MIT 6.5940(二)
使用HAN Lab开发的工具进行模型压缩的研究。
Lecture 9 Knowledge Distillation


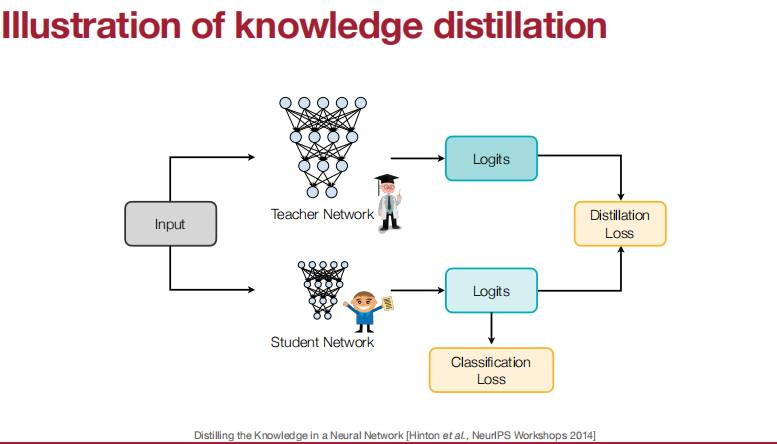
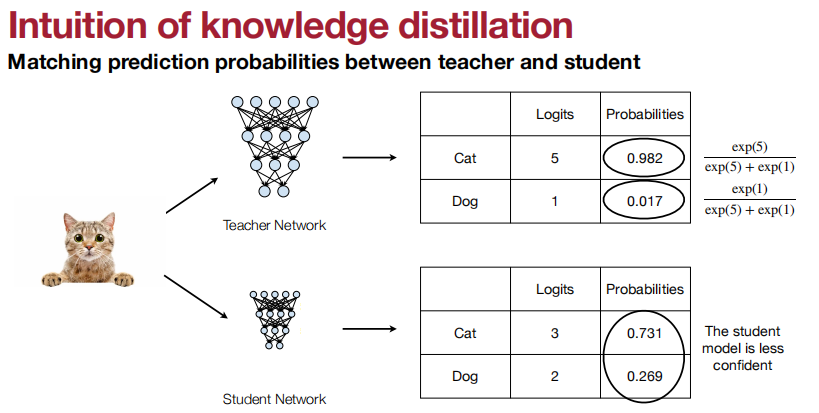

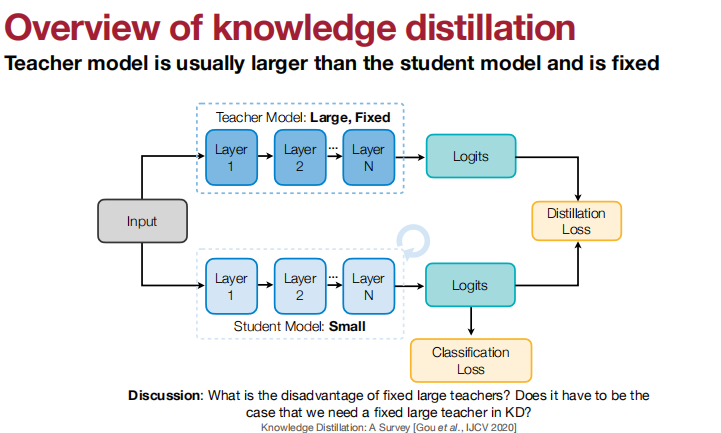
可以匹配什么呢?
输出的logits、中间权重、中间特征、梯度、稀疏模式、相关性信息。

对其梯度的有效性的直观理解:

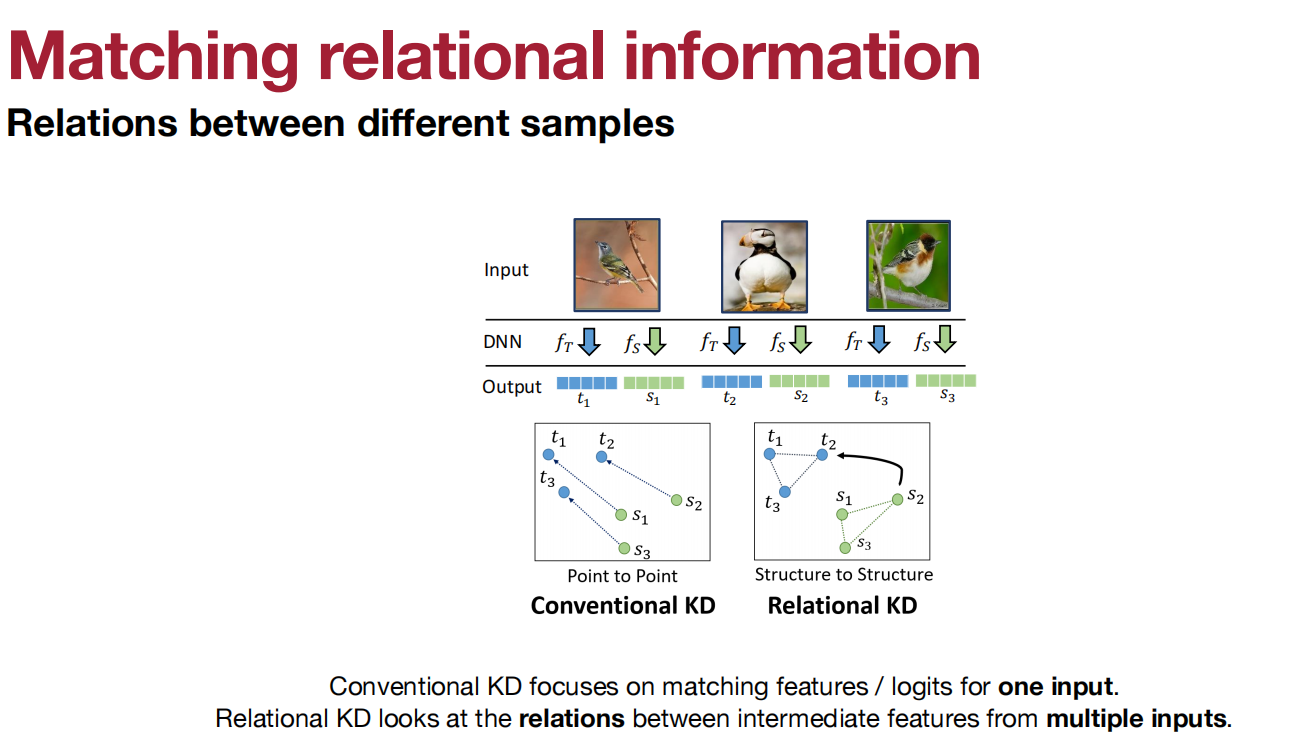
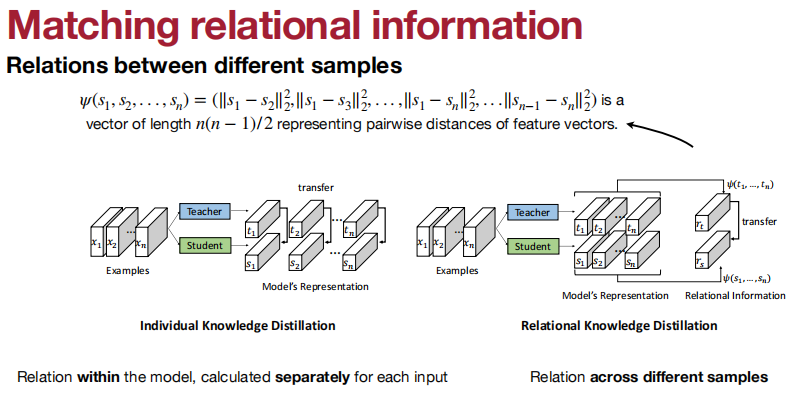
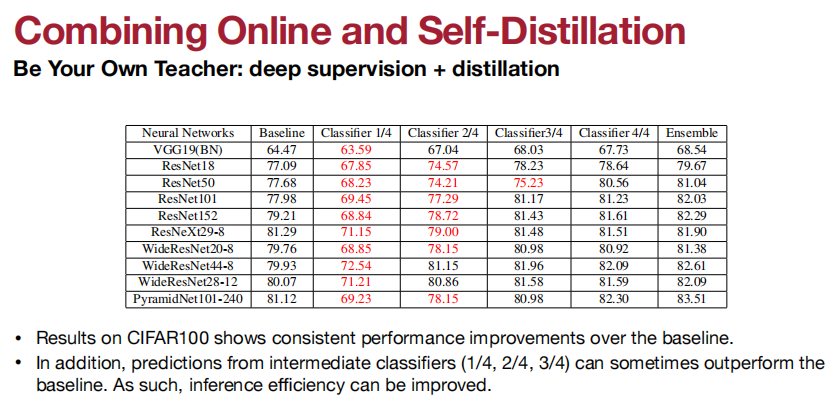
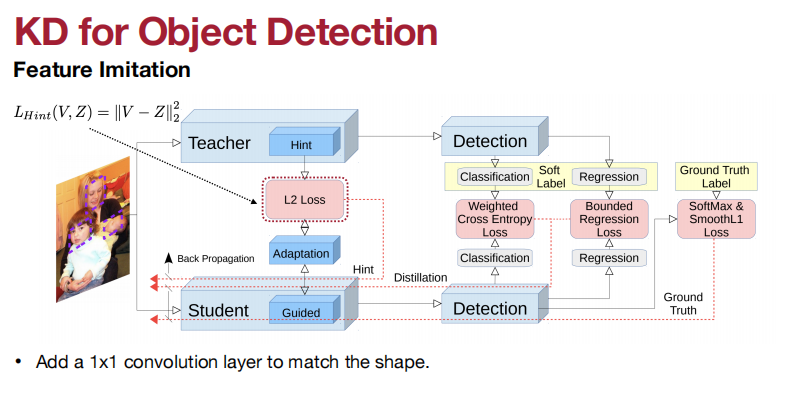
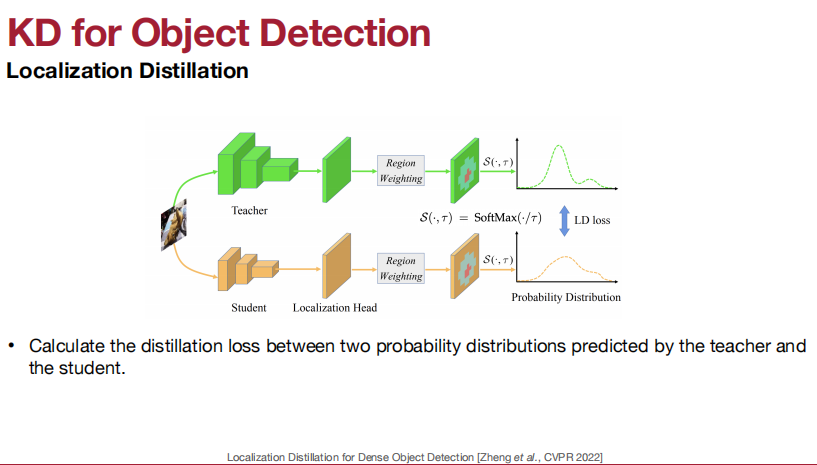
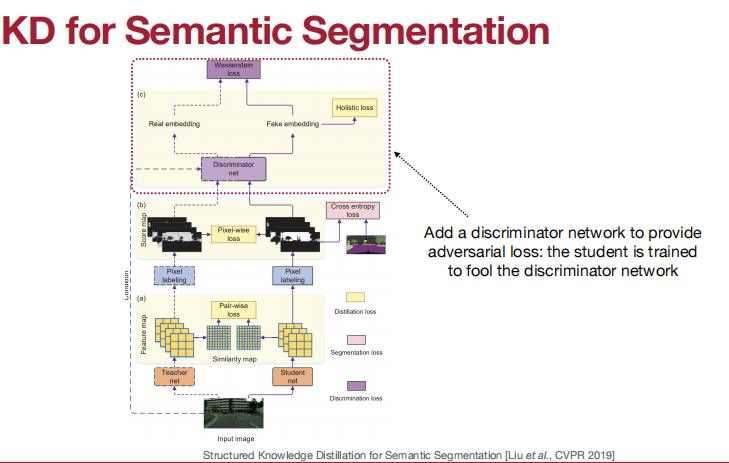
KD for 目标检测:
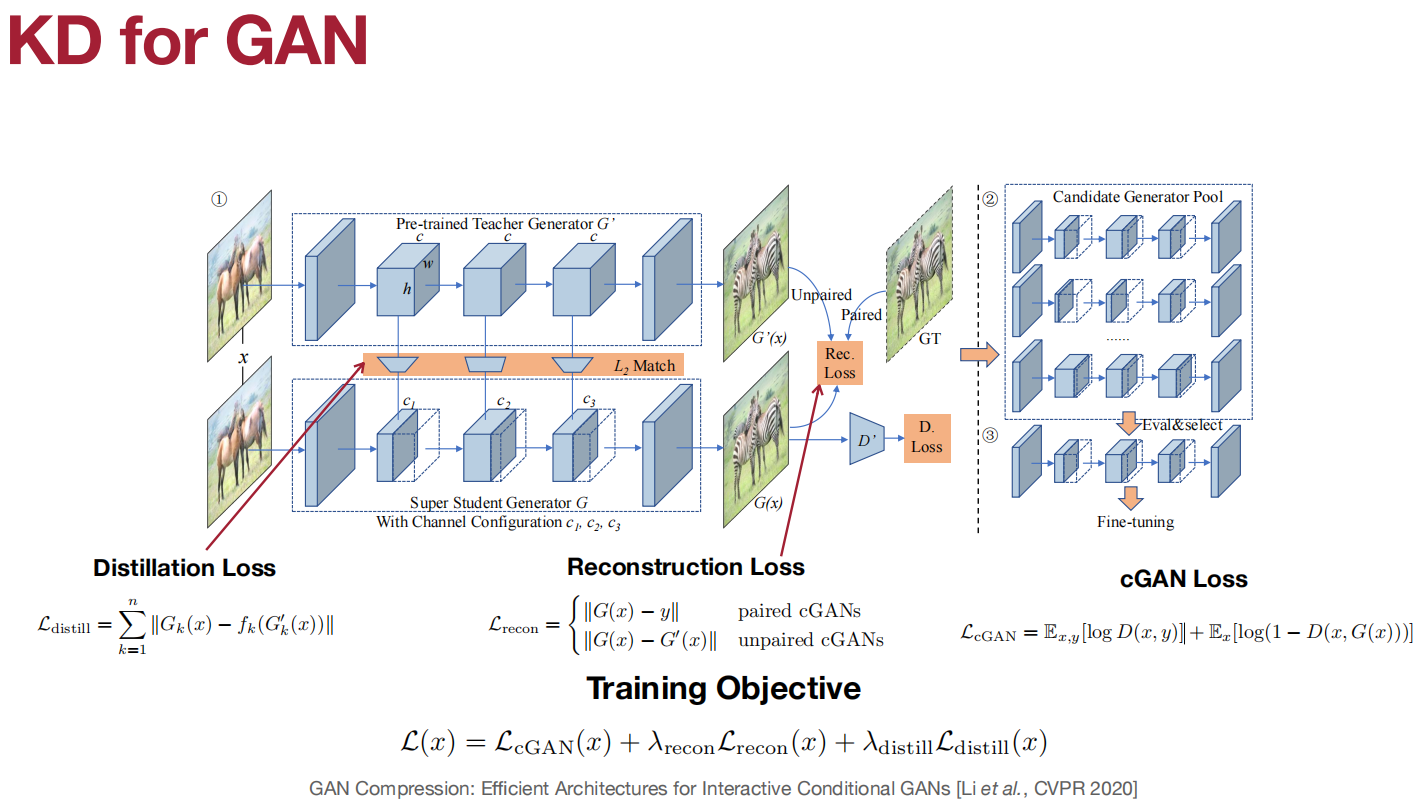
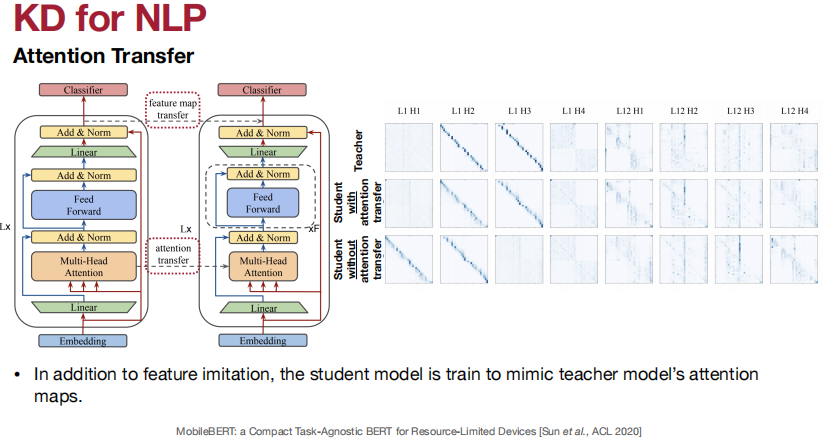
匹配特征和特征图。

数据增强也十分关键。
Dropout或者数据增强提升大神经网络的性能。
但是,Dropout或者数据增强会损害小神经网络的性能。
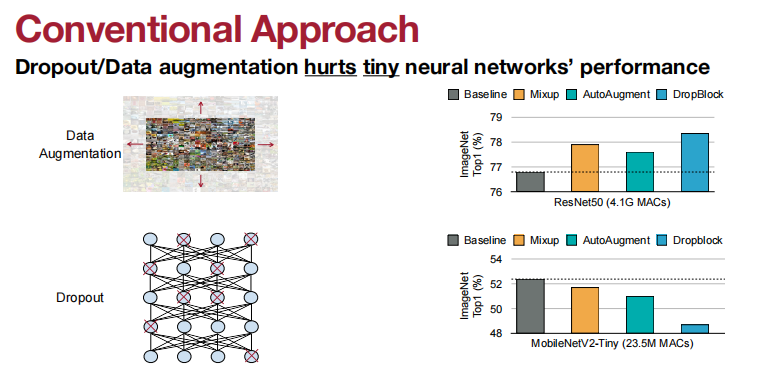
使用Dropout或者数据增强会损害小神经网络的性能的原因是:
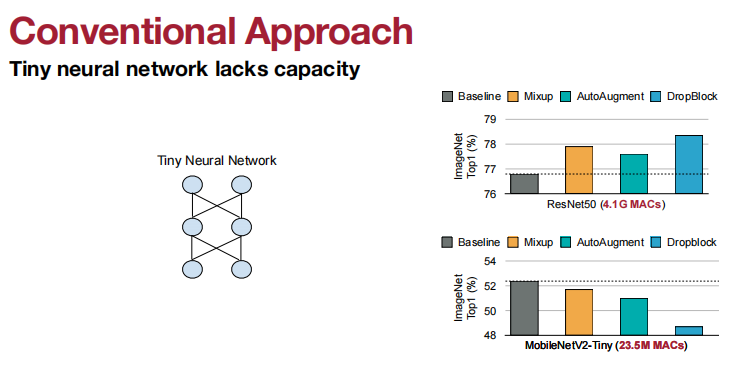
小神经网络缺乏容量。

