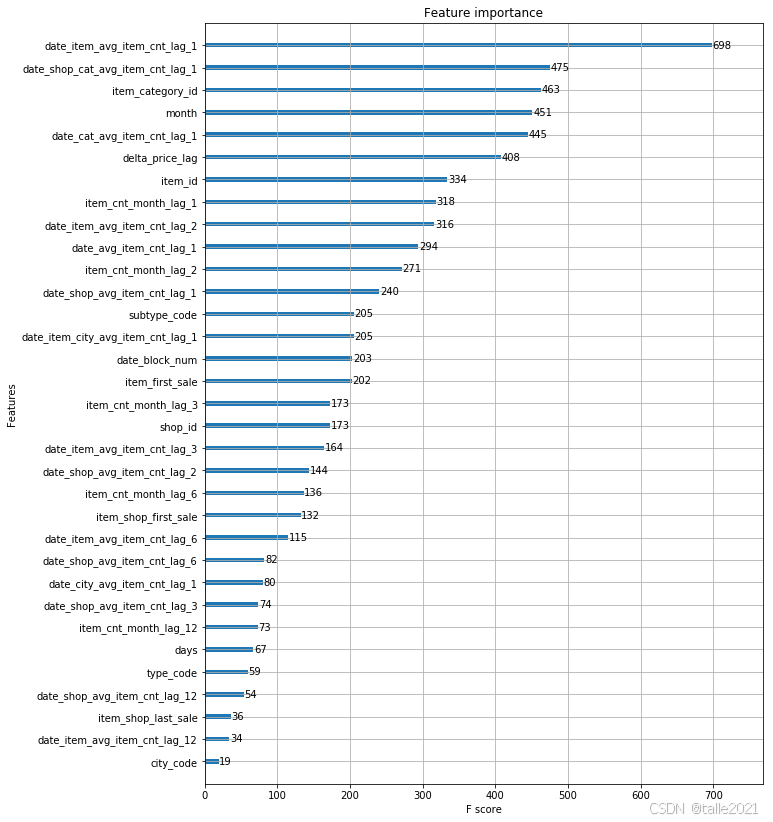
Kaggle-基于xgboost的销量预测
赛题来源:Predict Future Sales | Kaggle
本文复刻冠军方案(Feature engineering, xgboost | Kaggle)
目录
1 赛题引入
1.1 赛题描述
1.2 评估指标
1.3 数据集解释
1.3.1 文件描述
1.3.2 数据集描述
1 sales_train.csv
2 test.csv
3 items.csv
4 item_categories.csv
5 shops.csv
2 特征工程
2.1 训练集异常值处理
2.2 拆分原特征创建新特征
2.3 合并训练集和测试集
2.4 滑动窗口创建新特征
2.5 创建时间维度特征
3 模型建立
3.1 特征选择
3.2 分割数据集
3.3 模型训练与预测
1 赛题引入
1.1 赛题描述
这个比赛是Coursera课程“如何赢得数据科学竞赛”的最终项目。在本次比赛中,您将使用由每日销售数据组成的具有挑战性的时间序列数据集,该数据集由俄罗斯最大的软件公司之一[- 1C]公司提供。要求预测下个月每个商品和商店的总销售额。
1.2 评估指标
提交的数据通过均方根误差(root mean squared error,RMSE)进行评估。真实的目标值被裁剪到[0,20]范围内。对于测试集中的每个id,您必须预测销售的总数。该文件应该包含一个头文件,格式如下:
| ID | item_cnt_month |
| 0 | 0.5 |
| 1 | 0.5 |
| 2 | 0.5 |
1.3 数据集解释
1.3.1 文件描述
sales_train.csv 训练集,2013年1月- 2015年10月每日历史数据。
test.csv 测试集,需要预测2015年11月店铺和商品的销售情况。
sample_submission.csv 正确格式的示例提交文件。
items.csv 关于商品的补充信息。
item_categories.csv 关于项目类别的补充信息。
shops.csv 关于商店的补充信息。
1.3.2 数据集描述
1 sales_train.csv
| Field name | Description |
| date | 日期格式为dd/mm/yyyy |
| date_block_num | 连续月份,2013年1月为0,2013年2月为1,…, 2015年10月是33 |
| shop_id | 商店的唯一标识符 |
| item_id | 商品的唯一标识符 |
| item_price | 商品的当前价格 |
| item_cnt_day | 售出的商品数量 |
2 test.csv
| Field name | Description |
| ID | 表示测试集中的(Shop, Item)元组的ID |
| shop_id | 商店的唯一标识符 |
| item_id | 商品的唯一标识符 |
3 items.csv
| Field name | Description |
| item_name | 商品名称 |
| item_id | 商品的唯一标识符 |
| item_category_id | 商品类别的唯一标识 |
4 item_categories.csv
| Field name | Description |
| item_category_name | 商品类别名称 |
| item_category_id | 商品类别的唯一标识 |
5 shops.csv
| Field name | Description |
| shop_name | 商店名称 |
| shop_id | 商店的唯一标识符 |
2 特征工程
import numpy as np
import pandas as pd
pd.set_option('display.max_rows', 500)
pd.set_option('display.max_columns', 100)
from itertools import product
from sklearn.preprocessing import LabelEncoder
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
from xgboost import XGBRegressor
from xgboost import plot_importance
def plot_features(booster, figsize): fig, ax = plt.subplots(1,1,figsize=figsize)return plot_importance(booster=booster, ax=ax)
import time
import sys
import gc
import pickle
sys.version_info
items = pd.read_csv(r"D:\py_files\future_sales\competitive-data-science-predict-future-sales\items.csv")
shops = pd.read_csv(r"D:\py_files\future_sales\competitive-data-science-predict-future-sales\shops.csv")
cats = pd.read_csv(r"D:\py_files\future_sales\competitive-data-science-predict-future-sales\item_categories.csv")
train = pd.read_csv(r"D:\py_files\future_sales\competitive-data-science-predict-future-sales\sales_train.csv")
# set index to ID to avoid droping it later
test = pd.read_csv(r"D:\py_files\future_sales\competitive-data-science-predict-future-sales\test.csv").set_index('ID')2.1 训练集异常值处理
plt.figure(figsize=(10,4))
plt.xlim(-100, 3000)
sns.boxplot(x=train.item_cnt_day)plt.figure(figsize=(10,4))
plt.xlim(train.item_price.min(), train.item_price.max()*1.1)
sns.boxplot(x=train.item_price)![]()
