【读代码】从预训练到后训练:解锁语言模型推理潜能——Xiaomi MiMo项目深度解析
项目开源地址:https://github.com/XiaomiMiMo/MiMo
一、基本介绍
Xiaomi MiMo是小米公司开源的7B参数规模语言模型系列,专为复杂推理任务设计。项目包含基础模型(MiMo-7B-Base)、监督微调模型(MiMo-7B-SFT)和强化学习模型(MiMo-7B-RL)等多个版本。其核心创新在于通过全流程优化解锁模型的推理潜力:
技术亮点:
- 预训练阶段:优化数据管道,提升推理模式密度
- 训练目标:引入多token预测(MTP)加速推理
- 后训练阶段:创新性代码奖励机制与数据重采样策略
- 工程优化:无缝rollout引擎实现1.9倍训练加速
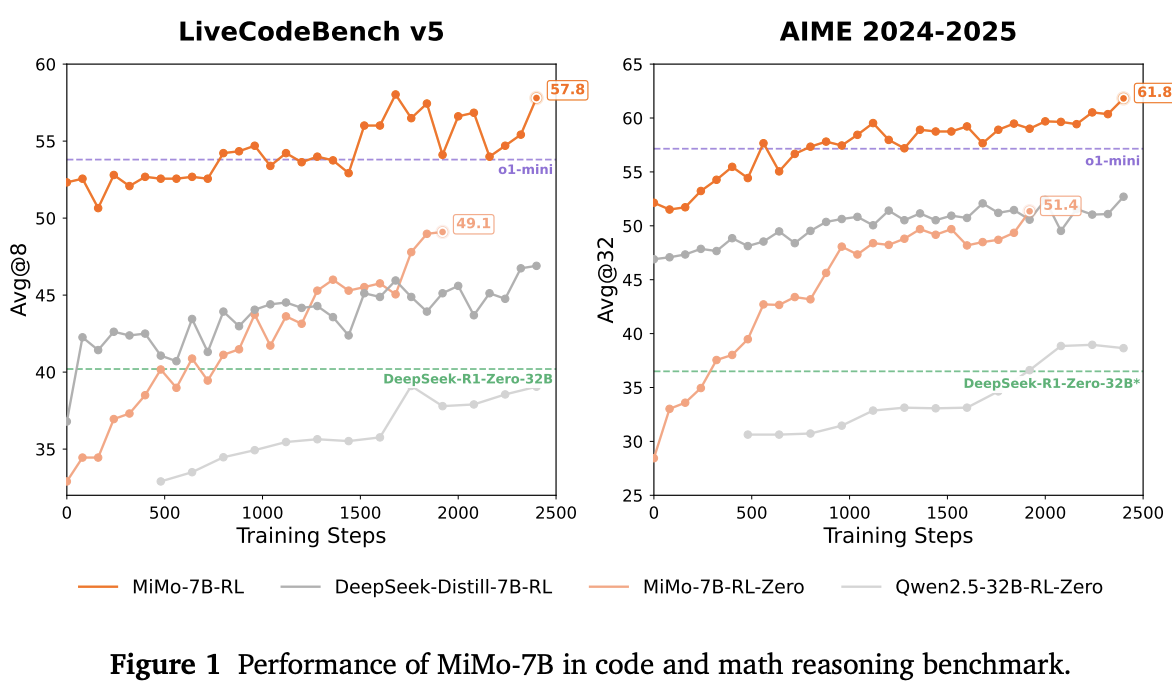
性能表现:
- 在AIME2024数学竞赛达到68.2%准确率(超过DeepSeek R1)
- LiveCodeBench v5代码基准57.8%准确率
- 推理速度提升90%(MTP加速)
二、快速上手
环境配置
# 使用官方推荐环境
conda create -n mimo python=3.10
conda activate mimo
pip install vllm>=0.7.3 torch==2.3.0
基础推理示例
from vllm import LLM, SamplingParamsmodel = LLM("XiaomiMiMo/MiMo-7B-RL",trust_remote_code=True,num_speculative_tokens=1)prompt = "解方程:x² -5x +6 = 0"
sampling_params = SamplingParams(temperature=0.6, max_tokens=256)outputs