【飞桨AI实战】基于PP-OCR和ErnieBot的智能视频问答
前言
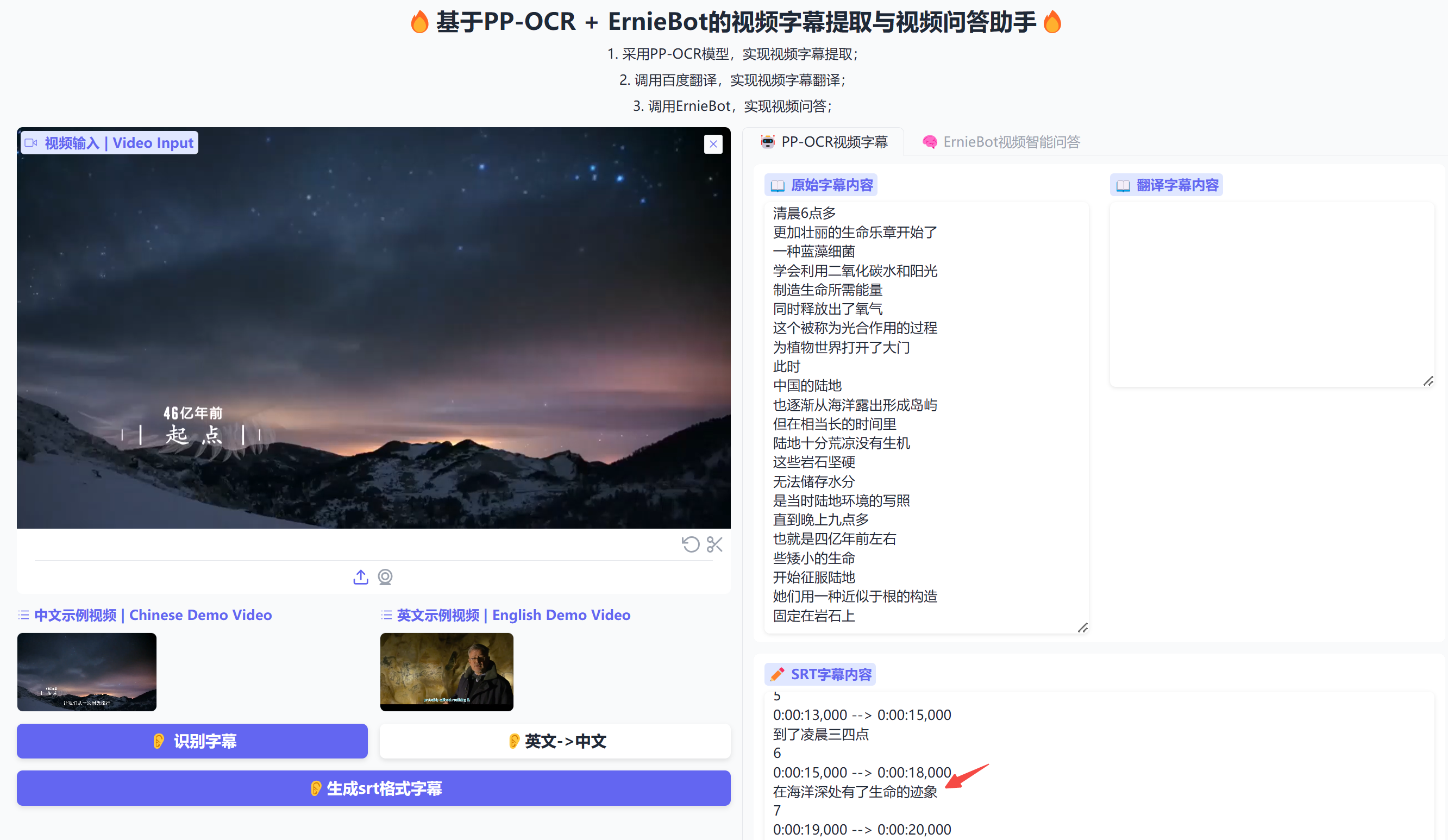
本次分享将带领大家从 0 到 1 完成一个基于 OCR 和 LLM 的视频字幕提取和智能视频问答项目,通过 OCR 实现视频字幕提取,采用 ErnieBot 完成对视频字幕内容的理解,并回答相关问题,最后采用 Gradio 搭建应用。本项目旨在帮助初学者快速搭建入门级 AI 应用,并分享开发过程中遇到的一些坑,希望对感兴趣的同学提供一点帮助。
项目背景和目标
背景:
光学字符识别(Optical Character Recognition,简称 OCR)是一种将图像中的文字转换为机器编码文本的过程。通常一个 OCR 任务的处理流程如下图所示:
 PP-OCR 是百度面向产业应用提供的 OCR 解决方案,底层采用的是两阶段 OCR 算法,即检测模型+识别模型的组成方式,其处理流程包括如下几个步骤:
PP-OCR 是百度面向产业应用提供的 OCR 解决方案,底层采用的是两阶段 OCR 算法,即检测模型+识别模型的组成方式,其处理流程包括如下几个步骤:

而视频字幕提取就是对视频中的每帧图像提取出其中的字幕文字。
大语言模型(LLM,Large Language Model)是一种先进的自然语言处理技术,当前主流的 LLM 包括 GPTs、百度文心一言、阿里通义千问、字节豆包等,而 ErnieBot 正是基于百度文心一言的智能体框架。