大模型-attention汇总解析之-MHA
一、MHA(Multi-Head Attention)
1.1 MHA 原理
MHA(Multi-Head Attention)称为多头注意力,开山之作所提出的一种 Attention 计算形式,它是当前主流 LLM 的基础工作。在数学原理上,多头注意力 MHA 等价于多个独立的单头注意力的拼接, MHA 可以形式地记为:
 公式展开下如下:
公式展开下如下:
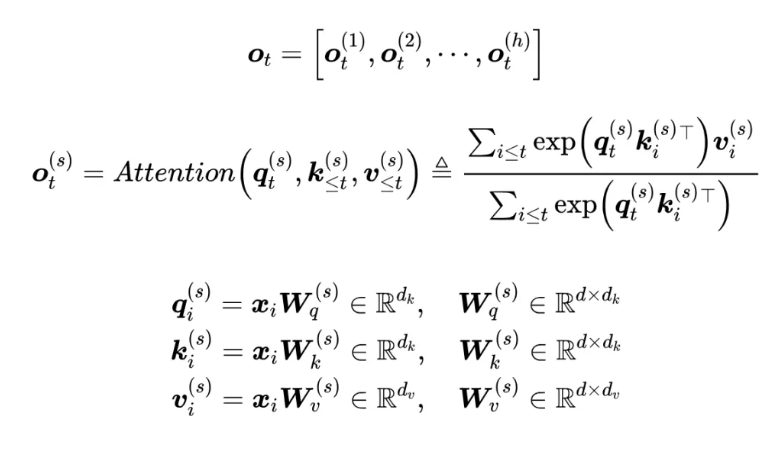
Attention 的计算公式如下:
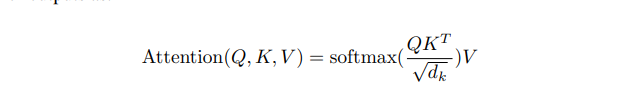
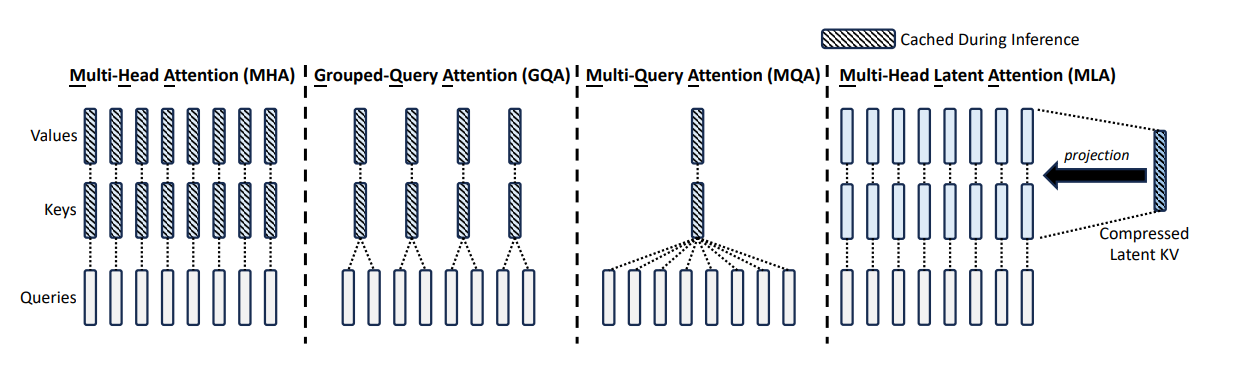
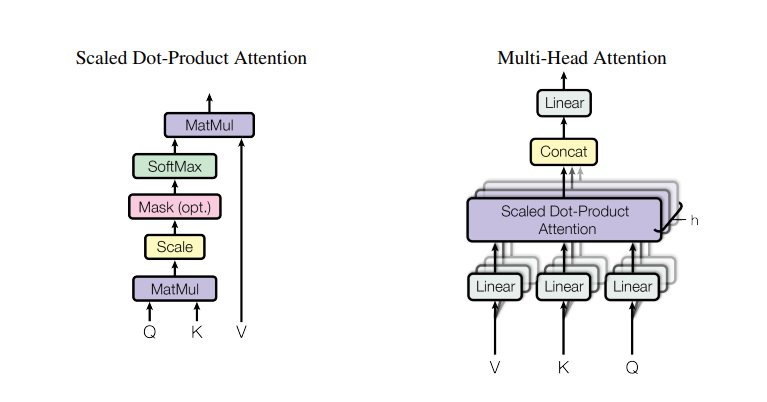
Attention 计算模型结构和MHA的模型结构示意图:
在实践中,为了减少计算复杂度和内存占用,通常会设置 ,其中 d 是模型的维度,h 是缩放因子(也称为头数,即多头注意力中的头的数量)。对于 LLaMA2-7b 模型:模型维度 d = 4096,多头数 h = 32, 因此,d_k = d_v = 128(即 4096 / 32.
