CentOS7搭建Hadoop集群
CentOS7搭建Hadoop集群
- 服务器规划
- 设置服务器主机名(三个节点都配置)
- 添加IP与主机名的映射(三个节点都配置)
- ssh服务配置
- 配置JDK环境变量
- JDK环境验证
- 配置Hadoop系统环境变量
- 验证Hadoop环境
- 修改hadoop-env.sh文件
- 修改core-site.xml文件
- 修改hdfs-site.xml文件
- 修改mapred-site.xml文件
- 修改yarn-site.xml文件
- 修改workers文件
- 将集群主节点的配置文件分发到其他子节点
- 格式化文件系统
- 启动hadoop集群
- 通过UI界面查看hadoop运行状态
在CentOS7中搭建一个具有3个DataNode节点的HDFS集群
服务器规划
| 主机名 | IP地址 |
|---|---|
| hadoop1 | 192.168.19.142 |
| hadoop2 | 192.168.19.143 |
| hadoop3 | 192.168.19.144 |
设置服务器主机名(三个节点都配置)
需要在三台服务器上设置服务器主机名
hostnamectl set-hostname hadoop1
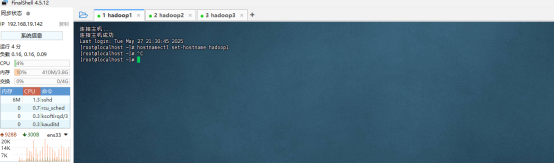
hostnamectl set-hostname hadoop2
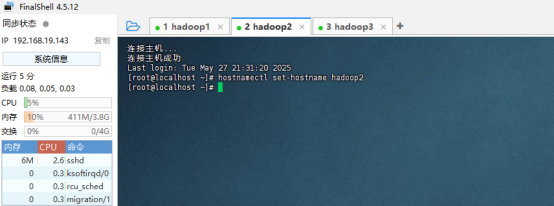
hostnamectl set-hostname hadoop3

设置完成后重启服务器(reboot)
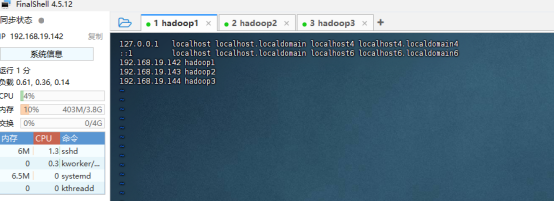
添加IP与主机名的映射(三个节点都配置)
sudo vim /etc/hosts
ssh服务配置
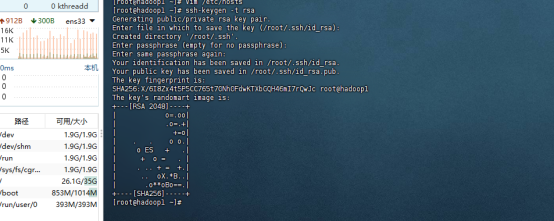
三台机器生成公钥和私钥
ssh-keygen -t rsa
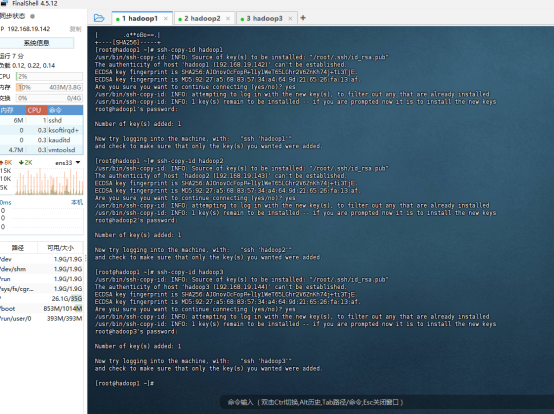
拷贝公钥到另外两台机器
在hadoop1,hadoop2和hadoop3上分别执行以下三行
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3
配置JDK环境变量
vim ~/.bashrc