基于提取的视频字幕,借助 LLM 强大的语义理解能力,我们可以完成很多有意思的任务,比如让 LLM 帮我们提取视频的关键信息,甚至是基于视频回答我们的问题,减轻当前大模型常见的“幻觉”-胡说八道,比如下面这张图:

目标:
- 掌握如何用 paddlepaddle 深度学习框架搭建一个文本识别模型;
- 掌握文本识别模型架构的设计原理以及构建流程;
- 掌握如何利用已有框架快速搭建应用,满足实际应用需求;
百度 AI Studio 平台
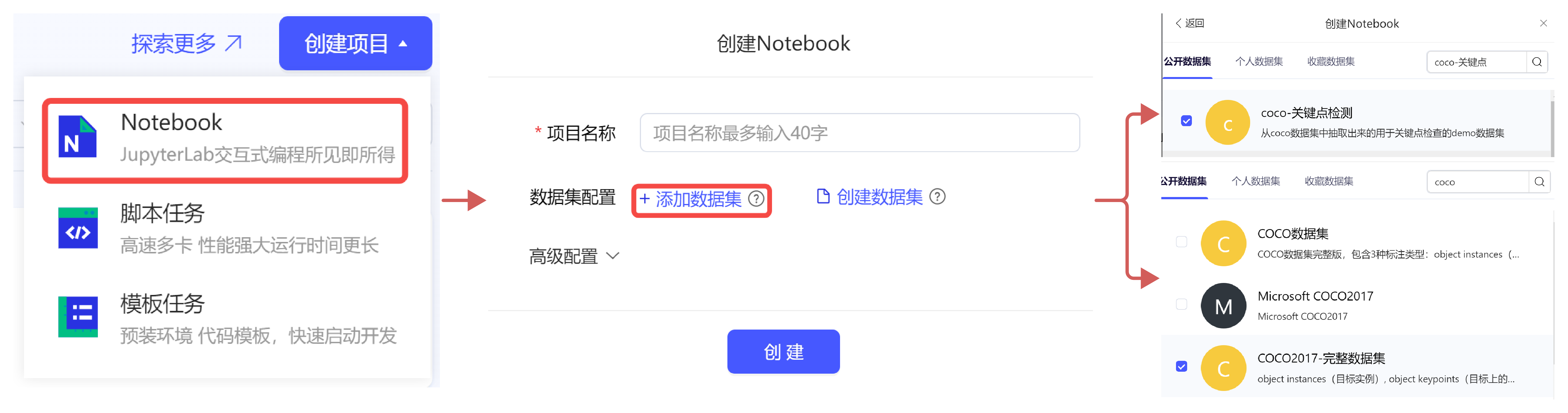
本次实验将采用 AI Studio 实训平台中的免费 GPU 资源,在平台注册账号后,点击创建项目-选择 NoteBook 任务,然后添加数据集,如下图所示,完成项目创建。启动环境可以自行选择 CPU 资源 or GPU 资源,创建任务每天有 8 点免费算力,推荐大家使用 GPU 资源进行模型训练,这样会大幅减少模型训练时长。
创建项目的方式有两种:
- 一是在 AI Studio 实训平台参考如下方式,新建项目。
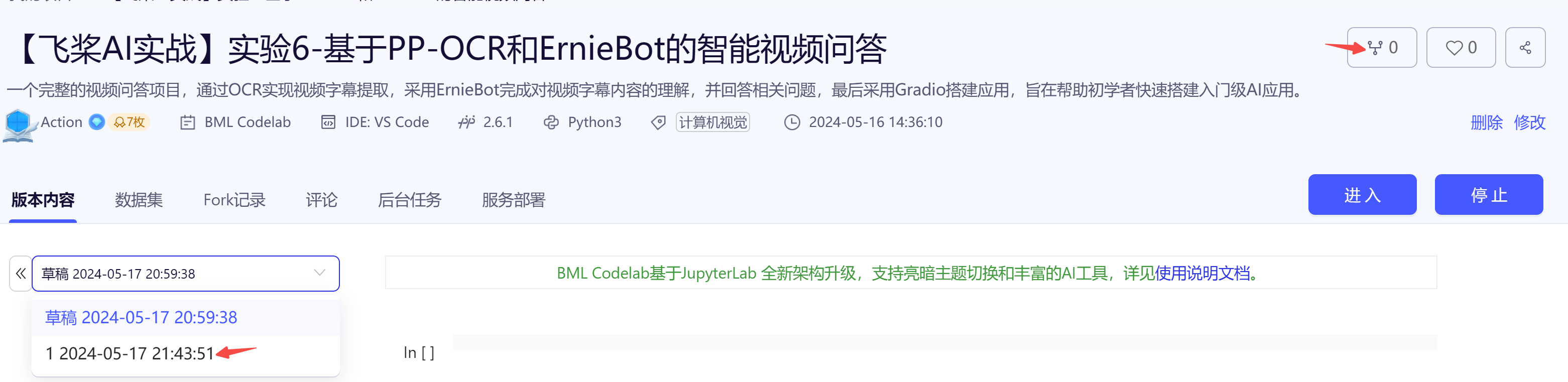
- 二是直接 fork 一个平台上的已有项目,比如本次实验,可以选择【飞桨 AI 实战】实验 6-基于 PP-OCR 和 ErnieBot 的智能视频问答的最新版本,然后点击 fork,成功后会在自己账户下新建一个项目副本,其中已经挂载了源项目自带的数据集和本次项目用到的核心代码。