这里我们只考虑了主流的自回归 LLM 所用的 Causal Attention,因此在 token by token 递归生成时,新预测出来的第 i+1个 token,并不会影响到已经算好的 前面的i个K, V的值,因此这部分K, V结果我们可以缓存下来供后续生成调用,避免不必要的重复计算,这就是所谓的 KV Cache。下面是kv cache的示意图。
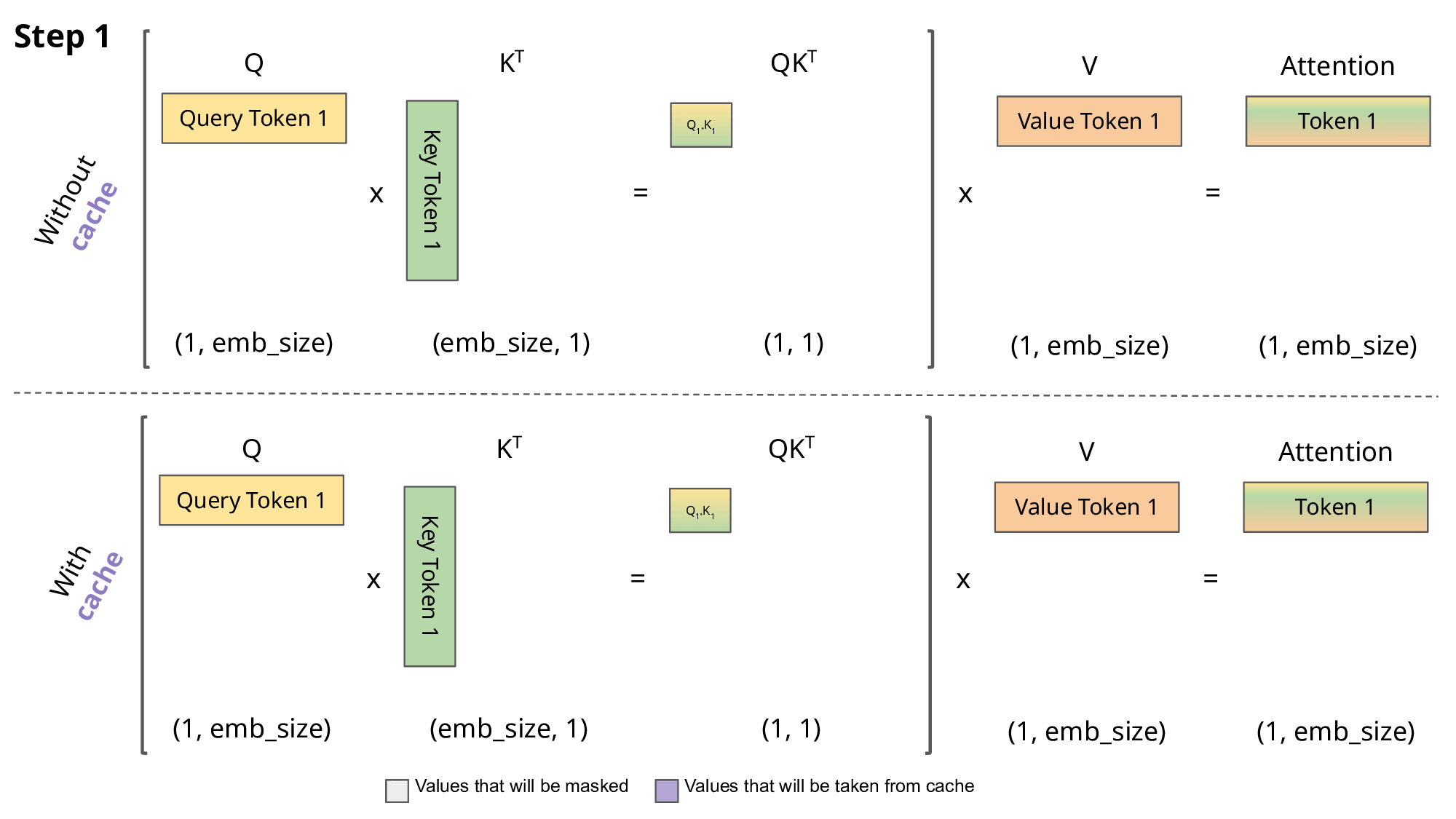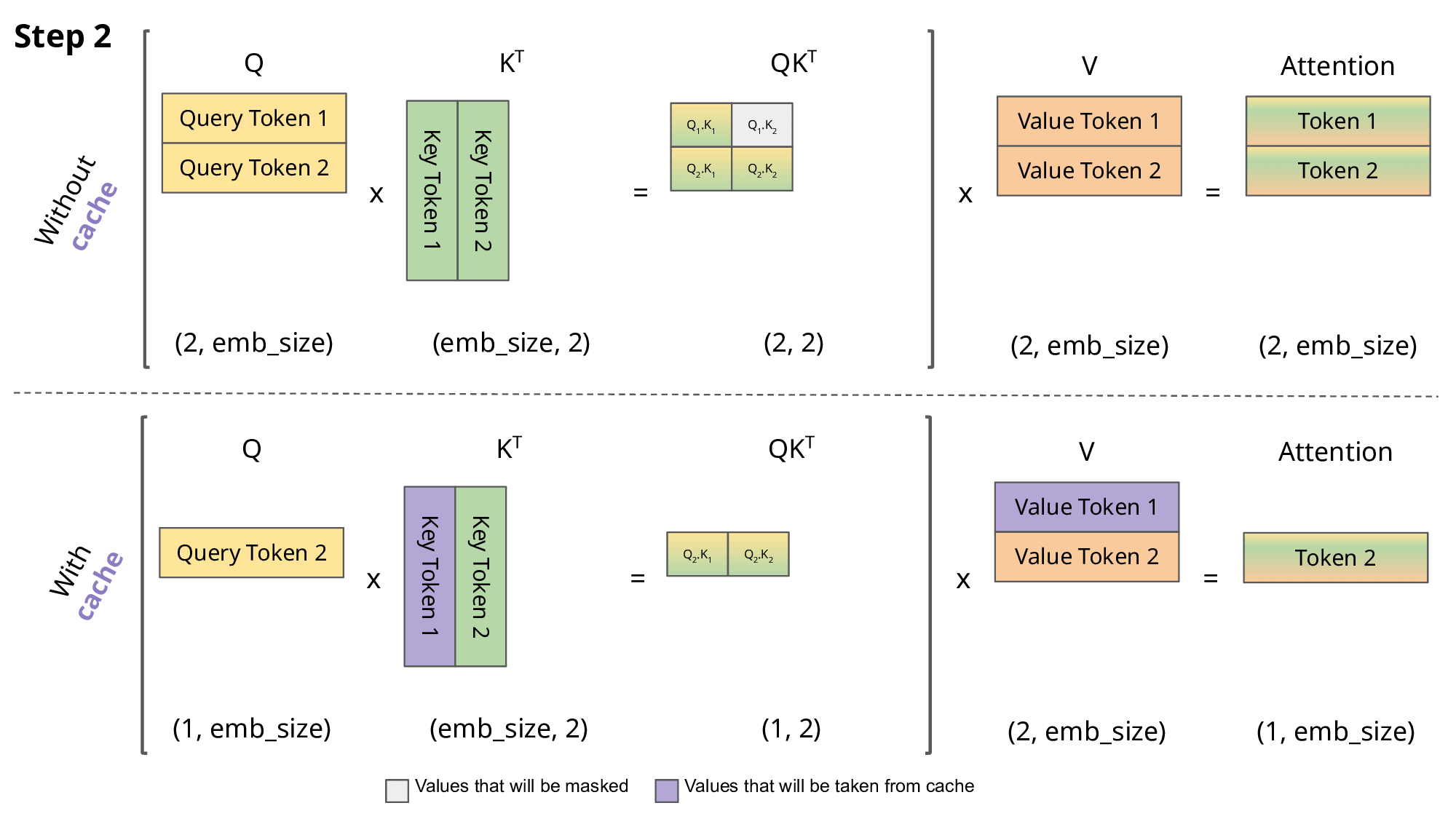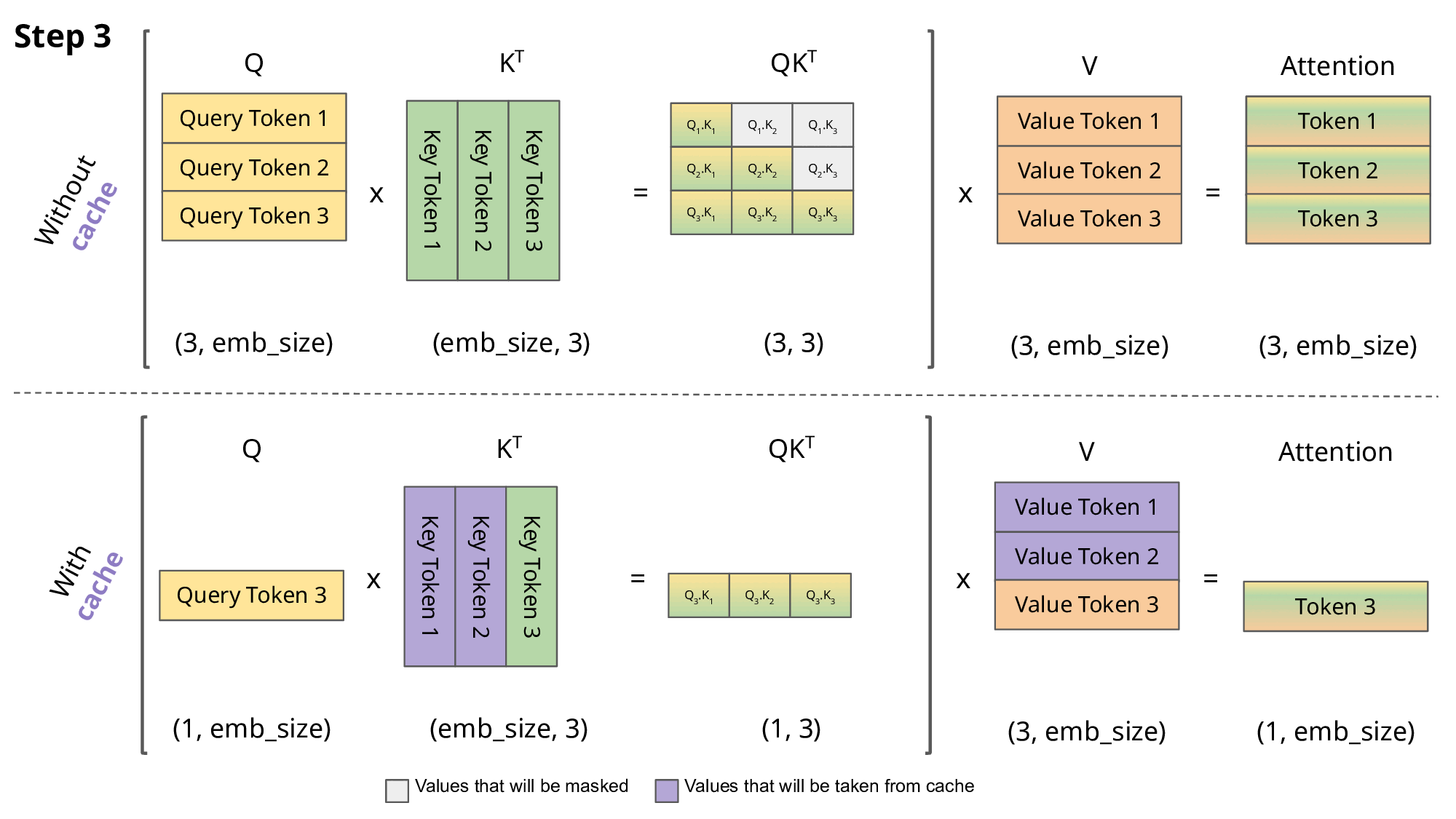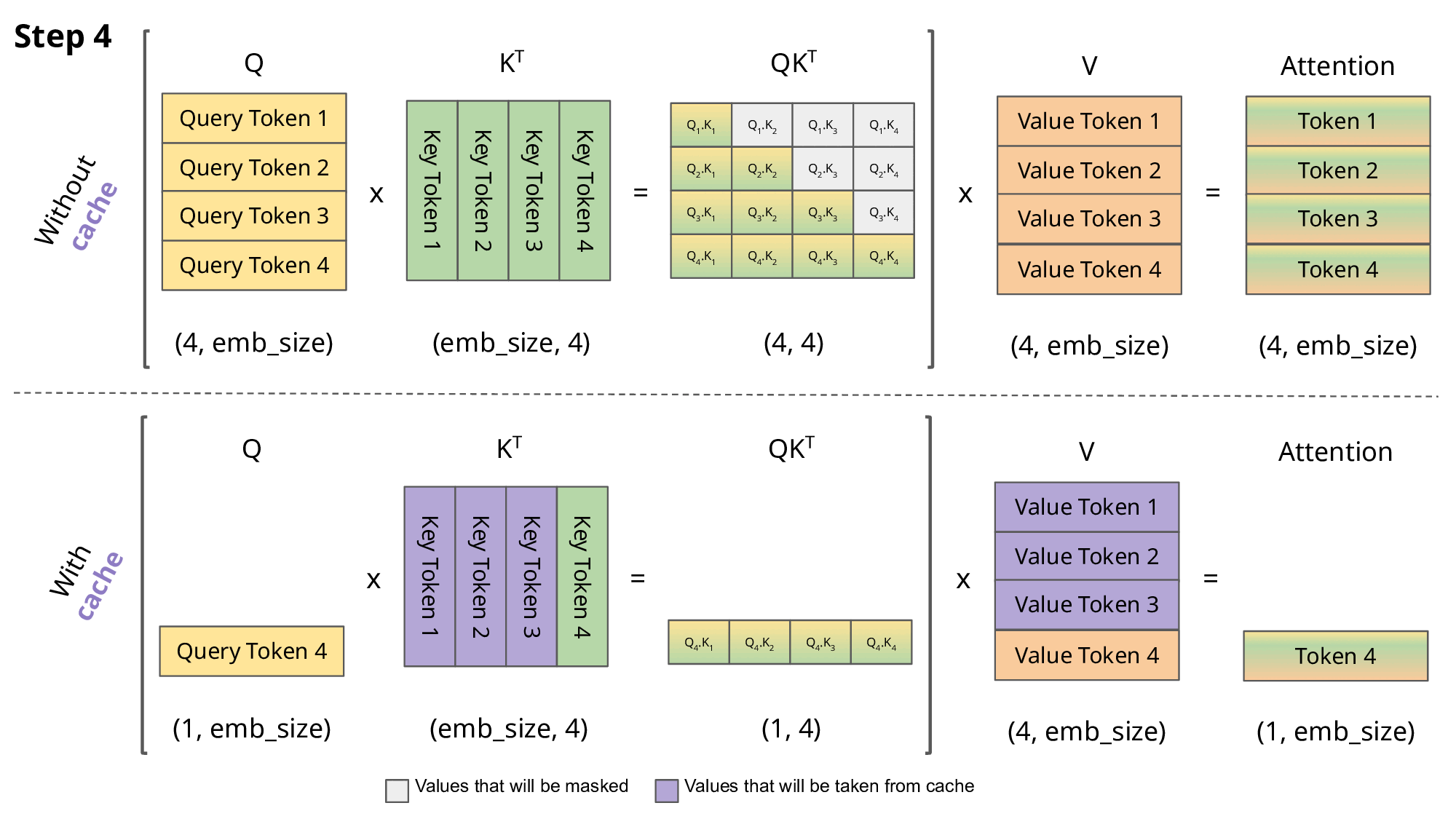
多头MHA的Kv cache 的简单实现:
import torch
