外骨骼驾驶舱HOMIE——3500元让人形机器人1:1复刻人类动作:类似Mobile ALOHA主从臂的主从分离版
前言
本文一开始是属于此文《人形loco-manipulation专题——涵盖Mobile-TeleVision、外骨骼驾驶舱HOMIE、下肢RL-上肢模仿的AMO、上下双智能体联合训练的FALCON》的第二部分
但考虑到
- 在这4个针对loco-manipulation的模型中,我(们)想先尝试一下其中的这个HOMIE
- 加之,HOMIE相对开源的更彻底,更想把其介绍的更详尽细致些
考虑到为了避免对上文篇幅过长的担忧,而使得很多细节 没法尽情展开,故把HOMIE独立出来,成此文
第一部分 HOMIE:具有人形等构外骨骼驾驶舱的本体行走与操作
1.1 引言与相关工作
1.1.1 引言:有点像Mobile ALOHA主从臂的主从分离版
如原论文所说,对于具备泛化能力的人形机器人行走与操作,需要协调的全身控制(WBC)策略,使机器人既具备强大的运动能力,又拥有精确、富于接触的物体操作技能,以便与各种物体进行交互
而远程操作是一项有前景的技术,有望通过数据驱动的方法实现这一愿景,并产生飞轮效应。然而,该领域目前面临着重大挑战
- 强化学习(RL)训练的行走策略在环境适应性方面表现出色,但缺乏实现实时、精确远程操作所需的接口[1,2,3,4,5,6]
- 另一方面,大多数现有的远程操作系统仅关注上半身控制,而未考虑行走对机器人操作工作空间的影响,从而极大地限制了其功能性[7,8,9,10,11]。这种割裂导致了两败俱伤的局面——机器人在移动过程中要么牺牲灵巧操作能力,要么在执行操作时牺牲其工作空间
前进的道路需要相互视角的迭代:
- 基于RL的训练引入了上半身遥操作接口,同时不影响机器人运动能力
- 遥操作系统则无缝集成了行走控制模块,并能实现准确且平滑的姿态获取
对此,作者提出了HOMIE
- 这是一种半自主的人形机器人遥操作系统,集成了用于身体控制的RL策略(通过脚踏板映射)、用于手臂控制的等构外骨骼手臂,以及用于手部控制的动作感应手套
- 其对应的论文为:HOMIE: Humanoid Loco-Manipulation with Isomorphic Exoskeleton Cockpit
其对应的项目地址为:OpenRobotLab/OpenHomie
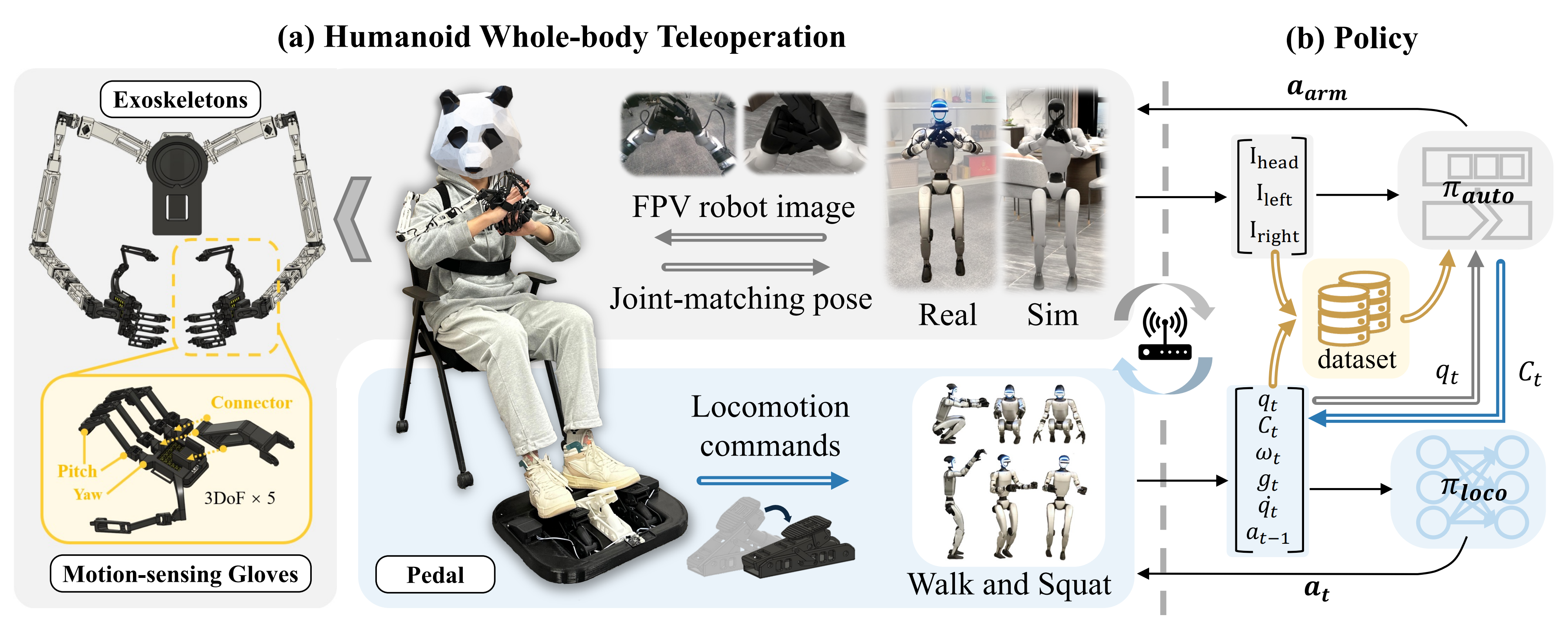
该统一驾驶舱使单一操作员能够精准高效地控制人形机器人的全身动作,解决了人形机器人全身控制与实时精确遥操作的双重需求
总之,他们的基于强化学习的训练框架包含三项核心技术:
- 用于动态平衡适应的上半身姿态课程
- 用于精确下蹲的高度跟踪奖励
- 以及用于动作正则化和数据增强的对称性利用
这些组件共同提升了机器人的物理灵活性,使其能够实现稳健行走、快速下蹲至任意所需高度,并在动态上半身运动过程中保持稳定平衡,从而显著扩展了机器人的操作工作空间,超越了现有解决方案,并允许任何远程操作指令生效
- 且与以往依赖于从MoCap数据[12]获得的运动先验的全身控制方法不同,他们的框架消除了这一依赖,从而实现了更高效的流程
- 此外,为了配合训练框架,他们的硬件系统配备了同构外骨骼手臂、一对运动感应手套和一个踏板。踏板设计作为行走指令获取的有效接口,引导机器人的移动,同时解放操作员的上半身。该设置能够同时获取上半身姿态,并消除了操作员与机器人之间持续同步行走的需求
- 且为了解决主流远程操作系统中常用的逆向运动学(IK)和姿态估计带来的不准确性,他们将外骨骼手臂设计为与被控机器人同构。这使得能够根据外骨骼的读数直接设定上半身关节位置,无需IK,从而实现更快、更准确的远程操作
另,每只手套都提供了15个自由度(DoF),超过了大多数现有灵巧手,使其能够使用同一副手套控制多种类型的机械手
且手套可以从手臂上拆卸下来,使其在同构系统中可用于不同的机器人以重复利用,该硬件系统的总成本仅为0.5千美元,显著低于动作捕捉(MoCap)设备的价格[13]
最后,作者通过消融实验,验证了训练框架中每项技术的有效性,并展示了所生成策略在不同机器人上的鲁棒性
- 评估表明,该硬件系统的姿态获取速度比以往方法快200%,且精度更高,使操作员能够比基于虚拟现实(VR)的方法更高效地完成任务。真实环境研究证实,训练得到的策略可以直接部署到现实世界中,使机器人能够在复杂环境下稳定地执行多样化的行走-操作任务
- 进一步展示,通过HOMIE收集的真实世界数据能够被模仿学习(IL)算法有效利用,使人形机器人能够自主执行任务。集成到仿真环境后,驾驶舱还支持在虚拟环境中的无缝远程操控
1.1.2 相关工作
第一,摇操作系统
