⚡️ Linux grep 命令参数详解
⚡️ Linux grep 用法及参数详解
📘 1. grep 简介
grep 是 Linux/Unix 系统中用于文本搜索的命令,其全称为 Global Regular Expression Print,意为全局正则表达式打印器。
它根据给定的 模式(pattern) 对文件或标准输入进行匹配,并输出符合条件的行。
⚙️ 2. grep 用法
🧾 2.1 从标准输入中搜索
grep [参数选项] [匹配表达式]
说明:
- 不指定文件或路径时,grep 会等待标准输入,可直接通过键盘输入内容后按回车测试匹配行为。
- 使用 Ctrl + D(Unix)或 Ctrl + Z(Windows)表示输入结束。
📄 2.2 从文件中搜索
grep [参数选项] [匹配表达式] [文件]
说明:
- grep 会在指定文件中逐行搜索符合表达式的行。
- grep 支持一次输入多个文件名,自动输出匹配所在的文件名与行内容。
📁 2.3 从目录中递归搜索
grep [参数选项] [匹配表达式] [路径]
说明:
- grep 可以常配合 -r(递归)或 -R(递归并解析符号链接)选项对目录下的所有文件进行搜索。
🧩 2.4 从其他命令的输出中搜索(配合管道)
[其他命令] | grep [参数选项] [匹配表达式]
说明:
- grep 可以对命令输出结果进行实时筛选。
- 这种用法适合日志分析、进程查看、搜索历史记录等场景。
🛠️ 3. grep 参数
📌 3.1 grep 匹配输入参数
🔍 grep 匹配语法参数
-G(–basic-regexp):使用基本正则表达式(BRE,默认模式)。-E(–extended-regexp):使用扩展正则表达式(ERE)。-P(–perl-regexp):使用 Perl 风格的正则表达式(需 grep 支持 PCRE 扩展)。-F(–fixed-strings):将匹配模式视为普通字符串,而非正则表达式。
在这四个参数都不存在的情况下,
grep会使用基本正则(-G模式)。不同正则模式的主要区别在于是否需要对特殊字符(如+、*、()等)进行转义:
- 在 BRE 中这些字符通常需要转义;
