Python实现P-PSO优化算法优化Catboost分类模型项目实战
说明:这是一个机器学习实战项目(附带数据+代码+文档),如需数据+代码+文档可以直接到文章最后关注获取。

1.项目背景
随着机器学习技术的快速发展,分类问题在金融风控、医疗诊断、推荐系统等领域的重要性日益凸显。CatBoost作为一种基于梯度提升决策树(GBDT)的高效机器学习算法,以其对类别型特征的自动处理能力、鲁棒性以及高预测精度而备受关注。然而,CatBoost模型的性能高度依赖于超参数的合理配置,例如学习率、树的深度、正则化系数等。手动调参不仅效率低下,还难以保证找到全局最优解,因此需要一种智能化的优化方法来提升模型性能。
粒子群优化算法(PSO)是一种受群体行为启发的智能优化算法,具有简单易实现、全局搜索能力强等优点,广泛应用于各类优化问题。然而,标准PSO算法在处理高维、多约束的超参数优化时可能陷入局部最优解,导致优化效果不理想。为此,改进型P-PSO算法通过引入动态权重调整和扰动机制,能够有效增强全局探索与局部开发能力,从而更好地应对CatBoost模型中超参数优化的复杂性。将P-PSO算法与CatBoost结合,不仅可以显著提升分类模型的性能,还能大幅降低人工调参的时间成本。
本项目旨在通过Python实现P-PSO优化算法,对CatBoost分类模型的超参数进行自动化调优,并在实际数据集上验证其效果。通过对比实验,分析P-PSO优化算法相较于传统网格搜索和随机搜索方法的优势,为解决复杂分类问题提供一种高效、可靠的解决方案。同时,该项目也为进一步研究智能优化算法与机器学习模型的结合提供了实践参考和技术支持。
本项目通过Python实现P-PSO优化算法优化Catboost分类模型项目实战。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
| 编号 | 变量名称 | 描述 |
| 1 | x1 | |
| 2 | x2 | |
| 3 | x3 | |
| 4 | x4 | |
| 5 | x5 | |
| 6 | x6 | |
| 7 | x7 | |
| 8 | x8 | |
| 9 | x9 | |
| 10 | x10 | |
| 11 | y | 因变量 |
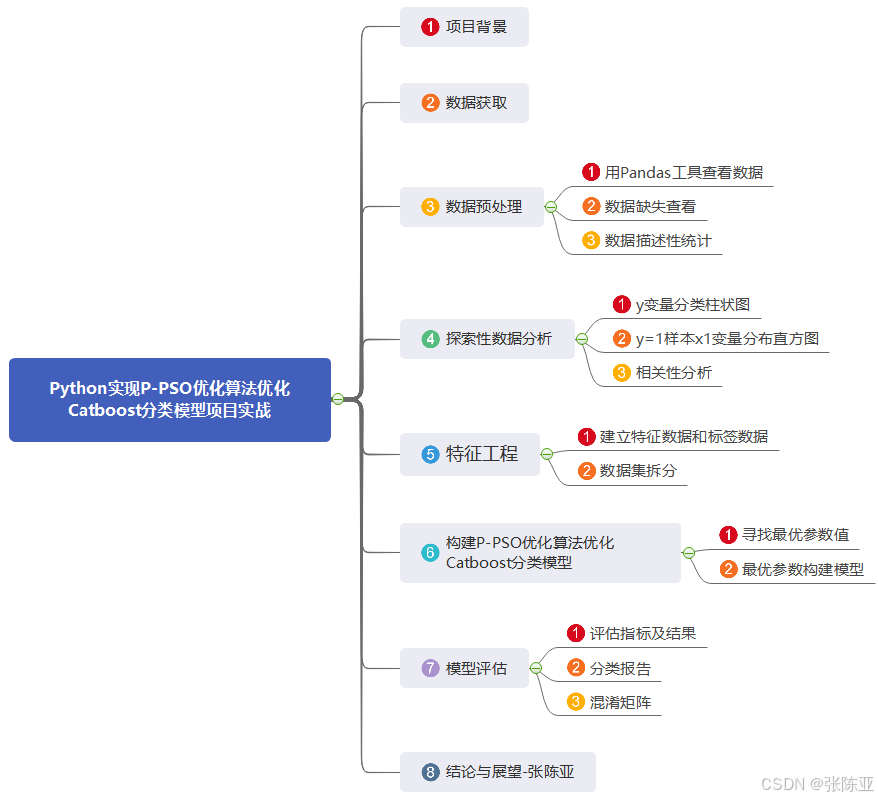
数据详情如下(部分展示):
3.数据预处理
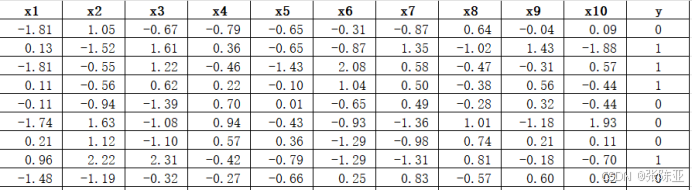
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:
关键代码:

3.2数据缺失查看
使用Pandas工具的info()方法查看数据信息:

从上图可以看到,总共有11个变量,数据中无缺失值,共2000条数据。
关键代码:

3.3数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
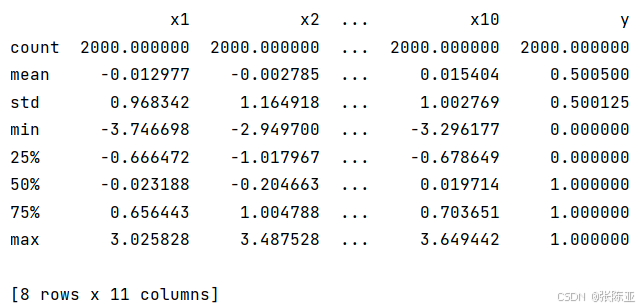
关键代码如下:

4.探索性数据分析
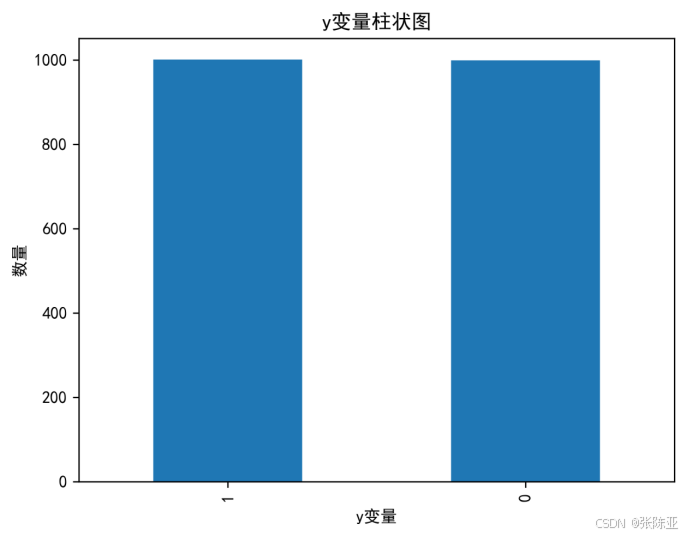
4.1 y变量柱状图
用Matplotlib工具的plot()方法绘制柱状图:
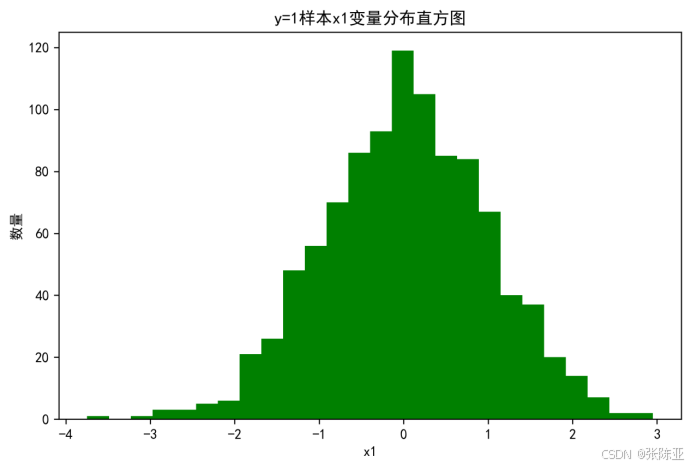
4.2 y=1样本x1变量分布直方图
用Matplotlib工具的hist()方法绘制直方图:
4.3 相关性分析
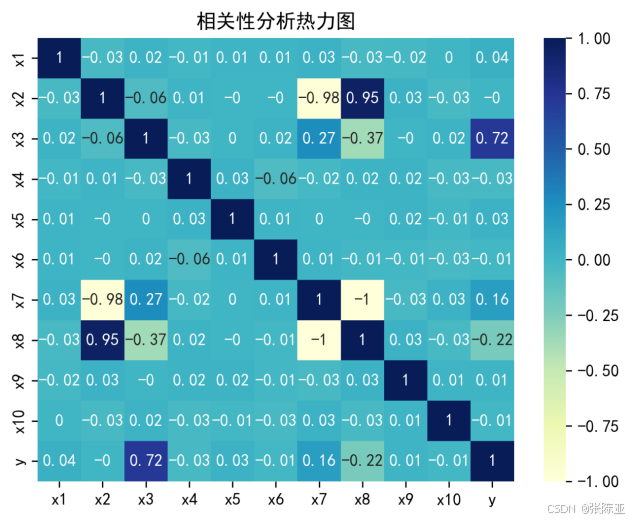
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:

5.2 数据集拆分
通过train_test_split()方法按照80%训练集、20%验证集进行划分,关键代码如下:

6.构建P-PSO优化算法优化Catboost分类模型
主要通过Python实现P-PSO优化算法优化Catboost分类模型算法,用于目标分类。
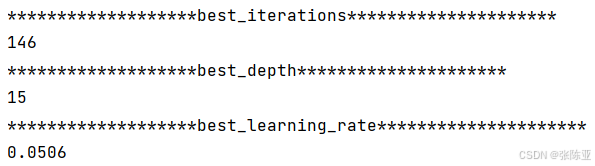
6.1 寻找最优参数值
最优参数值:
6.2 最优参数构建模型
这里通过最优参数构建分类模型。
| 模型名称 | 模型参数 |
| Catboost分类模型 | iterations=best_iterations |
| depth=best_depth | |
| learning_rate=best_learning_rate |
7.模型评估
7.1评估指标及结果
评估指标主要包括准确率、查准率、查全率、F1分值等等。
| 模型名称 | 指标名称 | 指标值 |
| 测试集 | ||
| Catboost分类模型 | 准确率 | 0.9000 |
| 查准率 | 0.8826 | |
| 查全率 | 0.9261 | |
| F1分值 | 0.9038 | |
从上表可以看出,F1分值为0.9038,说明P-PSO优化算法优化的Catboost模型效果良好。
关键代码如下:

7.2 分类报告
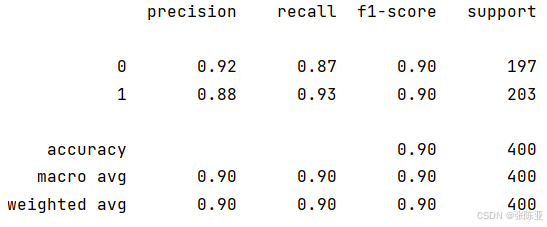
从上图可以看出,分类为0的F1分值为0.90;分类为1的F1分值为0.90。
7.3 混淆矩阵
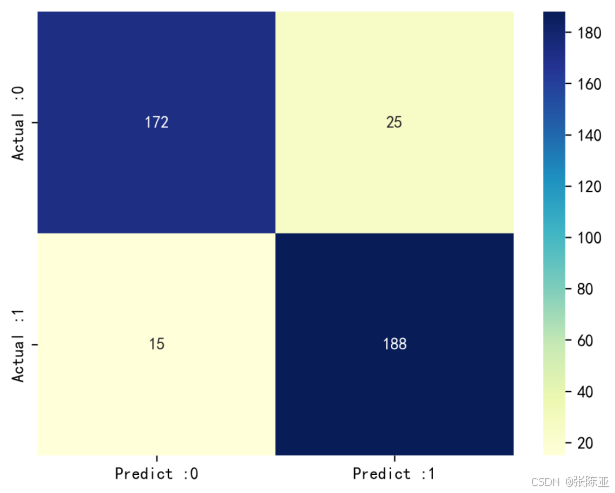
从上图可以看出,实际为0预测不为0的 有25个样本,实际为1预测不为1的 有15个样本,模型效果良好。
8.结论与展望
综上所述,本文采用了通过P-PSO优化算法优化Catboost分类算法的最优参数值来构建分类模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的建模工作。