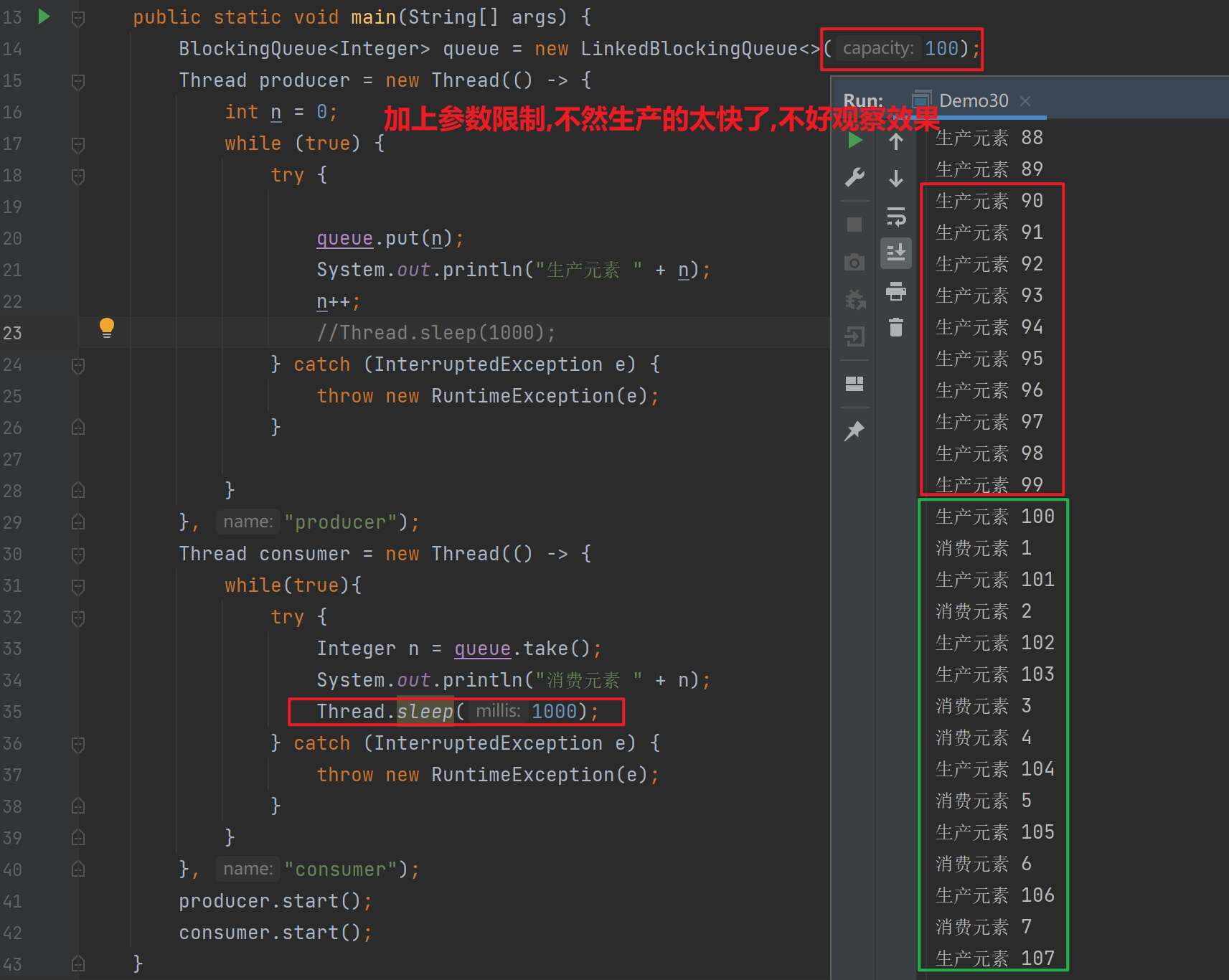
- 虽然 producer 只执行了1秒,但已经把阻塞队列填满了
- 因为队列已满,producer的put()方法产生阻塞效果
- 所以只能consumer消费一个元素,生产者才能生产一个元素
四、模拟实现阻塞队列
我们自己模拟实现一个简单的阻塞队列,并且基于这个阻塞队列实现 生产者消费者模型
1) 实现要点
- 通过"循环队列"的方式来实现
- 使用synchronized进行加锁控制
- put 插入元素时,判定如果队列满了,就进行wait
- take 取出元素时,判定如果队列为空,就进行wait
- wait的使用需要注意,建议配合while使用(后面详细介绍)
2) 基于数组实现普通队列
class MyBlockingQueue{private String[] data = null;public MyBlockingQueue(int capacity){data = new String[capacity];}
}public class Demo31 {public static void main(String[] args) {}
}3) 添加所需字段
class MyBlockingQueue{private String[] data = null;private int head = 0;//队头private int tail = 0;//队尾private int size = 0;//元素个数public MyBlockingQueue(int capacity){data = new String[capacity];}
}
4) 循环队列逻辑
- put()元素 放入tail处,take()元素 head处取出
- put()元素 => tail++
- take()元素 =>head++
- 若 head 和 tail > data.length =>两个指针置为0,继续循环
- 若 head 和 tail 指向同一个元素,要么队空,要么队满
- 要么 所有线程阻塞在 put,要么所有线程阻塞在take
5) 实现 put()
- 队满要进入阻塞(如何进入阻塞)
- put()一次,tail++ size ++
- tail 走出队列 要置为0
public void put(String elem){if(size == data.length){//队列满了,进入阻塞return;}data[tail] = elem;tail++;if(tail >= data.length){tail = 0;}size++;}
}
6) 实现take()
- 队空要进入阻塞(如何进入阻塞)
- take()一次 head++ size–
- head走出队列 要置为0
public String take(){if(size == 0){//队列为空,进入阻塞return null;}String ret = data[head];head++;if(head == data.length){head = 0;}size--;return ret;}
}7) 对 put 和 take 实现阻塞效果