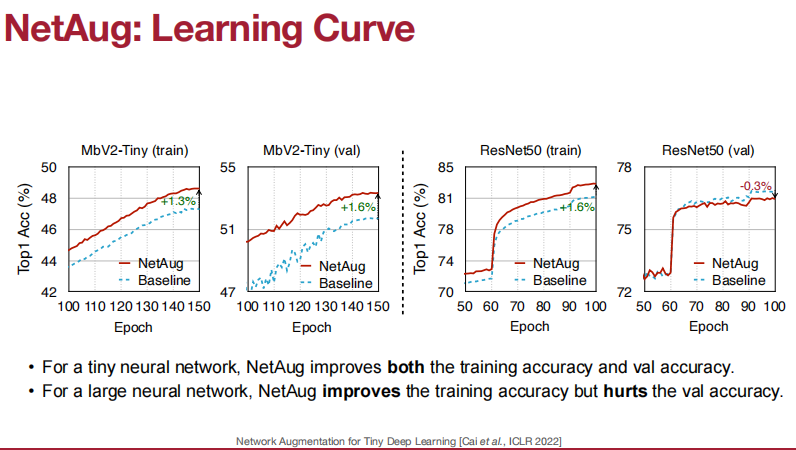
第一步:训练比较大块的网络。
第二步:保留中间部分,大块两边的随机选择一些,然后一起训练。
第三步:类似第二步,继续随机选择一些两边的。
Lecture 10 MCUNet and TinyML

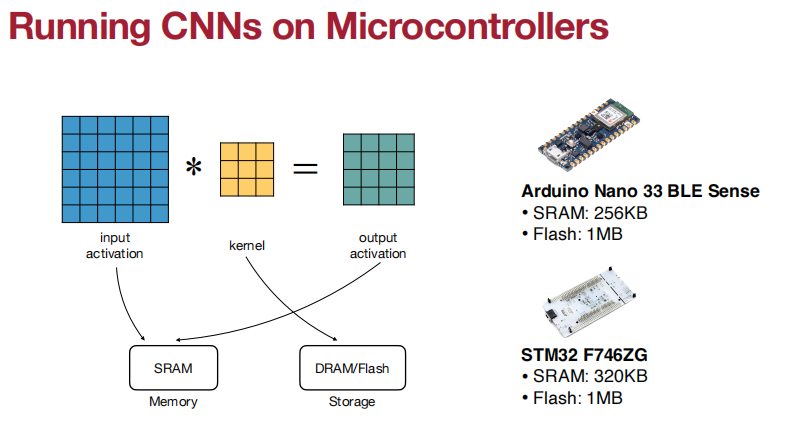
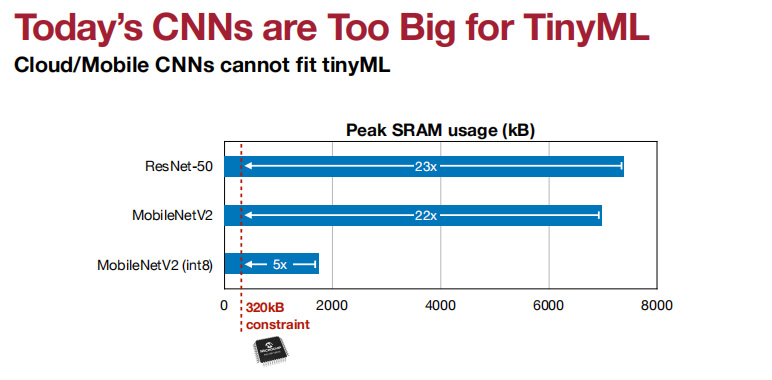
memory size对于运行DNN来说,很小。
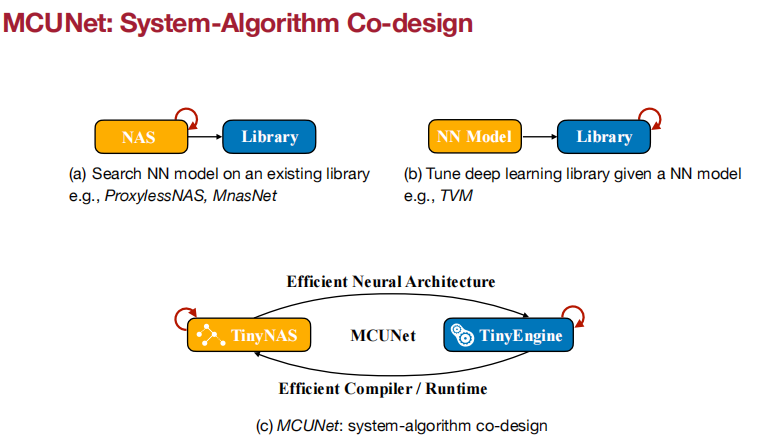
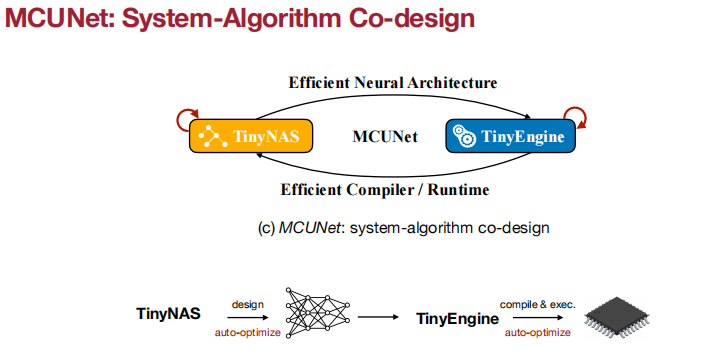
Tiny的图画得不错啊。
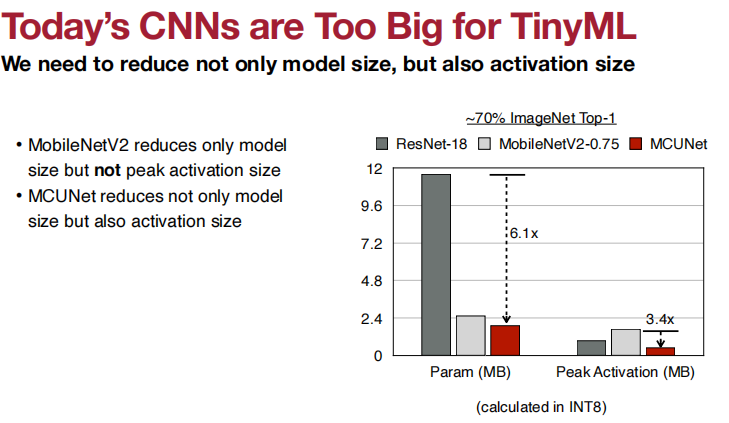
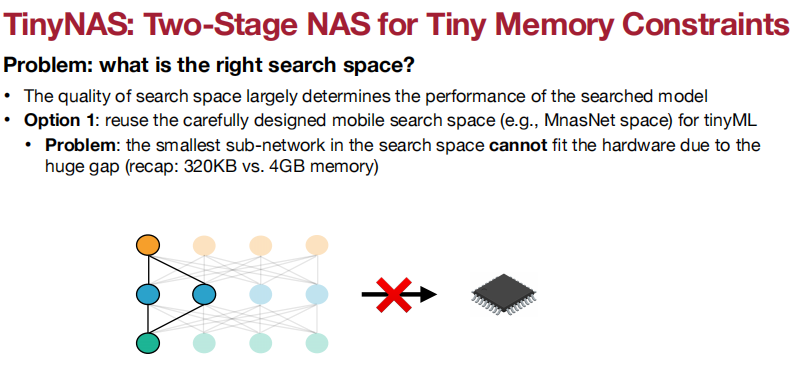
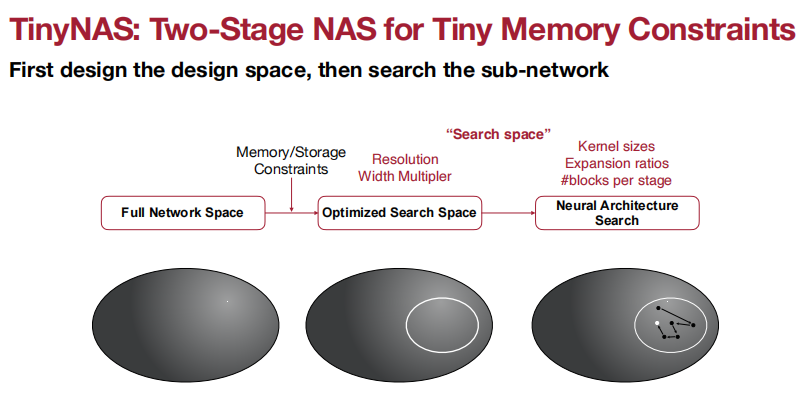
搜索空间的质量极大程度决定了搜索模型的性能。