修改完成之后记得使用命令source ~/.bashrc,使修改生效
JDK环境验证

配置Hadoop系统环境变量
vim ~/.bashrc

修改完成之后记得使用命令source ~/.bashrc,使修改生效
验证Hadoop环境

同时添加hadoop为root用户,否则启动的HDFS的时候可能会报错
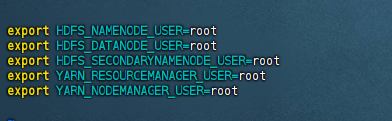
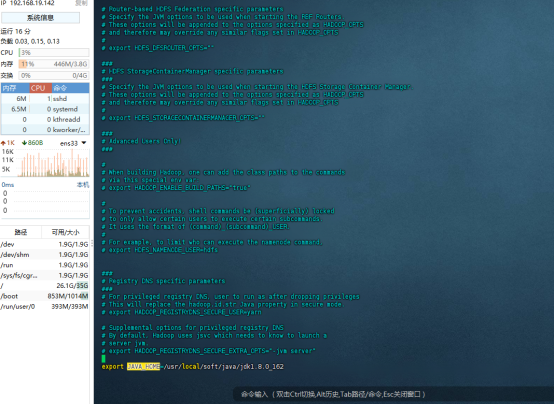
修改hadoop-env.sh文件
vim hadoop-env.sh
找到export JAVA_HOME的位置修改
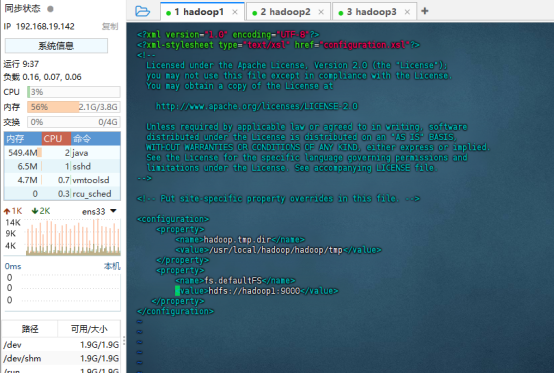
修改core-site.xml文件
主要是配置主进程NameNode的运行主机和运行生成数据的临时目录
vim core-site.xml
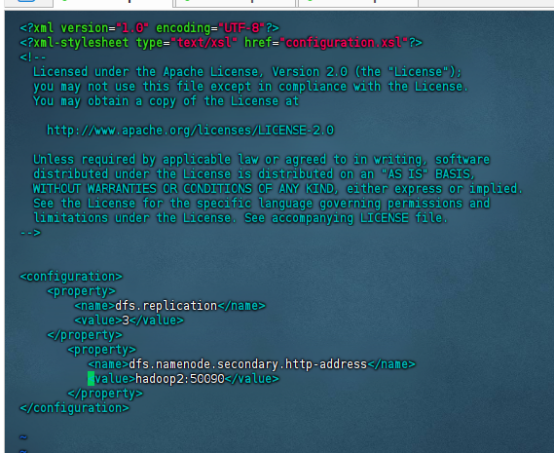
修改hdfs-site.xml文件
设置HDFS数据块的副本数量以及second namenode的地址
vim hdfs-site.xml
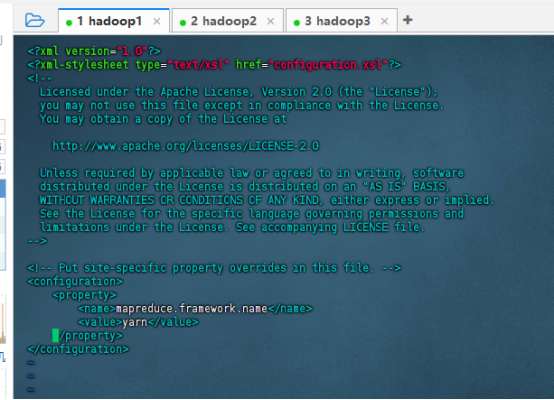
修改mapred-site.xml文件
设置MapReduce的运行时框架
vim mapred-site.xml
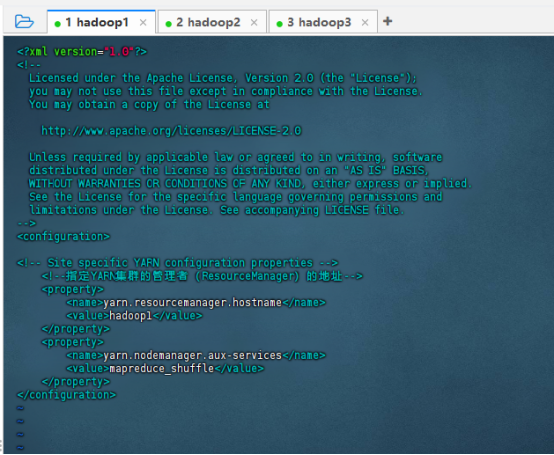
修改yarn-site.xml文件
设置yarn集群的管理者
vim yarn-site.xml
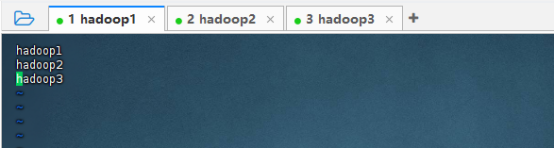
修改workers文件
