基于深度Retinex分解的低光照增强方法
Deep Retinex Decomposition for Low-Light Enhancement ---- 论文精读
摘要
本文提出了一种基于深度Retinex分解的低光照增强方法——Retinex-Net,旨在解决传统Retinex方法依赖手工约束、泛化能力不足的问题。核心贡献包括:
-
数据驱动的分解网络:通过构建首个真实场景低光/正常光成对数据集LOL(500对真实图像+1000对合成图像),利用Decom-Net从图像中分离反射率(R)和光照(I),约束两者共享反射率且光照平滑。
-
端到端增强框架:
-
Decom-Net:引入结构感知总变差损失(反射率梯度加权),保留光照的结构边界;
-
Enhance-Net:基于编码器-解码器调整光照,结合多尺度特征融合优化亮度分布;
-
在反射率上进行光照相关去噪(如BM3D),抑制低光噪声。
-
-
实验结果:在真实数据集(LIME、MEF等)上,Retinex-Net在视觉效果(细节保留、无过曝光)和分解质量(反射率一致性、光照平滑性)上均优于传统方法(如LIME、SRIE),验证了其有效性。
介绍
研究背景:
低光照图像因细节丢失和低对比度影响视觉质量与计算机视觉任务(如目标检测)。传统方法基于Retinex理论(图像分解为反射率R和光照I),但存在两大局限:
-
手工约束的局限性:需人工设计R和I的平滑性、一致性等约束(如TV损失),难以适应复杂场景;
-
参数敏感性:增强结果依赖参数调优,泛化能力差。
本文解决方案:
提出数据驱动的Retinex-Net,通过深度学习自动学习分解与增强:
-
构建LOL数据集:提供成对低光/正常光图像,支持网络训练;
-
联合优化分解与增强:
-
Decom-Net通过反射率共享约束和结构感知损失实现物理合理的分解;
-
Enhance-Net基于多尺度调整光照,避免全局过曝光;
-
反射率去噪抑制噪声放大。
-
-
优势:端到端训练、无需R/I标注数据、适应复杂场景。
2. 低光照增强的Retinex-Net
经典的retinex模拟了人类的颜色感知。假设观测图像可以分解为反射率和照度两个分量。设S表示源图像,则可以表示为
![]()
-
物理意义:
图像 S 可分解为反射率(R)和光照(I)的逐元素乘积(∘)。-
R: 物体固有属性(与光照无关),取值范围 [0,1]。
-
I: 光照强度,决定图像亮度分布。
-
-
作用:
为后续分解网络提供理论依据,即网络需从 S 中估计 R 和 I。
在Retinex理论的启发下,我们设计了一个深度Retinex- net来同时进行反射率/照度分解和弱光增强。该网络由分解、调整和重建三个步骤组成。在分解步骤中,Retinex-Net通过一个dec - net将输入图像分解为R和I。它在训练阶段接受低光/正光图像对,而只有低光图像作为输入测试阶段。在低光/正光图像具有相同反射率和光照平滑度的约束下,dec - net以数据驱动的方式学习提取不同光照图像之间的一致R。在调整步骤中,使用增强网对照度图进行增亮。
Enhance-Net采用了一个编码器-解码器的整体框架。采用多尺度级联的方法,在大范围内保持光照与上下文信息的全局一致性,同时通过集中注意力调整局部分布。此外,在低光条件下经常出现的放大噪声可以从反射率中去除。然后,在重建阶段通过逐元乘法将调整后的照度和反射率结合起来。
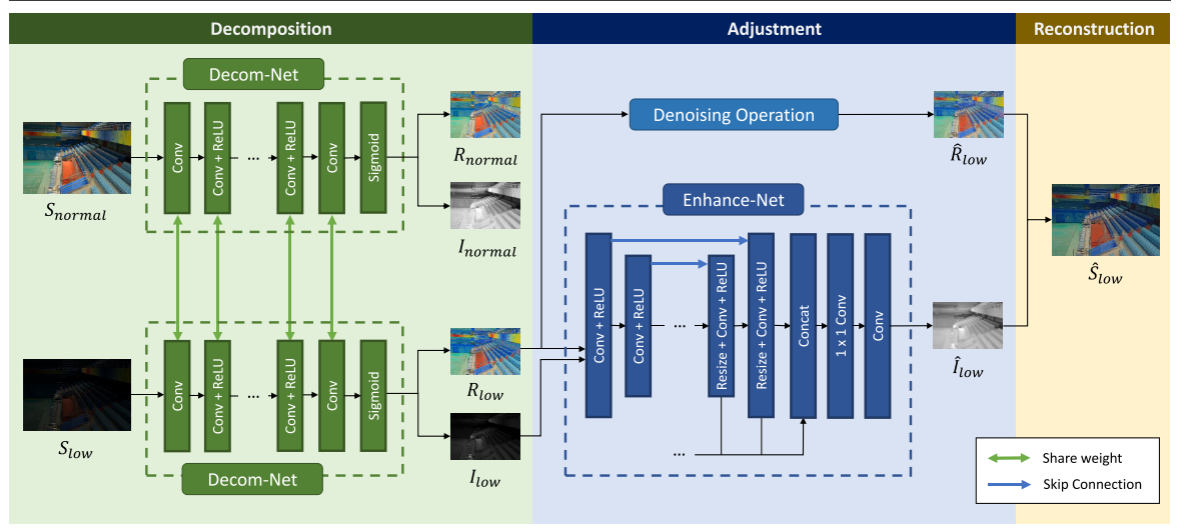
2.1 数据驱动的图像分解

