Arthas实际应用与实战
文章目录
- 1. Arthas简介
- 2. Arthas的安装与使用
- 2.1 安装Arthas
- 2.2 基本使用流程
- 3. Profiler功能详解
- 3.1 profiler命令基本用法
- 3.2 生成CPU火焰图
- 3.3 火焰图解读
- 3.4 采样其他事件
- 3.5 高级用法
- 4. Arthas常用性能分析命令
- 4.1 dashboard命令
- 4.2 thread命令
- 4.3 trace命令
- 4.4 monitor命令
- 4.5 watch命令
- 4.6 stack命令
- 4.7 tt命令
- 4.8 jvm命令
- 内存相关指标
- GC相关指标
- 线程相关指标
- 线程状态分布
- 类加载指标
- 运行时指标
- 文件描述符
- 4.9 heapdump命令
- 4.10 vmtool命令
- 5. 线上调优实战案例
- 5.1 案例一:使用profiler定位CPU使用率过高问题
- 问题背景
- 问题分析
- 解决方案
- 5.2 案例二:使用trace和watch定位接口超时问题
- 问题背景
- 问题分析
- 解决方案
- 5.3 案例三:使用Arthas解决OkHttpClient内存泄漏问题
- 问题背景
- 问题分析
- 解决方案
- 6. 线上Debug功能介绍
- 6.1 jad命令:反编译类
- 6.2 sc命令:查找类
- 6.3 sm命令:查找方法
- 6.4 ognl命令:执行表达式
- 6.5 redefine命令:重定义类
- 6.6 tt命令:时间隧道
- 6.7 watch命令:观察方法执行
- 6.8 实际调试案例
- 问题背景
- 调试过程
- 解决方案
- 7. Arthas最佳实践与总结
- 7.1 性能分析最佳实践
- 7.2 线上调试最佳实践
- 7.3 常见问题与解决方案
- 7.4 总结
1. Arthas简介
Arthas(阿尔萨斯)是阿里巴巴开源的一款强大的Java应用诊断工具,专为线上问题定位而生。它允许开发者在不修改应用代码的情况下,实时查看应用的运行状态,包括JVM信息、线程堆栈、方法调用、类加载等,极大地提升了线上问题排查效率。
Arthas的主要特点包括:
- 无侵入性:不需要修改应用代码,不需要重启应用
- 实时监控:可以实时查看应用的运行状态
- 丰富的功能:提供了大量的命令,覆盖了性能分析、线程分析、类加载分析等多个方面
- 易于使用:采用命令行交互模式,支持自动补全
- 跨平台:支持Linux/Mac/Windows,适用于各种环境
在实际生产环境中,我们经常会遇到以下问题:
- 应用响应缓慢,但不知道哪里是瓶颈
- 某个方法执行异常,但无法确定原因
- 线上环境出现问题,但无法使用调试器
- 代码逻辑复杂,难以追踪执行流程
这些问题在传统开发模式下往往需要添加日志、重新部署等繁琐步骤才能解决。而使用Arthas,我们可以直接连接到运行中的应用,实时查看各种信息,快速定位问题所在。
2. Arthas的安装与使用
2.1 安装Arthas
Arthas的安装非常简单,只需要一行命令:
curl -O https://arthas.aliyun.com/arthas-boot.jar
java -jar arthas-boot.jar
执行上述命令后,Arthas会列出当前系统中所有的Java进程,我们只需要选择要诊断的进程即可。
2.2 基本使用流程
- 启动Arthas并选择目标进程
- 使用各种命令进行诊断
- 分析结果,定位问题
- 退出Arthas(使用
quit或exit命令)
Arthas提供了丰富的命令,每个命令都有特定的用途。在接下来的章节中,我们将详细介绍一些常用的命令,特别是与性能分析相关的命令。
3. Profiler功能详解
Arthas的profiler命令是一个强大的性能分析工具,它可以生成应用热点的火焰图,帮助我们快速定位性能瓶颈。本质上,profiler是通过不断采样,然后将采样结果生成火焰图来实现的。
3.1 profiler命令基本用法
profiler命令的基本结构是:
profiler action [actionArg]
其中,action表示要执行的操作,actionArg是操作的参数。以下是一些常用的操作:
start:启动profiler,开始采样stop:停止profiler,并生成结果status:查看profiler的状态list:列出所有支持的事件resume:恢复profilergetSamples:获取已收集的样本数
