文件雕刻——一种碎片文件的恢复方法
文件雕刻是指基于对文件格式而非其他元数据的了解,在数据流中搜索文件的一种过程。 当文件系统元数据损坏或无法使用时,雕刻非常有用。FAT 文件系统(通常用于小型介质)是最常见的例子。 删除文件或格式化介质后,文件系统将指向文件内容的指针归零,从而导致位置数据丢失。
连续文件和碎片文件
文件系统可以将介质上的文件存储在一个块中(连续文件或非碎片文件) 或在多个不相邻的块(非连续或碎片文件)中。
当没有足够的连续可用空间来写入文件时,就会产生碎片;文件系统必须将文件拆分为适合可用空间块的若干个部分。当多个文件同时写入卷时,或其他情况下,也会发生碎片。
碎片随着文件系统的老化以及文件的创建和删除而增加。越大的文件其碎片越多;对于较高分辨率的静止图像亦是如此;对于视频文件来说,其碎片更多。存储卡上一半或更多的视频文件碎片化是很常见的。
连续文件的雕刻
任何雕刻算法都需要能够识别文件头。 雕刻的第一步是扫描介质并生成文件头列表,这些列表表示文件的起始点。找到起点后,有几个选项可供选择:
- 文件头和固定文件大小的雕刻。从文件头开始获取一些固定数量的数据。对于文件末尾后的剩余数据可忽略不计的大多数格式的文件,都可以使用这种方法。例如,假设 JPEG 几乎不超过 100 MB, 可以从文件头开始捕获 256 MB 的数据。这种简单的方法将捕获所有连续的 JPEG 文件 (尽管每个文件的末尾都有多余的数据)。可以根据特定任务、文件类型和摄像机设置调整大小限制。对于那些不能容忍文件末尾后额外数据丢失的文件格式,例如原始 Canon CRW,则不适合采用此方法。
- 文件头和文件大小雕刻。此方法是上面固定文件大小的变体,在这个过程中,我们使用从文件头得出的大小而不是固定的大小。这个方法仅适用于文件头中存储了文件大小信息的那些文件格式。此方法生成的文件在已恢复文件的末尾没有额外的数据。
- 文件头和文件尾雕刻。如果文件末端有一些可识别的文件尾数据,则可以将捕获大小限制为文件头后最近的文件尾,最终生成末尾没有多余数据的文件。但是,此方法需要进一步适应可以嵌套的文件格式,最显著的示例是 JPEG 内部包含另一个 JPEG 缩略图。对于连续文件,这种情况很容易检测到,因为检测到的点以四个为一组,两个文件头后跟两个文件尾。
所有这些方法都很快。处理速度主要受源介质读取速度的限制。
碎片文件的雕刻
碎片化文件雕刻难度更大。介质中仍然保留有文件头,幸运的话,还可以从这些文件头中提取出文件大小。但是,文件被拆分为两个或多个片段,这些片段的顺序不一定正确。对于这种情况,要完成文件雕刻任务,需要一个验证函数和一个邻近性函数。
验证函数和邻近性函数
验证函数确定某个文件是否正确。好的验证函数非常难以实现。每种文件格式都需要相应的验证函数; 此外,针对格式的变体,需要适当的调整函数。如果文件格式记录不佳或根本没有记录,则可能无法构建良好的验证函数。对于具有独特校验和(ZIP 或 PNG)的文件格式,验证函数最容易构造。定义松散的格式(如纯文本或 XML)是最糟糕的。
邻近性函数用来确定两个块是否是属于同一文件的相邻块,其函数值可以是一个概率值或以任意单位测量的某个数值。
双片段中间带间隙的雕刻法
双片段中间带间隙的雕刻法,是一种用于将文件恢复为两个连续片段的方法,其中两个片段之间有一些额外的数据(间隙)。该方法的适用性有限,但它有一个显著的优势,即不需要邻近性函数。您可以仅根据验证函数实现双片段间隙划分。以下图为例,我们有一个文件头。或者,我们有一个文件尾和从文件头计算的文件大小。文件头和文件尾之间的距离为 D,从文件头开始算起的文件大小为 S。
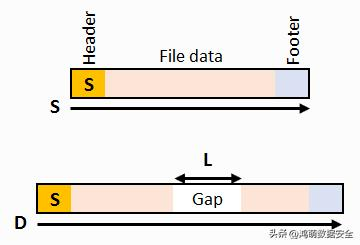