远程操作双臂机器人以执行复杂操作任务是一种高效收集真实世界专家示范的方法,这些示范随后可被模仿学习(IL)用于学习自主技能[14-Mobile aloha,7-Open-television,9-iDP3,17-π0,18-Learning visuotactile skills with two multifingered hands]
- 一些研究人员使用与远程操作机器人臂完全相同的机械臂——说白了 就是主从臂
[19-ALOHA ACT,
14-Mobile aloha,
15-Gello,
16-Airexo]
从而实现关节匹配,确保高精度和快速响应
然而,由于机械臂成本高昂,建立此类系统会带来显著的开支
此外,利用这些系统远程操作灵巧手也是不可行的 - 另一种方法是使用VR设备
[7-Open-television
11-Open teach: A versatile teleoperation system for robotic manipulation]
或仅使用摄像头
[20-Robotic Telekinesis: Learning a Robotic Hand Imitator by Watching Humans on YouTube,
10-Anyteleop: A general vision-based dexterous robot arm-hand teleoperation system,
21-Okami: Teaching humanoid robots manipulation skills through single video imitation]
这些工作采用基于视觉的技术来捕捉人类操作员的手腕姿态和手部关键点,IK(逆运动学)利用这些信息计算手臂和手的关节位置
然而,由于姿态估计在精度、推理速度以及处理遮挡方面的局限性,这类方法无法保证快速且准确地获取姿态 - 还有一些研究人员尝试使用MoCap方法
[13-Dexcap
22-A systematic review of commercial smart gloves: Current status and applications
23-Highfidelity grasping in virtual reality using a glove-based system
24-A glove-based system for studying hand-object manipulation via joint pose and force sensing]
以更高的频率获取更准确的姿态
但MoCap设备非常昂贵
此外,由于IK是一种近似求解的迭代方法,即使手腕和手的姿态被准确捕捉,IK的局限性也可能导致机器人无法实现期望的姿态 - 另一种可行的解决方案是基于外骨骼的遥操作系统,该系统不需要额外的同型机器人,因此整体成本相对较低
一些研究通过正向运动学(FK)计算外骨骼末端执行器的位姿,然后应用逆向运动学(IK)确定机器人的关节位置,同时利用计算机视觉技术捕捉手部姿态[8-Ace: A cross-platform visual-exoskeletons system for low-cost dexterous teleoperation]
然而,这些系统同样受限于IK和姿态估计的不准确性
一些研究利用同构外骨骼
[15-Gello
16-Airexo: Low-cost exoskeletons for learning wholearm manipulation in the wild]
同样可以通过关节匹配实现机器人远程操作,从而保证低成本、高精度和高控制频率
然而,这些系统通常只操作配备有夹爪的机械臂,因此其应用范围仅限于基本操作任务,而无法完成灵巧操作
由于部分项目引入了廉价且可靠的运动感应手套
[25-Project-homunculus. https://github.com/nepyope/Project-Homunculus
26-icub3 avatar system: Enabling remote fully immersive embodiment of humanoid robots]
将其与外骨骼重新设计并结合,有望克服这一限制,而这一方案在该领域尚未实现
而HOMIE的设计旨在融合上述所有优势,将同构外骨骼手臂与一对新型运动感应手套集成。HOMIE与以往典型远程操作系统的对比见Tab.I
第二,全身运动-操作
为了使机器人能够执行全身运动-操作任务
- 一些研究者专注于基于模型的优化算法
27-Dynamic walk of a biped
28-Optimization-based control for dynamic legged robots
29-Whole-body control of humanoid robots
30-Whole-body humanoid robot locomotion with human reference