3.2 生成CPU火焰图
生成CPU火焰图是profiler最常用的功能之一。以下是基本步骤:
- 启动profiler,开始采样CPU事件:
profiler start
默认情况下,profiler会采样CPU事件。我们也可以指定采样间隔和采样事件:
profiler start --interval 10 --event cpu
高亮显示特定包下的方法
profiler start --include "com.example.*"
可以同时指定多个包进行高亮
profiler start --include "com.example.*,org.springframework.*"
排除特定包,同时高亮其他包
profiler start --include "com.example.*" --exclude "com.example.util.*"
-
等待一段时间,让应用运行并收集足够的样本
-
停止profiler,生成火焰图:
profiler stop --format html
这将生成一个HTML格式的火焰图,并输出文件路径。我们可以在浏览器中打开这个文件查看火焰图。
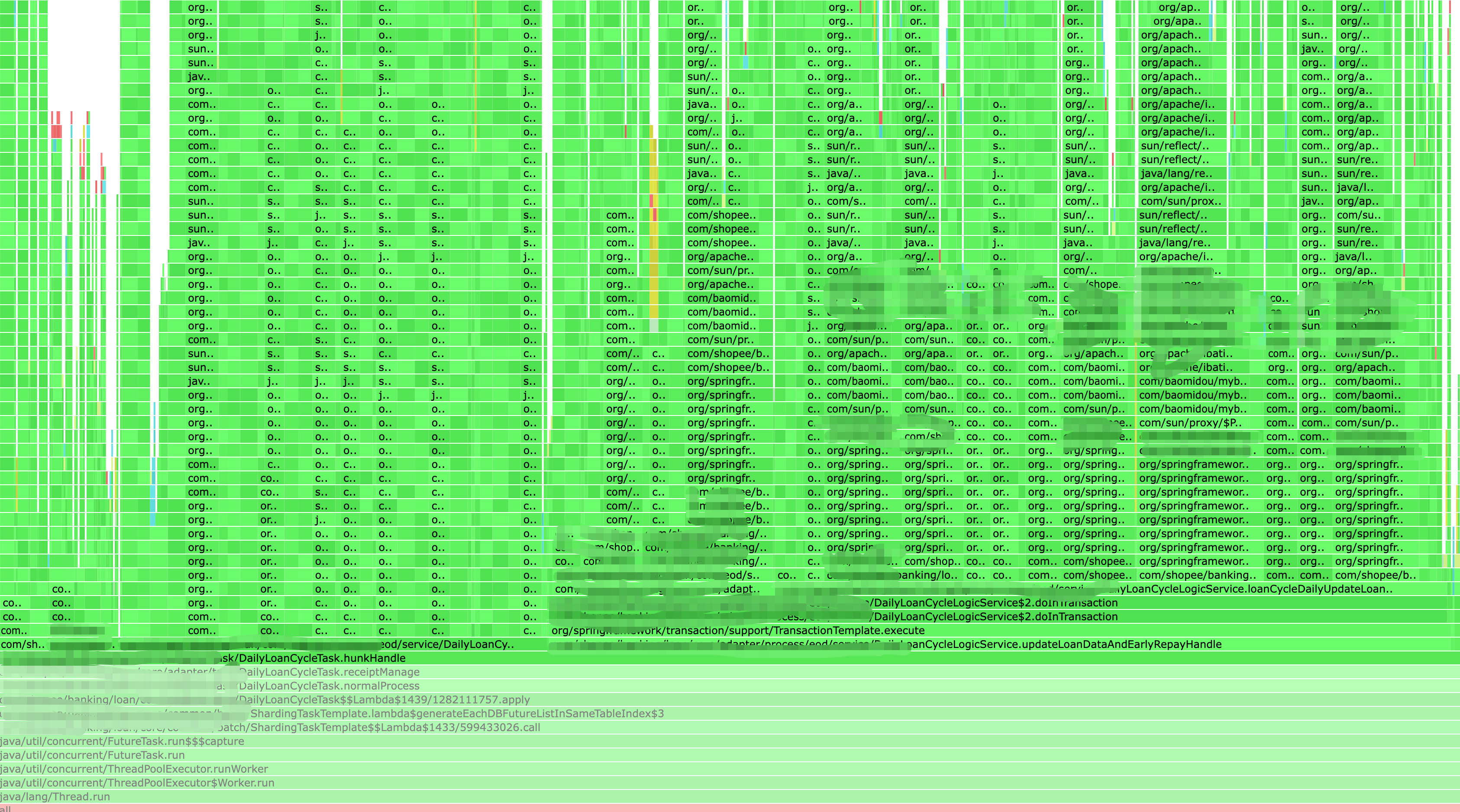
3.3 火焰图解读
火焰图是一种直观展示程序运行热点的图形化工具。在火焰图中:
- 每一层代表一个函数调用栈
- 每个方块的宽度代表其在采样中出现的频率,越宽表示消耗的CPU时间越多
- 颜色没有特殊含义,主要是为了区分不同的方块
- 纵向表示调用栈的深度,顶层函数调用底层函数
- 横向表示时间占比,从左到右不代表时间顺序
通过分析火焰图,我们可以快速找出以下问题:
- CPU使用率高的方法
- 调用次数过多的方法
- 调用链路过深的方法
3.4 采样其他事件
除了CPU事件外,profiler还支持采样其他类型的事件,如内存分配、锁竞争等。以下是一些常用的事件类型:
cpu:CPU使用情况alloc:内存分配情况lock:锁竞争情况wall:墙钟时间,包括I/O、网络等阻塞时间cache-misses:缓存未命中情况
例如,要采样内存分配情况,可以使用:
profiler start --event alloc
3.5 高级用法
profiler还提供了一些高级用法,如:
- 过滤特定包名:
profiler start --include "com.example.*" --exclude "com.example.util.*"
- 指定采样时间:
profiler start --duration 30
- 指定输出格式:
profiler stop --format svg
- 指定输出文件:
profiler stop --file /tmp/result.html
通过这些高级用法,我们可以更精确地控制profiler的行为,获取更有针对性的性能数据。
4. Arthas常用性能分析命令
除了profiler功能外,Arthas还提供了许多其他命令用于性能分析和问题排查。这些命令各有特点,可以从不同角度帮助我们分析应用性能。
4.1 dashboard命令
dashboard命令是Arthas中最常用的命令之一,它可以实时显示系统的运行状态,包括线程、内存、GC、运行环境等信息。
dashboard
执行该命令后,Arthas会每隔一段时间刷新一次数据,显示当前系统的状态。通过dashboard,我们可以快速了解:
- 系统负载情况
- 内存使用情况
- 垃圾回收情况
- 线程数量及状态
- CPU使用率最高的线程
这对于初步判断系统是否存在性能问题非常有帮助。例如,如果发现某个线程的CPU使用率异常高,我们可以进一步使用thread命令查看该线程的详细信息。
4.2 thread命令
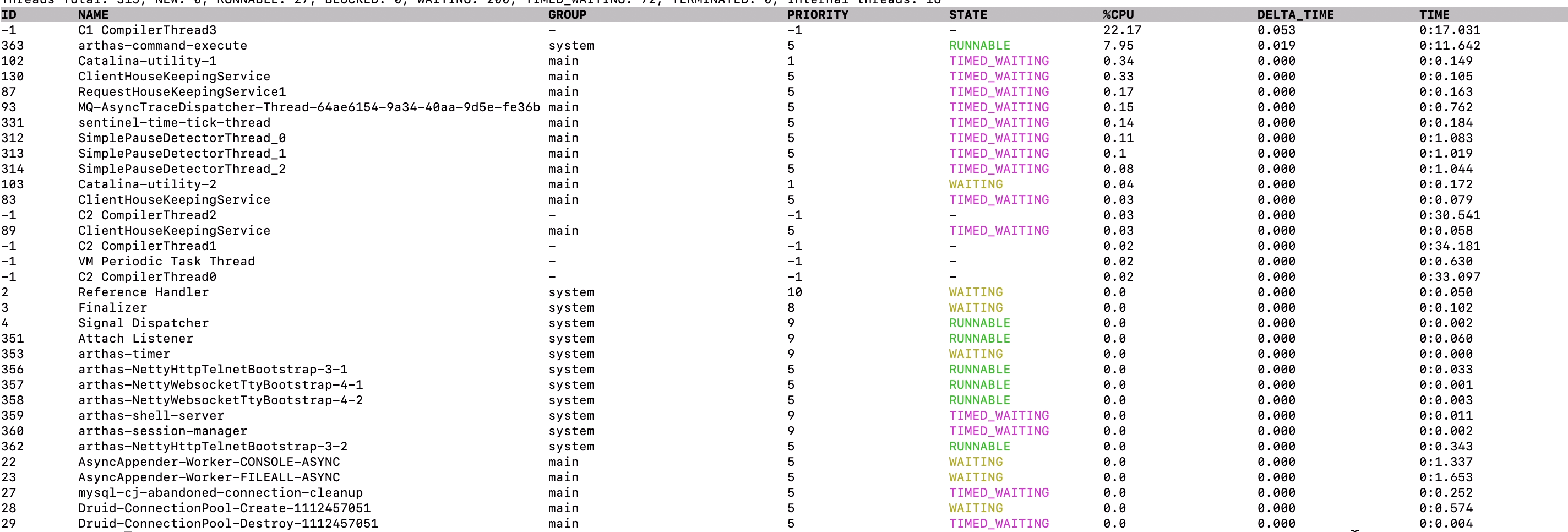
thread命令用于查看当前JVM的线程信息,包括线程的状态、CPU使用率、堆栈等。
# 查看所有线程
thread
# 查看指定线程的堆栈
thread 1
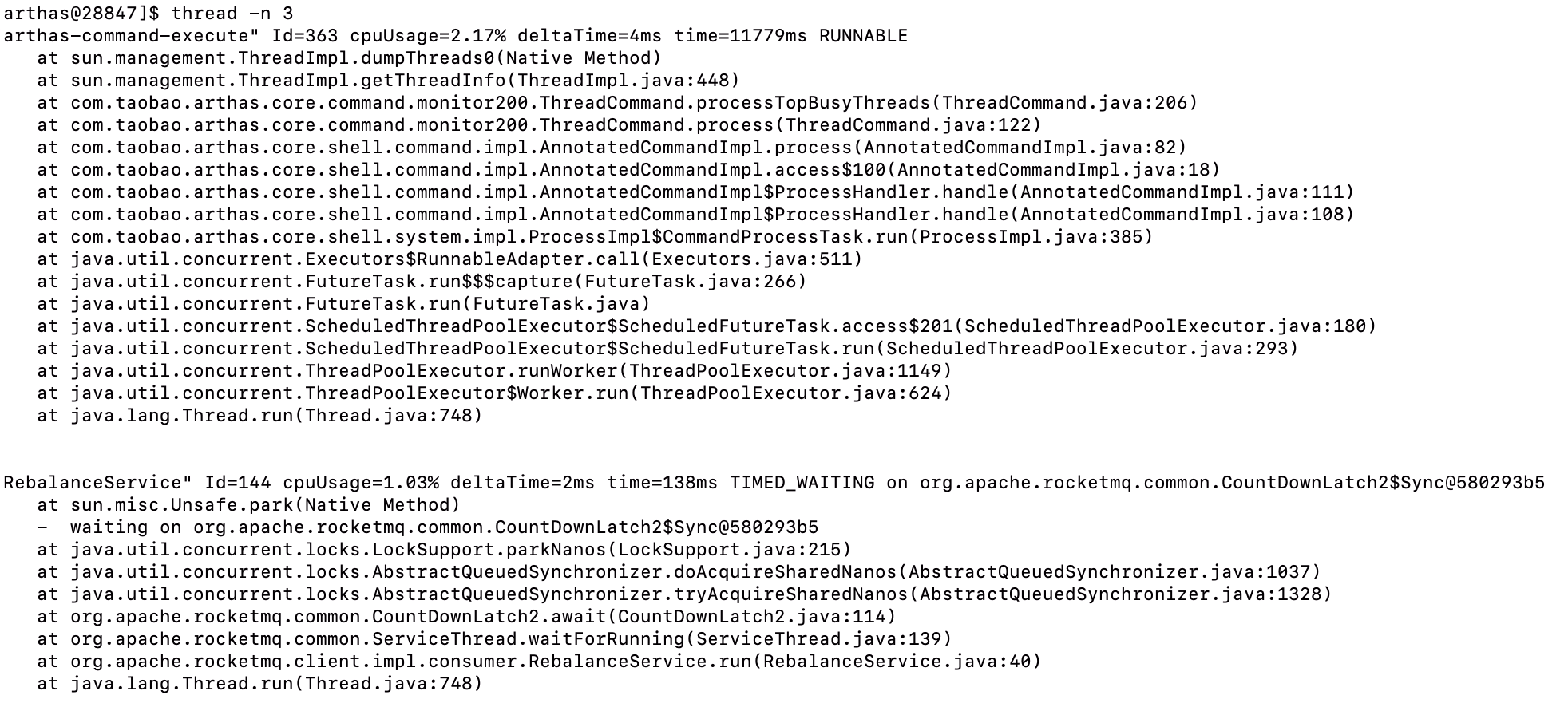
# 查看CPU使用率前N的线程
thread -n 3
# 查看指定状态的线程
thread -state BLOCKED
通过thread命令,我们可以快速定位到哪些线程可能存在问题,如:
- CPU使用率过高的线程
- 长时间处于BLOCKED状态的线程(可能存在死锁)
- 长时间处于WAITING状态的线程(可能存在资源等待)
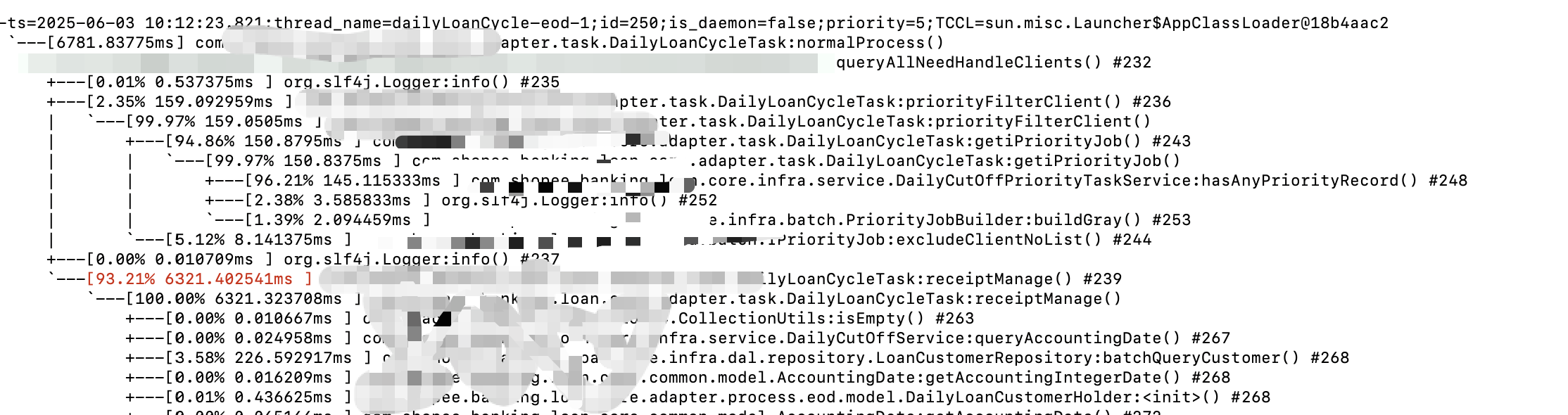
4.3 trace命令
trace命令是一个非常强大的命令,它可以跟踪方法的调用路径和耗时,帮助我们找出方法执行的瓶颈。
# 跟踪指定类的指定方法
trace com.example.demo.service.UserService getUserById# 跟踪指定类的所有方法
trace com.example.demo.service.UserService *# 限制跟踪的次数
trace com.example.demo.service.UserService getUserById -n 5# 限制跟踪的耗时(单位:ms)
trace com.example.demo.service.UserService getUserById '#cost > 10'#追踪多个方法和类
trace -E com.test.ClassA|org.test.ClassB method1|method2|method3trace命令的输出会显示方法调用的层次结构和每个方法的耗时,这对于定位性能瓶颈非常有帮助。例如,我们可以发现某个SQL查询或远程调用耗时过长。
4.4 monitor命令
monitor命令用于监控方法的执行情况,包括调用次数、成功率、平均耗时等。
# 监控指定类的指定方法
monitor com.example.demo.service.UserService getUserById# 监控指定类的所有方法
monitor com.example.demo.service.UserService *# 指定监控的时间间隔(单位:秒)
monitor -c 5 com.example.demo.service.UserService getUserById
monitor命令的输出会显示方法在一段时间内的执行统计信息,包括:
- 调用次数
- 成功次数
- 失败次数
- 平均耗时
- 失败率
这对于了解方法的整体执行情况非常有帮助。
4.5 watch命令
watch命令用于观察方法的入参和返回值,以及方法执行前后的对象状态变化。
# 观察方法的返回值
watch com.example.demo.service.UserService getUserById '{params, returnObj}'# 观察方法的入参和异常
watch com.example.demo.service.UserService getUserById '{params, throwExp}'# 观察方法执行前后的对象状态变化
watch com.example.demo.service.UserService getUserById '{params, returnObj}' -b -f# 观察方法执行的耗时
watch com.example.demo.service.UserService getUserById '{params, returnObj, #cost}'
watch命令的强大之处在于它可以观察方法执行的各个阶段(-b 执行前,-e 执行后,-s 异常抛出,-f 方法结束),并且可以使用OGNL表达式对结果进行处理。
4.6 stack命令
stack命令用于查看方法的调用堆栈,帮助我们了解方法是如何被调用的。
# 查看指定方法的调用堆栈
stack com.example.demo.service.UserService getUserById# 根据条件查看调用堆栈
stack com.example.demo.service.UserService getUserById 'params[0]==1'# 限制堆栈的深度
stack com.example.demo.service.UserService getUserById -n 3
通过stack命令,我们可以了解方法的调用链路,找出是哪些上层方法调用了目标方法,这对于理解代码流程和定位问题非常有帮助。
4.7 tt命令
tt(Time Tunnel)命令是一个非常特殊的命令,它可以记录方法的每次调用,并且可以对这些调用进行回放。
# 记录方法的调用
tt -t com.example.demo.service.UserService getUserById# 查看记录的调用
