经济学顶刊QJE:构建从非结构化文本数据中挖掘经济规律的新框架!
芝加哥大学和美国国家经济研究局教授Jens Ludwig和Sendhil Mullainathan共同研究的“Machine Learning as a Tool for Hypothesis Generation (机器学习作为假设生成的工具)”一文在经济学TOP5刊The Quarterly Journal of Economics中发表,研究以司法决策场景为例,构建了从非结构化文本数据中挖掘经济规律的框架,内容十分详细,本文简要概括,具体可阅读原文。
文本数据挖掘
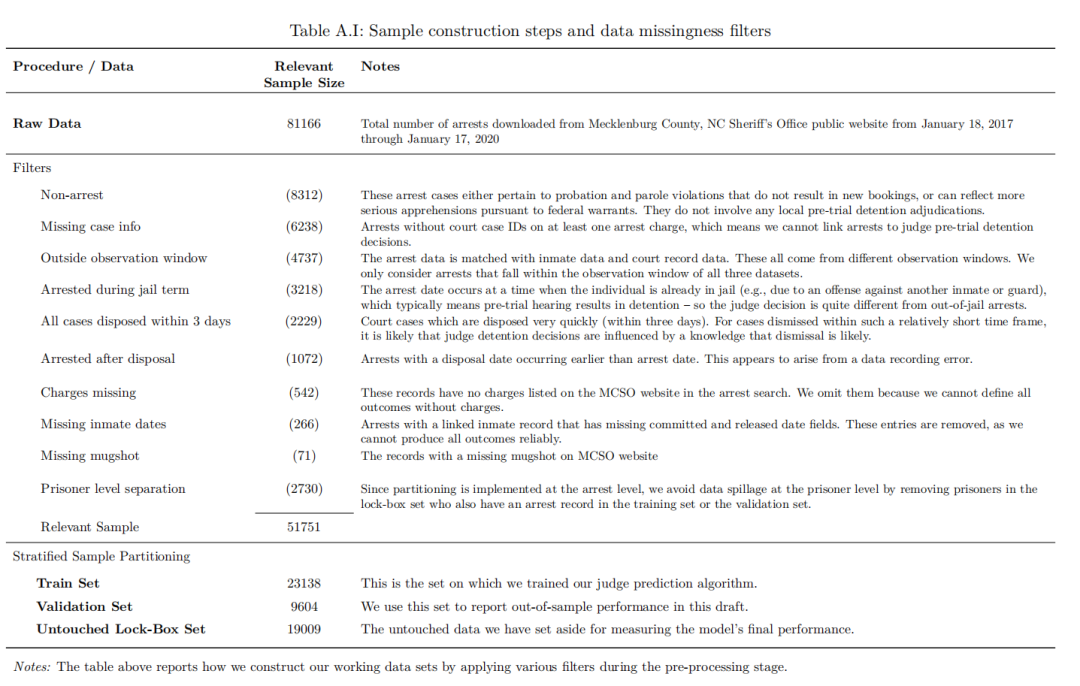
论文数据主要源自美国北卡罗来纳州梅克伦堡县,涵盖 2017 年 1 月 18 日至 2020 年 1 月 17 日期间的 81,166 条逮捕记录,经数据清洗,最终形成包含 51,751 条观测的分析数据集。
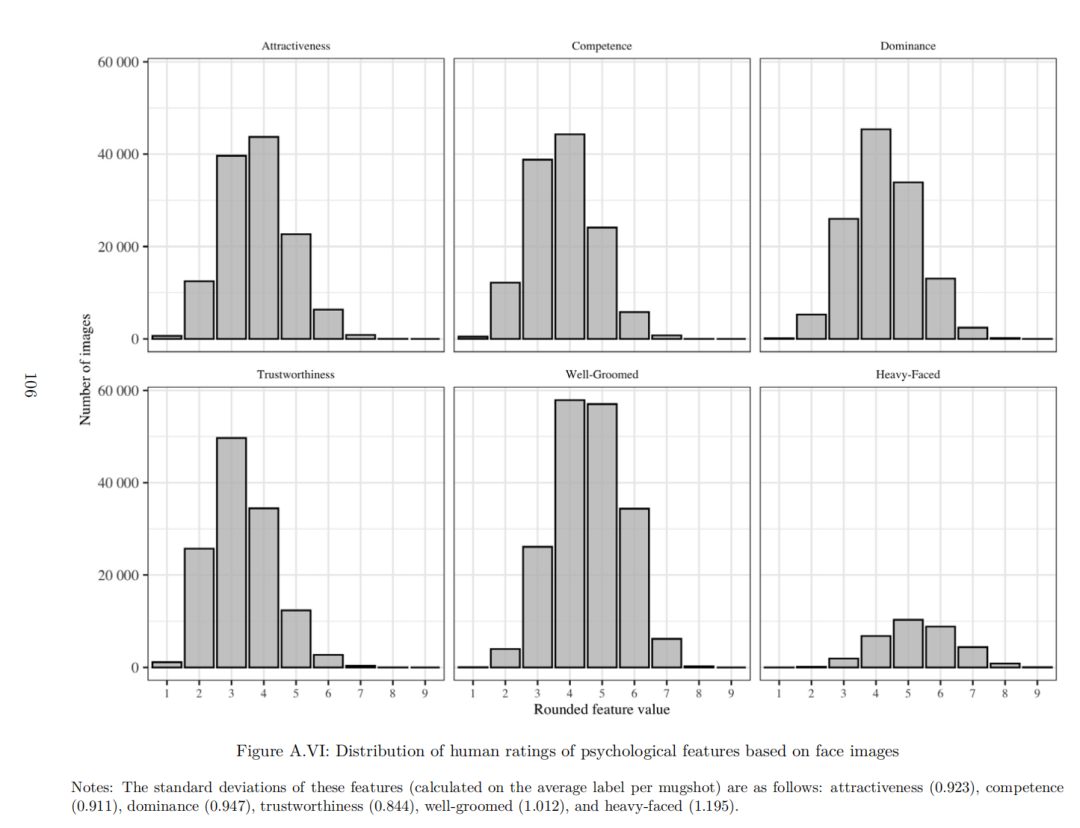
研究还通过人类智能任务(HITs)获取标注数据,包括 343 名亚马逊 Mechanical Turk 和 Prolific 平台受试者对被告面部特征(如吸引力、整洁度、面部宽大程度等)的评分,以及 595 名受试者对法官拘留决策的猜测数据,用于验证算法发现的特征与实际决策的关联性。