31- The mit humanoid robot: Design, motion planning, and control for acrobatic behaviors
特别是通过求解最优控制问题(OCPs)来生成运动控制律。尽管在提升OCP的计算可行性方面做出了大量努力,这些算法在在线处理过程中由于高计算需求,仍然难以应对复杂场景 - 基于强化学习RL的算法,尤其是基于近端策略优化(PPO)[32]的方法,提供了更为强大的替代方案
利用这些方法,多项研究成功实现了四足机器人全身行走与操作(loco-manipulation)
33-Visual whole-body control for legged loco-manipulation
34-Roboduet: A framework affording mobilemanipulation and cross-embodiment
35- Whole-body end-effector pose tracking
36-Umi on legs: Making manipulation policies mobile with manipulation-centric whole-body controllers
并有部分工作教会了仿人机器人穿越各种地形
37- Advancing humanoid locomotion: Mastering challenging terrains with denoising world model learning
38-Learning humanoid locomotion with perceptive internal model
39- Learning smooth humanoid locomotion through lipschitz-constrained policies
40- Learning multi-modal wholebody control for real-world humanoid robots
41- Reinforcement learning for versatile, dynamic, and robust bipedal locomotion control
42- Reinforcement learning for robust parameterized locomotion control of bipedal robots
43- Berkeley humanoid: A research platform for learning-based control
44- Wococo: Learning whole-body humanoid control with sequential contacts
或进行跑酷
45- Humanoid parkour learning
四足机器人领域的成果激励研究者将相同技术应用于仿人机器人全身行走与操作
46-Humanoid locomotion and manipulation: Current progress and challenges in control, planning, and learning
部分研究为仿人机器人训练了全身策略[5-Exbody2],使其能够以类似人类操作者的方式行动,甚至与人共舞 - 另一些研究则将上半身和下半身分开处理
4-Expressive wholebody control for humanoid robots,即Exbody
1-Humanplus
2-H2O,Learning humanto-humanoid real-time whole-body teleoperation
3-Omnih2o
6-Mobile-television
利用强化学习RL训练的策略控制下半身,而直接设置上半身的关节位置,从而帮助机器人实现更好的平衡。尽管取得了显著成果,这些方法仍然面临若干共同的局限
首先,它们通常依赖重定向的动作捕捉(MoCap)数据[12-AMASS]获取运动先验[47-Universal humanoid motion representations for physics-based control]用于机器人训练
然而,获取MoCap数据成本高昂,且机器人适应新姿态时需要额外采集数据,这极大地限制了这些方法的可扩展性
4-Exbody
1-Humanplus
2-H2O
3-Omnih2o
而另一些则使用摇杆或踏板[6-Mobile-television]
前者(摇杆)在操作者需要在大规模环境中控制机器人时变得不可行,而后者(踏板)则提供了更有效的解决方案。然而,使用摇杆控制需要双手操作,而双手可能已经被其他任务占用,这凸显了使用踏板下达行走指令的优势
