PyTorch学习(1):张量(Tensor)核心操作详解
PyTorch学习(1):张量(Tensor)核心操作详解
一、张量(Tensor)核心操作详解
张量是PyTorch的基础数据结构,类似于NumPy的ndarray,但支持GPU加速和自动微分。
1. 张量创建与基础属性
import torch# 创建张量
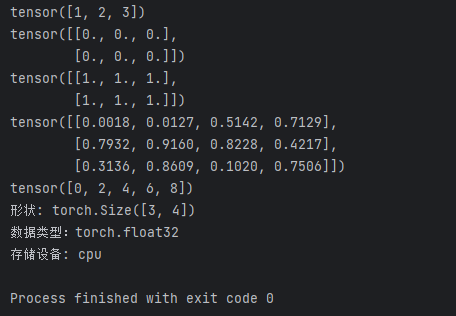
a = torch.tensor([1, 2, 3]) # 从列表中创建
print(a)
b = torch.zeros(2, 3) # 2*3零矩阵
print(b)
c = torch.ones_like(b) # 与b同形的全1矩阵
print(c)
d = torch.rand(3, 4) # 3*4随机矩阵
print(d)
e = torch.arange(0, 10, 2) # [0,2,4,6,8]
print(e)# 关键属性查看
print(f"形状: {d.shape}") # torch.Size([3, 4])
print(f"数据类型:{d.dtype}") # torch.float32
print(f"存储设备: {d.device}") # cpu 或 cuda:0
2. 张量运算与广播机制
x = torch.tensor([[1, 2], [3, 4]])
y = torch.tensor([[5], [6]])
print(x)
print(y)# 基本计算
add =x + y # 广播加法:[[6,7], [9,10]]
mul =x * 2 # 标量乘法:[[2,4], [6,8]]
print(add)
print(mul)# 高级运算
sum_x =torch.sum(x,dim=0) # 沿列求和:[4,6]
max_val,max_idx=torch.max(x,dim=1) # 每行最大值和索引
exp_x =torch.exp(x) # 指数运算
print(sum_x)
print(max_val,max_idx)
print(exp_x)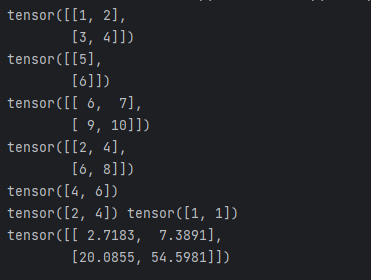
3. 形状操作与内存管理
z = torch.arange(12)
print(z)# 形状变换(不复制数据)
z_view =z.view(3,4) # 视图变形,3*4矩阵
print(z_view)
z_reshape = z.reshape(2,6)
print(z_reshape)# 内部复制
z_clone = z.clone() # 显性复制数据
z_transpone =z_view.T # 转置(共享数据)
print(z_clone)
print(z_transpone)# 维度操作
print(f"原始形状:{z.shape}")
unsqueezed = z.unsqueeze(0) # 增加维度:形状从(12,)变成(1,12)
print(f"增加维度后的形状:{unsqueezed.shape}")
print(unsqueezed)squeezed = unsqueezed.squeeze(0) # 压缩维度:shape(12)
print(f"压缩维度后的形状:{squeezed.shape}")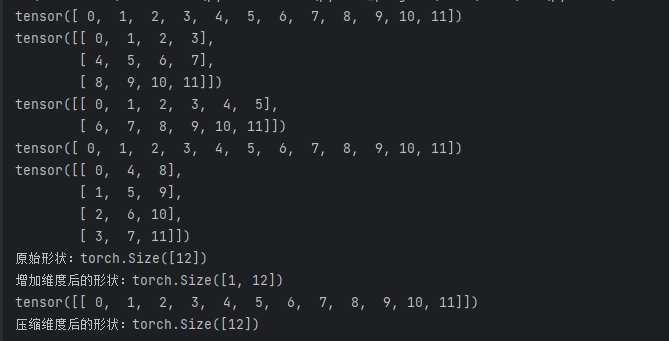
4. 与NumPy互操作
import numpy as np# Tensor → NumPy
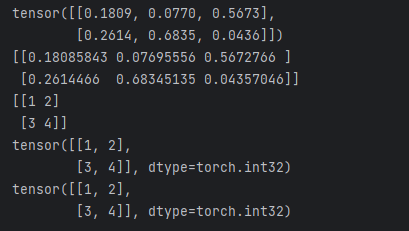
tensor = torch.rand(2,3)
print (tensor)
numpy_array = tensor.numpy() # 共享内存(CPU张量)
print (numpy_array)# NumPy → Tensor
np_arr = np.array([[1,2],[3,4]])
print (np_arr)
new_tensor = torch.from_numpy(np_arr) # 共享内存
print (new_tensor)# 显式内存复制
safe_tensor = torch.tensor(np_arr)
print (safe_tensor)
5、检查设备
# 检测GPU可用性
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
二、动态计算图与自动微分(Autograd)
1. 计算图基本原理
PyTorch使用动态计算图,运算时实时构建计算图,示例1:
# 创建需要跟踪梯度的张量
x = torch.tensor(2.0,requires_grad=True)
print(x)# 定义一个简单的函数 y = x^2
y = x ** 2# 计算 y 关于 x 的梯度
y.backward() # 执行反向传播# 查看梯度值 dy/dx = 2x = 2*2 = 4
print(x.grad) # 输出: tensor(4.)