此外,借助生成对抗网络(GAN)生成约 33,100 张合成面部图像,用于构建变形图像对以挖掘算法关注的关键面部特征,实验中还随机分配结构化变量(犯罪记录、当前指控等)至合成图像,形成包含 18,268(整洁度实验)和 18,548(面部宽大程度实验)条观测的实验室数据集,以检验特征对模拟法官决策的因果影响。
具体分析
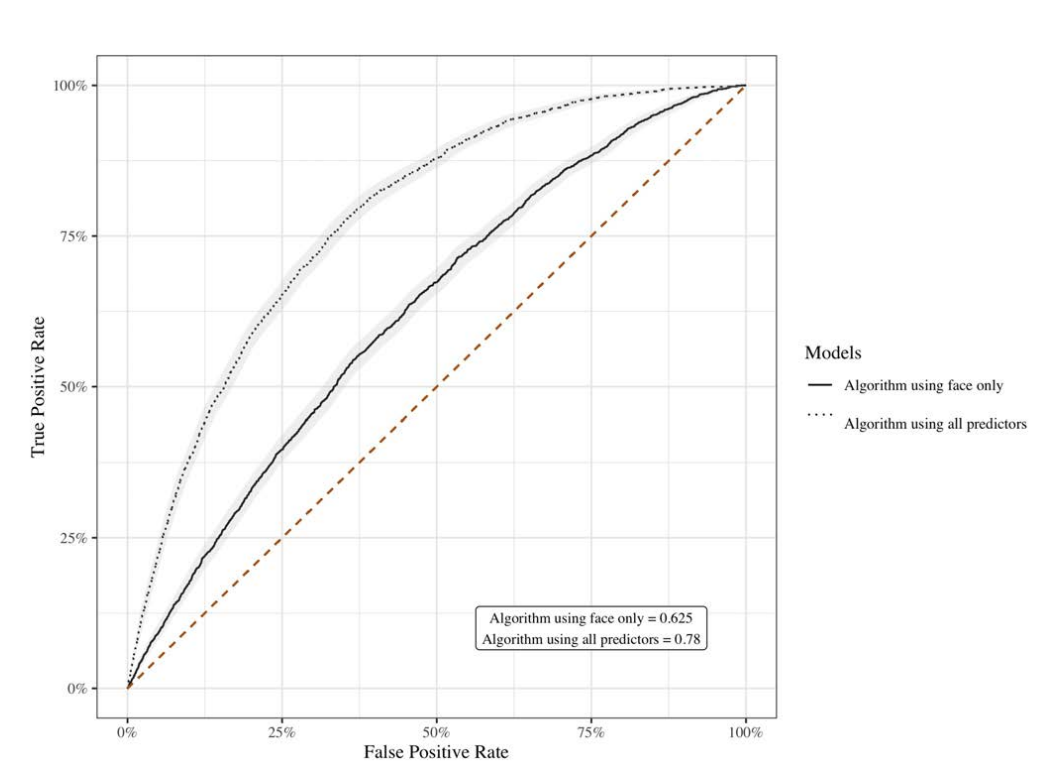
在特征工程与模型构建阶段,针对结构化数据(如被告年龄、性别、犯罪类型、前科等)采用梯度提升决策树建模,对于非结构化的面部图像数据,运用卷积神经网络(CNN)提取像素级特征并预测法官拘留决策,再通过堆叠方法将结构化数据模型与图像模型的预测结果结合,形成综合预测模型,该模型预测法官决策的 AUC 达到 0.780,仅用面部图像的模型 AUC 为 0.625,显示面部特征对法官决策有显著影响。
为探究算法从面部图像中捕捉的关键特征,研究借助生成对抗网络(GAN)生成合成面部图像,沿着预测拘留概率的梯度方向对合成图像进行 “变形”,生成仅在预测风险上有显著差异而其他视觉特征尽可能相似的图像对。