tt -l# 查看指定调用的详细信息
tt -i 1000# 重新执行指定的调用
tt -i 1000 -p
tt命令的强大之处在于它可以"穿越时间",让我们重新执行之前的方法调用,这对于复现和调试问题非常有帮助。

4.8 jvm命令
jvm命令用于查看JVM的详细信息,包括内存使用、GC情况、线程数量等。
jvm
通过jvm命令,我们可以了解JVM的整体状况,包括:
- JVM参数
- 内存使用情况
- GC情况
- 线程数量
- 类加载情况
这对于了解JVM的运行状态非常有帮助。
内存相关指标
| 指标名称 | 含义 | 关注点 |
|---|---|---|
| HEAP | Java堆内存使用情况 | 使用率超过80%需关注 |
| PS_EDEN_SPACE | 年轻代中Eden区内存使用情况 | 频繁占满可能导致Minor GC频繁 |
| PS_SURVIVOR_SPACE | 年轻代中Survivor区内存使用情况 | 经常占满可能导致对象过早进入老年代 |
| PS_OLD_GEN | 老年代内存使用情况 | 使用率持续增长可能存在内存泄漏 |
| NON-HEAP | 非堆内存使用情况 | 包括方法区、代码缓存等 |
| CODE_CACHE | JIT编译代码的缓存区 | 满了会导致JIT编译停止,影响性能 |
| METASPACE | 元空间,存储类的元数据信息 | 持续增长可能存在类加载泄漏 |
| COMPRESSED_CLASS_SPACE | 压缩类空间 | 通常与Metaspace一起关注 |
GC相关指标
| 指标名称 | 含义 | 关注点 |
|---|---|---|
| gc.ps_scavenge.count | 年轻代垃圾收集器执行次数 | 频率过高表明对象创建过多 |
| gc.ps_scavenge.time(ms) | 年轻代垃圾收集器执行总时间 | 单次耗时长可能影响响应时间 |
| gc.ps_marksweep.count | 老年代垃圾收集器执行次数 | 频繁Full GC表明内存压力大 |
| gc.ps_marksweep.time(ms) | 老年代垃圾收集器执行总时间 | 耗时长会导致应用暂停明显 |
线程相关指标
| 指标名称 | 含义 | 关注点 |
|---|---|---|
| COUNT | 当前活跃线程总数 | 数量过多可能导致资源竞争 |
| DAEMON-COUNT | 守护线程数量 | 通常用于后台服务 |
| PEAK-COUNT | 峰值线程数 | 反映历史最高线程使用量 |
| STARTED-COUNT | 启动过的线程总数 | 持续增长可能存在线程创建未复用 |
| DEADLOCK-COUNT | 死锁线程数量 | 非0表示存在死锁,需立即处理 |
线程状态分布
| 状态 | 含义 | 关注点 |
|---|---|---|
| NEW | 新创建但未启动的线程数 | 通常应该很少 |
| RUNNABLE | 正在运行或可运行的线程数 | 反映活跃工作线程 |
| BLOCKED | 被阻塞等待锁的线程数 | 数量大表明锁竞争严重 |
| WAITING | 无限期等待的线程数 | 可能是等待资源或信号 |
| TIMED_WAITING | 有限期等待的线程数 | 通常是执行了sleep或wait(timeout) |
| TERMINATED | 已终止的线程数 | 应该很少,否则可能有线程管理问题 |
类加载指标
| 指标名称 | 含义 | 关注点 |
|---|---|---|
| LOADED-CLASS-COUNT | 当前已加载的类数量 | 持续增长可能存在类加载泄漏 |
| TOTAL-LOADED-CLASS-COUNT | JVM启动以来加载的类总数 | 反映应用复杂度 |
| UNLOADED-CLASS-COUNT | JVM启动以来卸载的类数量 | 反映类的生命周期管理 |
运行时指标
| 指标名称 | 含义 | 关注点 |
|---|---|---|
| UPTIME | JVM运行时间 | 反映应用稳定性 |
| START-TIME | JVM启动时间 | 用于确定启动时刻 |
| PROCESS-CPU-TIME | 进程CPU时间 | 反映CPU资源消耗 |
| PROCESS-CPU-LOAD | 进程CPU负载 | 超过核心数表明CPU瓶颈 |
| SYSTEM-CPU-LOAD | 系统CPU负载 | 反映整体系统压力 |
