AlphaDrive:通过强化学习和推理释放自动驾驶中 VLM 的力量
AlphaDrive: Unleashing the Power of VLMs in Autonomous Driving via Reinforcement Learning and Reasoning
25年3月来自华中科技大学和地平线的论文
OpenAI 的 o1 和 DeepSeek R1 在数学和科学等复杂领域达到甚至超越了人类专家水平,其中强化学习(RL)和推理发挥了关键作用。在自动驾驶领域,最近的端到端模型极大地提升了规划性能,但由于常识和推理能力有限,在处理长尾问题时仍然面临困难。一些研究将视觉语言模型(VLMs)集成到自动驾驶中,但它们通常依赖于在驾驶数据上进行简单监督微调(SFT)的预训练模型,并未针对规划任务进一步探索专门的训练策略或优化方法。本文中,我们提出了 AlphaDrive,一个用于自动驾驶中视觉语言模型(VLMs)的强化学习与推理框架。AlphaDrive 引入了四种专门为规划任务定制的基于 GRPO 的强化学习奖励,并采用了一种结合监督微调(SFT)与强化学习(RL)的两阶段规划推理训练策略。其结果是,与仅使用监督微调(SFT)或不使用推理的方法相比,AlphaDrive 显著提升了规划性能和训练效率。此外,我们兴奋地发现,经过强化学习训练后,AlphaDrive 展现出一些涌现的多模态规划能力,这对于提升驾驶安全性和效率至关重要。据我们所知,AlphaDrive 是首个将基于 GRPO 的强化学习(RL)与规划推理集成到自动驾驶中的方法。我们将公开代码以促进未来的研究。
框架示意图:

1. 核心问题与动机
-
问题背景:
当前端到端自动驾驶模型虽在规划性能上有显著提升,但在长尾场景(如特殊交通标志、非常规障碍物)中表现不佳,主要受限于常识缺失和推理能力不足。 -
现有方案的局限:
-
直接使用视觉语言模型(VLMs)进行轨迹预测,因 VLMs 的文本生成特性难以输出精确数值控制信号,存在安全风险。
-
现有 VLM 驱动方法多依赖监督微调(SFT),未深入探索强化学习(RL)和推理技术对规划的优化潜力。
-
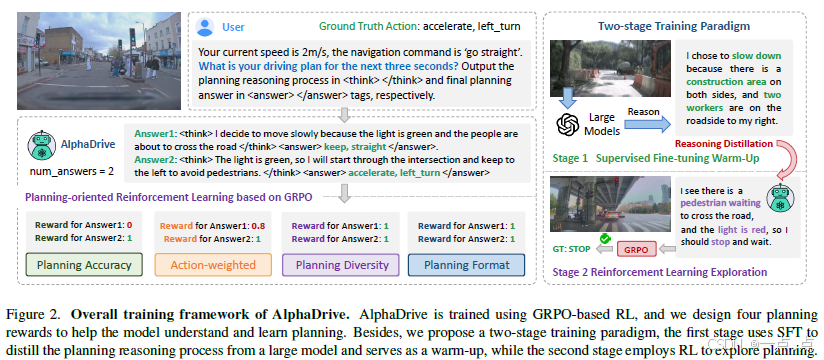
2. 创新方案:AlphaDrive框架
核心贡献
-
首个结合GRPO强化学习与规划推理的自动驾驶框架
-
提出 GRPO(Group Relative Policy Optimization) 作为 RL 算法,优于 PPO/DPO,更适合多解规划场景。
-
-
四大规划导向的GRPO奖励函数
-
规划准确性奖励:分速度/方向评估 F1-score。
-
动作加权奖励:按安全重要性加权(如刹车 > 匀速)。
-
规划多样性奖励:鼓励生成多可行解,避免模式坍塌。
-
格式规范化奖励:确保输出结构化(
<think>推理过程 +<answer>决策)。
-
-
两阶段训练策略
-
Stage 1(SFT 知识蒸馏):
用 GPT-4o 生成高质量规划推理数据(伪标签),蒸馏至小模型,解决真实推理数据稀缺问题。 -
Stage 2(RL 探索优化):
基于 GRPO 和四大奖励进一步优化,提升决策鲁棒性。
-
-
涌现的多模态规划能力
-
RL 训练后模型能生成多种合理驾驶方案(如直行时可选择匀速或加速),增强复杂场景适应性。
-
3. 关键技术细节
GRPO 的优势