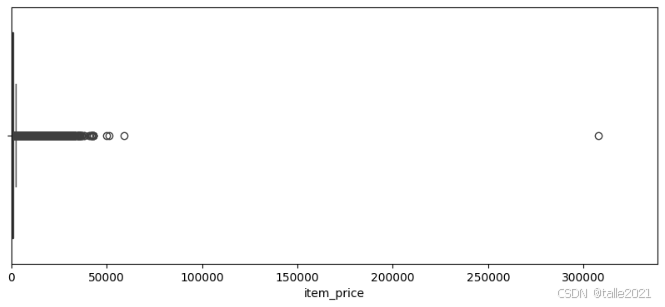
从以上俩图可以看出item_price出现有接近30w的异常值,item_cnt_day有大于2k的异常值,对异常值的处理为直接删除异常值所在行数据;对于价格小于0的商品使用中位数填充;有几家商店从名字上看都是一模一样的(0-57,1-58,10-11),统一shop_id。
train = train[train.item_price<100000]
train = train[train.item_cnt_day<1001]
median = train[(train.shop_id==32)&(train.item_id==2973)&(train.date_block_num==4)&(train.item_price>0)].item_price.median()
train.loc[train.item_price<0, 'item_price'] = median
# Якутск Орджоникидзе, 56
train.loc[train.shop_id == 0, 'shop_id'] = 57
test.loc[test.shop_id == 0, 'shop_id'] = 57
# Якутск ТЦ "Центральный"
train.loc[train.shop_id == 1, 'shop_id'] = 58
test.loc[test.shop_id == 1, 'shop_id'] = 58
# Жуковский ул. Чкалова 39м²
train.loc[train.shop_id == 10, 'shop_id'] = 11
test.loc[test.shop_id == 10, 'shop_id'] = 112.2 拆分原特征创建新特征
通过观察发现每个商店名称(shop_name)以城市名称开头,每个商品类别名称(item_category_name)中包含类型和细分类型。因此创建新特征:城市名称(city),类型(type)和子类型(subtype),并做特征编码处理。
shops.loc[shops.shop_name == 'Сергиев Посад ТЦ "7Я"', 'shop_name'] = 'СергиевПосад ТЦ "7Я"'
shops['city'] = shops['shop_name'].str.split(' ').map(lambda x: x[0])
shops.loc[shops.city == '!Якутск', 'city'] = 'Якутск'
shops['city_code'] = LabelEncoder().fit_transform(shops['city'])
shops = shops[['shop_id','city_code']]cats['split'] = cats['item_category_name'].str.split('-')
cats['type'] = cats['split'].map(lambda x: x[0].strip())
cats['type_code'] = LabelEncoder().fit_transform(cats['type'])
# if subtype is nan then type
cats['subtype'] = cats['split'].map(lambda x: x[1].strip() if len(x) > 1 else x[0].strip())
cats['subtype_code'] = LabelEncoder().fit_transform(cats['subtype'])
cats = cats[['item_category_id','type_code', 'subtype_code']]items.drop(['item_name'], axis=1, inplace=True)2.3 合并训练集和测试集
len(list(set(test.item_id) - set(test.item_id).intersection(set(train.item_id)))), len(list(set(test.item_id))), len(test)(363, 5100, 214200)
测试集是部分店铺和部分类别第34个月的商品。5100个类别* 42家店铺= 214200。与训练集相比,有363个新商品。因此,对于测试集中的大多数商品,目标值应该为零。使用product函数对训练集中(月份,item_id,shop_id)生成笛卡尔积。
matrix = []
cols = ['date_block_num','shop_id','item_id']
for i in range(34):sales = train[train.date_block_num==i]matrix.append(np.array(list(product([i], sales.shop_id.unique(), sales.item_id.unique())), dtype='int16'))
matrix = pd.DataFrame(np.vstack(matrix), columns=cols)
matrix['date_block_num'] = matrix['date_block_num'].astype(np.int8)
matrix['shop_id'] = matrix['shop_id'].astype(np.int8)
matrix['item_id'] = matrix['item_id'].astype(np.int16)
matrix.sort_values(cols,inplace=True)group = train.groupby(['date_block_num','shop_id','item_id']).agg({'item_cnt_day': ['sum']})
group.columns = ['item_cnt_month'] #月销售量
group.reset_index(inplace=True)
matrix = pd.merge(matrix, group, on=cols, how='left')
matrix['item_cnt_month'] = (matrix['item_cnt_month'].fillna(0).clip(0,20).astype(np.float16))test['date_block_num'] = 34
test['date_block_num'] = test['date_block_num'].astype(np.int8)
test['shop_id'] = test['shop_id'].astype(np.int8)