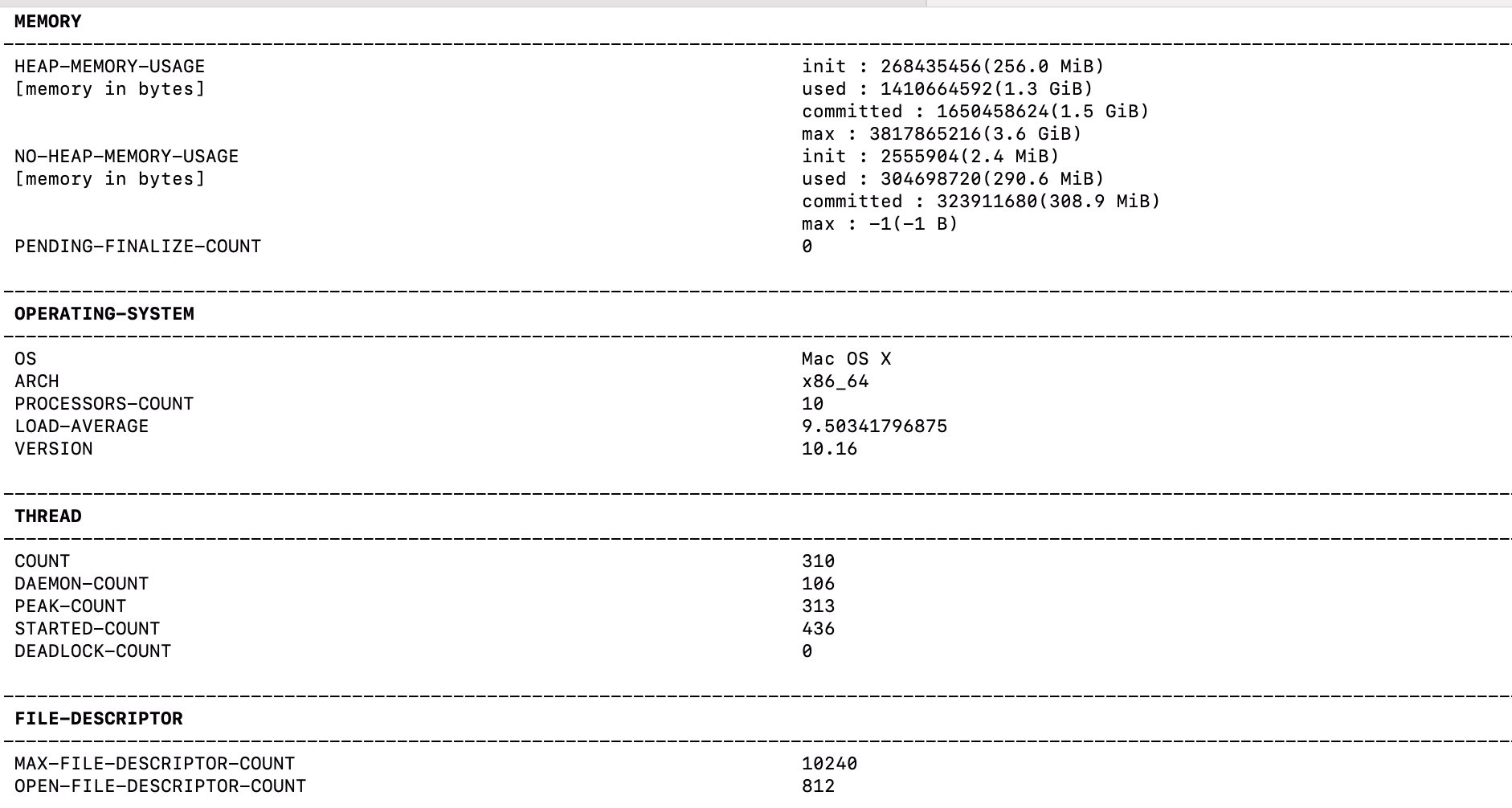
文件描述符
| 指标名称 | 含义 | 关注点 |
|---|---|---|
| MAX-FILE-DESCRIPTOR-COUNT | 最大文件描述符数量 | 系统限制 |
| OPEN-FILE-DESCRIPTOR-COUNT | 当前打开的文件描述符数量 | 接近最大值可能导致"Too many open files" |
4.9 heapdump命令
heapdump命令用于生成堆转储文件,帮助我们分析内存使用情况。
# 生成堆转储文件
heapdump /tmp/dump.hprof# 只转储活跃对象
heapdump --live /tmp/dump.hprof
生成的堆转储文件可以使用MAT(Memory Analyzer Tool)等工具进行分析,帮助我们找出内存泄漏的原因。
4.10 vmtool命令
vmtool命令是一个底层命令,它可以执行一些JVM相关的操作,如强制GC。
# 强制执行GC
vmtool --action forceGc
通过vmtool命令,我们可以执行一些特殊的JVM操作,这在某些场景下非常有用。
5. 线上调优实战案例
在本章节中,我们将通过几个真实的线上调优案例,展示如何使用Arthas解决实际生产环境中的性能问题。
5.1 案例一:使用profiler定位CPU使用率过高问题
问题背景
某电商系统在促销活动期间出现了CPU使用率异常高的情况,导致系统响应缓慢,影响用户体验。运维团队发现某个Java进程的CPU使用率长时间维持在90%以上,但无法确定具体是哪部分代码导致的问题。
问题分析
- 首先,使用
dashboard命令查看系统整体状况:
$ dashboard
ID NAME GROUP PRIORITY STATE %CPU DELTA_TIME TIME INTERRUPTED DAEMON
-1 VM Periodic Task Thread - -1 - 0.02 0.000 0:0.068 false true
1 main main 5 RUNNABLE 0.02 0.000 0:0.336 false false
2 Reference Handler system 10 WAITING 0.00 0.000 0:0.000 false true
3 Finalizer system 8 WAITING 0.00 0.000 0:0.000 false true
4 Signal Dispatcher system 9 RUNNABLE 0.00 0.000 0:0.000 false true
11 AsyncAppender-Worker-arthas-cache system 9 WAITING 0.00 0.000 0:0.000 false true
12 Attach Listener system 9 RUNNABLE 0.00 0.000 0:0.000 false true
13 http-nio-8080-exec-1 http-nio-8080-Acceptor 5 RUNNABLE 90.05 0.000 0:30.076 false true
14 http-nio-8080-exec-2 http-nio-8080-Acceptor 5 WAITING 0.00 0.000 0:0.000 false true
从输出可以看到,http-nio-8080-exec-1线程的CPU使用率高达90.05%,明显异常。
- 接下来,使用
thread命令查看该线程的堆栈:
$ thread 13
"http-nio-8080-exec-1" Id=13 RUNNABLEat com.example.service.ProductService.calculateDiscount(ProductService.java:67)at com.example.service.ProductService.getProductsWithDiscount(ProductService.java:42)at com.example.controller.ProductController.listProducts(ProductController.java:28)at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:498)...