-
torch.tensor(2.0)
创建一个值为 2.0 的标量张量(即单元素张量),数据类型默认是torch.float32。 -
requires_grad=True
这是一个关键参数,它告诉 PyTorch 需要跟踪这个张量的所有操作,以便之后进行自动求导。设置为True后,PyTorch 会构建一个计算图,记录所有依赖于x的操作,从而在需要时通过反向传播(backpropagation)自动计算梯度。
在这个例子中,由于x的requires_grad=True,PyTorch 记录了y = x²的计算过程,并在调用y.backward()时自动计算了梯度dy/dx,结果存储在x.grad中。
为什么需要这样做?
在深度学习中,梯度是优化模型参数的关键。例如,在神经网络训练时,我们需要计算损失函数对模型参数的梯度,以便使用梯度下降等优化算法更新参数。通过将requires_grad设置为True,PyTorch 会自动记录所有对该张量的操作,从而在调用backward()方法时计算梯度。
这种自动计算梯度的能力是深度学习框架(如 PyTorch、TensorFlow)的核心优势之一,它让我们无需手动推导复杂模型的导数公式,就能高效训练神经网络。
PyTorch使用动态计算图,运算时实时构建计算图,示例2:
# 创建需要跟踪梯度的张量
x = torch.tensor(2.0, requires_grad=True)
# 定义一个函数 y = x**3 + 2*x + 1
y = x**3 + 2*x + 1
# 再进行函数
z = torch.sin(y)z.backward() # 反向传播自动计算梯度print(x.grad) # dz/dx = dz/dy * dy/dx = cos(y)*(3x²+2)
2. 梯度计算模式
这是更灵活的显式梯度计算方式,适用于复杂场景
# 示例:计算偏导数
u = torch.tensor(1.0, requires_grad=True)
v = torch.tensor(2.0, requires_grad=True)
f = u**2 + 3*v# 计算梯度
grads = torch.autograd.grad(f, [u, v]) # (df/du, df/dv)
print(grads) # (tensor(2.), tensor(3.))requires_grad=True告诉 PyTorch 跟踪这些张量的所有操作,以便后续计算梯度。- \(u = 1.0\) 和 \(v = 2.0\) 是初始值,用于计算梯度的具体数值。
定义了一个二元函数 \(f(u, v) = u^2 + 3v\)。在深度学习中,这类似一个损失函数,我们需要计算它对参数的梯度。

核心区别
| 操作 | 用途 | 结果存储 | 适用场景 |
|---|---|---|---|
z.backward() | 计算 z 对所有 requires_grad=True 的叶子节点张量的梯度,并累积到 .grad 属性中。 | 梯度存储在叶子节点的 .grad 属性中。 | 标准的反向传播(如训练神经网络)。 |
torch.autograd.grad(f, [u, v]) | 显式计算 f 对指定张量 [u, v] 的梯度,返回梯度张量组成的元组。 | 梯度作为元组直接返回,不修改原有张量。 | 需要自定义梯度计算路径(如多输出模型) |
3. 梯度控制技巧
import torch
import torch.optim as optim# 初始化参数
x = torch.tensor(2.0, requires_grad=True)
w = torch.tensor(3.0, requires_grad=True)
b = torch.tensor(1.0, requires_grad=True)# 创建优化器
optimizer = optim.SGD([x, w, b], lr=0.01)# 1. 梯度累积清零
optimizer.zero_grad() # 训练循环中必须的操作
print(f"初始梯度 x.grad: {x.grad}") # 输出: None# 前向传播
y = x * w + b
loss = (y - 10)**2 # 假设目标值为10# 反向传播
loss.backward()
print(f"第一次反向传播后 x.grad: {x.grad}") # 输出: tensor(12.)# 再次反向传播(梯度会累积)
loss.backward()
print(f"第二次反向传播后 x.grad: {x.grad}") # 输出: tensor(24.)# 梯度清零
optimizer.zero_grad()
print(f"optimizer.zero_grad() 后 x.grad: {x.grad}") # 输出: tensor(0.)# 2. 冻结梯度
with torch.no_grad():z = x * 2 # 不会追踪计算历史
print(f"z.requires_grad: {z.requires_grad}") # 输出: False# 3. 分离计算图
a = x * w
detached = a.detach() # 创建无梯度关联的副本
print(f"detached.requires_grad: {detached.requires_grad}") # 输出: False# 4. 修改requires_grad