test['item_id'] = test['item_id'].astype(np.int16)
matrix = pd.concat([matrix, test], ignore_index=True, sort=False, keys=cols)
matrix.fillna(0, inplace=True)matrix.columnsIndex(['date_block_num', 'shop_id', 'item_id', 'item_cnt_month'], dtype='object')
串表:
matrix = pd.merge(matrix, shops, on=['shop_id'], how='left')
matrix = pd.merge(matrix, items, on=['item_id'], how='left')
matrix = pd.merge(matrix, cats, on=['item_category_id'], how='left')
matrix['city_code'] = matrix['city_code'].astype(np.int8)
matrix['item_category_id'] = matrix['item_category_id'].astype(np.int8)
matrix['type_code'] = matrix['type_code'].astype(np.int8)
matrix['subtype_code'] = matrix['subtype_code'].astype(np.int8)matrix.columnsIndex(['date_block_num', 'shop_id', 'item_id', 'item_cnt_month', 'city_code', 'item_category_id', 'type_code', 'subtype_code'], dtype='object')
2.4 滑动窗口创建新特征
举个栗子,在最开始循环时,matrix中某一行数据的date_block_num是2,经过6次循环,这行数据的date_block_num就会变为8,但这行数据所对应的其他列依然是2那天的数据。由于matrix中的date_block_num是不变的,因此在最后一次匹配时,matrix中的2匹配到的会是原本为(8-6)那个月的matrix的数据)。对matrix来说,date_block_num + shop_id + item_id被merge识别为索引了,因此merge函数会将剩下的列合并到matrix中。利用merge函数的这个性质,可以很容易完成matrix表单上的滑窗。
# 定义滑窗函数
def lag_feature(df, lags, col):tmp = df[['date_block_num','shop_id','item_id',col]]for i in lags:shifted = tmp.copy()shifted.columns = ['date_block_num','shop_id','item_id', col+'_lag_'+str(i)]shifted['date_block_num'] += idf = pd.merge(df, shifted, on=['date_block_num','shop_id','item_id'], how='left')return df月销量滑窗
# 基于['date_block_num','shop_id','item_id']月销量滑窗
matrix = lag_feature(matrix, [1,2,3,6,12], 'item_cnt_month')# 基于['date_block_num']月销量均值滑窗
group = matrix.groupby(['date_block_num']).agg({'item_cnt_month': ['mean']})
group.columns = [ 'date_avg_item_cnt' ]
group.reset_index(inplace=True)
matrix = pd.merge(matrix, group, on=['date_block_num'], how='left')
matrix['date_avg_item_cnt'] = matrix['date_avg_item_cnt'].astype(np.float16)
matrix = lag_feature(matrix, [1], 'date_avg_item_cnt')
matrix.drop(['date_avg_item_cnt'], axis=1, inplace=True)# 基于['date_block_num', 'item_id']月销量均值滑窗
group = matrix.groupby(['date_block_num', 'item_id']).agg({'item_cnt_month': ['mean']})
group.columns = [ 'date_item_avg_item_cnt' ]
group.reset_index(inplace=True)
matrix = pd.merge(matrix, group, on=['date_block_num','item_id'], how='left')
matrix['date_item_avg_item_cnt'] = matrix['date_item_avg_item_cnt'].astype(np.float16)
matrix = lag_feature(matrix, [1,2,3,6,12], 'date_item_avg_item_cnt')
matrix.drop(['date_item_avg_item_cnt'], axis=1, inplace=True)# 基于['date_block_num', 'shop_id']月销量均值滑窗
group = matrix.groupby(['date_block_num', 'shop_id']).agg({'item_cnt_month': ['mean']})
group.columns = [ 'date_shop_avg_item_cnt' ]
group.reset_index(inplace=True)
matrix = pd.merge(matrix, group, on=['date_block_num','shop_id'], how='left')
matrix['date_shop_avg_item_cnt'] = matrix['date_shop_avg_item_cnt'].astype(np.float16)
matrix = lag_feature(matrix, [1,2,3,6,12], 'date_shop_avg_item_cnt')