从堆栈可以看到,问题出在ProductService.calculateDiscount方法。
- 使用
profiler命令生成火焰图,进一步分析:
$ profiler start
Started [cpu] profiling
$ profiler status
[cpu] profiling is running for 4 seconds
$ profiler stop
profiler output file: /tmp/demo/arthas-output/20230602-134500.html
- 分析火焰图,发现
calculateDiscount方法中的循环计算逻辑占用了大量CPU时间
解决方案
通过分析源码,发现calculateDiscount方法中存在一个不必要的嵌套循环,每次请求都会重复计算相同的折扣信息。优化方案如下:
- 使用缓存存储计算结果,避免重复计算
- 优化算法,减少循环次数
- 将部分计算逻辑移至离线处理,减轻在线服务压力
实施优化后,再次使用profiler命令生成火焰图,确认CPU使用率已经降低到正常水平。
5.2 案例二:使用trace和watch定位接口超时问题
问题背景
某支付系统的订单查询接口偶发性出现超时,但无法稳定复现,给问题排查带来了困难。
问题分析
- 使用
trace命令跟踪接口的执行路径和耗时:
$ trace com.example.controller.OrderController queryOrder '#cost > 1000'
这里设置了条件,只跟踪执行时间超过1000ms的调用。
- 经过一段时间的监控,捕获到一次超时调用:
`---ts=2023-06-02 14:15:30;thread_name=http-nio-8080-exec-5;id=13;is_daemon=true;priority=5;TCCL=org.springframework.boot.web.embedded.tomcat.TomcatEmbeddedWebappClassLoader@5c45d770`---[3256.106485ms] com.example.controller.OrderController:queryOrder()+---[0.045435ms] com.example.controller.OrderController:checkPermission() #53+---[0.069398ms] com.example.model.OrderQuery:<init>() #55+---[3255.860372ms] com.example.service.OrderService:queryOrder() #57+---[0.034332ms] com.example.model.OrderQuery:getOrderId() #78+---[0.011969ms] com.example.model.OrderQuery:getUserId() #79+---[3255.708441ms] com.example.dao.OrderDao:queryOrder() #81+---[0.223414ms] com.example.dao.OrderDao:createConnection() #102+---[3255.361354ms] com.example.dao.OrderDao:executeQuery() #103`---[3255.113486ms] com.example.dao.OrderDao:lambda$executeQuery$0() #125`---[3254.911768ms] com.example.external.PaymentGateway:queryPaymentStatus() #189
从跟踪结果可以看出,超时主要发生在PaymentGateway.queryPaymentStatus()方法,该方法调用了外部支付网关。
- 使用
watch命令观察该方法的入参和返回值:
$ watch com.example.external.PaymentGateway queryPaymentStatus '{params, returnObj, #cost}'
- 捕获到的结果显示,当调用特定支付网关时,响应时间异常长:
method=com.example.external.PaymentGateway.queryPaymentStatus location=AtExceptionExit
ts=2023-06-02 14:20:15; [cost=3245ms] result=@ArrayList[@Object[][@PaymentQuery[PaymentQuery{gatewayType=GATEWAY_B, orderId=ORD20230602001}],],null,3245,
]
解决方案
通过分析,发现问题出在调用特定支付网关(GATEWAY_B)时,由于网络延迟或该网关自身问题导致响应缓慢。解决方案如下:
- 为外部调用添加超时设置,避免长时间等待
- 实现熔断机制,当检测到网关响应缓慢时快速失败
- 添加异步处理逻辑,不阻塞主流程
- 优化重试策略,避免在网关不可用时频繁重试
实施优化后,接口超时问题得到有效解决。
5.3 案例三:使用Arthas解决OkHttpClient内存泄漏问题
问题背景
某人脸识别服务在高并发场景下频繁报java.lang.OutOfMemoryError: unable to create new native thread错误,导致服务不可用。
问题分析
- 使用
dashboard和thread命令查看系统状态,发现线程数量异常多:
$ dashboard
Memory used total max usage GC
heap 2.62G 3.00G 3.00G 87.58% gc.ps_scavenge.count 130
ps_eden_space 1.11G 1.29G 1.29G 86.34% gc.ps_scavenge.time(ms) 1299
ps_survivor_space 0.13G 0.13G 0.13G 97.62% gc.ps_marksweep.count 6
ps_old_gen 1.38G 1.57G 1.57G 87.91% gc.ps_marksweep.time(ms) 956Thread count created daemon peak runnableState blockedState2341 2430 36 2341 187 0
系统中存在2341个线程,远超正常水平。
- 使用
jvm命令查看JVM详情,确认内存使用正常,但线程数过多:
$ jvmTHREAD-RELATEDCOUNT : 2341 DAEMON-COUNT : 36 PEAK-COUNT : 2341 STARTED-COUNT : 2430 DEADLOCK-COUNT : 0
- 使用
thread -n 5查看CPU使用率最高的几个线程,发现大量线程在执行HTTP请求:
$ thread -n 5
ID NAME GROUP STATE %CPU TIME INTERRUPTED
234 OkHttp ConnectionPool main TIMED_WAITING 0.38 0:1.003 false
456 OkHttp ConnectionPool main TIMED_WAITING 0.24 0:0.856 false
789 http-nio-8080-exec-15 http-nio-8080-exec RUNNABLE 0.19 0:2.126 false
- 使用
sc -d com.example.service.FaceCompareService查看可疑类的详细信息:
$ sc -d com.example.service.FaceCompareService
class-info com.example.service.FaceCompareServicecode-source /app/classes/name com.example.service.FaceCompareServiceisInterface falseisAnnotation falseisEnum falseisAnonymousClass falseisArray falseisLocalClass falseisMemberClass falseisPrimitive falseisSynthetic falsesimple-name FaceCompareServicemodifier publicannotation interfaces super-class java.lang.Objectclass-loader org.springframework.boot.loader.LaunchedURLClassLoader@5c45d770classLoaderHash 5c45d770
- 使用
jad命令反编译可疑类,查看源码:
$ jad com.example.service.FaceCompareServiceClassLoader:
+-org.springframework.boot.loader.LaunchedURLClassLoader@5c45d770+-sun.misc.Launcher$AppClassLoader@18b4aac2+-sun.misc.Launcher$ExtClassLoader@4554617cLocation:
/app/classes//** Decompiled with CFR.*/
package com.example.service;import com.example.model.CompareFaceBo;
import org.springframework.stereotype.Service;
import okhttp3.OkHttpClient;
import okhttp3.Request;
import okhttp3.Response;
import java.util.concurrent.TimeUnit;@Service
public class FaceCompareService {private static JSONObject compareFaceImage(CompareFaceBo compareFaceBo) {// 创建数据List<Map> list = new ArrayList();Map mapTemp = new HashMap();// ... 数据准备代码 ...list.add(mapTemp1);// 创建请求MediaType mediaType = MediaType.parse("application/json");RequestBody body = RequestBody.create(mediaType, JSONUtil.toJsonStr(list));Request request = (new Request.Builder()).url("http://IP:port/face-api/v3/face/match?appid=" + compareFaceBo.getAppId()).method("POST", body).addHeader("Content-Type", "application/json").build();// 问题代码:每次调用都创建新的OkHttpClient实例OkHttpClient client = (new OkHttpClient()).newBuilder().connectTimeout(1, TimeUnit.SECONDS).readTimeout(2, TimeUnit.SECONDS).writeTimeout(1, TimeUnit.SECONDS).build();try {Response response = client.newCall(request).execute();String res = response.body().string();return JSONUtil.parseObj(res);} catch (IOException var12) {throw new CustomException("百度人脸比对接口调用异常!" + var12.getMessage());} finally {list = null;}}