1.2 HOMIE的完整方法论
1.2.1 系统概述
如图2 所示,HOMIE 由一个低层策略 和一个基于外骨骼的硬件系统组成。在任意时刻
,机器人的第一视角(FPV)会通过Wi-Fi 传输到驾驶舱内的显示器上,因此操作员可以通过FPV 远程操控机器人
- 通过踩踏板,操作员提供所需的运动指令
,其中
是期望的前进或后退速度
是转向速度
是机器人躯干的目标高度
策略 根据
控制机器人的下半身
- 同时,操作员通过控制外骨骼为机器人的上半身提供所需的关节角度
,这些角度会直接设置到机器人上
此后,上下半身协同工作,持续循环这一过程,最终实现远程操控机器人在现实世界或仿真环境中完成运动-操作任务 - 驾驶舱与机器人之间通过Wi-Fi 实现通信,即使机器人远离硬件系统也能进行操作
从而可以在远程操控机器人时收集演示数据,并利用这些数据训练自主策略 。一旦训练成功,
1.2.2 人形全身控制
为了使人形机器人能够执行行走-操作任务,作者设计了一个基于强化学习的训练框架,该框架训练不同的机器人在上半身姿态持续变化的情况下完成下蹲和行走
以Unitree G1 为例,并在图3 中展示了该框架的流程。通过该过程训练得到的策略 能够实现零样本的sim-to-real迁移
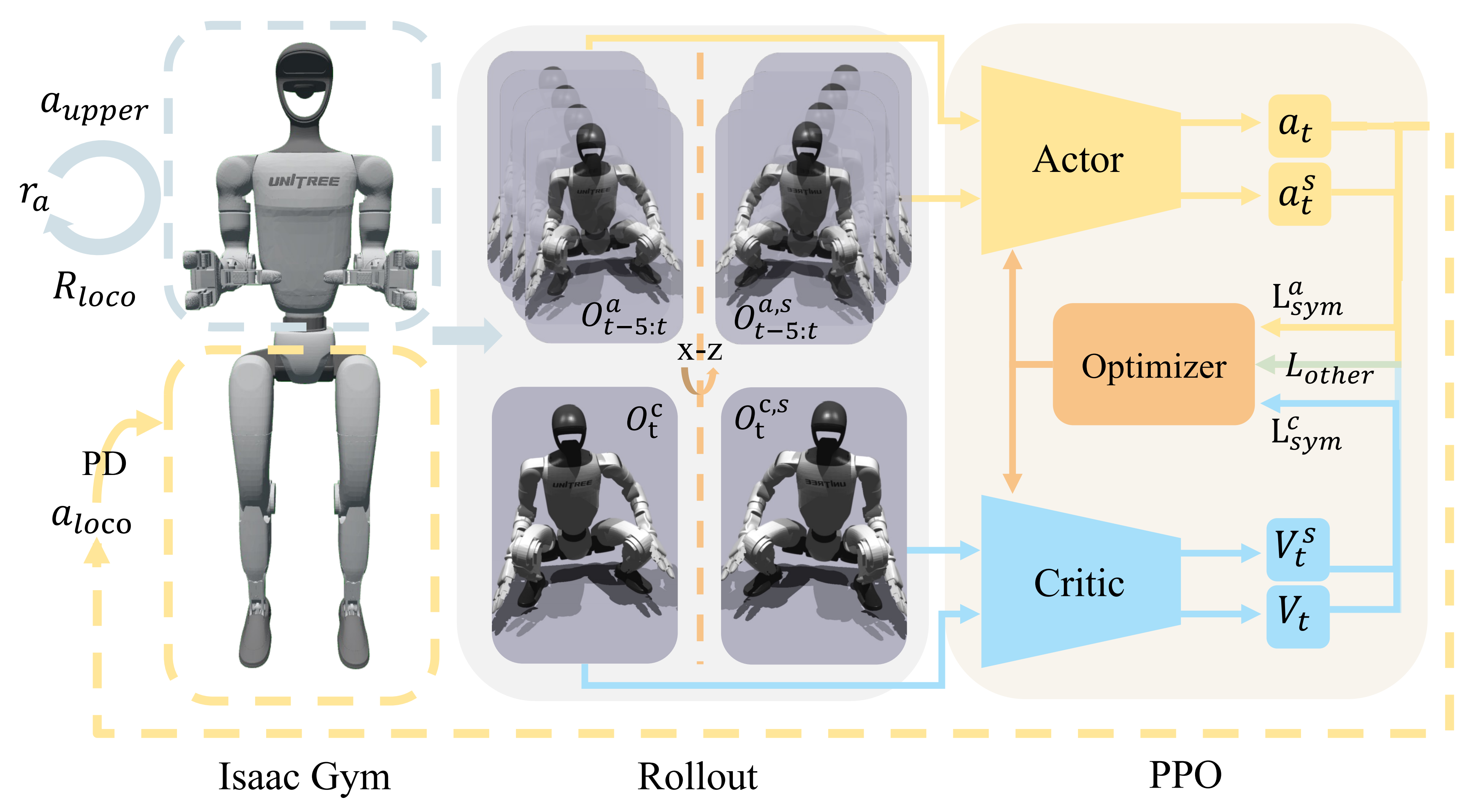
- 训练设置
一步的观测被定义为,其中
为身体的角速度
为
在机器人躯干坐标系下的投影
为机器人所有关节的关节角
为机器人所有关节的关节速度
为上一次的动作
然后通过拼接获得
策略的动作 与机器人下半身的关节一一对应
在神经网络基于
- 上半身姿态课程
作者采用课程学习技术,以确保
比如通过上半身动作比例 来调整上半身关节角度的采样范围
在训练开始时, 被设置为0
每当策略驱动机器人通过奖励函数跟踪线速度并达到阈值时,
作者首先从概率分布中采样
然后重新采样,服从,实际上是对
进行采样,如下述公式3所示
随着。这确保了在课程过程期间,概率分布始终满足
与直接使用相比,这种方法以更加渐进和平滑的方式接近最终目标
为了更好地理解上述公式(3),作者在原论文的附录A 中对其进行了可视化
且为了模拟在驾驶舱控制下上半身动作的连续变化,作者按照上述过程每1 秒重新采样一次目标上半身姿态
随后,作者采用均匀插值,确保目标动作在1 秒的时间间隔内从当前值逐渐变化到期望值。如果不采用这种方法,他们发现机器人在持续运动下难以保持平衡 - 高度跟踪奖励
跟踪高度可以显著扩展人形机器人可行的操作工作空间,从而帮助机器人执行更多的行走-操作任务。因此,
为此,作者设计了一个新的奖励函数,如下公式4所示
其中,表示机器人的实际高度,
和
分别为膝关节的最大和最小动作,
为机器人膝关节的当前位置
时,
鼓励膝关节屈曲
时,
在训练过程中,作者每4 秒重新采样所有指令。此时,随机选择三分之一的环境来训练机器人下蹲,而其余三分之二则专注于教机器人站立和行走
这一策略有助于平衡下蹲和行走的学习。此外,同一环境会在学习下蹲和学习行走之间切换,使得策略能够在下蹲与行走任务之间平滑过渡
为了更好地理解上面的公式(4),作者在附录A 中对其进行了可视化 - 对称性利用
作者在训练框架中引入了与[50] 相同的技巧。每次从仿真中获得一个转移时,作者都会对其进行一次翻转操作
具体而言,作者针对机器人的 平面对actor 和critic 的观测数据应用对称操作
这包括将机器人左右关节的位置、速度和动作,以及期望的转向速度等元素,沿
随后,和
在学习阶段,作者同样对从rollout 存储中获得的样本,这些将用于计算额外的损失
这两个损失项被加入到网络优化过程中,从而强制神经网络的对称性
1.2.3 硬件系统设计:同构外骨骼手臂、动作感应手套、脚踏板
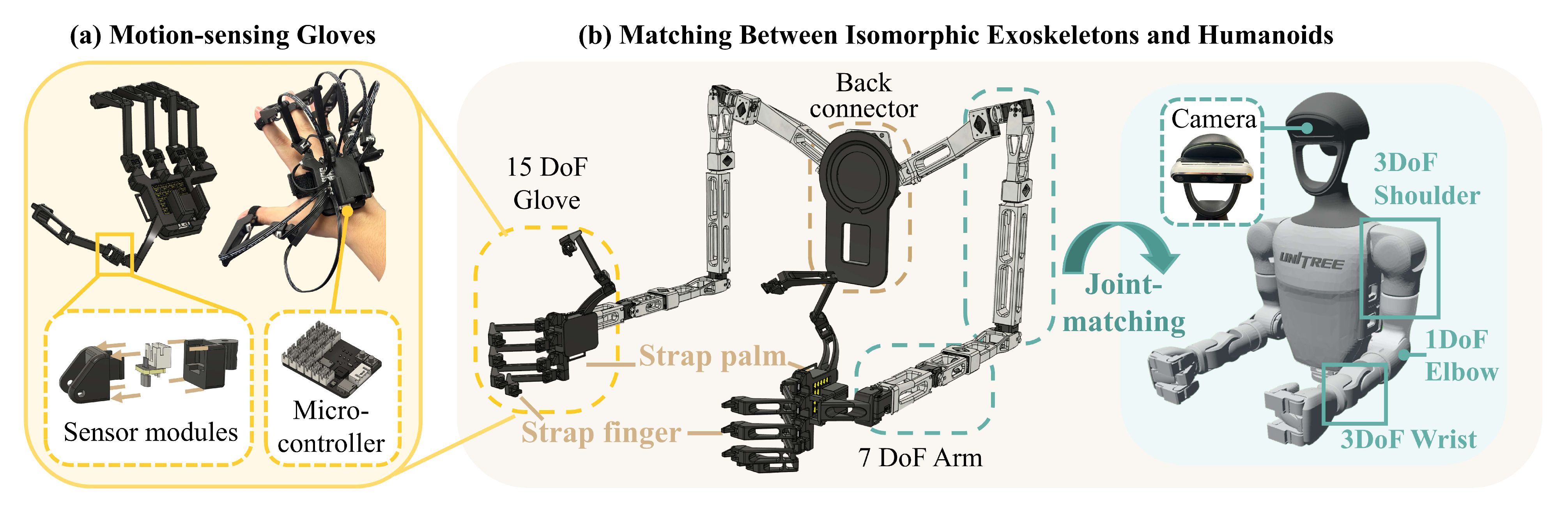
为了使单个操作员能够控制人形机器人的全身,我们设计了一套低成本的基于外骨骼的硬件系统,如图2左侧所示
- 针对人形机器人上半身的遥操作,作者设计了3D打印的7自由度同构外骨骼手臂,用于精确映射上肢关节角度,专门适配于两种类型的人形机器人:Unitree G1和Fourier GR-1
- 此外,作者还设计了一对低成本的动作感应手套,能够映射多达15个自由度的手指角度
- 为获取行走指令,又设计了一个脚踏板,能够模拟驾驶过程中脚的踩踏与释放动作,从而实现对人形机器人行走、下蹲等运动的控制
操作员可以轻松部署该系统,并实现对机器人行走-操作的单人遥操作,类似于在驾驶舱驾驶汽车或玩赛车游戏
具体而言,以下分别阐述
第一,对于同构外骨骼
为了实现对仿人机器人上肢关节的精确控制与映射,作者采用同构外骨骼作为机器人上半身的遥操作解决方案。基于Unitree G1 和Fourier GR-1 的形态,他们的同构外骨骼设计由一对对称的手臂组成,每个手臂具有7DoF,对应于机器人每个手臂的7DoF(肩部3 自由度,肘部1 自由度,腕部3 自由度),如图5(b) 所示