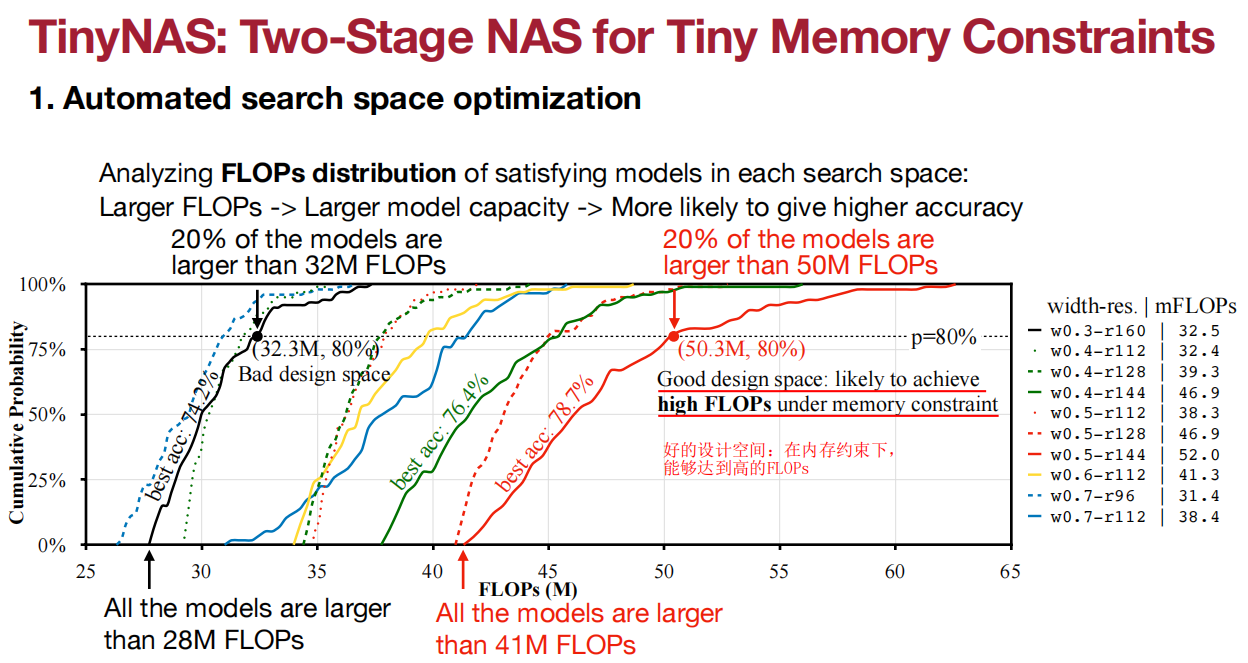
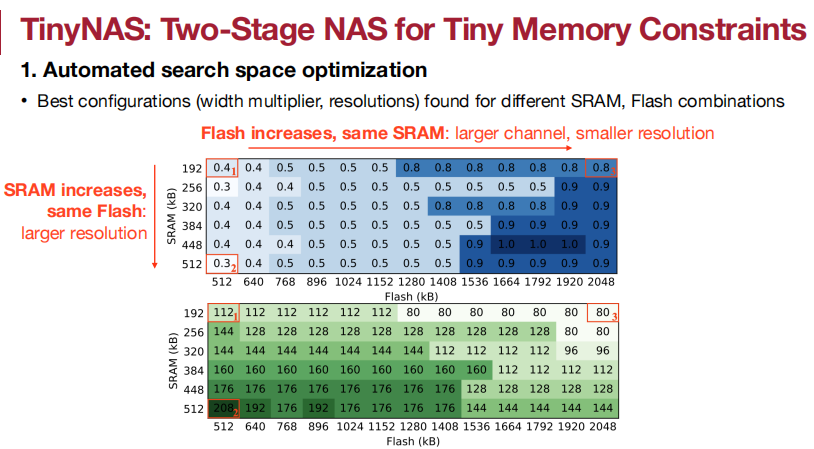
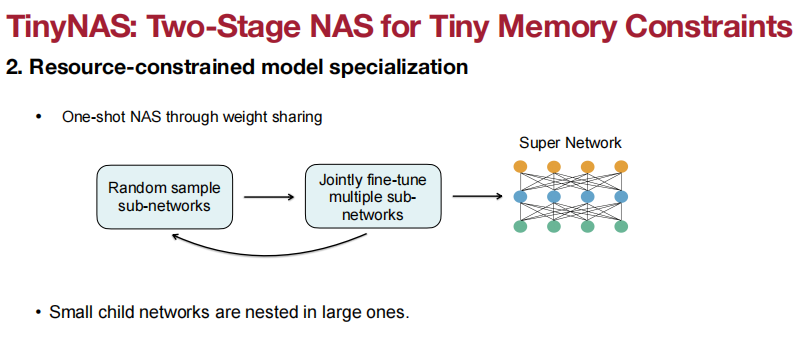
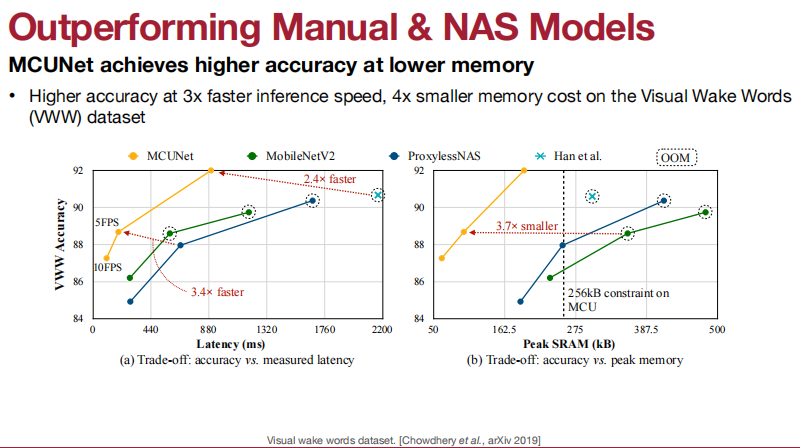
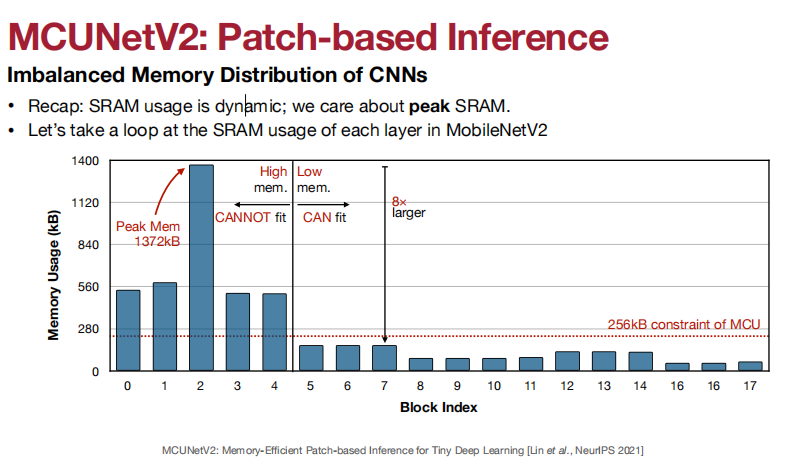
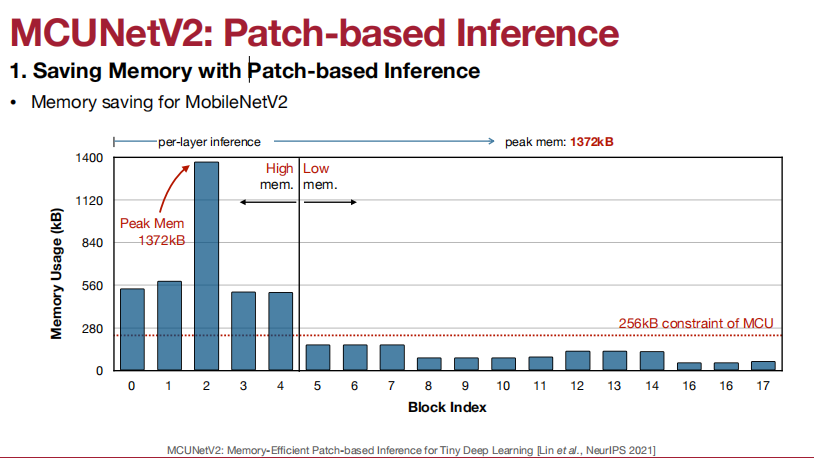
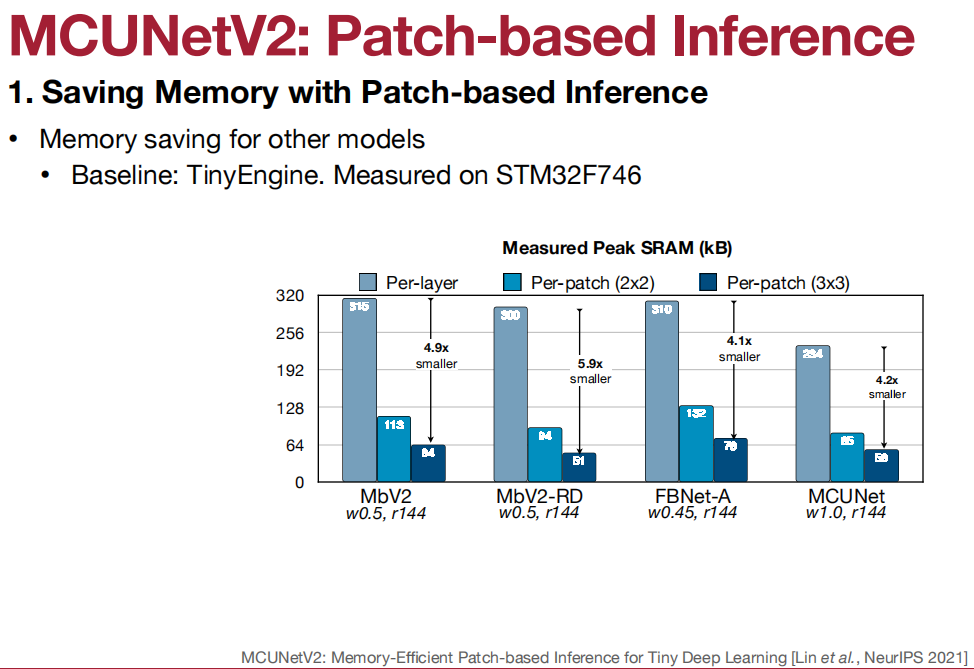
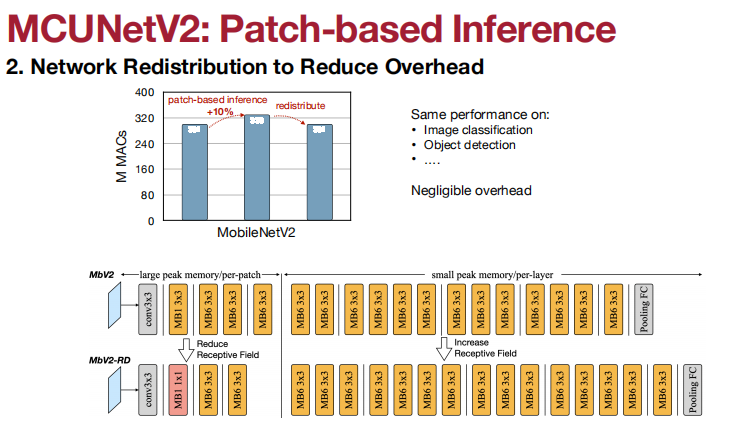
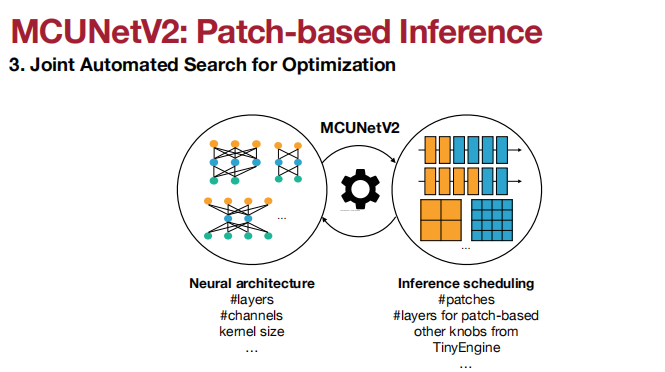
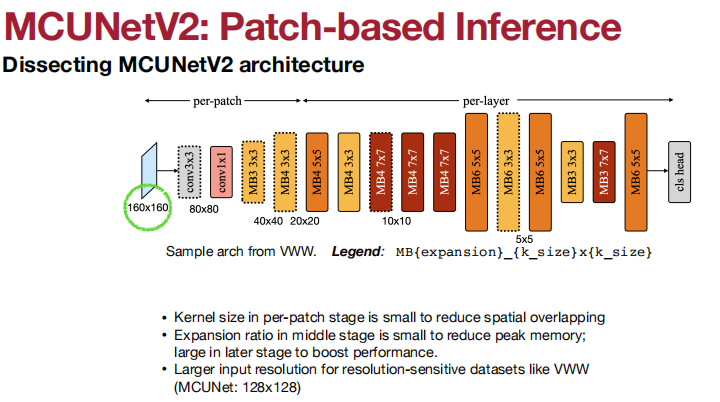