matrix.drop(['date_shop_avg_item_cnt'], axis=1, inplace=True)# 基于['date_block_num', 'item_category_id']月销量均值滑窗
group = matrix.groupby(['date_block_num', 'item_category_id']).agg({'item_cnt_month': ['mean']})
group.columns = [ 'date_cat_avg_item_cnt' ]
group.reset_index(inplace=True)
matrix = pd.merge(matrix, group, on=['date_block_num','item_category_id'], how='left')
matrix['date_cat_avg_item_cnt'] = matrix['date_cat_avg_item_cnt'].astype(np.float16)
matrix = lag_feature(matrix, [1], 'date_cat_avg_item_cnt')
matrix.drop(['date_cat_avg_item_cnt'], axis=1, inplace=True)# 基于['date_block_num', 'shop_id', 'item_category_id']月销量均值滑窗
group = matrix.groupby(['date_block_num', 'shop_id', 'item_category_id']).agg({'item_cnt_month': ['mean']})
group.columns = ['date_shop_cat_avg_item_cnt']
group.reset_index(inplace=True)
matrix = pd.merge(matrix, group, on=['date_block_num', 'shop_id', 'item_category_id'], how='left')
matrix['date_shop_cat_avg_item_cnt'] = matrix['date_shop_cat_avg_item_cnt'].astype(np.float16)
matrix = lag_feature(matrix, [1], 'date_shop_cat_avg_item_cnt')
matrix.drop(['date_shop_cat_avg_item_cnt'], axis=1, inplace=True)# 基于['date_block_num', 'shop_id', 'type_code']月销量均值滑窗
group = matrix.groupby(['date_block_num', 'shop_id', 'type_code']).agg({'item_cnt_month': ['mean']})
group.columns = ['date_shop_type_avg_item_cnt']
group.reset_index(inplace=True)
matrix = pd.merge(matrix, group, on=['date_block_num', 'shop_id', 'type_code'], how='left')
matrix['date_shop_type_avg_item_cnt'] = matrix['date_shop_type_avg_item_cnt'].astype(np.float16)
matrix = lag_feature(matrix, [1], 'date_shop_type_avg_item_cnt')
matrix.drop(['date_shop_type_avg_item_cnt'], axis=1, inplace=True)# 基于['date_block_num', 'shop_id', 'subtype_code']月销量均值滑窗
group = matrix.groupby(['date_block_num', 'shop_id', 'subtype_code']).agg({'item_cnt_month': ['mean']})
group.columns = ['date_shop_subtype_avg_item_cnt']
group.reset_index(inplace=True)
matrix = pd.merge(matrix, group, on=['date_block_num', 'shop_id', 'subtype_code'], how='left')
matrix['date_shop_subtype_avg_item_cnt'] = matrix['date_shop_subtype_avg_item_cnt'].astype(np.float16)
matrix = lag_feature(matrix, [1], 'date_shop_subtype_avg_item_cnt')
matrix.drop(['date_shop_subtype_avg_item_cnt'], axis=1, inplace=True)# 基于['date_block_num', 'city_code']月销量均值滑窗
group = matrix.groupby(['date_block_num', 'city_code']).agg({'item_cnt_month': ['mean']})
group.columns = [ 'date_city_avg_item_cnt' ]
group.reset_index(inplace=True)
matrix = pd.merge(matrix, group, on=['date_block_num', 'city_code'], how='left')
matrix['date_city_avg_item_cnt'] = matrix['date_city_avg_item_cnt'].astype(np.float16)
matrix = lag_feature(matrix, [1], 'date_city_avg_item_cnt')
matrix.drop(['date_city_avg_item_cnt'], axis=1, inplace=True)# 基于['date_block_num', 'item_id', 'city_code']月销量均值滑窗
group = matrix.groupby(['date_block_num', 'item_id', 'city_code']).agg({'item_cnt_month': ['mean']})