训练过程:
1. 网络架构
-
特征提取:输入图像通过多个 3×3 卷积层(ReLU激活)映射到高维特征空间。最后一层卷积 + Sigmoid 输出 R 和 I(值域约束到 [0,1])。
-
共享权重:
Slow 和 Snormal 使用同一Decom-Net处理,强制网络学习光照无关的反射率。
2.损失函数设计



3. 训练策略
-
输入处理:随机裁剪 96×96 图像块,batch size=16。
- 多任务平衡:通过 λir、λis 控制各损失项贡献,端到端训练:Decom-Net与Enhance-Net联合优化。
2.2结构感知平滑损失
为了使损失感知图像结构,对原TV函数用反射率图的梯度进行加权。最终的Lis公式为:
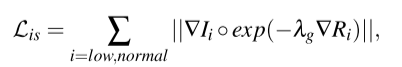
 2.3多尺度照度调节
2.3多尺度照度调节
(a) 编码器-解码器框架
-
编码器(下采样):由多个下采样块组成,每个块包含:
-
逐步压缩空间尺寸,提取全局光照分布特征。
-
卷积层(stride=2) + ReLU
-
作用:捕获图像的大尺度光照上下文(如整体亮度分布)。
-
解码器(上采样):
-
由上采样块组成,每个块包含:
-
最近邻插值 + 卷积层(stride=1) + ReLU
-
逐步恢复空间分辨率,重建局部光照细节。
-
-
作用:基于全局信息调整局部光照。
-
-
跳跃连接(Skip Connection)
(b) 多尺度特征融合
-
操作步骤:
-
从解码器的每一层上采样块提取特征图 Fm(共 M 层,每层 C 通道)。
-
将所有 Fm 上采样至最终输出尺寸(最近邻插值)。
-
沿通道维度拼接,得到 C×M 维特征。
-
通过 1×1 卷积降维至 C 通道,再经 3×3 卷积输出 I^。
-
-
设计动机:
-
全局一致性:深层特征(低分辨率)指导整体亮度调整。
-
局部适应性:浅层特征(高分辨率)优化细节光照。
-

2.4反射去噪
在分解步骤中,对网络施加了几个约束,其中一个约束是光照映射的结构感知平滑性。当估计的光照贴图是平滑的,细节都保留在反射率上,包括增强的噪声。因此,在用光照映射重建输出图像之前,我们可以对反射率进行去噪处理。考虑到在分解过程中,暗区噪声会根据亮度的强弱被放大,我们应该采用与光照相关的去噪方法。
3.数据集
我们构建了一个新的低光增强网络,该网络由两类组成:真实摄影对和原始图像合成对。第一个捕获了真实情况下的退化特征和特性。第二种是数据增强,使场景和对象多样化。
(略)
4.实验
4.1实现细节
4.2分解结果
在图5中,我们展示了LOL数据集评估集中的低光/正光图像对,以及通过decomd - net和LIME分解的反射率和照度图。补充文件中提供了更多示例。结果表明,我们的反网络可以从文本区域和平滑区域的不同光照条件下的一对图像中提取出基本一致的反射率。弱光图像的反射率与正常光图像的反射率相似,只是真实场景中暗区出现了放大的噪声。另一方面,照明映射描绘图像上的亮度和阴影。与我们的结果相比,LIME在反射率上留下了很多照明信息(见架子上的阴影)。

4.3评估
(略)
4.4联合弱光增强与去噪
考虑到综合性能,在Retinex-Net中采用BM3D作为去噪操作。结果:retex - net可以更好地保留细节,而LIME和JED则会模糊边缘。
5.结论
本文提出了一种深度Retinex分解方法,该方法可以在不需要分解的反射率和照度的ground truth的情况下,以数据驱动的方式学习将观测图像分解为反射率和照度。随后介绍了光照增强和反射率去噪操作。分解网络和弱光增强网络进行端到端训练。实验结果表明,该方法具有较好的图像分解效果和视觉增强效果。