应用于Visual Wake Words(视觉唤醒词)、
Small-footprint Keyword Spotting、
time series/anomaly detection。
使用HAN Lab开发的工具进行模型压缩的研究。
Lecture 11 TinyEngine

循环重排序:
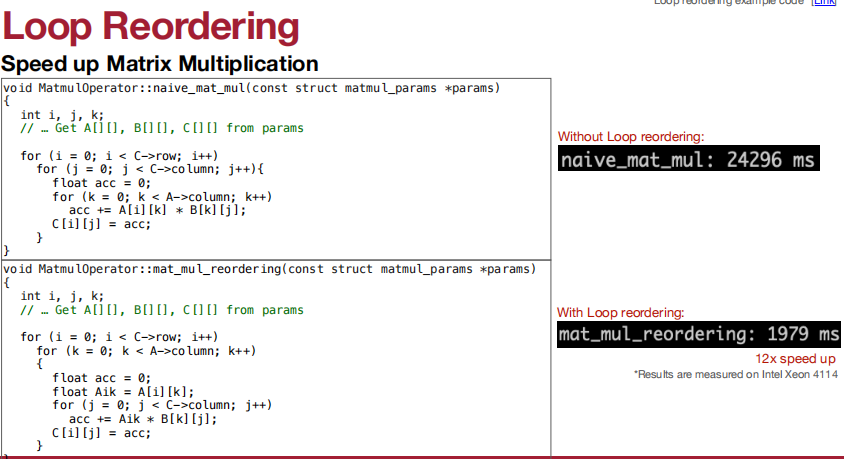
仿照CNN的计算:





不同的线程可以在不同的CPU核心上运行,从而提高性能并允许并行性。
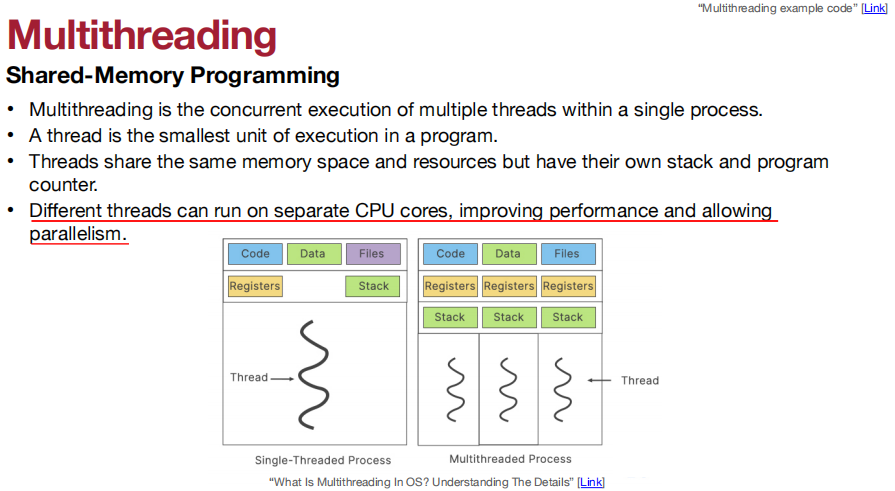
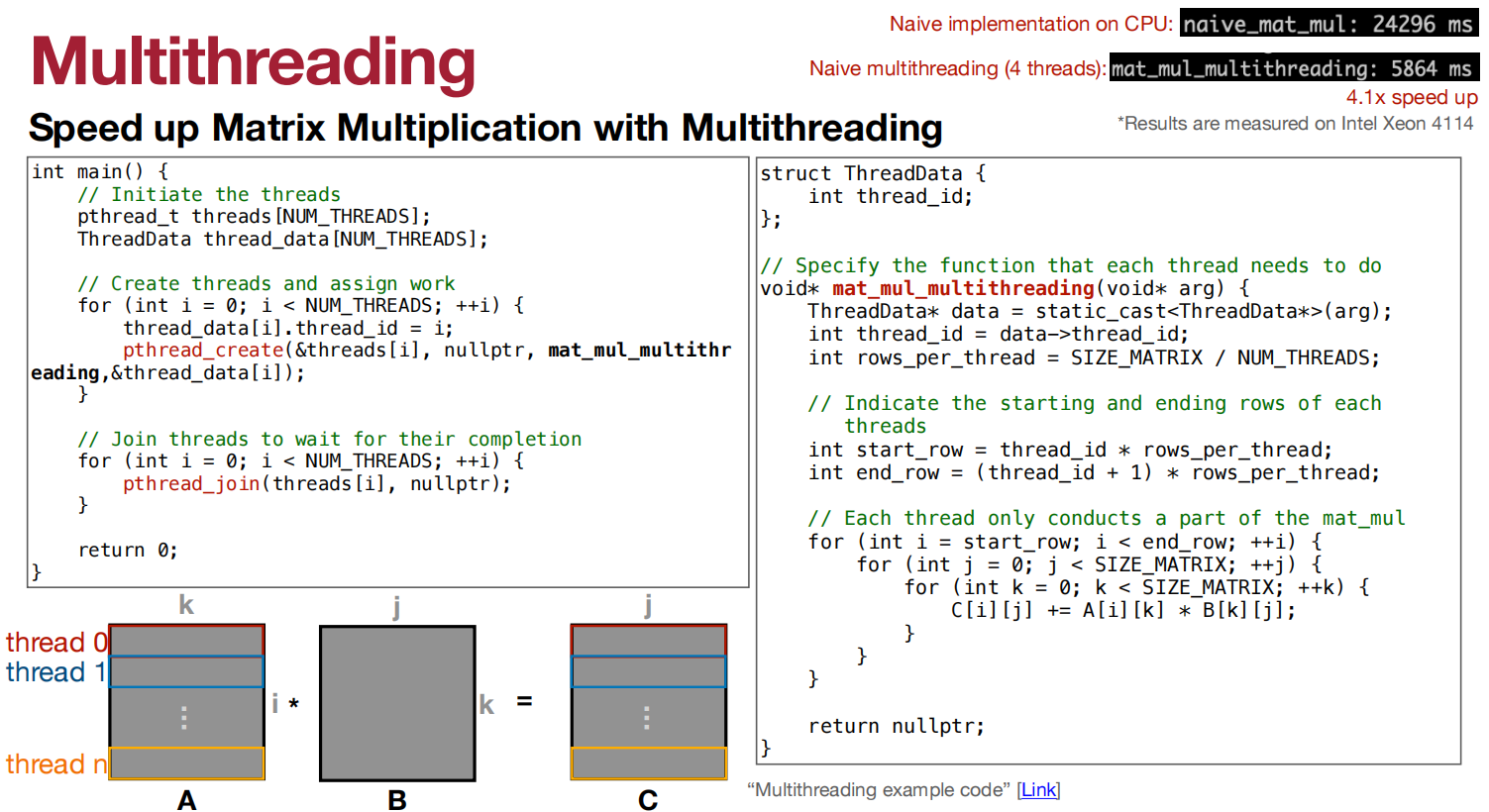
用Multithreading加速矩阵乘法的速度
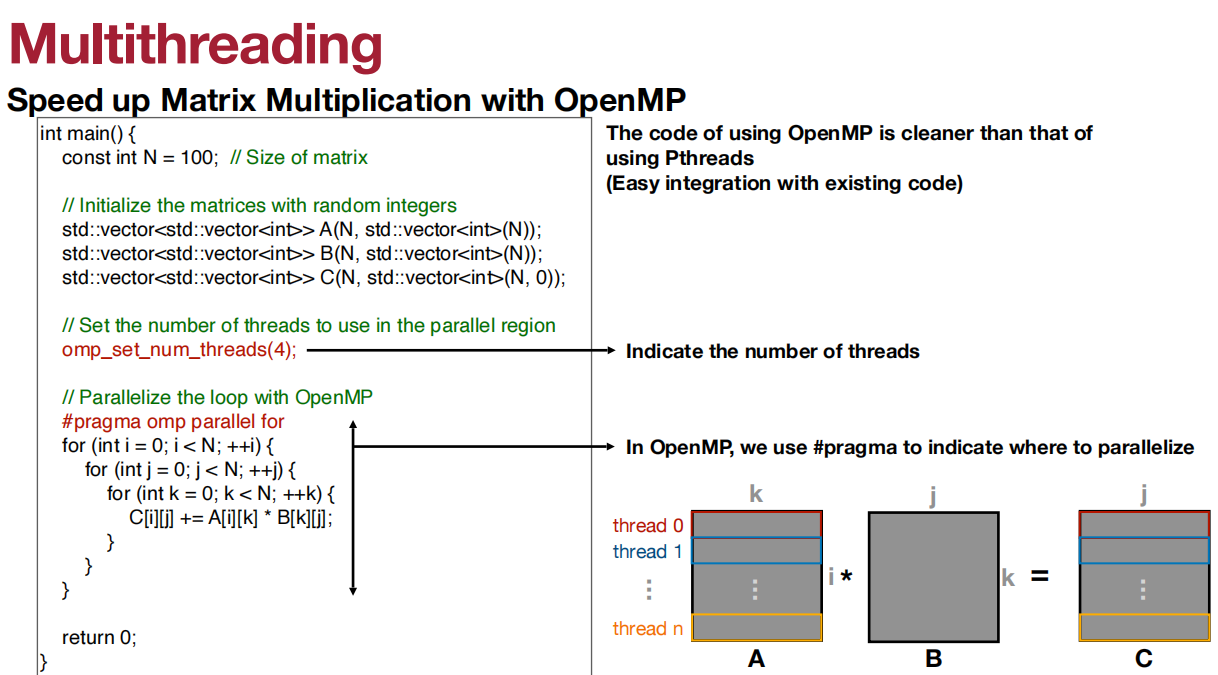
使用OpenMP加速矩阵乘法的速度