group.columns = [ 'date_item_city_avg_item_cnt' ]
group.reset_index(inplace=True)
matrix = pd.merge(matrix, group, on=['date_block_num', 'item_id', 'city_code'], how='left')
matrix['date_item_city_avg_item_cnt'] = matrix['date_item_city_avg_item_cnt'].astype(np.float16)
matrix = lag_feature(matrix, [1], 'date_item_city_avg_item_cnt')
matrix.drop(['date_item_city_avg_item_cnt'], axis=1, inplace=True)# 基于['date_block_num', 'type_code']月销量均值滑窗
group = matrix.groupby(['date_block_num', 'type_code']).agg({'item_cnt_month': ['mean']})
group.columns = [ 'date_type_avg_item_cnt' ]
group.reset_index(inplace=True)
matrix = pd.merge(matrix, group, on=['date_block_num', 'type_code'], how='left')
matrix['date_type_avg_item_cnt'] = matrix['date_type_avg_item_cnt'].astype(np.float16)
matrix = lag_feature(matrix, [1], 'date_type_avg_item_cnt')
matrix.drop(['date_type_avg_item_cnt'], axis=1, inplace=True)# 基于['date_block_num', 'subtype_code']月销量均值滑窗
group = matrix.groupby(['date_block_num', 'subtype_code']).agg({'item_cnt_month': ['mean']})
group.columns = [ 'date_subtype_avg_item_cnt' ]
group.reset_index(inplace=True)
matrix = pd.merge(matrix, group, on=['date_block_num', 'subtype_code'], how='left')
matrix['date_subtype_avg_item_cnt'] = matrix['date_subtype_avg_item_cnt'].astype(np.float16)
matrix = lag_feature(matrix, [1], 'date_subtype_avg_item_cnt')
matrix.drop(['date_subtype_avg_item_cnt'], axis=1, inplace=True)商品价格滑窗
# 基于['item_id']求商品价格均值
group = train.groupby(['item_id']).agg({'item_price': ['mean']})
group.columns = ['item_avg_item_price']
group.reset_index(inplace=True)
matrix = pd.merge(matrix, group, on=['item_id'], how='left')
matrix['item_avg_item_price'] = matrix['item_avg_item_price'].astype(np.float16)# 基于['date_block_num','item_id']求商品价格均值
group = train.groupby(['date_block_num','item_id']).agg({'item_price': ['mean']})
group.columns = ['date_item_avg_item_price']
group.reset_index(inplace=True)
matrix = pd.merge(matrix, group, on=['date_block_num','item_id'], how='left')
matrix['date_item_avg_item_price'] = matrix['date_item_avg_item_price'].astype(np.float16)lags = [1,2,3,4,5,6]
matrix = lag_feature(matrix, lags, 'date_item_avg_item_price')
# 求当月商品价格与商品平均价格的变化率
for i in lags:matrix['delta_price_lag_'+str(i)] = \(matrix['date_item_avg_item_price_lag_'+str(i)] - matrix['item_avg_item_price']) / matrix['item_avg_item_price']# 从一组滞后(lag)的价格变化列中,选择第一个非零(或非空、非假值)的值,如果所有值都是零(或空、假值),则返回 0。
def select_trend(row):for i in lags:if row['delta_price_lag_'+str(i)]:return row['delta_price_lag_'+str(i)]return 0matrix['delta_price_lag'] = matrix.apply(select_trend, axis=1)
matrix['delta_price_lag'] = matrix['delta_price_lag'].astype(np.float16)
matrix['delta_price_lag'].fillna(0, inplace=True)
fetures_to_drop = ['item_avg_item_price', 'date_item_avg_item_price']
for i in lags:fetures_to_drop += ['date_item_avg_item_price_lag_'+str(i)]fetures_to_drop += ['delta_price_lag_'+str(i)]matrix.drop(fetures_to_drop, axis=1, inplace=True)销售额滑窗
