day16 数组的常见操作和形状
目录
Numpy数组基础知识
数组的维度
数组的秩
数组的简单创建
zeros创建数组
ones创建数组
arange创建数组
数组的随机化创建
数组的遍历
数组的运算
数组的索引
一维数组索引
二维数组索引
三维数组索引
SHAP值的深入理解
知识点:
- numpy数组的创建:简单创建、随机创建、遍历、运算
- numpy数组的索引:一维、二维、三维
- SHAP值的深入理解
Numpy数组基础知识
数组的维度
数组的维度与轴是相同的,维度层数统称通过打印输出时的 [ ] 的嵌套层数来确定
一层 `[ ]`: 一维 (1D) 数组。
两层 `[ ]`: 二维 (2D) 数组。
三层 `[ ]`: 三维 (3D) 数组,依此类推。
数组的秩
数组的秩就是轴的个数,也就是维度的数量,通过ndim属性来获取
arr.ndim数组的简单创建
import numpy as np
a = np.array([2,4,6,8,10,12]) # 创建一个一维数组
b = np.array([[2,4,6],[8,10,12]]) # 创建一个二维数组
print(a)
print(b)[ 2 4 6 8 10 12]
[[ 2 4 6][ 8 10 12]]# 分清楚列表和数组的区别
print([7, 5, 3, 9]) # 输出: [7, 5, 3, 9](逗号分隔)
print(np.array([7, 5, 3, 9])) # 输出: [7 5 3 9](空格分隔)# numpy中可以用shape来查看数组的形状
a.shape
b.shape(6,)
(2,3)zeros创建数组
zeros方法可以创建指定维度和类型的数组,数组的每个元素都是0
arr1 = np.zero((2,3),dtype=int)arr1([[0, 0, 0],[0, 0, 0]])arr2 = np.zero((2,3),dtype=float)arr2([[0., 0., 0.],[0., 0., 0.]])ones创建数组
与zeros方法相似,但是数组的每个元素都是1
arange创建数组
arange方法可以创建顺序数组
arange = np.arange(1, 10) # 创建一个从1到9的数组array([ 1, 2, 3, 4, 5, 6, 7, 8, 9])数组的随机化创建
Numpy随机数生成方法对比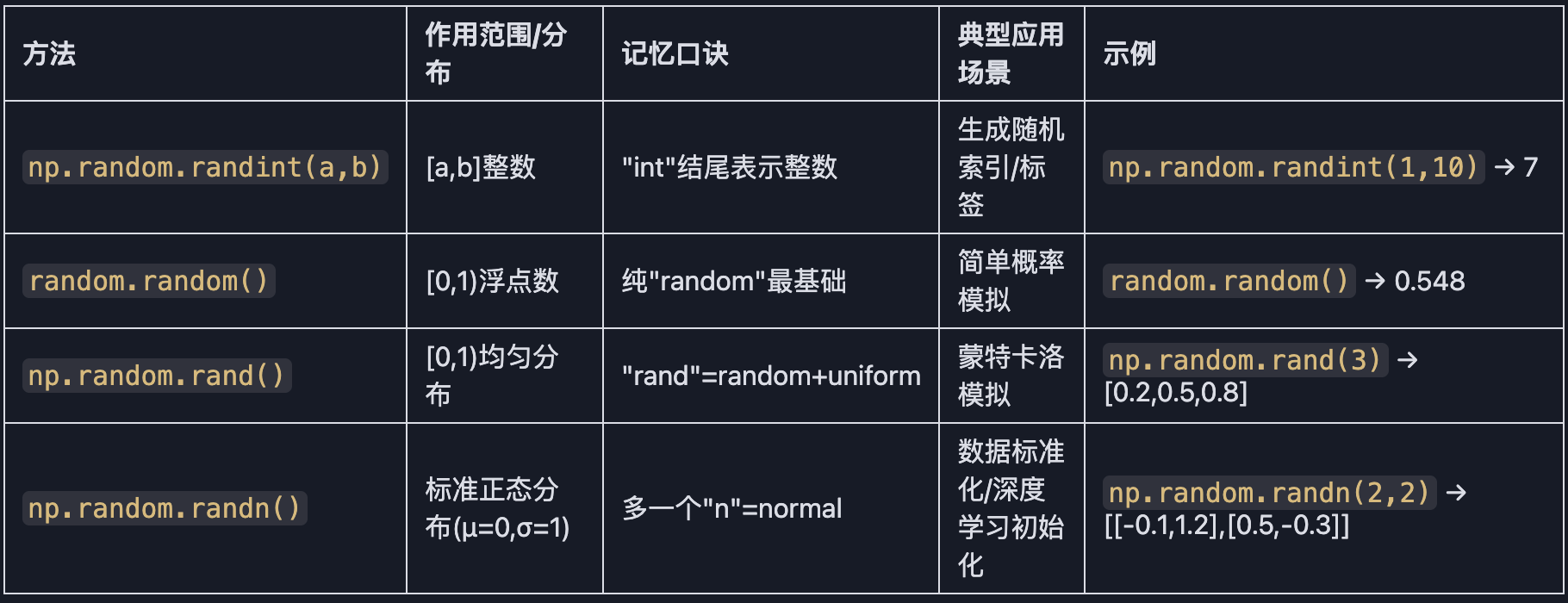
记忆技巧:
1.看结尾:
"int" → 整数
"n" → 正态(normal)
2.看前缀:
纯"random" → Python基础随机
"np.random" → Numpy增强版
3.功能差异:
random()和rand()都是均匀分布,但是rand会直接生成数组
randn()生成的数据会有正有负,其他方法都是非负数
# 创建一个2*2的随机数组c,区间为[0,1)
c = np.random.rand(2,2) array([[0.64229954, 0.78735483],[0.7358728 , 0.16490259]])np.random.seed(42) # 设置随机种子确保结果可重复# 生成10个数学成绩(正太分布,均值80,标准差15)
math_scores = np.random.normal(80,15,10).round() #保留一位小数# 找出最高分和最低分及其索引
max_score = np.max(math_scores)
max_index = np.argmax(math_scores)
min_score = np.min(math_scores)
min_score = np.argmin(math_scores)print(f"所有成绩: {math_scores}")
print(f"最高分: {max_score} (第{max_index}个学生)")
print(f"最低分: {min_score} (第{min_index}个学生)")所有成绩: [80. 73.6 81.5 90.2 72.7 72.7 90.8 82.7 70.3 80.4]
最高分: 90.8 (第6个学生)
最低分: 70.3 (第8个学生)数组的遍历
scores = np.array([1,3,5,7,9,11,13,15,17])
score += 1
sum = 0
for i in scores:sum += i
print(sum)90
数组的运算
1. 矩阵乘法:需要满足第一个矩阵的列数等于第二个矩阵的行数,和线代的矩阵乘法算法相同。
2. 矩阵点乘:需要满足两个矩阵的行数和列数相同,然后两个矩阵对应位置的元素相乘。
3. 矩阵转置:将矩阵的行和列互换。
4. 矩阵求逆:需要满足矩阵是方阵且行列式不为0,然后使用伴随矩阵除以行列式得到逆矩阵。
5. 矩阵求行列式:需要满足矩阵是方阵,然后使用代数余子式展开计算行列式。