- 外骨骼的每个关节均配备了DYNAMIXEL XL330-M288-T舵机,能够以0.09◦的精度进行关节角度读取和调节,实现精确的关节角度映射与初始校准
与增量编码器相比,舵机可以存储绝对位置,即使断电后也能保留当前位置数据,从而避免了重新启动时的重新校准 - 外骨骼的操作部分被设计为与人体手臂长度相匹配。考虑到完全复现机器人上臂结构的难度,作者将舵机与机器人的电机URDF 关节坐标系对齐
且可以获得舵机位置角与机器人关节角
。由于Dynamixel 舵机能够存储绝对位置,
此外,舵机盘上有四个对称的孔,使得的整数倍
- 另,使用
为了实现运动学等效性和标定,其中偏移量遵循,
,
是一个用于调整角度变化方向和尺度的系数,
是额外的关节角度补偿
作者设定且
,这意味着不需要额外的缩放或角度补偿
第二,对于运动感应手套
为了实现手指的精细远程操作,作者采用了关节匹配的方法。基于Nepyone手套项目[25],作者设计了一款低成本的运动感应手套,可直接连接至外骨骼进行组装和使用,且能够为手指捕捉提供多达 15 个自由度——以控制灵巧的手
- 具体而言,每根手指都配备了三组传感器,可映射指尖和指腹的俯仰运动,以及指腹的偏航运动。这一配置足以实现不同仿人机器人灵巧手的映射
- 作者在每个关节处放置霍尔效应传感器和小型钕磁铁。当关节旋转时,钕磁铁也随之旋转,从而影响传感器感知到的磁场,实现手指关节角度的映射
- 此外,还设计了手套的微控制器、传感器模块和结构模型。微控制器安装在手背上,可通过端子连接器直接与封装好的传感器连接,便于插拔以重新分配和修改映射关系,如图5(a)所示
且该运动感应手套可以方便地安装和拆卸到不同的外骨骼上,具有很高的通用性
第三,脚踏板
在他们的驾驶舱中,脚踏板用作遥控器的替代品,通过向发送指令,实现对人形机器人下半身的命令控制。操作员通过踩下和松开脚踏板来控制机器人下半身运动的加速和减速
- 且他们使用高精度旋转电位器将踏板压力变化映射为电信号。在他们的系统中,通过线速度、偏航速度和高度调节来控制人形机器人的行走。这些指令使机器人能够充分展示其运动能力。为此,他们使用三个小型踏板来控制这些指令
- 此外,一对模式切换按钮(脚操作,带瞬时开关)用于在前进/后退和左/右转向之间切换,如图6所示

用户可以修改踏板配置并重新分配指令,以适应多样化的运动组合
1.3 实验
1.3.1 仿人全身控制
第一,对于训练框架消融
- 在本节中,作者对所提出的上半身姿态课程、高度跟踪奖励以及对称性的使用进行了消融实验。所有消融实验均基于上文的『2.2.2 人形全身控制』(对应于原论文的第III-B 节)中描述的方法进行
- 对于每种设置,作者使用三个随机种子为Unitree G1 训练策略,并在1000 个环境中进行评估,评估周期为20 秒,期间从公式(3) 中以
随机采样上半身姿态
- 评估指标包括线速度跟踪误差、角速度跟踪误差、高度跟踪误差、对称性损失和存活时间。每种设置的最终性能通过计算三个随机种子训练出的三组策略结果的平均值和标准差获得。所有训练均在Nvidia RTX 4090 上进行,并由Isaac Gym以4096 并行模拟
与消融无关的组件保持不变,仅对相关部分进行训练修改。训练和评估过程中使用的详细参数列于附录A
首先,对于上半身姿态课程
作者将作者的方法与两种替代方案进行比较:
- 作者的方法
- w/o cur,即省略课程,直接采样
w/o cur, which omits the curriculum anddirectly samples ai = U(0, U(0, 1)) - 以及rand,其使用相同的ρa 课程,但将公式(3)
替换为
which uses the same ρa curriculum but replaces Eq. (3) with ai =U(0, U(0, ρa))
由于这三种方法在时都采用相同的采样策略
,最终目标保持一致,确保了公平的比较
实验结果如图7 第一行所示
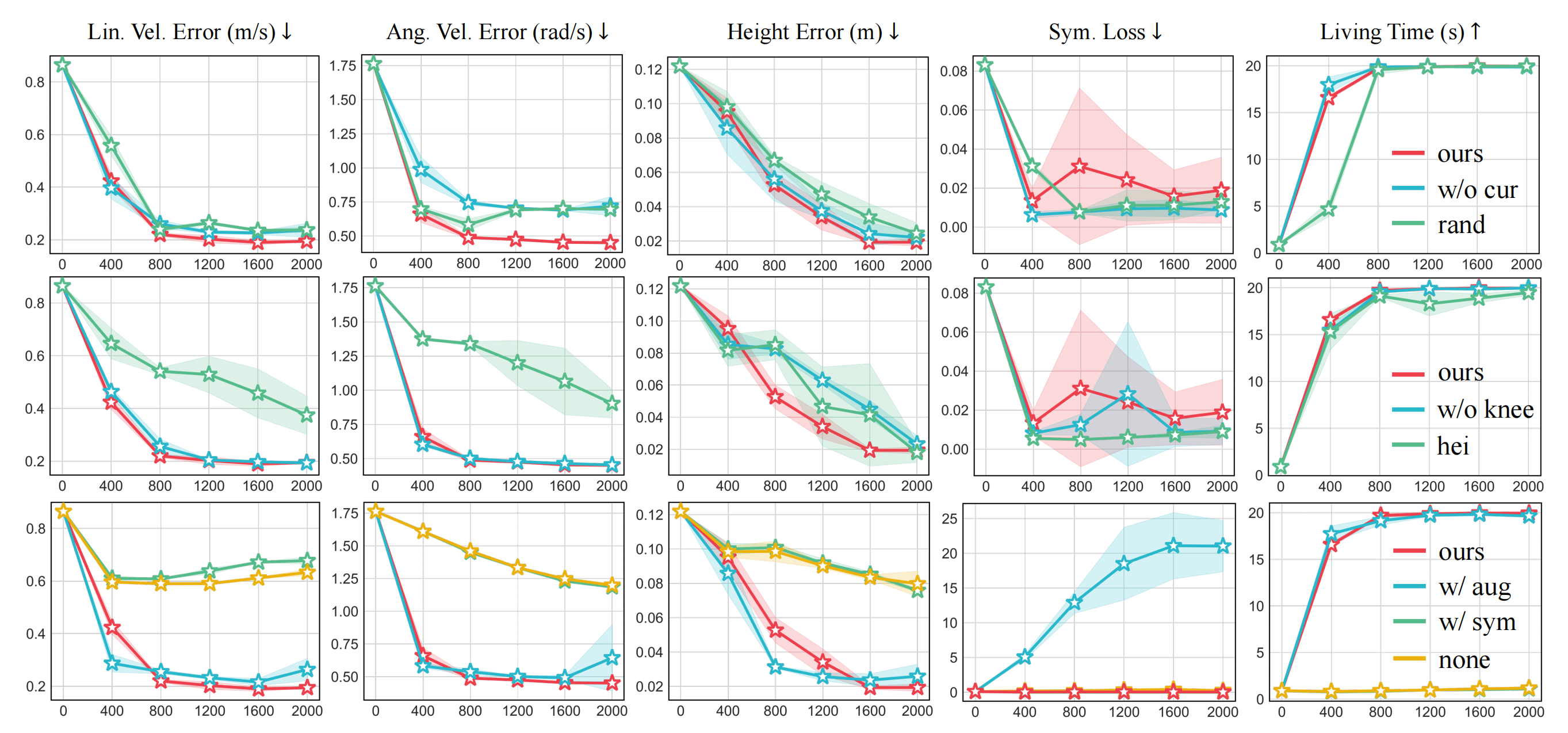
- 表明他们的方法在线速度追踪、角速度追踪和高度误差方面均优于w/o cur 和rand,具有更快的收敛速度和更小的误差
shown in the first row of Fig. 7, reveal that ours outperforms both w/o cur and rand in linear velocity tracking, angular velocity tracking, and height error, withfaster convergence and smaller errors.
