ICML 2025 Spotlight | 机器人界的「Sora」!让机器人实时进行未来预测和动作执行!
标题:Video Prediction Policy: A Generalist Robot Policy with Predictive Visual Representations
作者:Yucheng Hu, Yanjiang Guo, Pengchao Wang, Xiaoyu Chen, Yen-Jen Wang, Jianke Zhang, Koushil Sreenath, Chaochao Lu, Jianyu Chen
机构:Tsinghua University、UC Berkeley、Shanghai Artificial Intelligence Laboratory、Shanghai Qi Zhi Institute、Robot Era
原文链接:https://arxiv.org/abs/2412.14803
代码链接:https://video-prediction-policy.github.io/
-
导读
视觉表示在开发通用机器人策略中起着至关重要的作用。以前的视觉编码器,通常用单图像重建或双图像对比学习进行预训练,倾向于捕捉静态信息,经常忽略对具体化任务至关重要的动态方面。最近,视频扩散模型(VDM)展示了预测未来帧的能力,并展示了对物理世界的深刻理解。我们假设VDM固有地产生包含当前静态信息和预测的未来动态的视觉表示,从而为机器人动作学习提供有价值的指导。基于这一假设,我们提出了视频预测策略(VPP ),它根据VDM内部预测的未来表示来学习隐式逆动力学模型。为了预测更精确的未来,我们根据机器人数据集和互联网人类操作数据微调预训练的视频基础模型。在实验中,VPP在Calvin ABC-D泛化基准上取得了18.6%的相对改进,并证明了复杂现实世界灵巧操作任务的成功率提高了31.6%。 -
效果展示
视频预测模型中的视觉表示明确表达了当前和未来帧,为实体代理提供了有价值的前瞻性信息。以前的视觉编码器没有明确的未来表示。
图片
我们对模拟和真实世界的机器人任务进行了广泛的实验,以评估视频预测策略的性能。模拟环境包括CALVIN基准和MetaWorld基准,而现实世界的任务包括熊猫手臂操作和XHand灵巧手操作。

定量结果对比:
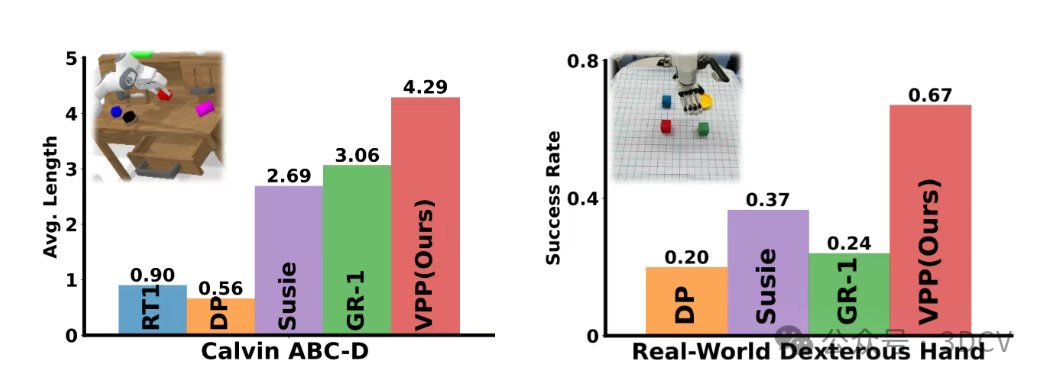
- 引言
构建能够解决多种任务的通用机器人策略是一个快速发展的研究领域。在这些通用策略中,一个关键组件是视觉编码器,它从像素观测中捕获视觉信息。许多研究聚焦于为具身智能体优化视觉表征,通常利用互联网视频数据集以及自监督技术,例如单图像重建、双图像对比学习以及图像 - 文本对比学习。尽管这些视觉预训练方法在具身任务中已展现出成功,但由于它们通常仅对单个或两个采样图像进行操作,可能无法充分利用顺序视频数据集中编码的动态信息。