a = np.array([[1, 2], [3, 4], [5, 6]])
b = np.array([[7, 8], [9, 10], [11, 12]])
print(a)
print(b)[[1 2][3 4][5 6]]
[[ 7 8][ 9 10][11 12]]print(a + b) # 计算两个数组的和[[ 8 10][12 14][16 18]]print(a - b) # 计算两个数组的差[[-6 -6][-6 -6][-6 -6]]print(a / b) # 计算两个数组的除法[[0.14285714 0.25 ][0.33333333 0.4 ][0.45454545 0.5 ]]print(a * b) # 矩阵点乘array([[ 7, 16],[27, 40],[55, 72]])a @ b.T # 矩阵乘法,3*2的矩阵和2*3的矩阵相乘,得到3*3的矩阵 T为转置array([[ 23, 29, 35],[ 53, 67, 81],[ 83, 105, 127]])数组的索引
一维数组索引
arr1d = np.arange(10) array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
# 1. 取出数组的第一个元素。
arr1d[0] # 0
# 2. 取出数组的最后一个元素。-1表示倒数第一个元素。
arr1d[-1] # 9
# 3. 取出数组中索引为 3, 5, 8 的元素。
# 使用整数数组进行索引,可以一次性取出多个元素。语法是 arr1d[[index1, index2, ...]]。
arr1d[[3, 5, 8]] # array([3,5,8])
# 4. 切片取出索引
# 取出索引为2到5的元素(不包括索引6的元素,取左不取右)
arr1d[2:6] # array([2,3,4,5])
# 5. 取出数组中从头到索引 5 (不包含 5) 的元素。
# 使用切片 slice [:stop]
arr1d[:5] # array([0,1,2,3,4])
# 6. 取出数组中从索引 4 到结尾的元素。
# 使用切片 slice [start:]
arr1d[4:] # array([4,5,6,7,8,9])
# 7. 取出全部元素
arr1d[:] # array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
# 8. 取出数组中所有偶数索引对应的元素 (即索引 0, 2, 4, 6, 8)。
# 使用带步长的切片 slice [start:stop:step]
arr1d[::2] # array([0,2,4,6,8])二维数组索引
# 数组:
arr2d = np.array([[1, 2, 3, 4],[5, 6, 7, 8],[9, 10, 11, 12],[13, 14, 15, 16]])索引顺序:在二维数组arr2d里,第一个索引值代表行,第二个索引值代表列。比如arr2d[i,j],i是行索引,j是列索引。
# 取出第 1 行 (索引为 1) 的所有元素。
#
# 使用索引 arr[row_index, :] 或 arr[row_index]
arr2d[1, :]
# 也可以省略后面的 :
arr2d[1]array([5, 6, 7, 8])# 取出第 2 列 (索引为 2) 的所有元素。
# 使用索引 arr[:, column_index]
arr2d[:, 2]array([ 3, 7, 11, 15])# 取出位于第 2 行 (索引 2)、第 3 列 (索引 3) 的元素。
# 使用 arr[row_index, column_index]
arr2d[2, 3] # 12# 取出由第 0 行和第 2 行组成的新数组。
# 使用整数数组作为行索引 arr[[row1, row2, ...], :]
arr2d[[0, 2], :]array([[ 1, 2, 3, 4],[ 9, 10, 11, 12]])# 取出由第 1 列和第 3 列组成的新数组。
# 使用整数数组作为列索引 arr[:, [col1, col2, ...]]
arr2d[:, [1, 3]]array([[ 2, 4],[ 6, 8],[10, 12],[14, 16]])# 取出一个 2x2 的子矩阵,包含元素 6, 7, 10, 11。
# 使用切片 slice arr[row_start:row_stop, col_start:col_stop]
arr2d[1:3, 1:3]array([[ 6, 7],[10, 11]])三维数组索引
