sqoop的参数及初体验
基本命令
常见的命令
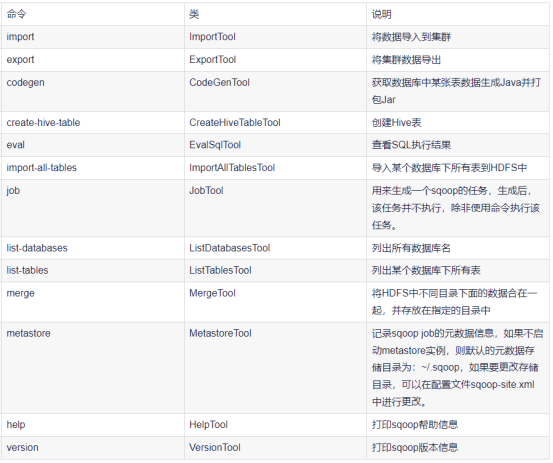
公用参数:import
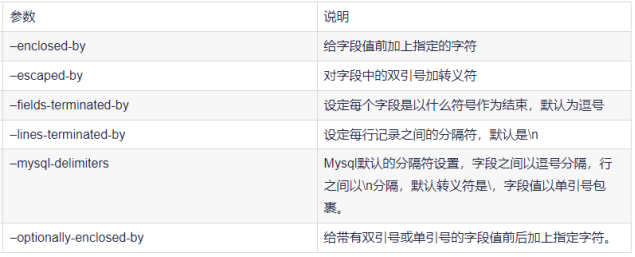
公用参数:数据库连接
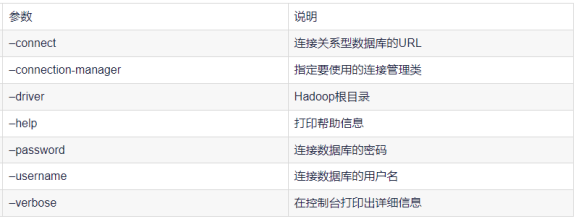
公用参数:export
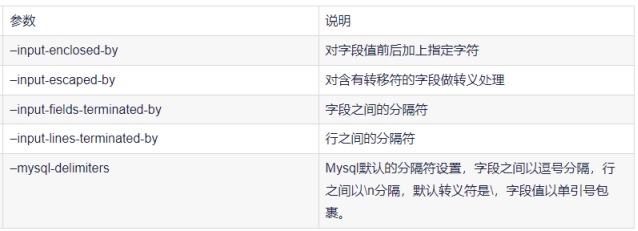
公用参数:hive
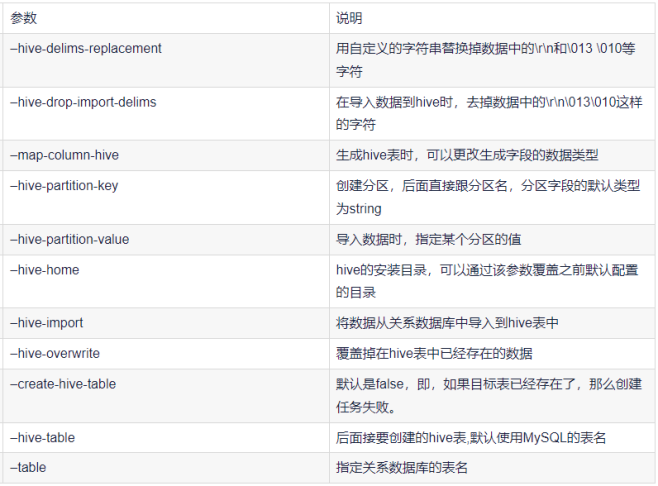
sqoop导入import
从RDBMS中以MySQL为例导出单表到HDFS,MySQL表中的每一行数据被视为HDFS中的一条记录,所有记录都存储为文本数据。下面的语法格式将用于将数据导入HDFS。
| sqoop import (generic-args) (import-args) |
全量导入mysql表数据到HDFS
下面的命令用于从MySQL数据库服务器中的emp表导入HDFS。
sqoop import \
--connect jdbc:mysql://ip地址:3306/数据库 \
--username 用户名 \
--password 密码 \
--delete-target-dir \
--target-dir HDFS路径 \
--table 表名\
--m 1 \
--fields-terminated-by '\t'--delete-target-dir:如果路径存在就自动删除
--target-dir:可以用来指定导出数据存放至HDFS的目录;
--m:是--num-mappers的缩写,表示启动N个mapper任务并行,默认4
--fields-terminated-by '\t':来指定分隔符
全量导入mysql表数据到HIVE
先将关系型数据的表结构复制到hive
sqoop create-hive-table \
--connect jdbc:IP地址:3306/库名\
--username 用户名\
--password 密码 \
--table 表名\
--hive-table hive表名备注:默认是false,即,如果目标表已经存在了,那么创建任务失败。
从关系数据库导入文件到hive中
sqoop import \
--connect jdbc:IP地址:3306/库名\
--username 用户名\
--password 密码 \
--table 表名\
--hive-table hive表名
--hive-import \
--m 1导入表数据子集(where过滤)
where可以指定从关系数据库导入数据时的查询条件。它执行在数据库服务器相应的SQL查询,并将结果存储在HDFS的目标目录。
sqoop import \
--connect jdbc:IP地址:3306/库名\
--username 用户名\
--password 密码 \
--table 表名\
--where "条件语句" \
--hive-table hive表名
--hive-import \
--m 1增量导入
在实际工作当中,数据的导入,很多时候都是只需要导入增量数据即可,并不需要将表中的数据每次都全部导入到hive或者hdfs当中去,这样会造成数据重复的问题。因此一般都是选用一些字段进行增量的导入,sqoop支持增量的导入数据,用于只导入比已经导入行新的数据行。其中,使用的参数为:
1、--check-column col 指定某一列
用来指定一些列,这些列在增量导入时用来检查这些数据是否作为增量数据进行导入,和关系型数据库中的自增字段及时间戳类似。
注意:这些被指定的列的类型不能使任意字符类型,如char、varchar等类型都是不可以的,同时-- check-column可以去指定多个列。
2、--incremental mode (append / lastmodified 两种模式)
增量导入数据分为两种方式:
- append:基于递增列的增量数据导入,必须为数值型
- lastmodified:基于时间列的数据增量导入,必须为时间戳类型
3、--last-value value (指定大于的值)
指定自从上次导入后列的最大值(大于该指定的值),也可以自己设定某一值
append增量导入 (将mysql数据库表的id>3的值筛查出来并存放进HDFS路径)
sqoop import \
--connect jdbc:IP地址:3306/库名\
--username 用户名\
--password 密码 \
--table 表名\
--m 1 \
--target-dir HDFS路径 \
--incremental append \
--check-column id \
--last-value 3 // 同步时不包含词条数据
lastmodified增量导入 (将mysql表last_modified 字段大于等于"2023-11-18 20:52:02"的数据)
sqoop import \
--connect jdbc:IP地址:3306/库名\
--username 用户名\
--password 密码 \
--table 表名\
--target-dir HDFS路径 \
--m 1 \
--check-column last_modified \
--incremental lastmodified \
--last-value "2023-11-18 20:52:02" // 同步时包含此条数据sqoop导出export
默认情况下,sqoop export将每行输入记录转换成一条INSERT语句,添加到目标数据库表中。如果数据库中的表具有约束条件(例如,其值必须唯一的主键列)并且已有数据存在,则必须注意避免插入违反这些约束条件的记录。如果INSERT语句失败,导出过程将失败。此模式主要用于将记录导出到可以接收这些结果的空表中。通常用于全表数据导出。
导出时可以是将Hive表中的全部记录或者HDFS数据(可以是全部字段也可以部分字段)导出到Mysql目标表。
sqoop export \
--connect jdbc:IP地址:3306/库名\
--username 用户名\
--password 密码 \
--table 表名\
--export-dir HDFS文件路径Sqoop的缺点
1、Sqoop属于Hadoop生态圈中一员,和Hadoop深度的绑定,Sqoop底层与MapReduce又是强耦合,不是解耦的,现在spark,flink技术的使用,使得sqoop的应用场景变少
2、目前已经从Apache下架,不再更新新版本
3、由于停更,只支持常见的RDBMS如MySQL、Oracle等和常见的Hadoop生态圈的HDFS、Hive等,对新产出的数据分析工具几乎没有相关联