train['revenue'] = train['item_price'] * train['item_cnt_day']
# 基于['date_block_num','shop_id']求总销售额
group = train.groupby(['date_block_num','shop_id']).agg({'revenue': ['sum']})
group.columns = ['date_shop_revenue']
group.reset_index(inplace=True)
matrix = pd.merge(matrix, group, on=['date_block_num','shop_id'], how='left')
matrix['date_shop_revenue'] = matrix['date_shop_revenue'].astype(np.float32)# 基于['shop_id']求销售额均值
group = group.groupby(['shop_id']).agg({'date_shop_revenue': ['mean']})
group.columns = ['shop_avg_revenue']
group.reset_index(inplace=True)
matrix = pd.merge(matrix, group, on=['shop_id'], how='left')
matrix['shop_avg_revenue'] = matrix['shop_avg_revenue'].astype(np.float32)# 求商店当月销售额与商店平均销售额的变化率
matrix['delta_revenue'] = (matrix['date_shop_revenue'] - matrix['shop_avg_revenue']) / matrix['shop_avg_revenue']
matrix['delta_revenue'] = matrix['delta_revenue'].astype(np.float16)# 滑窗
matrix = lag_feature(matrix, [1], 'delta_revenue')
matrix.drop(['date_shop_revenue','shop_avg_revenue','delta_revenue'], axis=1, inplace=True)2.5 创建时间维度特征
matrix['month'] = matrix['date_block_num'] % 12
days = pd.Series([31,28,31,30,31,30,31,31,30,31,30,31])
matrix['days'] = matrix['month'].map(days).astype(np.int8)# 计算每个商品(item_id)在每个商店(shop_id)的“上一次销售距今的月份数”
cache = {}
matrix['item_shop_last_sale'] = -1
matrix['item_shop_last_sale'] = matrix['item_shop_last_sale'].astype(np.int8)
for idx, row in matrix.iterrows(): key = str(row.item_id)+' '+str(row.shop_id)if key not in cache:if row.item_cnt_month!=0:cache[key] = row.date_block_numelse:last_date_block_num = cache[key]matrix.at[idx, 'item_shop_last_sale'] = row.date_block_num - last_date_block_numcache[key] = row.date_block_num # 计算每个商品(item_id)的“上一次销售距今的月份数”
cache = {}
matrix['item_last_sale'] = -1
matrix['item_last_sale'] = matrix['item_last_sale'].astype(np.int8)
for idx, row in matrix.iterrows(): key = row.item_idif key not in cache:if row.item_cnt_month!=0:cache[key] = row.date_block_numelse:last_date_block_num = cache[key]if row.date_block_num>last_date_block_num:matrix.at[idx, 'item_last_sale'] = row.date_block_num - last_date_block_numcache[key] = row.date_block_num # 计算每个商品(item_id)的“当月销售距第一次销售的月份数”
matrix['item_shop_first_sale'] = matrix['date_block_num'] - matrix.groupby(['item_id','shop_id'])['date_block_num'].transform('min')
matrix['item_first_sale'] = matrix['date_block_num'] - matrix.groupby('item_id')['date_block_num'].transform('min')由于滑窗的最大滞后为12,这就导致第0到第11个月的数据缺失,故删除第11个月之前的数据,并填充缺失值。
matrix = matrix[matrix.date_block_num > 11]
def fill_na(df):for col in df.columns:if ('_lag_' in col) & (df[col].isnull().any()):if ('item_cnt' in col):df[col].fillna(0, inplace=True) return dfmatrix = fill_na(matrix)matrix.columns---------------------------------------------------------------------------------