将这些变形图像对展示给受试者,让其在有反馈激励的实验中学习并识别算法关注的面部特征,受试者通过观察对比,命名出如 “整洁度”(well-groomed,反映被告面部整洁、打理程度)和 “面部宽大程度”(heavy-faced,体现面部宽度、圆润度等特征)等关键特征,且这些特征经独立标注验证与算法预测显著相关。

在假设验证环节,通过实验室实验,向受试者随机展示变形后的合成图像,控制被告的结构化变量(如犯罪记录、当前指控等),观察其模拟法官的拘留决策,发现受试者更倾向于拘留 “整洁度” 低或 “面部宽大程度” 低的被告,与算法发现的特征对实际法官决策的影响一致,表明这些新假设具有实证合理性,且相关特征并非是对被告风险、社会经济地位、心理健康等已知因素的代理,具有新颖性。
整个文本分析过程通过 “数据采集与预处理 - 多模态模型构建 - 人机交互生成假设 - 实验验证” 的闭环,展示了如何从高维图像数据中系统性挖掘出人类可解释的新颖假设,为机器学习在社会科学研究中的假设生成提供了可迁移的方法论框架。
来源文献
Ludwig, Jens, and Sendhil Mullainathan. "Machine learning as a tool for hypothesis generation." The Quarterly Journal of Economics 139.2 (2024): 751-827.