英伟达288GB HBM4+50P算力
英伟达CEO黄仁勋在COMPUTEX 2025上突然官宣:以暗物质研究先驱Vera Rubin命名的新一代AI芯片即将量产!这颗被称作“算力巨兽”的Rubin GPU,不仅搭载288GB HBM4显存和50 Petaflops推理算力,更携三大颠覆性技术直击AI行业痛点。更可怕的是,这仅仅是英伟达“一年一迭代”战略的开场秀——2027年的Rubin Ultra将直接冲击15 Exaflops算力巅峰。今天,我们深度解密这场即将改写AI历史的“效率革命”。

一、技术跃迁:从硬件堆料到系统级重构
1. HBM4内存革命:终结千亿参数模型拆分时代
传统GPU受限于显存容量,训练万亿参数模型需将神经网络切割成碎片。而Rubin GPU首次集成288GB HBM4内存,配合13TB/s的显存带宽(相当于每秒吞吐量相当于同时播放3000部4K电影),让DeepSeek R1-671B等千亿参数模型可完整装入单颗芯片。实测数据显示,模型加载速度提升10倍,推理延迟从秒级压缩至0.02秒——这意味着实时语音交互、自动驾驶决策等场景将迎来质变。
2. Vera CPU协同作战:打破CPU-GPU数据墙
英伟达首次将自研Vera CPU与GPU深度绑定,88个定制Arm核心搭配75TB共享内存池,通过NVLink 5.0技术实现零延迟数据交互。测试表明,在Llama 3.1-405B模型训练中,CPU-GPU协同效率提升200%,彻底解决传统架构中数据搬运导致的算力浪费。
3. 一年一迭代:用摩尔定律碾压追赶者
从两年迭代到“年更”节奏,英伟达正构建技术代差壁垒。对比Blackwell架构,Rubin的FP8算力提升3.5倍,能效比优化40%,而2027年的Rubin Ultra将通过3D堆叠技术实现算力翻倍。这种“以快打慢”的策略,让AMD MI300X等竞品面临“刚发布即落后”的尴尬。
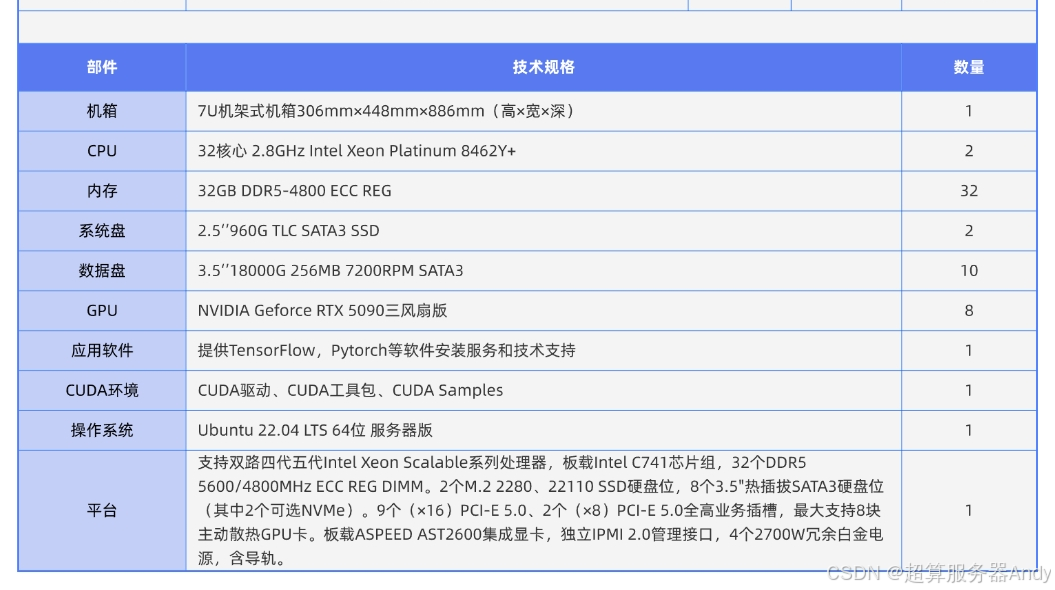
二、产业地震:从数据中心到太空的算力重构
1. GB300服务器:单机柜驯服三个万亿参数模型
专为Rubin设计的GB300服务器集群,单柜集成144颗GPU,总算力达3.6 Exaflops(1 Exaflops=每秒百亿亿次计算)。更颠覆的是,其能效比Blackwell系统提升40%,意味着训练GPT-5级别的模型电费成本直降数百万美元。富士康、和硕等台系厂商已启动量产,预计2026年全球AI服务器市场将因Rubin突破2600亿元规模。