Index(['date_block_num', 'shop_id', 'item_id', 'item_cnt_month', 'city_code','item_category_id', 'type_code', 'subtype_code', 'item_cnt_month_lag_1','item_cnt_month_lag_2', 'item_cnt_month_lag_3', 'item_cnt_month_lag_6','item_cnt_month_lag_12', 'date_avg_item_cnt_lag_1','date_item_avg_item_cnt_lag_1', 'date_item_avg_item_cnt_lag_2','date_item_avg_item_cnt_lag_3', 'date_item_avg_item_cnt_lag_6','date_item_avg_item_cnt_lag_12', 'date_shop_avg_item_cnt_lag_1','date_shop_avg_item_cnt_lag_2', 'date_shop_avg_item_cnt_lag_3','date_shop_avg_item_cnt_lag_6', 'date_shop_avg_item_cnt_lag_12','date_cat_avg_item_cnt_lag_1', 'date_shop_cat_avg_item_cnt_lag_1','date_shop_type_avg_item_cnt_lag_1','date_shop_subtype_avg_item_cnt_lag_1', 'date_city_avg_item_cnt_lag_1','date_item_city_avg_item_cnt_lag_1', 'date_type_avg_item_cnt_lag_1','date_subtype_avg_item_cnt_lag_1', 'delta_price_lag','delta_revenue_lag_1', 'month', 'days', 'item_shop_last_sale','item_last_sale', 'item_shop_first_sale', 'item_first_sale'],dtype='object')matrix.to_pickle('data.pkl')
del matrix
del cache
del group
del items
del shops
del cats
del train
# leave test for submission
gc.collect();3 模型建立
3.1 特征选择
data = pd.read_pickle('data.pkl')
data = data[['date_block_num','shop_id','item_id','item_cnt_month','city_code','item_category_id','type_code','subtype_code','item_cnt_month_lag_1','item_cnt_month_lag_2','item_cnt_month_lag_3','item_cnt_month_lag_6','item_cnt_month_lag_12','date_avg_item_cnt_lag_1','date_item_avg_item_cnt_lag_1','date_item_avg_item_cnt_lag_2','date_item_avg_item_cnt_lag_3','date_item_avg_item_cnt_lag_6','date_item_avg_item_cnt_lag_12','date_shop_avg_item_cnt_lag_1','date_shop_avg_item_cnt_lag_2','date_shop_avg_item_cnt_lag_3','date_shop_avg_item_cnt_lag_6','date_shop_avg_item_cnt_lag_12','date_cat_avg_item_cnt_lag_1','date_shop_cat_avg_item_cnt_lag_1',#'date_shop_type_avg_item_cnt_lag_1',#'date_shop_subtype_avg_item_cnt_lag_1','date_city_avg_item_cnt_lag_1','date_item_city_avg_item_cnt_lag_1',#'date_type_avg_item_cnt_lag_1',#'date_subtype_avg_item_cnt_lag_1','delta_price_lag','month','days','item_shop_last_sale','item_last_sale','item_shop_first_sale','item_first_sale',
]]3.2 分割数据集
将第12个月到第32个月的数据作为训练集,第33个月的数据作为验证集,第34个月的数据为测试集
X_train = data[data.date_block_num < 33].drop(['item_cnt_month'], axis=1)
Y_train = data[data.date_block_num < 33]['item_cnt_month']
X_valid = data[data.date_block_num == 33].drop(['item_cnt_month'], axis=1)
Y_valid = data[data.date_block_num == 33]['item_cnt_month']
X_test = data[data.date_block_num == 34].drop(['item_cnt_month'], axis=1)3.3 模型训练与预测
model = XGBRegressor(max_depth=8,n_estimators=1000,min_child_weight=300, colsample_bytree=0.8, subsample=0.8, eta=0.3, seed=42)model.fit(X_train, Y_train, eval_metric="rmse", eval_set=[(X_train, Y_train), (X_valid, Y_valid)], verbose=True, early_stopping_rounds = 10)[0] validation_0-rmse:1.15115 validation_1-rmse:1.11798
Multiple eval metrics have been passed: 'validation_1-rmse' will be used for early stopping.Will train until validation_1-rmse hasn't improved in 10 rounds.