}
通过代码分析,发现问题在于每次调用compareFaceImage方法都会创建一个新的OkHttpClient实例,而OkHttpClient内部会创建线程池,导致大量线程无法释放。
解决方案
- 将OkHttpClient改为单例模式,避免重复创建:
private static final OkHttpClient CLIENT = new OkHttpClient.Builder().connectTimeout(1, TimeUnit.SECONDS).readTimeout(2, TimeUnit.SECONDS).writeTimeout(1, TimeUnit.SECONDS).build();private static JSONObject compareFaceImage(CompareFaceBo compareFaceBo) {// ... 其他代码不变 ...// 使用单例客户端try {Response response = CLIENT.newCall(request).execute();String res = response.body().string();return JSONUtil.parseObj(res);} catch (IOException var12) {throw new CustomException("百度人脸比对接口调用异常!" + var12.getMessage());} finally {list = null;}
}
- 优化OkHttpClient配置,合理设置连接池大小和保活时间:
private static final OkHttpClient CLIENT = new OkHttpClient.Builder().connectTimeout(1, TimeUnit.SECONDS).readTimeout(2, TimeUnit.SECONDS).writeTimeout(1, TimeUnit.SECONDS).connectionPool(new ConnectionPool(10, 5, TimeUnit.MINUTES)) // 最大10个连接,空闲5分钟后释放.build();
实施优化后,服务稳定性显著提升,不再出现内存溢出错误。
6. 线上Debug功能介绍
除了性能分析和调优外,Arthas还提供了强大的线上调试功能,可以帮助我们在不重启应用的情况下进行代码调试和问题排查。
6.1 jad命令:反编译类
jad命令可以反编译指定的类,帮助我们查看运行时的代码逻辑。这在没有源码或怀疑代码与预期不符时非常有用。
# 反编译指定类
jad com.example.service.UserService# 反编译指定类的指定方法
jad com.example.service.UserService getUserById# 保存反编译结果到文件
jad --source-only com.example.service.UserService > UserService.java
通过jad命令,我们可以确认当前运行的代码是否与预期一致,特别是在怀疑代码部署有问题时。
6.2 sc命令:查找类
sc(Search Class)命令用于查找类的加载信息,帮助我们了解类的来源和加载情况。
# 模糊查找类
sc com.example.*Service# 查看类的详细信息
sc -d com.example.service.UserService# 查看类的字段信息
sc -f com.example.service.UserService
通过sc命令,我们可以确认类是否被正确加载,以及类的加载来源(哪个JAR包)。
6.3 sm命令:查找方法
sm(Search Method)命令用于查找类的方法信息。
# 查找类的所有方法
sm com.example.service.UserService# 查找类的指定方法
sm com.example.service.UserService getUserById# 查看方法的详细信息
sm -d com.example.service.UserService getUserById
通过sm命令,我们可以确认方法是否存在,以及方法的签名是否符合预期。
6.4 ognl命令:执行表达式
ognl命令是一个非常强大的命令,它可以执行OGNL表达式,访问和修改对象的属性,调用对象的方法等。
# 获取静态字段
ognl '@com.example.Constants@MAX_VALUE'# 调用静态方法
ognl '@java.lang.System@currentTimeMillis()'# 获取实例字段
ognl '#user=@com.example.service.UserServiceFactory@getInstance(), #user.username'# 修改实例字段
ognl '#user=@com.example.service.UserServiceFactory@getInstance(), #user.username="admin", #user.username'
通过ognl命令,我们可以在运行时查看和修改对象的状态,这在调试复杂问题时非常有用。
更详细的介绍可以看另一篇博文
6.5 redefine命令:重定义类
redefine命令可以在不重启JVM的情况下,重新加载类的字节码,实现热更新。
# 重定义类
redefine -c 789f1ec /tmp/UserService.class
使用redefine命令前,我们通常需要先使用jad命令导出类的源码,然后修改、编译后再重定义。这个过程可以帮助我们快速验证修复方案,而不需要重启应用。
6.6 tt命令:时间隧道
前面已经介绍过tt命令,它不仅可以用于性能分析,还是一个强大的调试工具。通过记录方法的调用,我们可以"穿越时间",查看历史调用的详细信息。
# 记录方法调用
tt -t com.example.service.UserService getUserById# 查看记录的调用
tt -l# 查看指定调用的详细信息
tt -i 1000# 重新执行指定的调用
tt -i 1000 -p
tt命令的"回放"功能特别有用,它可以帮助我们重现问题,而不需要等待问题再次发生。
6.7 watch命令:观察方法执行
前面已经介绍过watch命令,它是一个非常灵活的调试工具,可以观察方法的执行过程。
# 观察方法的入参和返回值
watch com.example.service.UserService getUserById '{params, returnObj}'# 观察方法抛出的异常
watch com.example.service.UserService getUserById '{params, throwExp}' -e# 观察方法的入参、返回值和执行耗时
watch com.example.service.UserService getUserById '{params, returnObj, #cost}'
通过watch命令,我们可以详细了解方法的执行情况,包括入参、返回值、异常和执行耗时等。
6.8 实际调试案例
下面是一个使用Arthas进行线上调试的实际案例:
问题背景
某电商系统的订单支付功能偶发性失败,但错误日志中只有简单的"支付失败"信息,无法确定具体原因。
调试过程
- 使用
sc命令查找支付相关的类:
$ sc *Payment*Service
com.example.service.PaymentService
- 使用
sm命令查看类的方法:
$ sm com.example.service.PaymentService
com.example.service.PaymentService <init>()V
com.example.service.PaymentService processPayment(Lcom/example/model/Order;)Z
com.example.service.PaymentService validatePayment(Lcom/example/model/Order;)V
com.example.service.PaymentService callExternalPaymentGateway(Lcom/example/model/Order;)Lcom/example/model/PaymentResult;
- 使用
watch命令观察支付处理方法的执行:
$ watch com.example.service.PaymentService processPayment '{params, returnObj, #cost}' -x 3
- 等待问题复现,捕获到一次失败的调用:
method=com.example.service.PaymentService.processPayment location=AtExceptionExit
ts=2023-06-02 15:30:45; [cost=256ms] result=@ArrayList[@Object[][@Order[Order{id=12345, userId=678, amount=99.99, status=PENDING}],],null,256,
]
- 使用
tt命令记录方法调用,以便进一步分析:
$ tt -t com.example.service.PaymentService processPayment
- 捕获到失败调用后,使用
tt命令查看详细信息:
$ tt -lINDEX TIMESTAMP COST(ms) IS-RET IS-EXP OBJECT CLASS METHOD1000 2023-06-02 15:35:12 301 false true 0x3bd1a634 PaymentService processPayment1001 2023-06-02 15:35:15 287 true false 0x3bd1a634 PaymentService processPayment1002 2023-06-02 15:35:18 312 false true 0x3bd1a634 PaymentService processPayment$ tt -i 1000 -x 3INDEX 1000GMT 2023-06-02 15:35:12COST 301msOBJECT 0x3bd1a634CLASS com.example.service.PaymentServiceMETHOD processPaymentIS-RETURN falseIS-EXCEPTION truePARAMETERS[@Object[][@Order[Order{id=12345, userId=678, amount=99.99, status=PENDING}],]]THROW-EXCEPTION java.lang.NullPointerException: nullat com.example.service.PaymentService.validatePayment(PaymentService.java:42)at com.example.service.PaymentService.processPayment(PaymentService.java:28)
- 使用
jad命令查看相关方法的源码:
$ jad com.example.service.PaymentService validatePaymentpublic void validatePayment(Order order) {// 问题代码:没有检查paymentConfig是否为nullif (order.getAmount().compareTo(this.paymentConfig.getMaxAmount()) > 0) {throw new IllegalArgumentException("Payment amount exceeds maximum allowed");}// ... 其他验证逻辑 ...
