数据库介绍
1、什么是数据库
数据库是一个“广义的概念"
1. 表示一门学科
2. 表示一类软件,管理数据的软件
3. 表示某一个具体的数据库软件
4. 表示部署了某个数据库软件的主机(电脑)本专栏介绍的是具体的数据库软件:MySQL
数据库软件的主要功能是对数据的增删改查(CRUD)
2、数据库分类
数据库大体可以分为 关系型数据库 和 非关系型数据库
4. SQLite:运行速度快,占用体积小(1M大小左右的exe程序),经常在嵌入式设备中使用
关系型数据库(RDBMS):
是指采用了关系模型来组织数据的数据库。 简单来说,关系模型指的就是二维表格模型,而一个
关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。
基于标准的SQL,只是内部一些实现有区别。常用的关系型数据库如:
1. Oracle:甲骨文产品,适合大型项目,适用于做复杂的业务逻辑,如ERP、OA等企业信息系统。收费。
2. MySQL:属于甲骨文,不适合做复杂的业务。开源免费。
3. SQL Server:微软的产品,安装部署在windows server上,适用于中大型项目。收费。
非关系型数据库:
(了解)不规定基于SQL实现。现在更多是指NoSQL数据库,如:
1. 基于键值对(Key-Value):如 memcached、redis
2. 基于文档型:如 mongodb
3. 基于列族:如 hbase
4. 基于图型:如 neo4j
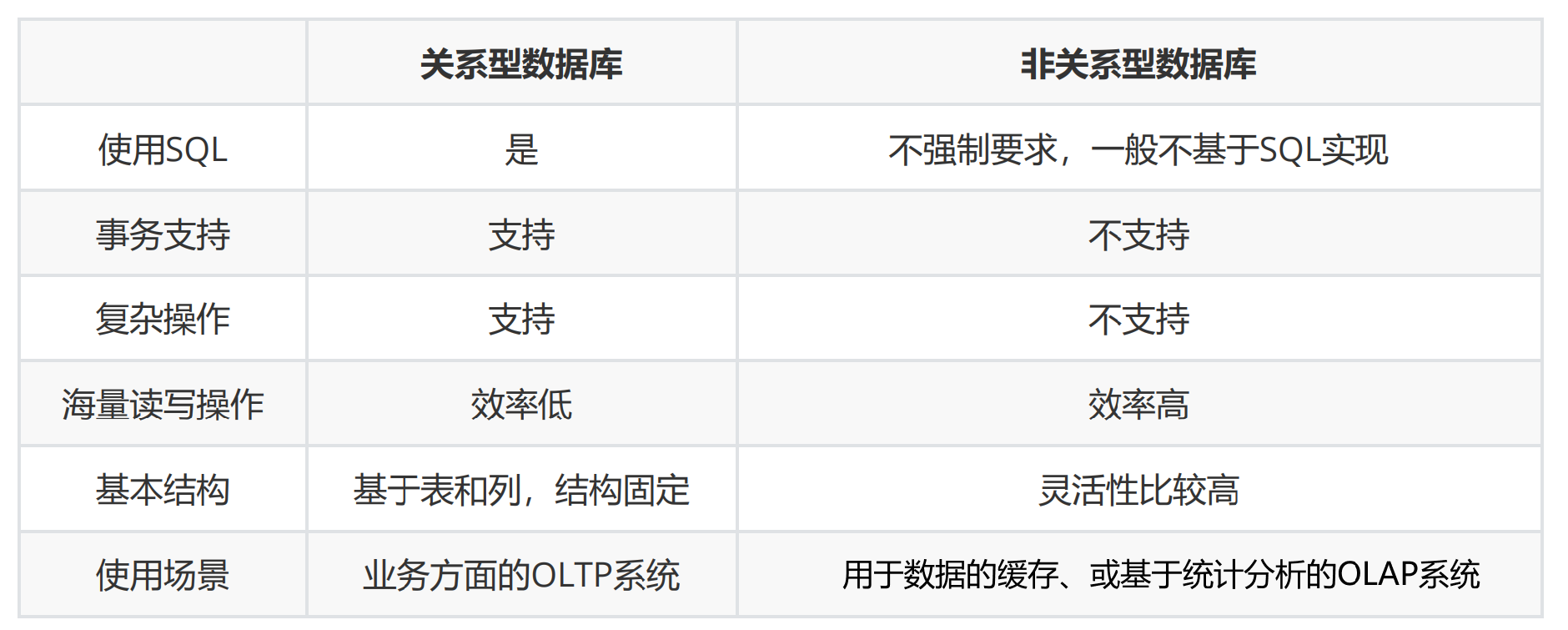
关系型数据库与非关系型数据库的区别:
关系型数据库 是使用“表”这样的结构来组织数据的,类似excel,有很多行,很多列,每一条数据,都作为一行(一个记录)一行里有很多列(一个字段)每一行的列数,列的含义都得匹配,对数据的格式要求比较高
非关系型数据库 更加灵活,会使用 “文档” / “键值对“这样的结构来组织数据,一条数据,就是一个文档,文档和文档之间,可以差异很大,键值对也没有太多的要求
关系型数据库之间差异是非常小的。学习完这里介绍的 mysql,对其他数据库 oracle 或者 sqlserver等,也是很容易上手的
3、MySQL介绍
MySQL是一个“客户端-服务器”结构的软件