CUDA编程的内存模型:
- 不同的主机和设备地址空间
- 数据可以在不同的地址空间之间移动

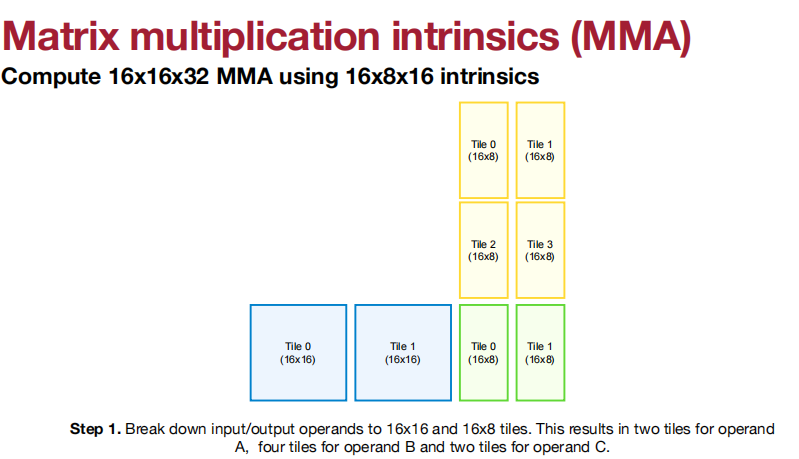
也可以获得更高的吞吐量和更多的数据类型。
推理优化

Winograd Convolution不理解。

Lecture 12 Transformers and LLM
双方向RNN用于辨别任务(encoding)
单方向RNN用于生成任务(decoding)
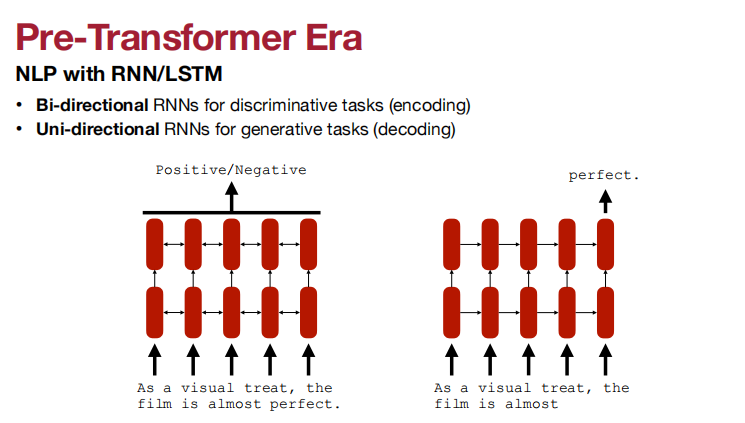
RNN/LSTM的微博图
- 难于建模长周期关系
- 有限的并行训练
Transformer
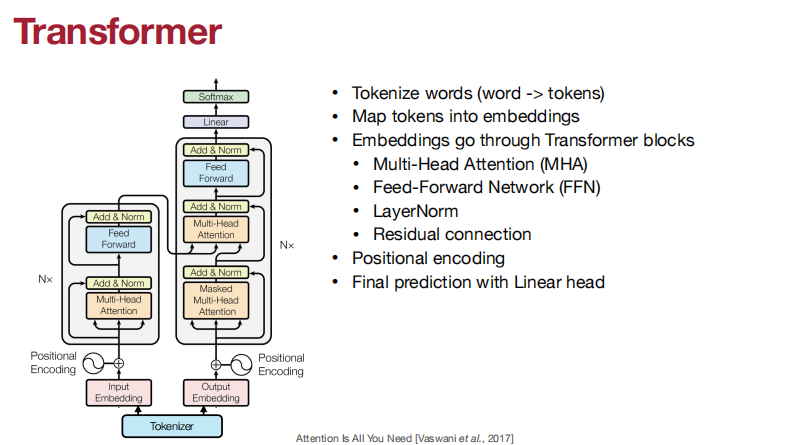
Tokenization

Map tokens into embedding
One Hot Encoding: 将每个单词表示为一个向量,该向量中的值与词汇表中的单词一样多。一个向量中的每一列表示一个词汇表中的一个可能的单词。

Word Emdbedding: 将单词索引映射到通过查找表嵌入的连续单词。

Embeddings go through transformer blocks
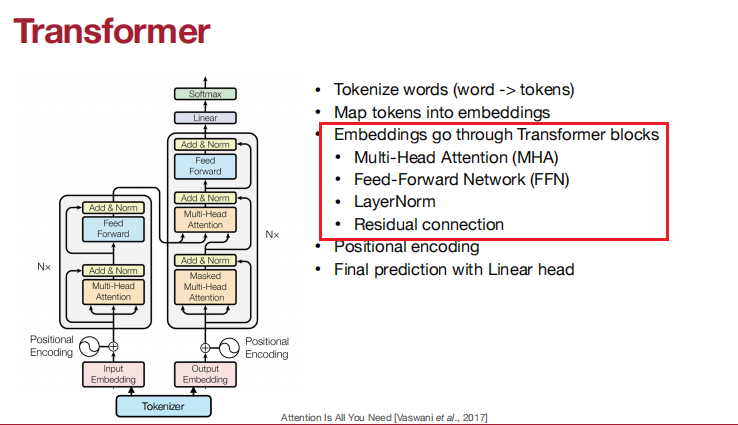
多头注意力机制、前向传播网络、层归一化、残差连接。
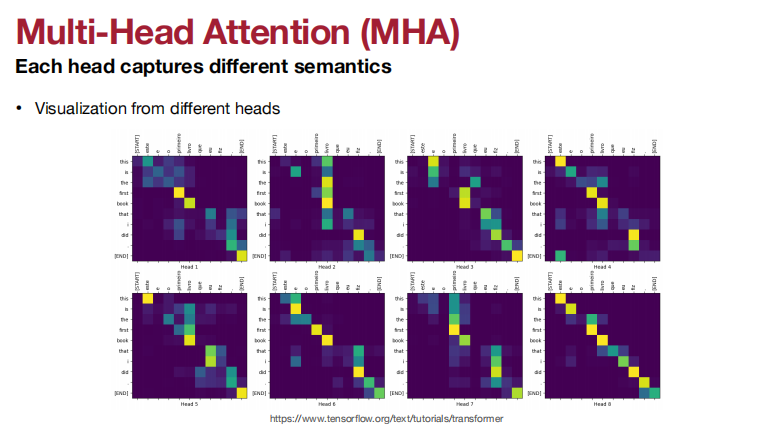
多头注意力机制:
多头注意力机制每个头可以捕捉不同的语义信息。
前向传播网络:
自我注意模型是令牌之间的关系,但没有元素级的非线性。
添加一个前馈网络(FFN),以帮助进行功能建模。