最近,强大的视频扩散模型(VDMs)在视频生成任务中取得了令人瞩目的成果。视频扩散模型并非对单张图像或图像对进行预训练操作,而是直接对整个视频序列进行建模。文本引导的视频预测模型(TVPs)甚至能够基于当前观测和指令预测未来帧,展现出对物理动态的良好理解。
受TVP模型强大预测能力的启发,我们假设其本身包含有价值的物理动态知识,并能为具身智能体生成更有效的视觉表征。我们深入研究了TVP模型内部的视觉表征。这些表征通常以张量形式构建,维度为(T, H, W),明确表示1个当前步骤和(T - 1)个预测的未来步骤,其中H和W分别对应图像表征的高度和宽度。相比之下,以往的视觉编码器并未明确捕获未来表征。基于这一区别,我们将视频扩散模型中的这些潜在变量称为“预测性视觉表征”。
我们的关键见解是,下游策略可以通过在预测性表征中跟踪机器人的运动来隐式学习逆动力学模型。只要视频模型能够准确预测不同任务的未来场景,策略便可以通过隐式跟踪机械臂的位置来生成适当的动作。如此一来,我们便能够将视频预测模型的泛化能力迁移到机器人策略中。我们仅需少量演示,即可将机器人的动作空间与视觉空间对齐。
- 主要贡献
我们引入了视频预测策略(VPP),该策略采用两阶段学习过程:首先,我们使用互联网人类和机器人操作数据将通用视频扩散模型微调为文本引导的视频预测(TVP)模型。这一步骤旨在开发一个可控的视频生成模型,以提高操作领域的预测能力。在第二阶段,我们学习一个以TVP模型的预测性表征为条件的逆动力学模型。由于我们直接使用内部表征,并避免了先前工作中所需的多个去噪步骤,VPP能够以高频方式在闭环模式下运行。我们还对VDM内部的表征进行了可视化,并确认它们有效捕获了关于未来演化的关键信息。
在实验中,VPP在两个模拟环境和两个真实场景设置中始终优于其他基线算法,证明了我们方法的有效性。值得注意的是,与之前的最先进方法相比,VPP在Calvin ABC→D基准测试中取得了41.5%的提升。在真实实验中,VPP在高维灵巧手操作任务上的成功率比最强的基线方法提高了31.6%。
- 方法
我们描述了视频预测策略的两阶段学习过程。最初,我们在不同的操作数据集上训练文本引导视频预测(TVP)模型,以利用来自互联网数据的物理知识;随后,我们设计网络来聚合TVP模型中的预测视觉表示,并输出最终的机器人动作。
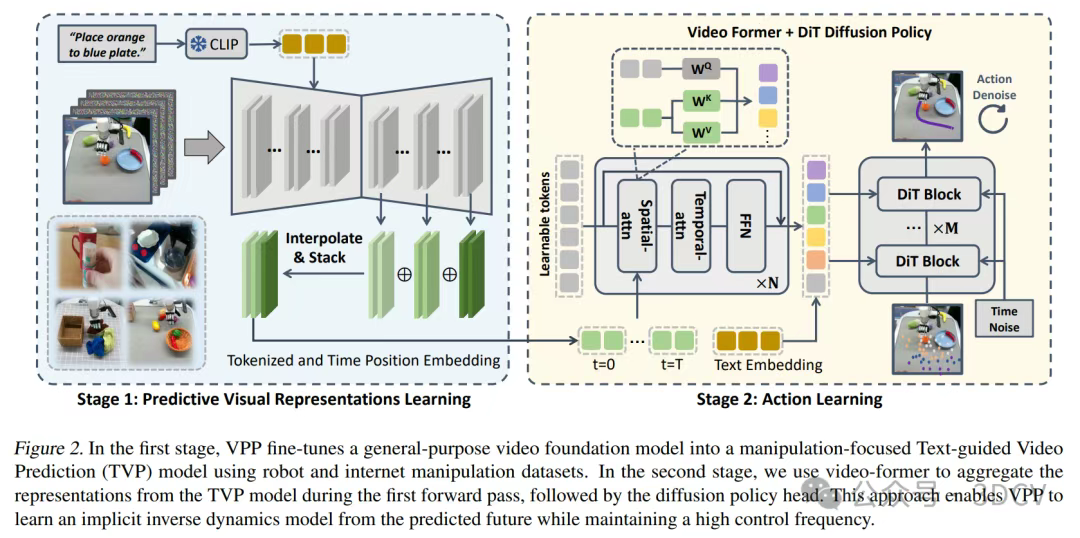
-
实验结果
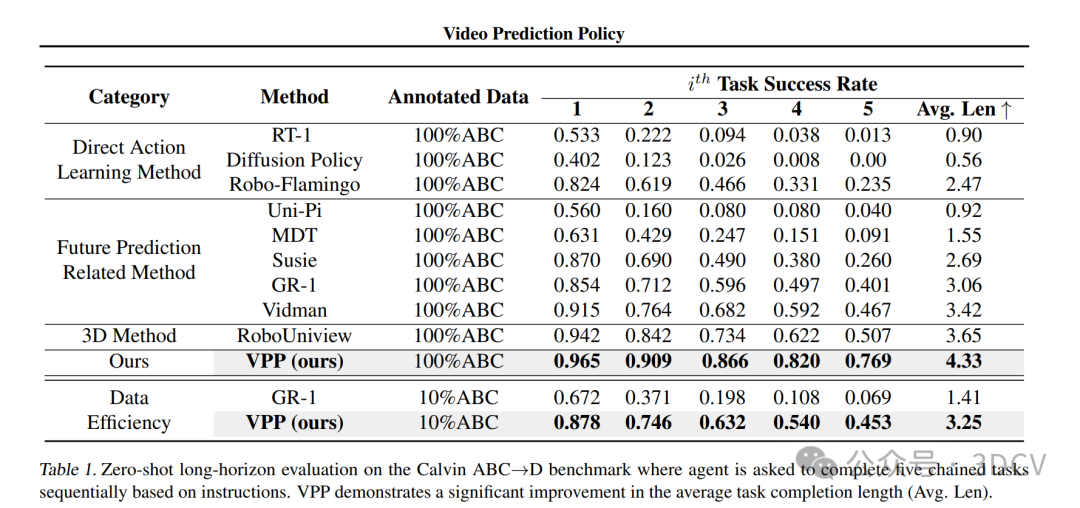
-
总结
我们引入了视频预测策略(VPP),这是一种学习通用机器人策略的新颖方法。VPP在VDM内的预测表示条件下学习隐式逆动力学模型,并在模拟和现实世界任务中产生一致的改进。随着视频生成模型变得越来越强大,我们的目标是充分释放视频模型在构建物理智能方面的潜力,并强调视频生成模型在具身任务中的潜力。