MySQL的本体是服务器,在服务器这边来负责存储种管理数据
客户端-服务器:
1. 在运行程序中经常会涉及到多个程序之间相互作用,相互配合,其中客户端(Client)是主动发起请求的一方,服务器(Server)是被动接收请求的一方。
2. 客服端和服务器是往往是通过网络进行通信的
3. 客户端给服务器发起的数据,称为请求(Request);服务器给客户端返回的数据,称为响应(Response)
3. 服务器是被动的一方,它不知道客户端啥时候来,啥时候发起请求,它能做的只有等
4. 大部分服务器是给很多个客户端提供服务的,但是也有服务器是给少数一两个客户端提供服务的(分布式系统)
分布式系统:
5. 分布式系统:一台计算机,能够处理的数据是有限的,往往需要引入多台计算机,相互配合,完成更复杂的工作;分布式系统,顾名思义,就是让多台服务器、多计算单元,协同来完成整体的计算任务
6. 分布式系统中,计算机之间也是通过网络进行通信的,每台计算机既可以是服务器,也可以是客户端
4、安装MySQL
统一使用5.7.x的版本
安装完成后,建议使用第二个,两个的区别编码方式不一样,第二个是使用utf8编码

5、计算机知识
冯诺依曼体系结构(最早的电脑)
1. CPU
2.存储器(内存+硬盘)
3.输入设备
4.输出设备
现代电脑的核心硬件设备:
1.CPU(电脑最核心的部分,中央处理器)
2.主板
3.内存
4.硬盘
5.散热器
6.电源
7.机箱(鞋盒)
8.显卡(可选)
9.显示器,键盘,鼠标外设 ...
计算机使用二进制来保存和表示数据
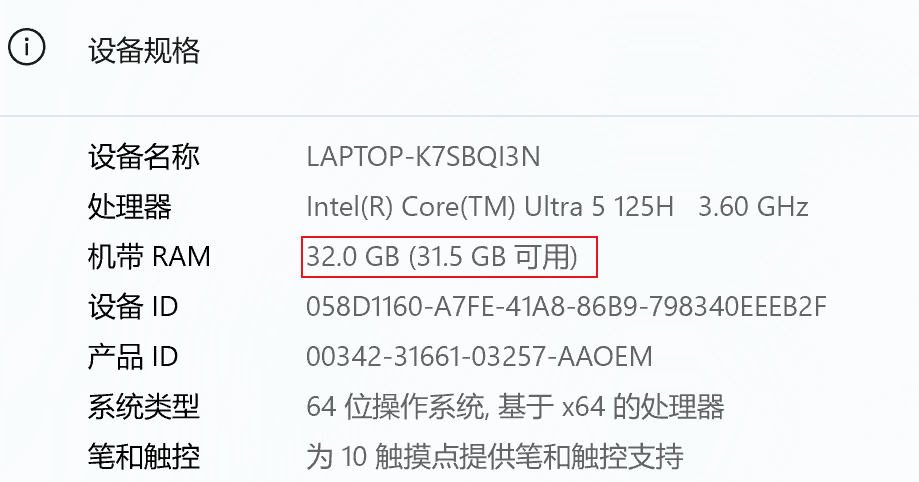
内存:例如我这台电脑的 机带RAM
手机512G内存,实际上是硬盘,手机真正的内存,是 “运存”
外存:硬盘/U盘/软盘/光盘
硬盘:
一般512g的硬盘,可用空间只有474g,因为整个硬盘不光要存储数据,还要存储一些属性(元数据)
内存和硬盘的差别:
1.内存速度快,硬盘速度慢,差几千数万倍
2.内存空间小,硬盘空间大
3.内存贵,硬盘便宜
4.内存中存储的数据是易失的,重启或掉电,就没了;硬盘中存储的数据是持久的
数据库存储的数据,希望存储的数据量比较大,持久化存储,所以一般存储在硬盘(也有少数数据库是使用内存的,追求速度的最大化,例如redis)