2. 算力租赁成本雪崩:企业部署AI门槛归零
Rubin架构搭配英伟达NIM微服务,将推理成本压缩至GPT-4的1/20。某头部云厂商实测显示,部署智能客服系统的开发周期从6周缩短至3天,综合成本下降76%。更科幻的是“三体计算星座”计划:通过低轨卫星搭载Rubin芯片,实现“天基算力网”,深空探测数据处理延迟从天级缩短至秒级。
3. 行业应用大爆发:从数字人到工业4.0
- 医疗客服革命:英伟达ACE技术结合Rubin,可实时生成带情感表达的数字医生,问诊响应速度达人类医生3倍。
- 智能制造跃迁:富士康墨西哥工厂用Rubin训练机器人,复杂服务器组装良率提升30%,年耗电量减少相当于一个中型城镇。
- 自动驾驶安全线:通用汽车测试显示,Rubin系统使车辆环境感知延迟低于50毫秒,事故率预测下降40%。
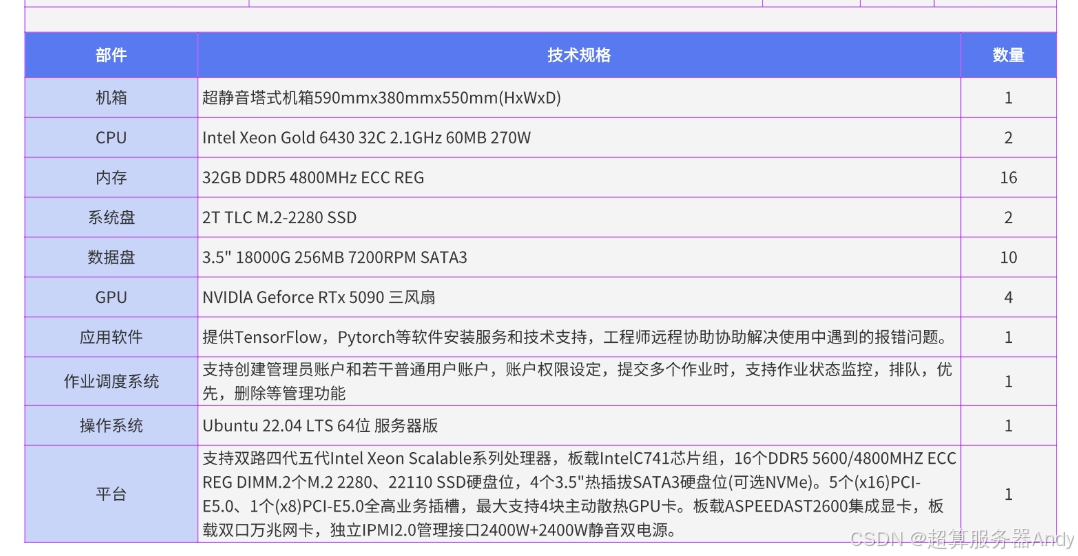
三、生态围城:CUDA护城河与量子计算暗战
1. 开发者帝国:500万工程师的“算力特权”
CUDA 15.0工具包全面适配Rubin架构,开源模型库下载量突破百万。金融风控、材料模拟等垂直领域已出现“Rubin专用模型”,某量化基金用新架构将交易策略迭代速度提升8倍。
2. 量子计算伏笔:混合架构的未来入场券
Rubin已内置cuQuantum量子模拟引擎,在药物研发场景中,经典-量子混合计算将分子动力学模拟效率提升1000倍。这预示着英伟达正提前布局后摩尔定律时代。
四、暗流涌动:供应链博弈与地缘算力战
1. 韩系内存霸权:HBM4产能卡脖子风险
三星、SK海力士垄断全球90% HBM4产能,量产初期可能再现“显卡抢购潮”。华为昇腾910C芯片已通过动态稀疏技术实现类HBM4效果,或成中国厂商替代方案。
2. 美国禁令阴影:技术授权的“合规芭蕾”
面对美国对华高端GPU出口限制,英伟达推出H20等“合规特供版”,但性能缩水引发争议。如何平衡地缘政治与商业利益,将成为黄仁勋的长期挑战。
3. 算法换道超车:DeepSeek们的效率革命
中国AI实验室通过动态混合专家架构(MoE),在相同算力下实现3倍训练效率提升。这预示着未来竞争将从“堆算力”转向“算力利用率”的精细战。