在这些指标的最终结果上,w/o cur 和rand 之间没有显著差异
鉴于对称性损失(symmetry loss)在无约束情况下可以达到20 量级,在三种方法的对称性损失方面也未观察到显著差异
三种配置最终的生存时间相近,但他们的方法和w/o cur 收敛更快。尽管rand 采用了一些课程调整,但受到内的值,随着
相比之下,他们的方法和w/o cur 从一开始就采样整个[0, 1] 区间,实现了更快且更稳定的收敛。因此,作者认为,他们的课程(curriculum)方法相比rand表现更优。尽管w/o cur 未使用课程,使得能够持续从
,但缺乏难度平滑会导致最终的跟踪结果变差,这突显了他们的课程设计能够提供更有效的训练过程
其次,高度跟踪奖励
作者设计了两种额外的算法:
- w/o knee(不使用公式(4)中描述的
- 和hei『同样省略
在下图图7的第二行展示了结果。如图所示,这三种设置在训练过程中对对称性损失都没有显著影响
- 在线速度误差和角速度误差方面,ours和w/o knee表现相似,而hei的误差则大得多
在高度误差方面,作者的方法比w/o knee和hei收敛更快,尽管hei在初始阶段(400步时)表现更好 - 在存活时间方面,三种设置之间没有显著差异
这些结果表明,仅仅在hei中放大高度跟踪奖励虽然初期能更快减少高度跟踪误差,但会对其他奖励的反馈产生负面影响,导致机器人无法有效平衡多任务。实际上,hei最终在高度跟踪上的收敛速度并不比ours更快
相比之下,作者方法中引入为深蹲跟踪提供了更具体的指导,使机器人能够更快减少跟踪误差并实现更快收敛。这突显了
在帮助机器人学习深蹲动作方面的有效性
再其次,对于对称性利用
作者引入了三种算法变体
- 与ours在对称性利用方面进行比较:w/ aug (仅使用对称数据增强)
- w/ sym (仅使用对称性损失)
- 以及none (不使用对称数据增强或对称性损失)
测试结果如图7第三行所示
- 除了对称性损失外,ours和w/aug的性能相似,但整体跟踪精度上ours略优
- 另一方面,w/ aug表现出非常高的对称性损失,表明采用对称性损失有助于在学习到的策略中保持机器人的左右对称性,这间接支持了对称策略有利于机器人行走任务的观点[50]。nsym和none都显示出改进的趋势,但训练速度明显较慢
- 值得注意的是,w/ sym和none的直接比较表明w/ sym获得了更低的对称性损失
然而,由于训练速度较慢,none相比w/ aug表现出更少的对称性破坏
综上所述,对称性数据增强显著提升了训练效率,而对称性损失的使用则有效防止策略为完成任务而牺牲对称性,同时也有利于任务本身
第二,对于在不同机器人上的训练
作者选择了另一种类型的机器人 Fourier GR-1,该机器人与 Unitree G1 有很大不同,以展示他们方法在不同机器人模型间的通用性
如图8所示

- Fourier GR-1 比 Unitree G1 高得多且更重,同时其手部重量比更低。与 Unitree G1的训练设置相比,作者仅更改了高度跟踪范围和一些机器人特定的距离数值,奖励权重和训练流程未做其他任何更改