该文件用来记录从节点的主机名(hadoop 2.x中为slaves文件)
打开该配置文件,先删除里面的内容(默认localhost),然后配置如下内容。
vim workers
将集群主节点的配置文件分发到其他子节点
scp -r /usr/local/hadoop/hadoop hadoop2:/usr/local/hadoop/Hadoop
scp -r /usr/local/hadoop/hadoop hadoop3:/usr/local/hadoop/hadoop
传完之后要在hadoop2和hadoop3上分别执行 source ~/.bashrc 命令,来刷新配置文件
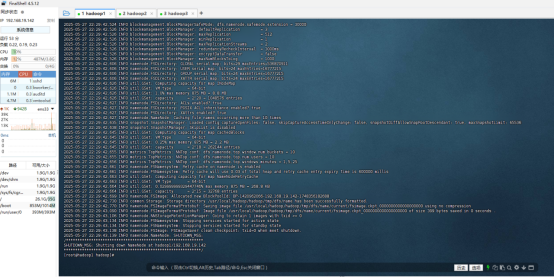
格式化文件系统
初次启动HDFS集群时,必须对主节点进行格式化处理。在hadoop1上执行格式化文件系统指令如下:
hdfs namenode -format
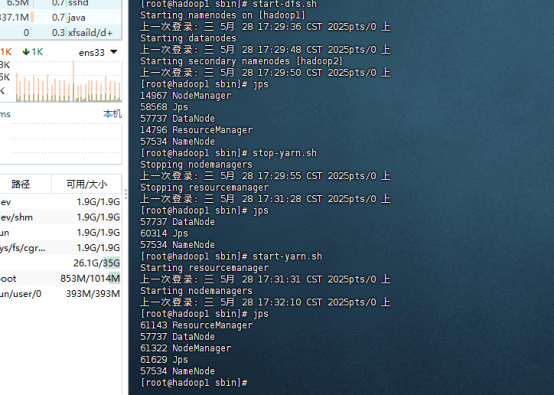
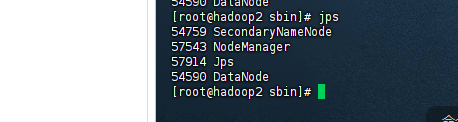
启动hadoop集群
脚本一键启动:
hadoop1主节点上执行:
start-dfs.sh
在主节点上执行
start-yarn.sh
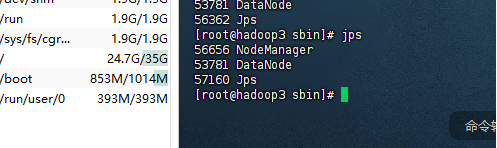
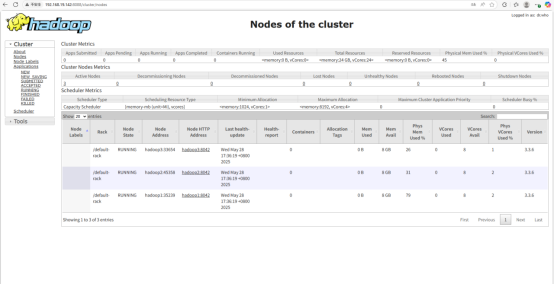
通过UI界面查看hadoop运行状态
访问地址: http://192.168.19.142:9870
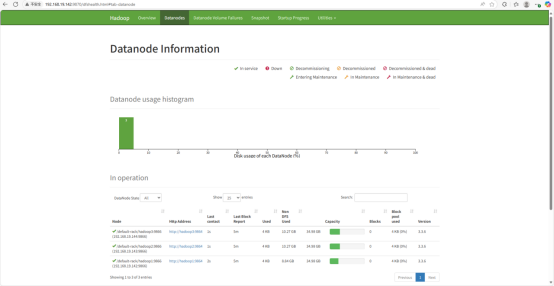
http://192.168.19.142:8088