- 在 ERE 和 PCRE 中则可直接使用。
更多正则语法规则详见:regexp 正则表达式详解 (以后有空更)
🎯 grep 匹配输入项参数
-e PATTERN:指定一个匹配模式,可多次使用以指定多个模式。例如:grep -e "hello" -e "world" file.txt-f FILE:从指定的文件中读取匹配模式(每行一个模式),适用于批量匹配。例如:grep -f patterns.txt application.log
📏 grep 匹配方式参数:
-i(–ignore-case):忽略大小写进行匹配。--no-ignore-case:不忽略大小写(不加-i的话默认就是这个模式,加了这个参数可以覆盖-i)。-v(–invert-match):反向匹配,输出不匹配的行。-w(–word-regexp):只匹配整个单词,而不是部分单词。效果:
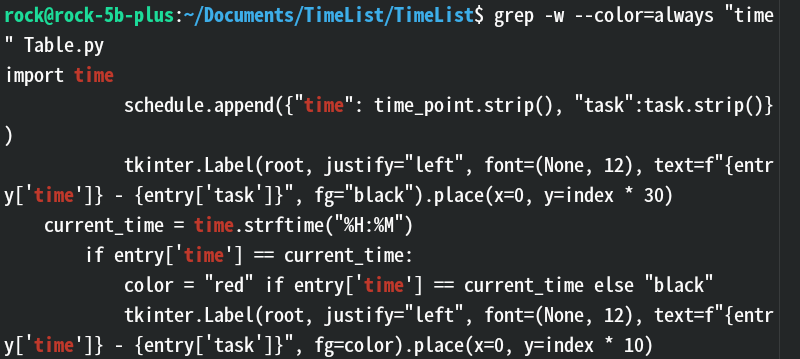
解释:这里只匹配到了一整个单词的
time没有匹配到current_time、check_time这种半个单词的time
-x(–line-regexp):整行匹配,只有整行完全匹配才算成功。效果:
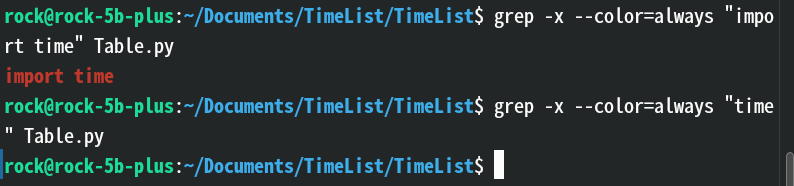
解释:这里只匹配到了一整行的
import time没有匹配到一整行的time
📁 grep 匹配文件与目录参数
-a:将二进制文件视为文本文件(用于分析其中可能包含的文本数据)。 效果:
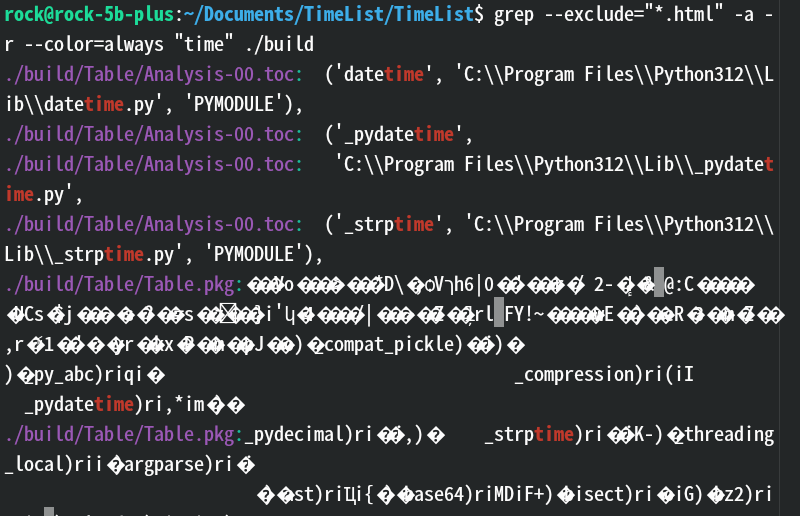
注意:使用该选项可能导致输出大量乱码(途中的方块问号就是),因为二进制文件中包含非文本字符,会使终端显示异常或不可读字符。
--binary-files=binary:遇到二进制文件时的处理方式,把二进制文件当成二进制文件处理(默认行为,不输出匹配内容)。--binary-files=text:遇到二进制文件时的处理方式,把二进制文件当成文本文件处理(和-a差不多,可能导致乱码)。--binary-files=without-match:遇到二进制文件时的处理方式,跳过该文件,不进行匹配(比--bindary-file=binary更省时间)。-d read:对目录的处理方式,读取目录内容(🐍皮玩法,目录有什么好读的)。-d skip:对目录的处理方式,跳过目录(默认行为)。效果:
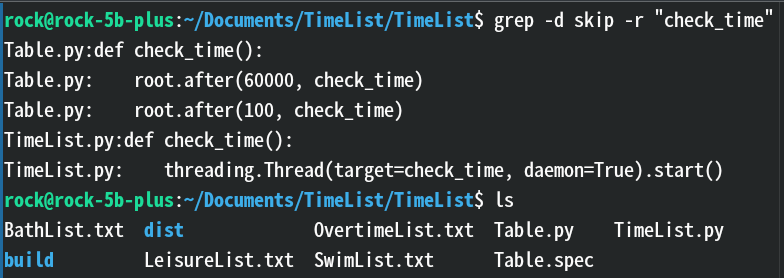
解释:这里为了跳过了
dist、build目录匹配当前目录下的其他所有文件
-D read:匹配设备文件、FIFO、socket 文件时的处理方式,尝试读取这些特殊文件(🐍皮玩法,设备有什么好读的)。-D skip:匹配设备文件、FIFO、socket 文件时的处理方式,跳过这些文件(默认行为)。效果:
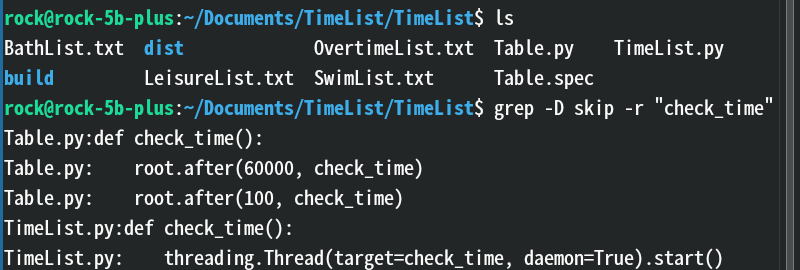
解释:这里跳过设备文件(一般只有在
/dev目录下才有设备文件,我这里虚空演示就当他有了)递归匹配当前目录下所有文件
--exclude=GLOB:匹配时跳过文件名符合 GLOB 模式的文件。效果:
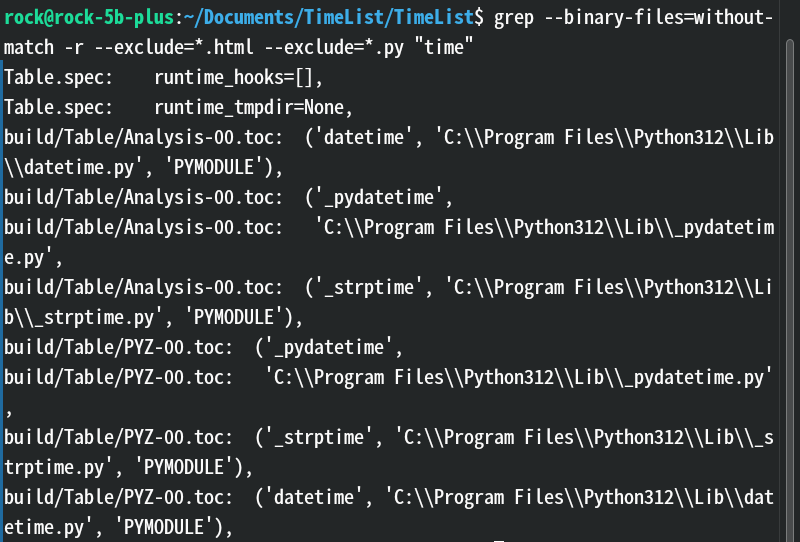
解释: 不匹配二进制文件,同时排除所有html和py文件
--exclude-from=FILE:从 FILE 文件中读取 GLOB 模式来排除文件。--exclude-dir=GLOB:排除指定模式的目录。--include=GLOB:只匹配文件名符合 GLOB 模式的文件。 效果:
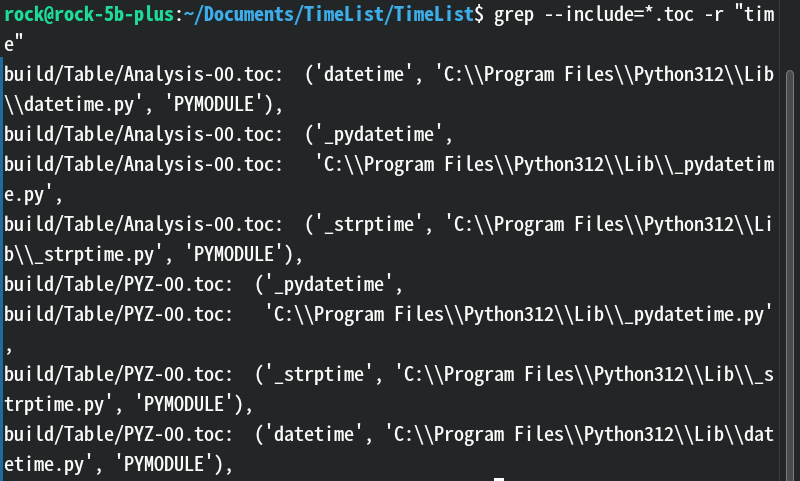
解释:这里只搜索toc文件
-r:递归处理目录。-R:递归处理目录,并解析符号链接。
⚜️ 3.2 grep 匹配输出参数
📤 grep 全局输出参数
-c:只显示每个文件中匹配的行数。 效果:

解释: 这里在
Table.py文件中搜索到了14条记录
--color=auto(默认):当输出目标为终端时高亮,重定向到文件或管道时不高亮。--color=never:不高亮显示匹配内容。--color=always:始终高亮显示匹配内容。效果:
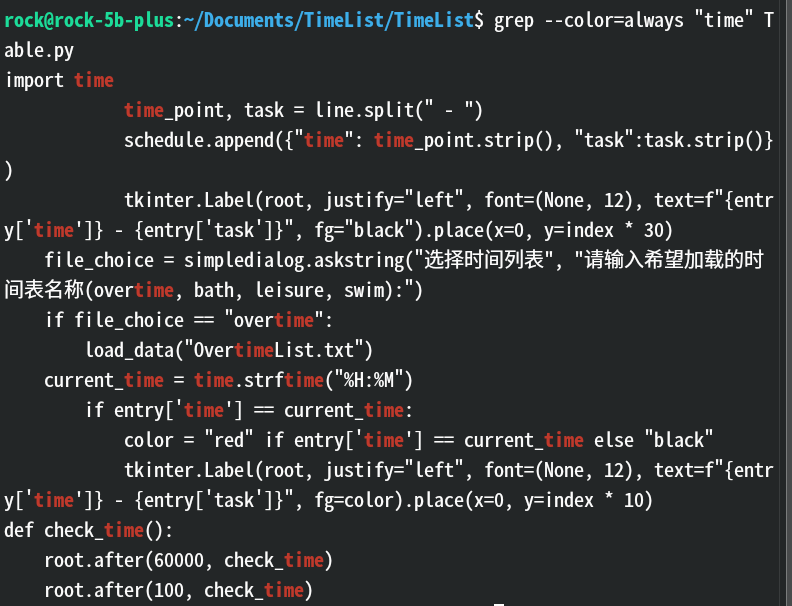
解释:看到他红了没?