且在训练2k步后对策略进行了评估——使用Sec.IV-A1中的度量标准对每个机器人进行评估,并将结果展示在表II中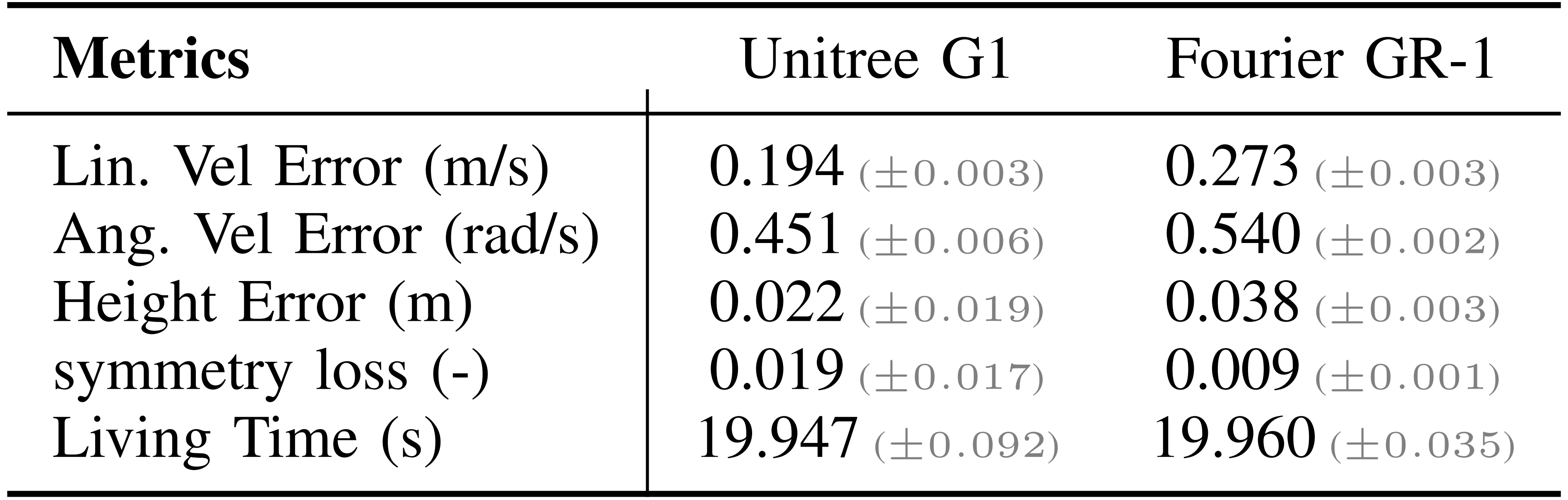
- 结果表明,尽管这两类机器人差异较大,作者的强化学习训练框架仍能将它们训练至收敛于能够驱动机器人在任意上半身姿态下,稳健地完成行走和下蹲任务的策略
Fourier GR-1的训练细节见附录A
1.3.2 遥操作硬件性能:可由操作员控制做各类动作
作者在表III中列出了远程操作硬件系统的一系列硬件指标,该系统由同构外骨骼手臂、一对运动感应外骨骼手套和一个踏板组成
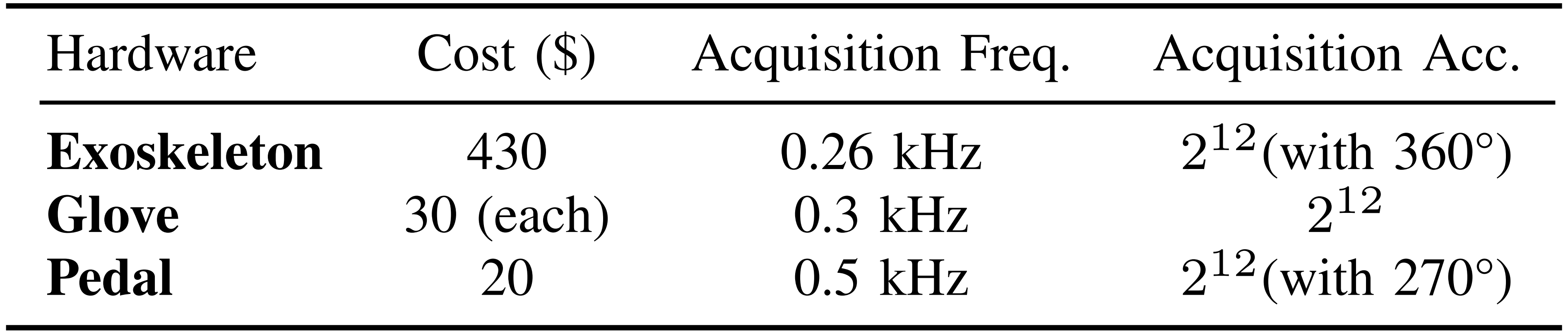
- 其中主要费用归因于外骨骼部分。这是因为作者为运动感应手套和踏板组件独立设计并焊接了控制板(PCB)和传感器模块
采集频率表示通过有线连接以115200波特率在远程操作系统的硬件组件与主机之间测得的更新信号频率。更改波特率会影响采集频率
采集精度表示角度变化范围(以度为单位)及其对应的采集读数变化,范围为0到4095(2¹²)
由于运动感应手套的映射关系并不是明确定义的线性关系,且每个手指关节的映射角度各不相同,更详细的信息可参见附录B-B - 对于上半身远程操作,任务可分为两部分:手臂控制和灵巧手控制。作者选择手臂姿态频率和手部姿态频率作为评估指标,该指标用于衡量遥操作的平滑性和流畅性
在下表表 IV中,作者将视觉/VR 方案与「作者他们的关节匹配方案」进行了比较因此,作者的方法无需依赖 GPU 和系统级芯片(SoC)等高性能硬件,即可实现极高的输出频率
由于作者的关节匹配方案可以直接设置机器人的上半身姿态,无需额外耗时的处理,因此输出到机器人的频率与采集频率高度一致
- 为了进一步展示作者运动感知手套的可扩展性,作者在 SAPIEN [51] 环境下,利用 AnyTeleop[10] 中的 Dex Retargeting 库,测试了不同类型的灵巧手
结果如下图图 9 所示,上方显示被测试的灵巧手名称,下方则表示每只手的关节数量
1.3.3 遥操作系统
1.3.3.1 现实世界
- 作者在现实世界中将训练好的策略部署在Unitree G1上,并通过同构外骨骼硬件系统进行远程操作,使其执行各种行走-操作任务
且采用WiFi实现驾驶舱与机器人之间的通信。由于他们的系统每个数据包仅需128字节(32位浮点数),在正常网络条件下,测得的通信延迟为16毫秒——这一结果被认为可接受于实时控制
此外,作者还实现了包括校验和验证在内的网络技术,以确保数据传输的完整性。G1的部署代码源自[52] - 图1 (a)
图1 (c) 展示了机器人能够下蹲、从较低的货架上取物并放置到较高的货架上,以及利用其行走能力在货架之间抓取和搬运箱子
图1 (b) 突出了他们系统的可扩展性,使两名操作员能够分别控制不同的机器人并协作完成任务,如转移苹果
在图1 (d) 中,机器人被控制推动一位坐在椅子上的60 kg 的人,其体重大约是机器人的两倍,展示了本地操控系统的强健性
图1 (e) 展示了机器人如何利用其本地操控能力,通过抓住把手并同时向后移动来打开烤箱
图1 (f) 显示他们的远程操作系统能够完成双手协作任务,如一只手将物体递给另一只手
图1 (g) 展示了机器人从低处地面抓取物体的能力