}
- 通过分析,发现问题出在
validatePayment方法中,paymentConfig字段可能为null,导致空指针异常。
解决方案
- 使用
ognl命令检查paymentConfig的值:
$ ognl -x 3 '@com.example.service.PaymentService@instance.paymentConfig'
null
- 临时修复:使用
ognl命令设置paymentConfig的值:
$ ognl '@com.example.service.PaymentService@instance.paymentConfig=new com.example.model.PaymentConfig(new java.math.BigDecimal("1000"))'
- 永久修复:修改代码,添加空值检查:
public void validatePayment(Order order) {if (paymentConfig == null) {// 加载默认配置或记录错误paymentConfig = loadDefaultConfig();}if (order.getAmount().compareTo(this.paymentConfig.getMaxAmount()) > 0) {throw new IllegalArgumentException("Payment amount exceeds maximum allowed");}// ... 其他验证逻辑 ...
}
通过这个案例,我们可以看到Arthas强大的线上调试能力,它可以帮助我们快速定位和解决问题,而不需要重启应用或添加大量日志。
7. Arthas最佳实践与总结
在前面的章节中,我们详细介绍了Arthas的各种功能和实战案例。在本章节中,我们将总结一些使用Arthas的最佳实践,帮助大家更高效地使用这个强大的工具。
7.1 性能分析最佳实践
-
循序渐进的分析方法
在进行性能分析时,建议采用由粗到细的分析方法:
- 首先使用
dashboard命令获取系统整体状况 - 然后使用
thread命令找出CPU使用率高的线程 - 接着使用
trace或profiler命令进行深入分析 - 最后使用
watch或tt命令观察具体方法的执行
- 首先使用
-
合理使用采样时间
使用
profiler命令时,采样时间不宜过长或过短:- 过短的采样时间可能无法捕获到足够的样本
- 过长的采样时间会产生大量数据,增加分析难度
- 一般建议采样时间在30秒到5分钟之间,根据应用特点调整
-
关注热点方法
在分析性能问题时,应重点关注:
- CPU使用率高的方法
- 调用次数多的方法
- 执行时间长的方法
- 锁竞争激烈的方法
-
结合业务场景
性能分析应结合具体的业务场景:
- 在业务高峰期进行采样,更容易发现问题
- 针对特定业务流程进行分析,如下单、支付等关键流程
- 考虑数据量对性能的影响,如大数据量查询、批量处理等
7.2 线上调试最佳实践
-
谨慎使用修改类的命令
redefine等修改类的命令功能强大,但使用时需谨慎:- 在测试环境充分验证修改后的代码
- 修改前备份原始类的字节码
- 修改后密切监控系统状态
- 避免修改关键类或频繁修改
-
合理使用条件表达式
多数Arthas命令支持条件表达式,合理使用可以提高效率:
- 使用
#cost > 100过滤执行时间长的调用 - 使用
params[0] == "specificValue"过滤特定参数的调用 - 使用
returnObj != null过滤非空返回值的调用
- 使用
-
注意对系统的影响
使用Arthas进行线上调试时,应注意对系统的影响:
- 避免在高峰期执行耗时长的命令
- 使用
-n参数限制命令执行的次数 - 使用
-m参数限制输出结果的大小 - 完成调试后及时退出Arthas
-
保存重要信息
调试过程中获取的重要信息应及时保存:
- 使用
> file将命令输出重定向到文件 - 使用
tt命令记录关键方法的调用 - 使用
heapdump命令保存堆转储文件 - 使用
jfr命令记录JVM运行时事件
- 使用
7.3 常见问题与解决方案
-
Arthas无法连接到目标进程
- 检查当前用户是否有足够权限
- 检查目标进程是否存在
- 检查防火墙和安全策略
- 查看Arthas日志(~/logs/arthas/)
-
命令执行缓慢
- 减少输出数据量,使用条件表达式过滤
- 限制执行次数和深度
- 检查目标系统负载
- 考虑使用异步命令
-
输出结果过多
- 使用
-n参数限制结果数量 - 使用
grep命令过滤结果 - 使用
> file将结果重定向到文件 - 使用条件表达式精确匹配
- 使用
-
类无法重定义
- 检查类是否被多个类加载器加载
- 检查新类的字节码版本是否兼容
- 检查新类的方法签名是否变化
- 考虑使用
reset命令重置增强
7.4 总结
Arthas是一款功能强大的Java应用诊断工具,它可以帮助我们在不修改应用代码的情况下,实时查看应用的运行状态,定位性能瓶颈,解决线上问题。
在本文中,我们详细介绍了Arthas的各种功能,包括:
- profiler功能:生成火焰图,分析性能热点
- 常用性能分析命令:dashboard, thread, trace, monitor等
- 线上调优实战案例:CPU使用率过高、接口超时、内存泄漏等
- 线上调试功能:jad, sc, sm, ognl, redefine等
通过这些功能和案例,我们可以看到Arthas在Java应用诊断和性能优化中的强大能力。它不仅可以帮助我们快速定位和解决问题,还可以提供深入的性能分析,帮助我们优化应用性能。
在实际使用中,我们应该根据具体场景选择合适的命令和功能,遵循最佳实践,以最小的影响获取最有价值的信息。同时,我们也应该不断学习和探索Arthas的新功能,提升自己的诊断和优化能力。
希望本文能够帮助大家更好地使用Arthas,解决实际工作中遇到的问题,提升应用的性能和稳定性。