-L:只列出没有匹配结果的文件名。效果:
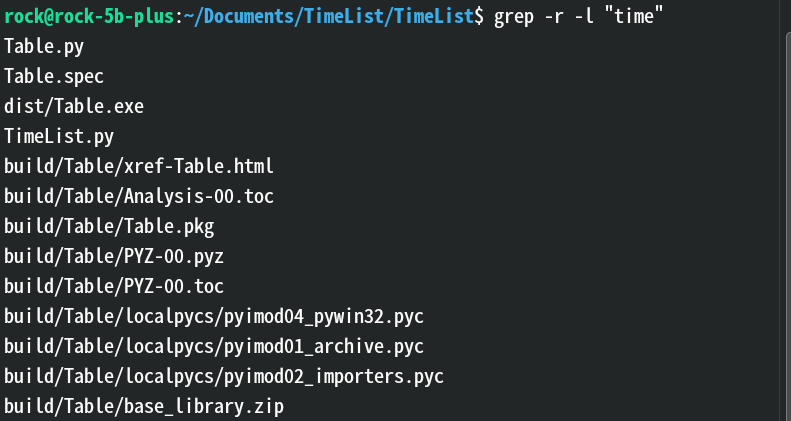
解释:和下图比较,这张图表示搜到的没有
time的文件
-l:只列出有匹配结果的文件名。效果:
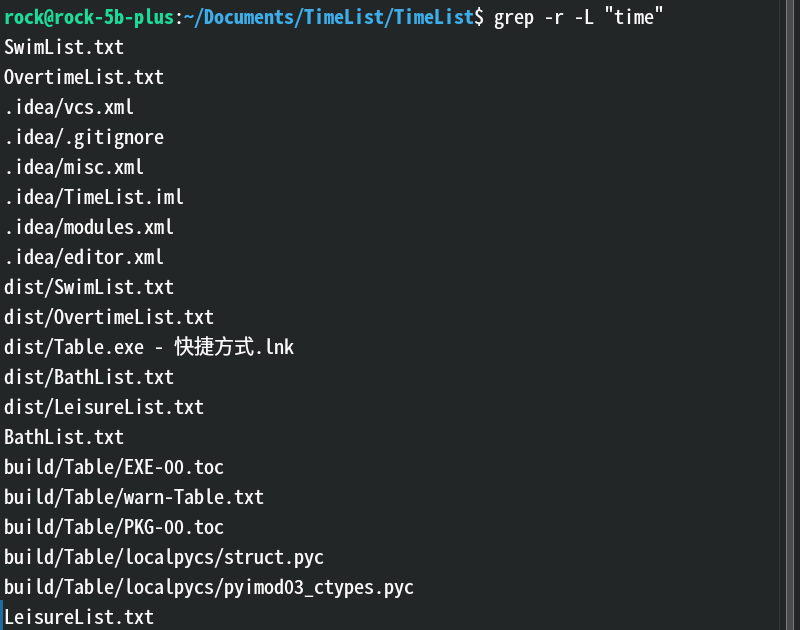
解释:和上图比较,这张图表示搜到的有
time的文件
-m NUM:最多匹配 NUM 条后停止搜索。效果:

注意:这张图表示我搜到的2条
time的记录,但是经过我测试-m NUM参数对目录递归搜索不管用
-o:只输出匹配的部分内容,而不是整行,常用于提取正则表达式匹配到的字段。效果:
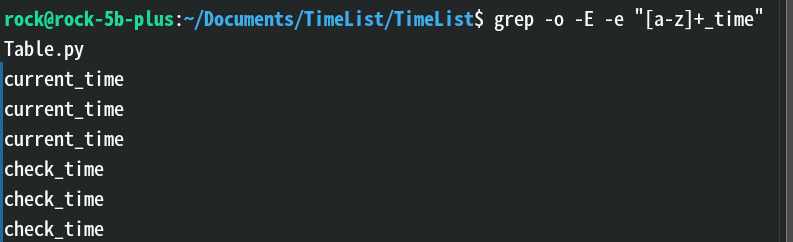
解释:正则表达式匹配到的类似xxx_time的字段,需要注意的是,由于我屏幕太窄,grep命令中的Table.py换行显示了,Table.py不是搜索到的结果(真想给他一拳)
-q:静默模式,不输出任何匹配内容,适用于脚本中只关心匹配结果的情况。-s:抑制错误信息输出,例如文件不存在时不会报错,适合批量操作。
📝 grep 行输出参数
-b:在输出中显示每行前的字节偏移量。效果:
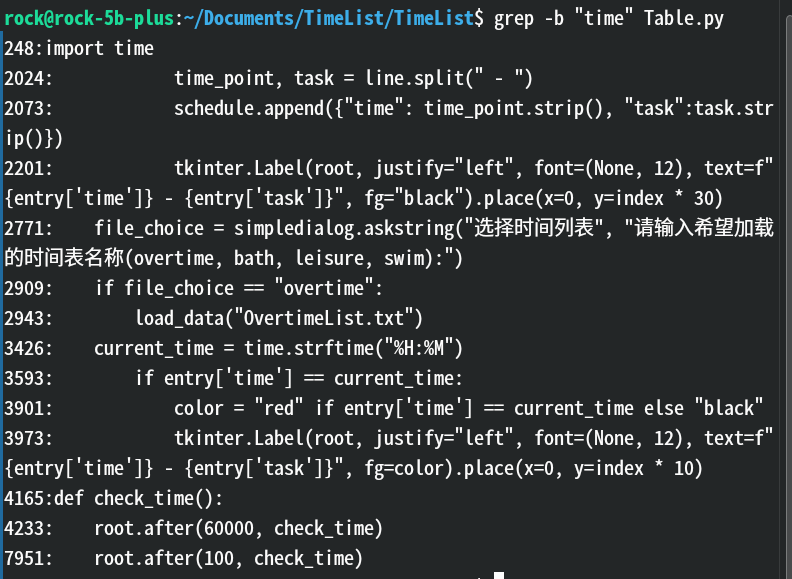
解释: 这里表示grep分别在第248、2024、2073……个字符的地方发现了
time
-h:不要在输出中显示文件名(默认,即使匹配多个文件)。-H:始终显示匹配行的文件名(即使只匹配一个文件)。效果
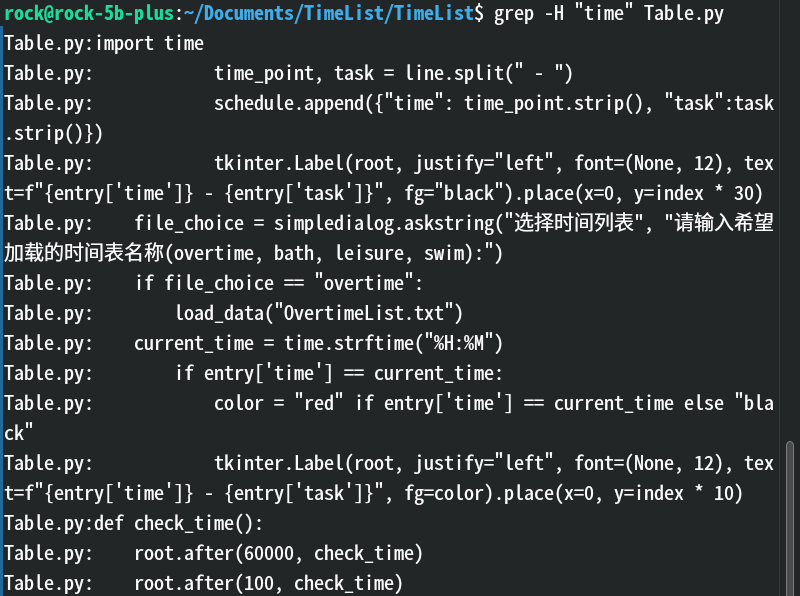
解释:输出结果每行前面加了个文件名,方便你递归搜索的时候找文件
-n:显示匹配行的行号。效果:
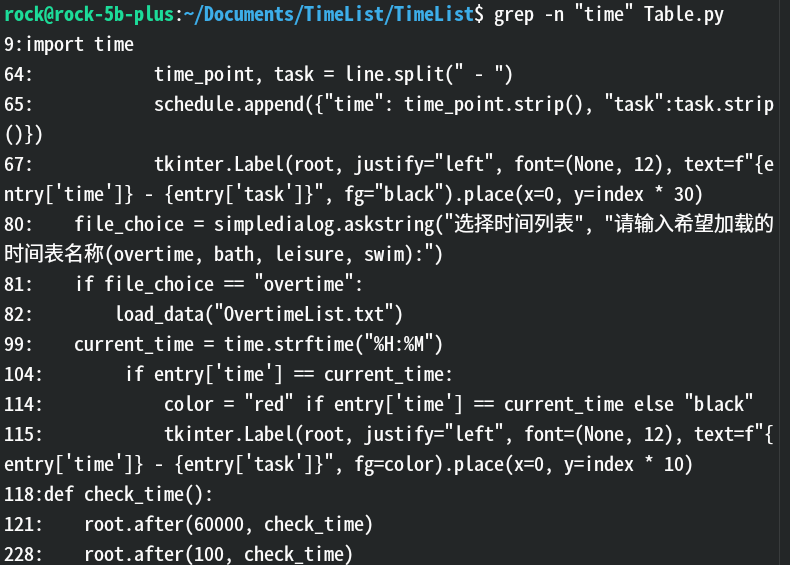
解释: 输出结果在每行前面加了行号,方便你用sed命令定位修改
-T:保持 Tab 字符宽度一致,利于对齐(仅在部分实现中有效)。效果:
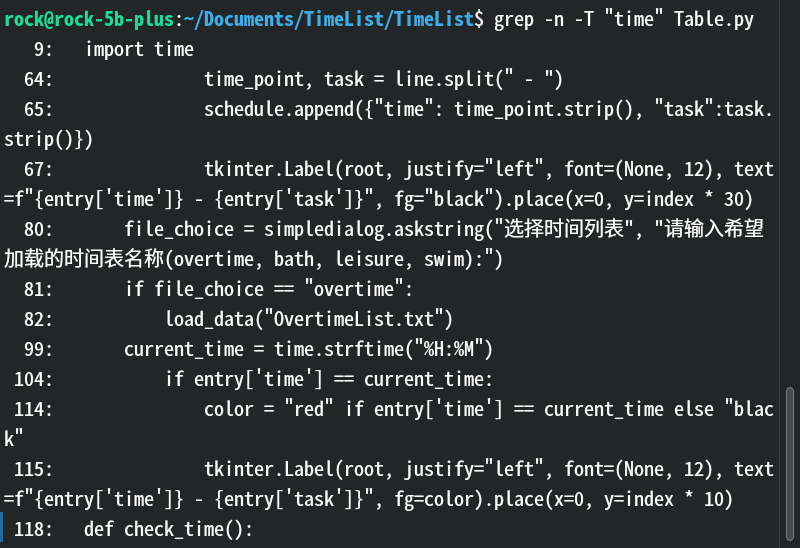
解释:和上张图对比,只对齐了冒号,可见实际并没什么🥚用
🧱 grep 上下文输出参数
-A NUM:显示匹配行 之后 的 NUM 行。效果:
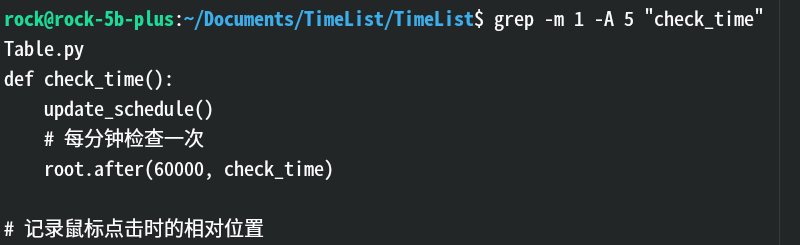
解释:显示了
check_time后面的5行