为了快速跑通项目流程,建议直接 fork 源项目。
从零开始实战
1 基础:动手跑通 CRNN 文本识别任务
核心代码在:
core/文件夹下
背景:CRNN 是较早被提出也是目前工业界应用较多的文本识别方法。本节将详细介绍如何基于 PaddleOCR 完成 CRNN 文本识别模型的搭建、训练、评估和预测。数据集采用 CaptchaDataset 中文本识别部分的 9453 张图像,其中前 8453 张图像在本案例中作为训练集,后 1000 张则作为测试集。
1.1 数据准备
step 1:解压缩数据
# 打开终端
# 解压子集 -d 指定解压缩的路径,会在data0文件夹下生成
unzip data/data57285/OCR_Dataset.zip -d data0/
# 查看文件夹中文件数量
ls data0/OCR_Dataset/|wc -l
step 2: 准备数据部分代码
# 数据读取类在 reader.py, 可以执行如下脚本查看训练数据
python reader.py
可视化结果如下:

1.2 模型构建
本次实验我们将采用最简单的网络架构来搭建 CRNN 网络 并构建损失函数 CTCLoss
step 1: 搭建 CRNN 网络
# 定义模型类
net.py
step 2: 定义损失函数 CTCLoss
# 定义 loss, 位于 net.py
class CTCLoss(paddle.nn.Layer):def __init__(self, batch_size):"""