如果没有文件尾,则假定距离 D 为某个合理的常数,足够大,可以容纳尽可能大的间隙和尽可能大的文件(假设 D = L最大 + S最大)。如果 S 已知,则间隙尺寸 L 可以简单地计算为 L = D-S。 然后,我们需要做大约 N -(D-L)/B 个验证测试(针对间隙的每个可能位置),查看哪个能够生成有效文件。这里的 B 是块大小,通常为 512 字节。
如果验证函数不是很好,则可能会有若干正向验证结果。如果发生这种情况,则会生成多个可能的文件供用户选择所需的文件。间隙的第一个和最后一个位置无需测试,因为我们都知道这些两侧的最外延位置是被文件头和文件尾占用的,很显然它们是文件的一部分。
然后,如果 S 未知,我们就无法确定间隙大小,我们必须对每个可能的间隙大小重复测试,其中最大的 Lmax = D-Smin,其中 Smin 是可接受的最小文件大小。Smin通常是通过查看同一相机在相同设置下生成的已知良好文件来猜测的。这大约需要 N-((D-Lmax)/B)*(Lmax/B)此测试。
无法识别文件尾并没有太大影响,只是我们必须在假设一些最大的Dmax值后,执行更多的测试。
在现实世界中,对于典型的 20 MP 图像,每个 CPU 内核每秒可以执行 10 次验证。假设使用多个 CPU 内核系统每秒进行 50 次验证。假设文件大小为 10 MB,这有点偏小,但仍然合理。典型的扇区大小为 512 字节。有时,我们可以从文件系统的剩余部分嗅探文件系统块大小并使用它。 这样就提高了速度。
假设块大小为 512 字节(即没有文件系统集群信息),那么处理单个文件头所需的时间是:
| 参数 | 块大小 B = 512 字节 | ||
| D | 10 MB + 32 KB | 10 MB + 32 KB | Dmax= 16 MB |
| S | 10 兆字节 | 未知 | 未知 |
| L | L = D - S | Lmax = 256 KB | Lmax = 256 KB |
| N | (D-L)/B | (Lmax/B)*(D-Lmax)/B | (Lmax/B)*(Dmax-Lmax)/B |
| ~20,000 | ~10,000,000 | ~16,000,000 | |
| 时间 | ~ 6 分钟 | ~40 小时 | ~70 小时 |
数据块大小为 32 KB(当检测到文件系统集群大小时):
| 参数 | 数据块大小 B = 32 KB | ||
| D | 10 MB + 32 KB | 10 MB + 32 KB | Dmax = 16 MB |
| S | 10 兆字节 | 未知 | 未知 |
| L | L = D - S | Lmax = 256 KB | Lmax = 256 KB |
| N | (D-L)/B | (Lmax/B)*(D-Lmax)/B | (Lmax/B)*(Dmax-Lmax)/B |
| ~320 | ~2500 | ~4000 | |
| 时间 | ~ 6 秒 | ~50 秒 | ~80 秒 |
因此,如果不是所有参数都已知,所需的时间会急剧增加。如果可以通过某种或其他方法确定块大小,则扫描时间与每个块的扇区数成反比,这是相当令人惊讶的。
双片段间隙雕刻的唯一缺点是适用性有限。
复杂的碎片文件雕刻
没有任何已知的最佳算法可以从多个片段中恢复文件。方法有很多,但没有一种是简单或快速的。最简单的方法是将邻近性函数应用于所有可能的块组合,然后合并从最邻近的块开始的块。 这会产生很可能属于不同文件的块链。一个链对应一个文件。实现这一点的另外一种方法是 Parallel Unique Path (PUP) 雕刻算法。不幸的是,所需的计算量与介质上块数的平方成正比,这真的很慢。
复杂的雕刻需要邻近性函数。每种文件格式都需要特定的邻近性函数。邻近性函数的精度与其性能之间存在着微妙的平衡。显然,越复杂的函数速度越慢。较复杂的函数往往会有一些偏差悄悄溜进来。因此,它们与一组图像配合良好,而与另一组图像配合效果不佳。例如,边缘检测在自然风景照片上效果很好,但使用黑白文本扫描时存在问题。因此,必须用场景类型检测来增强它才能获得可接受的结果。