-B NUM:显示匹配行 之前 的 NUM 行。效果:

解释:显示了
check_time前面的5行
-C NUM:显示匹配行 前后 各 NUM 行。效果:
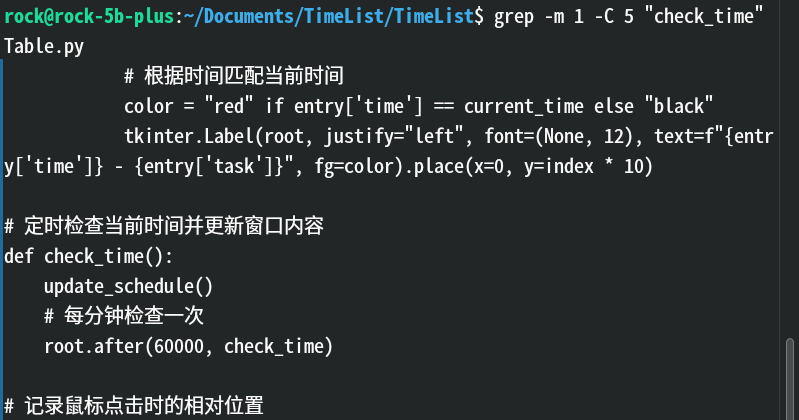
解释:
check_out前后都有了
--no-group-separator:匹配段之间不显示分隔符。(默认)--group-separator=SEP:自定义匹配项之间的分隔符。(要配合-A ,-B -C使用) 效果:
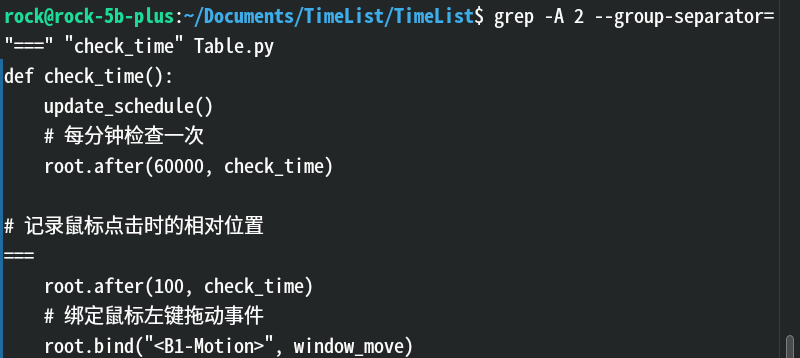
解释:这里可以自定义分隔符,我定义了
===他就显示===了。这条命令一定要配合-A 、-B、-C使用,否则分隔符显示不出来
🧪 3.3 grep 特殊用法参数(🐍皮玩法,你这辈子都不一定会用到)
--line-buffered:按行刷新输出(通常 grep 默认采用块缓冲)。适合实时处理输出,例如日志流分析。例如:tail -f /var/log/syslog | grep --line-buffered "fail"-U,--binary:以二进制模式读取文件,保留 Windows 文件中的 \r(回车符)。适用于对二进制数据或特定格式的分析。例如:grep -U $'\r\n' windows_data.txt-z(–null-data):将 ASCII NUL (\0) 字符视为换行符,适用于处理以 NUL 分隔的记录,例如一些 tar 输出或 find -print0 的结果。例如:grep -z "hello" nul_separated.txt-Z:在输出中使用 ASCII NUL (\0) 分隔匹配的文件名,适用于配合 xargs -0 等工具处理文件名中包含空格或换行的情况。例如:grep -rlZ "TODO" . | xargs -0 sed -i 's/TODO/DONE/g'--label=LABEL:当输入为标准输入(如管道)时,强制为其命名(显示为文件名),以便区分多来源的输出。例如:echo "error: disk full" | grep --label=stdin "error"--:标志参数结束,后续所有内容一律按文件名处理(即使看起来像参数)。用于防止文件名被误识别为选项。例如:grep "main" -- --filename-starts-with-dash.c
📖 参考资料
GNU grep 官方文档(在线)