层归一化
残差连接
Pre-Lorm设计现在更流行。因为它有更好的训练稳定性。
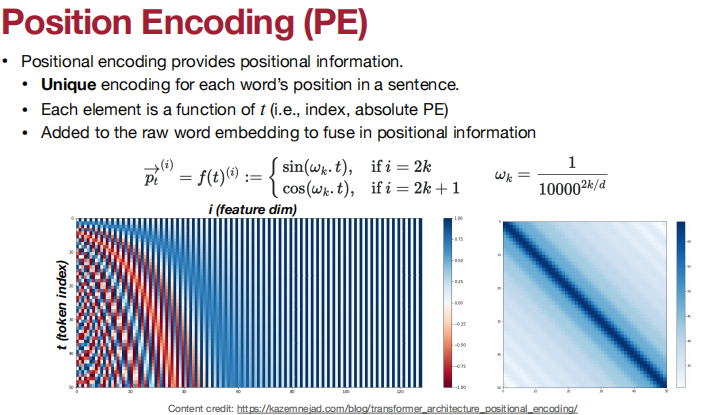
问题:注意和FFN不区分输入令牌的顺序(不像卷积)
集编码(坏的),而不是序列编码(好的)
解决方案:位置编码!
Encoder-only (BERT)
两个预训练方法:MLM、NSP
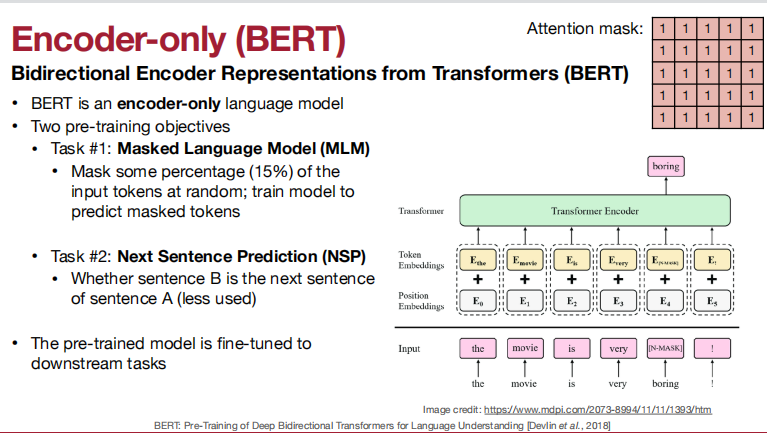
Decoder-only: Generative Pre-trained Transformer (GPT)
更大的模型可以运行在zero-shot/few-shot情况下。
Transformer设计变体
- 绝对位置编码变为相对位置编码。
- KVcache优化。
- FFN变为GLU。

相对位置编码通过影响注意力分数(增加偏差或修改查询和键)来提供相对距离信息,而不是影响V。

RoPE: 能够扩展上下文窗口。
在传统的Transformer模型中,位置编码通常被添加到输入嵌入中以保留序列中的位置信息。然而,随着输入序列长度的增加,这种简单的位置编码方式可能会遇到限制,特别是在处理非常长的文本时。RoPE通过将位置信息直接融入到注意力机制中解决了这个问题。
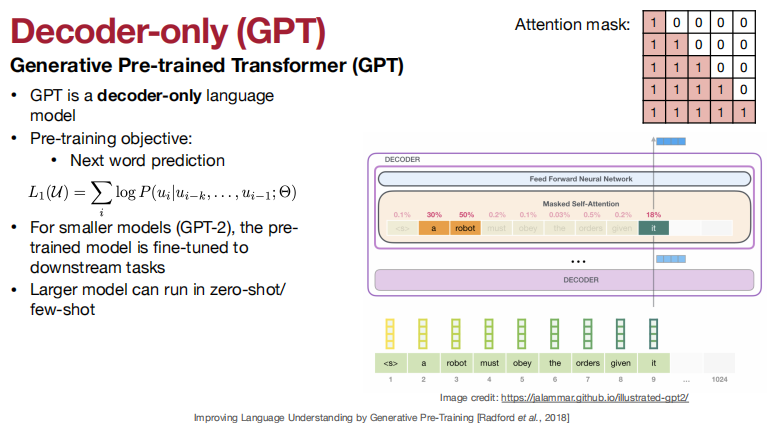
KV cache optimizations

使用MQA/GQA来降低KV cache的内存使用情况
(GQA挺常用)
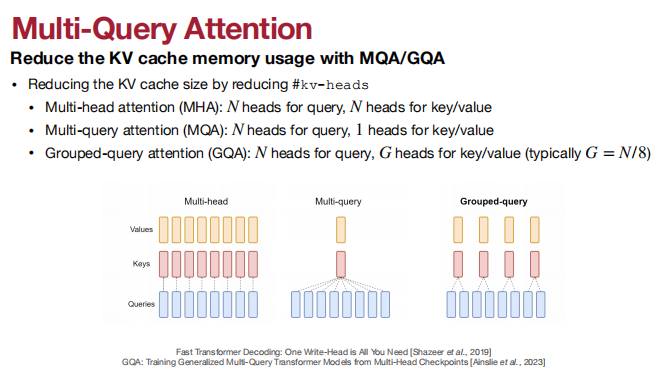
门线性单元(Gated Linear Units, GLU):使用GLU来取代原始FFN。

LLMs
趋势就是LLM规模越来越大。
将Transformer扩展为few-shot learner(上下文学习)

GPT家族、OPT、LLaMA、Llama 2、Llama3、Mistral-7B。
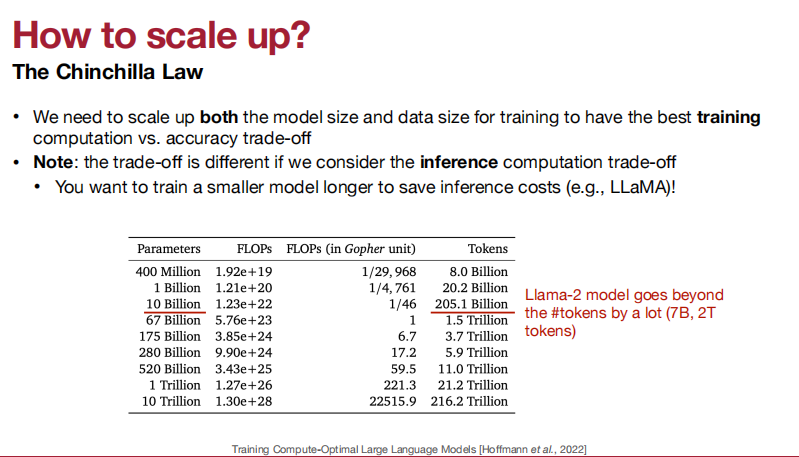
扩大规模的方法:The Chinchilla Law。
- 我们需要扩大模型的大小和数据的大小来进行训练,以获得最佳的训练计算和准确性的权衡。
Lecture 13 LLM Deployment Techniques
Quantization;Pruning & Sparsity;LLM Serving Systems。
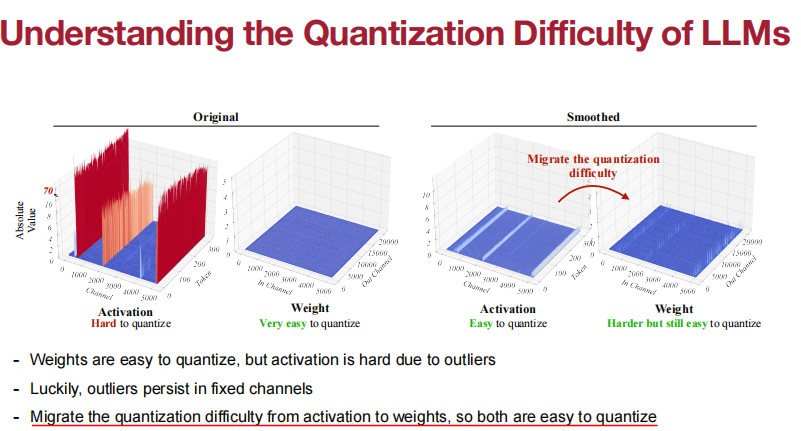
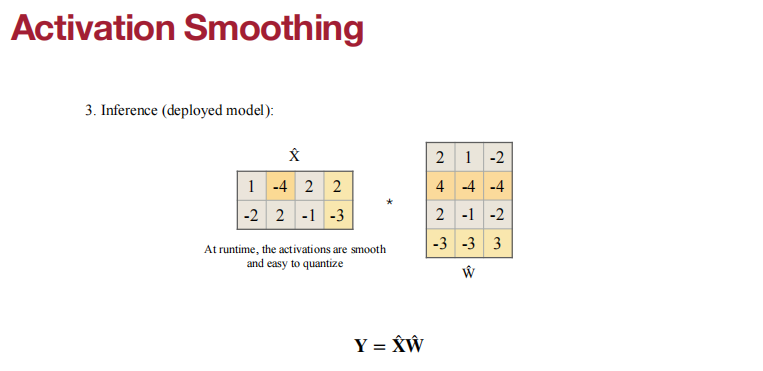
当我们将LLM扩展到6.7B以上时,激活中就会出现系统异常值。传统的CNN量化方法会破坏其精度。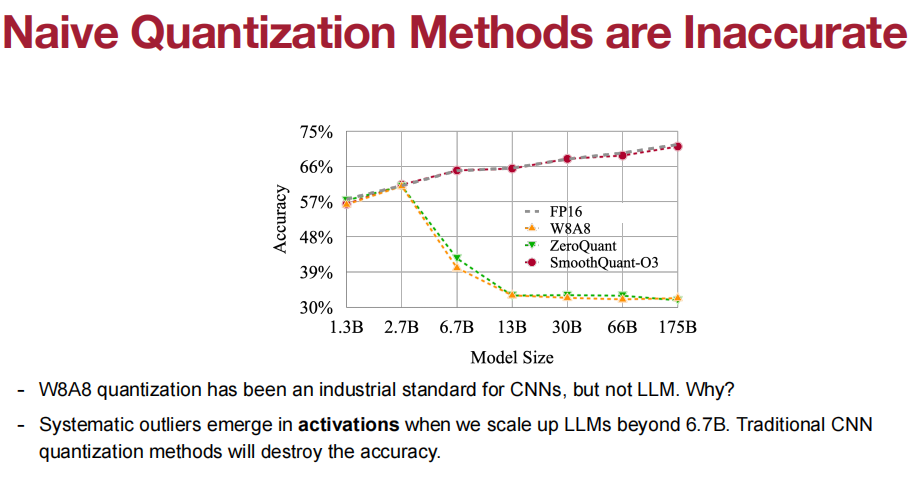
- 权重很容易量化,但激活由于异常值很难量化。
- 幸运的是,异常值仍然存在于固定的通道中。
- 将量化难度从激活迁移到权重,所以两者都很容易量化。
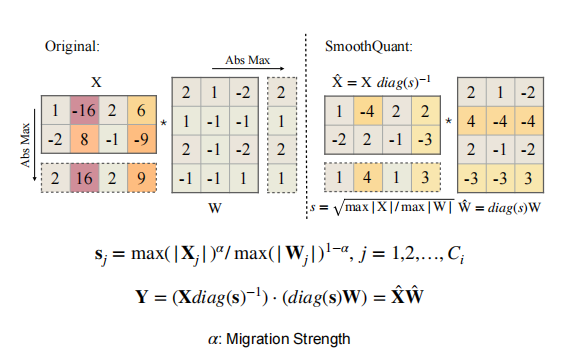