-
组优化策略:一次生成多组输出(如 4 个规划方案),通过组内奖励归一化计算优势值,适配规划问题多解特性。
-
训练稳定性:相比 DPO/PPO,GRPO 在早期训练波动更小(参考 DeepSeek R1 的成功经验)。
奖励设计原理
| 奖励类型 | 解决痛点 | 设计方法 |
|---|---|---|
| 准确性奖励 | 动作格式噪声导致早期训练不稳定 | 分速度/方向计算 F1-score(非严格匹配) |
| 动作加权奖励 | 关键动作(刹车)安全权重不足 | 按动作安全重要性动态加权(e.g., 刹车权重 > 加速) |
| 多样性奖励 | 输出收敛至单一解 | 组内输出差异越大奖励越高(惩罚相似决策) |
| 格式奖励 | 非结构化输出难解析 | 强制要求 <think>推理 + <answer>决策格式 |
两阶段训练必要性
-
SFT 阶段:解决小模型感知能力弱、早期 RL 幻觉问题(如忽略红绿灯)。
-
RL 阶段:引入稀疏奖励信号探索高质量决策,突破 SFT 性能天花板。
4. 实验结果与优势
性能对比(MetaAD 数据集)
| 模型 | 规划准确率 | 速度 F1↑ | 方向 F1↑ | 推理质量(CIDEr) |
|---|---|---|---|---|
| Qwen2VL-7B (SFT) | 61.44% | 73.80 | 84.53 | 30.65 |
| AlphaDrive (2B) | 77.12% | 86.63 | 86.80 | 38.97 |
-
关键优势:
-
仅用 20% 数据时,超越 SFT 基线 35.31%。
-
小模型(2B)显著超越大模型(7B),验证框架高效性。
-
消融实验结论
-
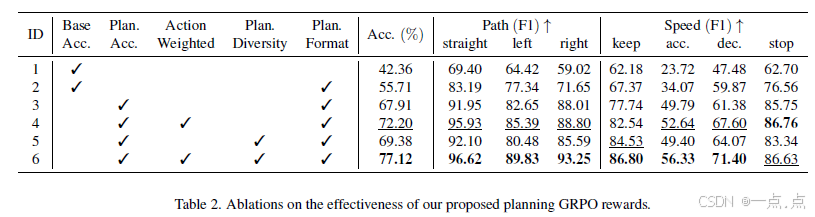
奖励缺一不可:移除动作加权奖励导致关键动作(减速)F1 下降 19%(表2)。
-
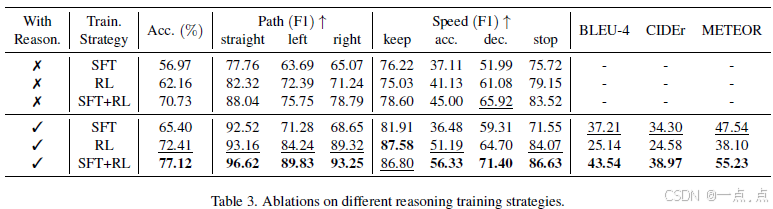
推理的必要性:引入推理后复杂动作(加速/减速)F1 提升 10%(表3)。
-
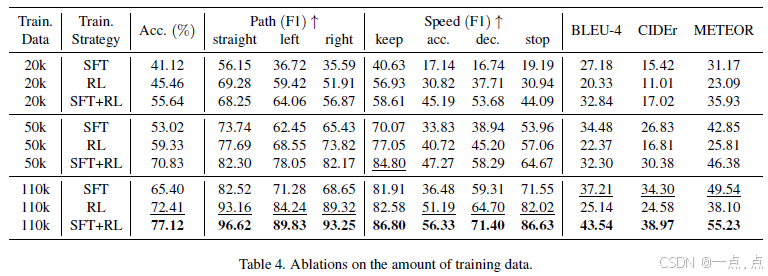
数据效率:50k 样本时 SFT+RL 已达 70.83% 准确率,纯 SFT 需 110k 样本(表4)。
5. 局限与未来方向
-
局限:
-
无法处理变道(lane change)等高阶行为(缺乏标注数据)。
-
推理数据依赖大模型伪标签,可能遗漏关键感知因素(如未识别施工标志)。
-
-
未来方向:
-
构建真实驾驶推理数据集。
-
扩展至多智能体交互场景。
-
探索 3D 场景表示与 VLM 的深度结合(参考 OmniDrive)。
-
6. 总结
AlphaDrive 的核心价值在于:
-
方法创新:首次将 GRPO 强化学习与规划推理引入自动驾驶,突破 SFT 瓶颈。
-
性能突破:小模型实现 SOTA 性能,数据效率提升 5 倍。
-
安全增强:多模态规划能力为动态场景提供冗余决策方案。
-
开源意义:代码公开推动社区发展(GitHub: hustvl/AlphaDrive)。
启示:该研究证明,通用大模型的 RL 与推理技术可迁移至垂直领域(如自动驾驶),通过领域适配的奖励设计和数据生成策略,解决小样本、长尾问题。
如果此文章对您有所帮助,那就请点个赞吧,收藏+关注 那就更棒啦,十分感谢!!!