x.requires_grad_(False) # 关闭梯度追踪
print(f"修改后 x.requires_grad: {x.requires_grad}") # 输出: False# 验证修改后的效果
try:y = x ** 2y.backward() # 会报错,因为x.requires_grad=False
except RuntimeError as e:print(f"错误: {e}") # 输出: element 0 of tensors does not require grad and does not have a grad_fn总结对比表
optimizer.zero_grad() # 训练循环中必须的操作
torch.no_grad() # 梯度清零
| 操作 | 作用范围 | 是否影响原张量 | 是否释放内存 | 典型场景 |
|---|---|---|---|---|
optimizer.zero_grad() | 优化器管理的所有参数 | 是(梯度清零) | 否 | 每个训练迭代前 |
torch.no_grad() | 上下文内的所有计算 | 否 | 是 | 推理阶段、无需梯度的计算 |
a.detach() | 单个张量 | 否(创建新张量) | 否 | 截断梯度流、固定部分网络 |
x.requires_grad_(False) | 单个张量 | 是(原地修改) | 否 | 冻结预训练模型参数 |
代码说明:
-
梯度累积清零:
- 两次调用
loss.backward()会累积梯度 optimizer.zero_grad()将梯度重置为零
- 两次调用
-
冻结梯度:
with torch.no_grad()块内的计算不会追踪梯度- 输出张量
z的requires_grad为False
-
分离计算图:
a.detach()创建与计算图分离的新张量- 修改分离后的张量不会影响原梯度计算
-
修改 requires_grad:
x.requires_grad_(False)原地修改张量属性- 后续尝试对
x进行反向传播会报错
注意事项:
- 实际训练中,
optimizer.zero_grad()应在每个训练迭代开始时调用 torch.no_grad()常用于推理阶段以提高性能detach()适用于需要固定部分网络参数的场景- 修改
requires_grad是永久性的,需谨慎操作
4. 梯度检查(调试技巧)
import torch
def grad_check():x = torch.tensor(3.0, requires_grad=True)y = x ** 2# 理论梯度y.backward()analytic_grad = x.grad.item()# 数值梯度(修正:使用 x.item() 而非硬编码 3.0)eps = 1e-5y1 = (x.item() + eps) ** 2y2 = (x.item() - eps) ** 2numeric_grad = (y1 - y2) / (2 * eps)print(f"解析梯度: {analytic_grad:.6f}, 数值梯度: {numeric_grad:.6f}")assert abs(analytic_grad - numeric_grad) < 1e-6# 调用函数
grad_check()这段代码实现了一个简单的 ** 梯度验证(Gradient Check)** 功能,用于验证 PyTorch 自动微分计算的梯度是否与数值计算的梯度一致。
1. 定义测试函数和输入
x = torch.tensor(3.0, requires_grad=True)
y = x ** 2
2. 计算解析梯度(Analytical Gradient)
y.backward()
analytic_grad = x.grad.item()
3. 计算数值梯度(Numerical Gradient)
eps = 1e-5
y1 = (x.item() + eps) ** 2
y2 = (x.item() - eps) ** 2
numeric_grad = (y1 - y2) / (2 * eps)
4. 验证结果
print(f"解析梯度: {analytic_grad:.6f}, 数值梯度: {numeric_grad:.6f}")
assert abs(analytic_grad - numeric_grad) < 1e-6打印结果:解析梯度: 6.000000, 数值梯度: 6.000000

关键知识点
-
自动微分(Autograd): PyTorch 通过跟踪计算图自动计算梯度,无需手动推导公式。
-
数值微分: 数值方法是验证梯度计算正确性的重要工具,但计算效率低,仅用于测试。
-
梯度验证的重要性: 在实现复杂模型(如自定义层或损失函数)时,梯度验证能帮助发现反向传播中的错误。
潜在问题与改进
-
步长 \(\epsilon\) 的选择: 太小会导致数值误差(如浮点数舍入),太大会降低近似精度。
-
多维张量支持: 当前代码仅支持标量输入,扩展到多维张量需为每个元素计算数值梯度。
-
高阶导数验证: 对于二阶或更高阶导数,需使用更复杂的数值方法。
这个简单的验证函数是深度学习开发中的重要调试工具,特别是在实现自定义操作或优化算法时。