import torch.nn as nn
import mathclass CachedAttention(nn.Module):def __init__(self, d_model, num_heads):super().__init__()self.d_model = d_modelself.num_heads = num_headsself.head_dim = d_model // num_heads# 定义线性变换层,将输入映射到Query、Key和Value空间self.q_proj = nn.Linear(d_model, d_model)self.k_proj = nn.Linear(d_model, d_model)self.v_proj = nn.Linear(d_model, d_model)# 定义输出线性变换层,将注意力计算结果映射回原维度self.out_proj = nn.Linear(d_model, d_model)def forward(self, x, kv_cache=None):b, t, c = x.shape# 将输入x通过线性变换得到Query,并调整形状和维度q = self.q_proj(x).view(b, t, self.num_heads, self.head_dim).transpose(1, 2)# 将输入x通过线性变换得到Key,并调整形状和维度k = self.k_proj(x).view(b, t, self.num_heads, self.head_dim).transpose(1, 2)# 将输入x通过线性变换得到Value,并调整形状和维度v = self.v_proj(x).view(b, t, self.num_heads, self.head_dim).transpose(1, 2)if kv_cache is not None:cached_k, cached_v = kv_cache# 将缓存中的Key和当前计算的Key拼接起来k = torch.cat((cached_k, k), dim=2)# 将缓存中的Value和当前计算的Value拼接起来v = torch.cat((cached_v, v), dim=2)# 计算注意力分数,这里除以根号下head_dim是为了缩放attn = (q @ k.transpose(-2, -1)) * (1.0 / math.sqrt(self.head_dim))# 对注意力分数进行softmax归一化attn = attn.softmax(dim=-1)# 根据注意力分数对Value进行加权求和y = (attn @ v).transpose(1, 2).contiguous().view(b, t, c)# 通过输出线性变换层得到最终输出y = self.out_proj(y)return y, (k, v)
1.2 存在的问题
看下attention计算的公式:
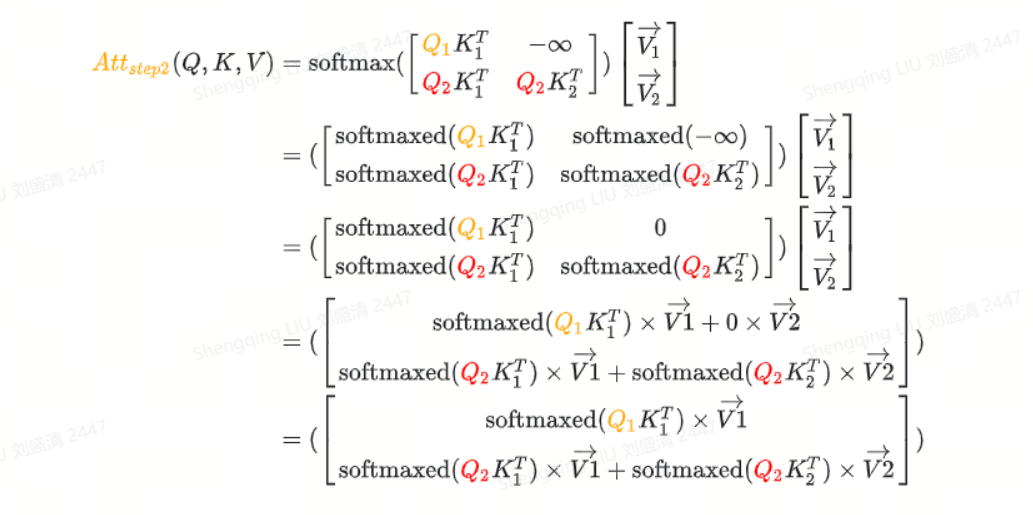
从上面的可以知道:
-
attention2的计算和Q2, K1, K2, V1, V2有关系。
-
如果我们把之前已经计算好的K1, V1 保存起来,那么这一步的计算量就节省了,从而可以使用空间换时间,加快计算速度。
-
人们总是不断的追求极致, 那么能不能再进一步的节省空间,减少KV cache的同时,保证计算的效果还能达到要求呢。
所以后续就出现了一系列的attention的优化方法。这里先上一张简洁明了的示意图。后续再聊