而图1 (h) 展示了机器人能够用双臂将重物(如一捆花)举起并放入箱中
图1 (i) 展示了机器人如何在不同上半身姿态下保持平衡

- 在以上所有的这些任务中,每个机器人都由一名操作员控制,机器人与操作员之间的通信通过Wi-Fi 实现,不限制机器人的运动空间。这些任务展示了他们本地操控策略的强健性以及HOMIE 远程操作仿人机器人在各种环境下执行多种复杂任务的能力
作者为了进一步展示他们远程操作系统的效率,他们将他们的硬件系统与基于 VR 的方法 OpenTelevision [7] 在任务完成时间上进行了对比,涵盖如图10所示的总计四项任务。这些任务旨在评估系统在不同场景下对机器人手臂和手部的精确控制能力:
- 抓取与放置:机器人需从桌上抓取一个番茄并将其放入水果篮
- 扫码:机器人必须握持扫描仪,用手指按下其按钮,并扫描盒子上的条形码

- 传递:机器人需抓住一个番茄并递给另一只手
- 开烤箱:机器人必须将手指插入把手并打开烤箱门
这些任务考察了远程操作的关键能力,包括精确定位、双手协调和细致的手指控制。图11中的结果表明,他们的系统完成任务的时间几乎是基于VR方法的一半
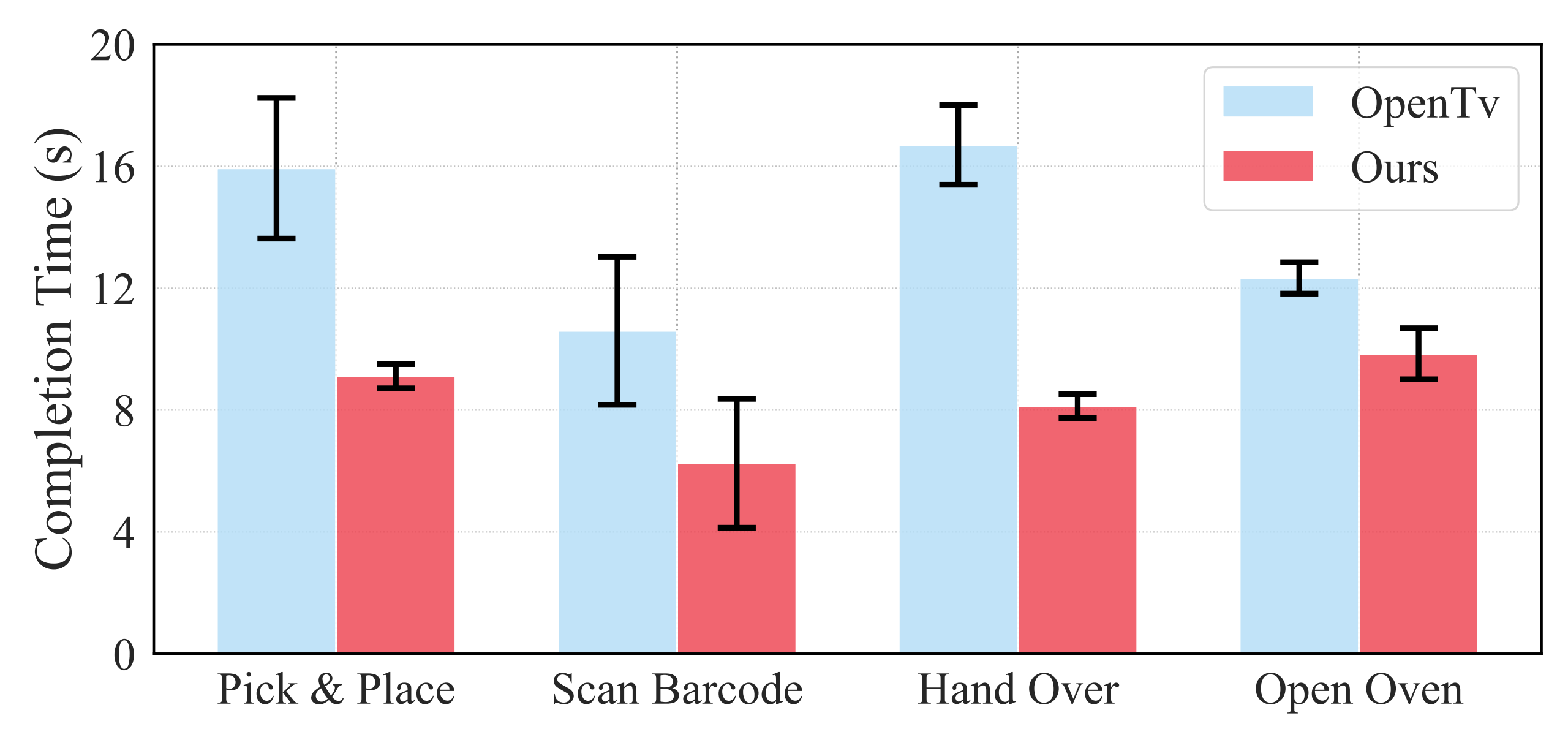
值得注意的是,当任务需要精确的定位和姿态时,他们系统与VR方法之间的性能差距更加明显。这是因为基于VR的姿态估计在切向方向上的表现往往较差,而他们的外骨骼方法则完全避免了此类问题
这些结果表明,作者的外骨骼系统使操作者能够更顺畅、高效地远程操作机器人,尤其是在需要高精度和灵巧性的任务中
1.3.3.2 仿真
为 Unitree G1 和 Fourier GR-1训练的策略从 Isaac Gym 转移到由 GRUtopia[54] 开发的场景中,该场景基于 Isaac Sim 和Isaac Lab [55]。这种迁移使得可以利用 HOMIE在各种仿真环境中控制机器人
通过利用这些仿真场景,机器人能够以更低的成本,在比现实世界更广泛的情景下执行多样化的行走-操作任务
如图 13 所示「下图上排展示了操作员如何通过第一人称视角(FPV)控制机器人执行行走-操作任务。下排展示了机器人在逼真的仿真环境中导航」

操作员可以在复杂且逼真的环境中无缝地引导机器人的移动和动作,展示了HOMIE 在多种仿真场景下的多功能性和适用性
1.3.4 自主策略
- 数据收集:为了验证HOMIE 为IL 算法收集的示范数据的有效性,作者设计了两个不同的任务:
采集RGB 图像、机器人状态qt、上半身指令qupper 以及运动指令Ct,采样频率为10Hz,每个任务收集50 个回合
用于图像采集的硬件设置见图14 - 训练设置:作者采用端到端的视觉运动控制策略,该策略以图像和机器人本体感知信号为输入,并持续输出机器人控制动作
且采用名为Seer[56]的模型,其特点是自回归Transformer架构。多视角图像通过MAE预训练的ViT编码器进行处理,机器人的本体感知状态特征则通过MLP提取。这些特征随后被拼接为token。这些标记的信息随后由一个transformer编码器进行整合。该transformer编码器利用自回归方法生成用于控制上层的潜在编码
// 待更