# reshape(3, 4, 5)表示把一维数组转换为三维数组,有3个二维子数组,每个二维子数组有4行5列
arr3d = np.arange(3 * 4 * 5).reshape((3, 4, 5))array([[[ 0, 1, 2, 3, 4],[ 5, 6, 7, 8, 9],[10, 11, 12, 13, 14],[15, 16, 17, 18, 19]],[[20, 21, 22, 23, 24],[25, 26, 27, 28, 29],[30, 31, 32, 33, 34],[35, 36, 37, 38, 39]],[[40, 41, 42, 43, 44],[45, 46, 47, 48, 49],[50, 51, 52, 53, 54],[55, 56, 57, 58, 59]]])# 选择特定的层
# 使用整数数组 [0, 2] 作为第一个维度 (层) 的索引
arr3d[1, :, :] # 遍历第1个二维子数组array([[20, 21, 22, 23, 24],[25, 26, 27, 28, 29],[30, 31, 32, 33, 34],[35, 36, 37, 38, 39]])arr3d[1, 0:2, :] # 遍历第1个二维子数组的第0-1行array([[20, 21, 22, 23, 24],[25, 26, 27, 28, 29]])arr3d[1, 0:2, 2:4] # 遍历第1个二维子数组的第0-1行的第2-3列array([[22, 23],[27, 28]])SHAP值的深入理解
import shap
import matplotlib.pyplot as plt# 初始化 SHAP 解释器
explainer = shap.TreeExplainer(rf_model)# 计算 SHAP 值(基于测试集),这个shap_values是一个numpy数组,表示每个特征对每个样本的贡献值
shap_values = explainer.shap_values(X_test) array([[[ 9.07465700e-03, -9.07465700e-03],[ 7.21456498e-03, -7.21456498e-03],[ 4.55189444e-02, -4.55189444e-02],...,[ 7.12857198e-05, -7.12857198e-05],[ 4.67733508e-05, -4.67733508e-05],[ 1.61298135e-04, -1.61298135e-04]],[[-1.02606871e-02, 1.02606871e-02],[ 1.85572634e-02, -1.85572634e-02],[-1.64992848e-02, 1.64992848e-02],...,[ 2.00070852e-04, -2.00070852e-04],[ 5.11798841e-05, -5.11798841e-05],[ 1.02827796e-04, -1.02827796e-04]],[[ 3.21529115e-03, -3.21529115e-03],[ 1.28184070e-02, -1.28184070e-02],[ 1.02124914e-01, -1.02124914e-01],...,[ 1.73012306e-04, -1.73012306e-04],[ 4.74133256e-05, -4.74133256e-05],[ 1.26753231e-04, -1.26753231e-04]],...,[[ 1.15222741e-03, -1.15222741e-03],[-1.71843266e-02, 1.71843266e-02],[-3.04994337e-02, 3.04994337e-02],...,[ 1.44859329e-04, -1.44859329e-04],[ 1.80111014e-05, -1.80111014e-05],[ 1.30107512e-04, -1.30107512e-04]],[[ 1.29249120e-03, -1.29249120e-03],[ 5.66948438e-03, -5.66948438e-03],[ 2.49050264e-02, -2.49050264e-02],...,[ 2.50590715e-06, -2.50590715e-06],[ 4.68839113e-05, -4.68839113e-05],[ 1.15002997e-05, -1.15002997e-05]],[[-1.12640555e-03, 1.12640555e-03],[ 1.42648293e-02, -1.42648293e-02],[ 4.74790019e-02, -4.74790019e-02],...,[ 6.19451775e-05, -6.19451775e-05],[ 3.30996384e-05, -3.30996384e-05],[ 4.45219920e-05, -4.45219920e-05]]])shap_values[0,:,:]array([[ 