论文略读:Surge Phenomenon in Optimal Learning Rate and Batch Size Scaling
2024 Neurips
1 结论
- 使用 SGD 风格的优化器时,最佳学习率为:
- 使用 SGD 风格的优化器时,最佳学习率为
- ε_max,最大学习率
- 模型在训练过程中,仍能保持稳定收敛而不会发散的最大学习率值
- 通常是指在小 batch size 下实验测出来的最大学习率
- 也可以理解为最优学习率的上限值
- B_noise
- 模型在该 batch size 下,训练稳定性发生显著变化的临界点
B ≪ B_noise时,增大 batch size 会显著降低梯度噪声,训练稳定性和效率会显著提升- 当
B ≫ B_noise时,梯度噪声已经很小了,再增大 batch size 其实不会带来显著提升,而是资源浪费
ε_max和B_noise一般都是通过实验测出来的
2 延申结论
- 学习率不应盲目线性放大,需遵循噪声主导 scaling 规律
- 对于 SGD 风格优化器
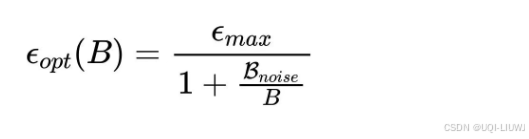
- 小 batch 时梯度噪声大,最大学习率必须小
- 当 B≫Bnoise 时,学习率逐渐逼近 ϵmax,也就是说你不能无限增大学习率
- 但是<Bnoise时,近似于“batch size ×10,学习率 ×10”
- 这是对之前“batch size ×10,学习率 ×10”的 naive scaling 法则的修正
- 对于 Adam 风格优化器:
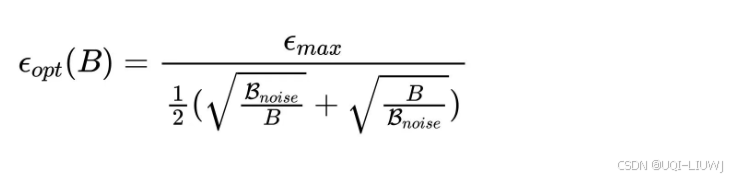
-
是一个更平滑的双向平衡形式;
-
当 B=Bnoise时,分母最小,得到最大有效学习率
- 对于 SGD 风格优化器
-
存在最优 batch size,即 Bnoise
- 无论是哪个优化器,batch size 太小或太大都不是最优的
- 最优学习率和训练效率在 B≈Bnoise时达到最优;
- 超过这个点时,直接线性放大学习率可能会不稳定或低效;