为啥有一些是FP16量化,有一些是INT8量化。

我们发现权重并非同等重要,仅保留 1% 的显著权重通道不进行量化,就能够大幅降低困惑度。
AWQ:Activation-aware Weight Quantization
待详读论文和代码。
W8-A8-KV8用于云服务,而W4-A16-KV16用于边缘推断。

MoE没看懂
SpAtten: token pruning & head pruning
H2O: token pruning in KV cache


总结:LLM Serving Systems完全听不懂。
Lecture 14 LLM Post-training
有监督微调可以让LLM更佳适配客户。

DPO简化了基于RL的方法的两个模型为单个模型:
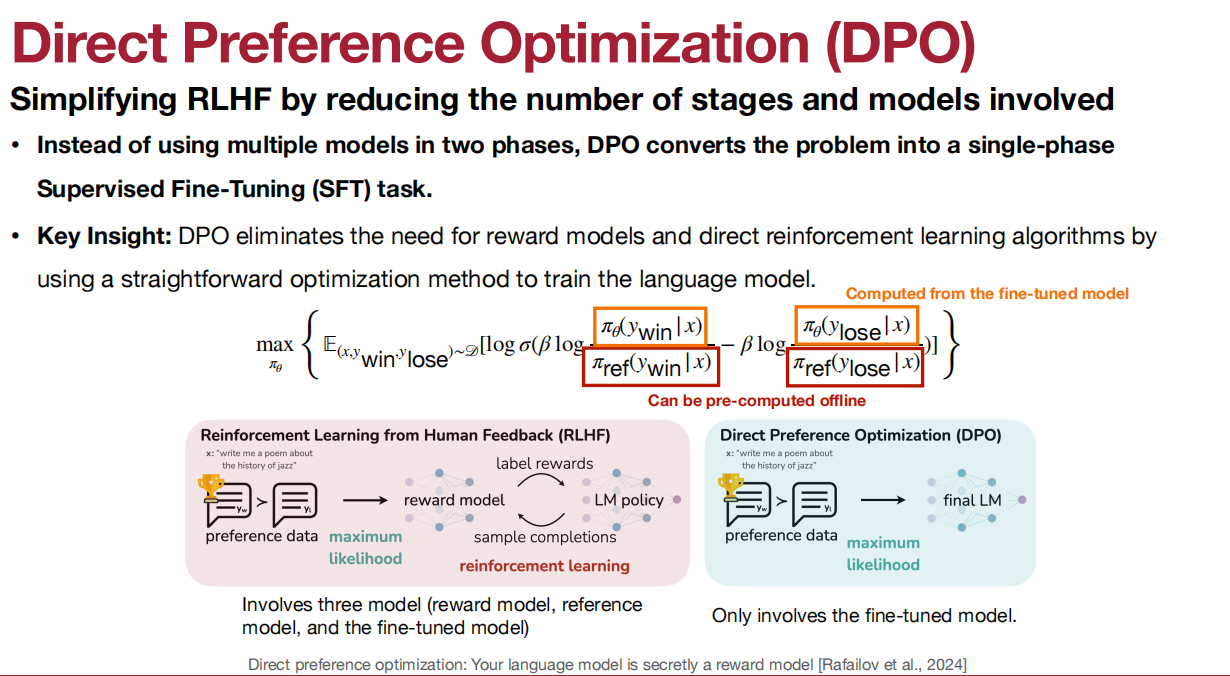
BitFit:仅微调偏差项。
TinyTL:关键原则-保持激活大小较小。1.降低分辨率2.避免倒置瓶颈。
Adapter:在变压器架构中插入可学习层。(每个任务只添加少量可训练参数,可以添加新任务而无需重新访问以前的任务。)
Prompt Tuning:从离散提示到连续提示。tune第一层
Prefix-Tuning:tune每一层。
LoRA Family:tune without adding any latency。

QLoRA是具有量化主干和分页优化器状态的LoRA。
Bit-Delta:
设置为系数×sign。
需要优化系数。
将权重增量量化到1位,而不会影响性能,微调缩放因子(每个张量)

Vision Languange Model
两种方式:
- 交叉注意力,将视觉信息注入到LLM中(Flamingo风格)
- 将视觉标记作为输入(PaLM-E风格)
Prompt Engineering
- In-Context Learning (ICL)
- Chain-of-Thought (CoT)
- Retrieval Augmented Generation (RAG)
ICL:
在ICL中,用户通过在提示中提供输入-输出对实例,让模型“模仿”示例的模式来解决新问题。
RAG:
- 嵌入模型:文档被转换成向量,这使得系统更容易管理和比较大量文本数据。人们使用如MTEB这样的基准来评估嵌入模型。
- 检索器:获取与查询最相关的文档向量。
- 重排序器(可选):确定检索到的文档与当前问题的相关性,并为每个文档提供一个相关性评分。
- 语言模型:根据检索器或重排序器提供的顶级文档以及原始问题,构建精确的答案。
Lecture 15 Long Context LLM
长上下文LLM

Lecture 16 Vision Transformer

窗口注意力机制
线性机制:
- 替代Softmax Attention为Linear Attention
- 加入depthwise convolution到FFN 来增强linear attention的区域特征信息提取能力。
Lecture 17 Efficient GAN, Video, and Point Cloud

Efficient GANs
GAN Compression:
使用Neural architecture search来做automated channel reduction。
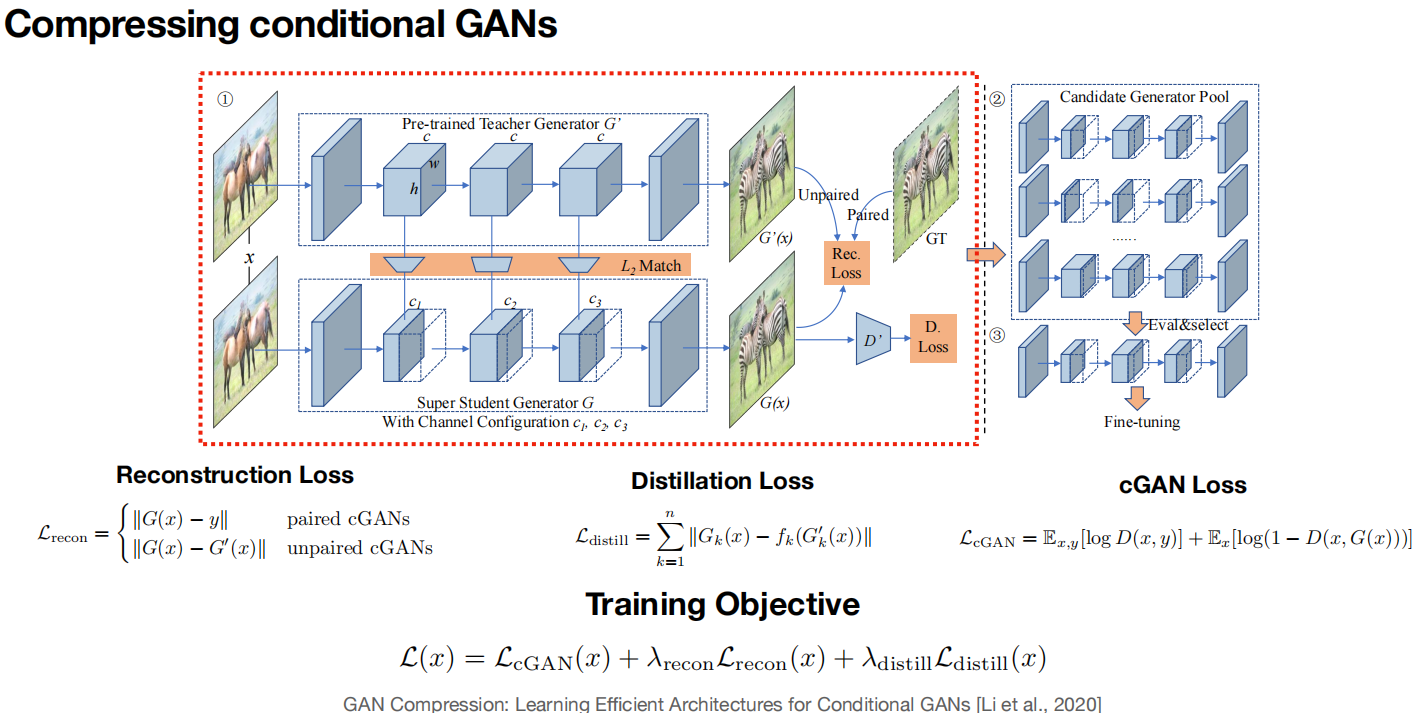
Anycost GAN:
基于采样的:
- 多分辨率
- 多通道
Differentiable Augmentation for Data-Efficient GANs
Efficient Video Understanding
TSM
略
Efficient Point Cloud Understanding
PVCNN / SPVCNN
BEVFusion
略
Lecture 18 Diffusion Model
略
Lecture 19、20 Distributed Training
Lecture 21 On-Device Training and Transfer Learning
22 总结
23 量子机器学习