9.07465700e-03, -9.07465700e-03],[ 7.21456498e-03, -7.21456498e-03],[ 4.55189444e-02, -4.55189444e-02],[ 3.47666501e-04, -3.47666501e-04],[ 2.57821493e-04, -2.57821493e-04],[ 2.00758099e-03, -2.00758099e-03],[-7.54175659e-03, 7.54175659e-03],[-1.35324163e-03, 1.35324163e-03],[-7.08191659e-04, 7.08191659e-04],[-6.06829865e-03, 6.06829865e-03],[-1.90501403e-03, 1.90501403e-03],[ 1.44384291e-02, -1.44384291e-02],[-4.91452434e-02, 4.91452434e-02],[ 6.28172371e-03, -6.28172371e-03],[-1.64613559e-02, 1.64613559e-02],[-6.04576031e-01, 6.04576031e-01],[ 4.58074016e-04, -4.58074016e-04],[-1.95125086e-05, 1.95125086e-05],[-1.47478232e-05, 1.47478232e-05],[ 6.27274034e-04, -6.27274034e-04],[-1.26003035e-05, 1.26003035e-05],[-3.58303017e-04, 3.58303017e-04],[ 7.89740644e-05, -7.89740644e-05],[ 2.08492876e-04, -2.08492876e-04],[ 5.52330472e-06, -5.52330472e-06],
...[ 7.15614011e-06, -7.15614011e-06],[ 1.07037925e-04, -1.07037925e-04],[ 7.12857198e-05, -7.12857198e-05],[ 4.67733508e-05, -4.67733508e-05],[ 1.61298135e-04, -1.61298135e-04]])
shap_values[0,:,:].shape(31, 2)上面对应的是(特征数,类别数目)-----每个特征对应2个目标类别的shap值贡献
# 三个维度
# 第一个维度是样本数
# 第二个维度是特征数
# 第三个维度是类别数
shap_values.shape(1500, 31, 2)# 比如我想取出所有样本对第一个类别的贡献值
shap_values[:,:,0]array([[ 9.07465700e-03, 7.21456498e-03, 4.55189444e-02, ...,7.12857198e-05, 4.67733508e-05, 1.61298135e-04],[-1.02606871e-02, 1.85572634e-02, -1.64992848e-02, ...,2.00070852e-04, 5.11798841e-05, 1.02827796e-04],[ 3.21529115e-03, 1.28184070e-02, 1.02124914e-01, ...,1.73012306e-04, 4.74133256e-05, 1.26753231e-04],...,[ 1.15222741e-03, -1.71843266e-02, -3.04994337e-02, ...,1.44859329e-04, 1.80111014e-05, 1.30107512e-04],[ 1.29249120e-03, 5.66948438e-03, 2.49050264e-02, ...,2.50590715e-06, 4.68839113e-05, 1.15002997e-05],[-1.12640555e-03, 1.42648293e-02, 4.74790019e-02, ...,6.19451775e-05, 3.30996384e-05, 4.45219920e-05]])此时可以理解为什么shap.summary_plot中第一个参数是所有样本对预测类别的shap值了。
传入的 SHAP 值 (shap_values[:, :, 0]) 和特征数据 (X_test) 在维度上需要高度一致和对应。
- shap_values[:, :, 0] 的每一行代表的是 一个特定样本每个特征对于预测类别的贡献值(SHAP 值)。缺乏特征本身的值
- X_test 的每一行代表的也是同一个特定样本的特征值。
这二者组合后,就可以组合(特征数,特征值,shap值)构成shap图的基本元素
@浙大疏锦行