[1] validation_0-rmse:1.10687 validation_1-rmse:1.08404
[2] validation_0-rmse:1.06586 validation_1-rmse:1.05307
[3] validation_0-rmse:1.03083 validation_1-rmse:1.02696
[4] validation_0-rmse:1.0038 validation_1-rmse:1.00857
[5] validation_0-rmse:0.978529 validation_1-rmse:0.990388
[6] validation_0-rmse:0.957395 validation_1-rmse:0.975655
[7] validation_0-rmse:0.938939 validation_1-rmse:0.96271
[8] validation_0-rmse:0.923232 validation_1-rmse:0.952649
[9] validation_0-rmse:0.910424 validation_1-rmse:0.944352
[10] validation_0-rmse:0.899173 validation_1-rmse:0.937611
[11] validation_0-rmse:0.889466 validation_1-rmse:0.932494
[12] validation_0-rmse:0.881379 validation_1-rmse:0.928056
[13] validation_0-rmse:0.874594 validation_1-rmse:0.924315
[14] validation_0-rmse:0.868647 validation_1-rmse:0.921059
[15] validation_0-rmse:0.863089 validation_1-rmse:0.918693
[16] validation_0-rmse:0.858058 validation_1-rmse:0.916832
[17] validation_0-rmse:0.853956 validation_1-rmse:0.91513
[18] validation_0-rmse:0.850375 validation_1-rmse:0.913957
[19] validation_0-rmse:0.847462 validation_1-rmse:0.912559
[20] validation_0-rmse:0.844111 validation_1-rmse:0.912796
[21] validation_0-rmse:0.84148 validation_1-rmse:0.911829
[22] validation_0-rmse:0.83889 validation_1-rmse:0.91081
[23] validation_0-rmse:0.836327 validation_1-rmse:0.909467
[24] validation_0-rmse:0.833778 validation_1-rmse:0.909143
[25] validation_0-rmse:0.831529 validation_1-rmse:0.908383
[26] validation_0-rmse:0.830163 validation_1-rmse:0.907943
[27] validation_0-rmse:0.828674 validation_1-rmse:0.907645
[28] validation_0-rmse:0.827013 validation_1-rmse:0.907034
[29] validation_0-rmse:0.825432 validation_1-rmse:0.906604
[30] validation_0-rmse:0.824283 validation_1-rmse:0.906815
[31] validation_0-rmse:0.823251 validation_1-rmse:0.906519
[32] validation_0-rmse:0.822098 validation_1-rmse:0.906345
[33] validation_0-rmse:0.821213 validation_1-rmse:0.906329
[34] validation_0-rmse:0.820317 validation_1-rmse:0.906179
[35] validation_0-rmse:0.819347 validation_1-rmse:0.906203
[36] validation_0-rmse:0.81856 validation_1-rmse:0.906378
[37] validation_0-rmse:0.818015 validation_1-rmse:0.90614
[38] validation_0-rmse:0.817035 validation_1-rmse:0.906135
[39] validation_0-rmse:0.816415 validation_1-rmse:0.906268
[40] validation_0-rmse:0.815919 validation_1-rmse:0.906379
[41] validation_0-rmse:0.815426 validation_1-rmse:0.906448
[42] validation_0-rmse:0.814711 validation_1-rmse:0.906425
[43] validation_0-rmse:0.814034 validation_1-rmse:0.906463
[44] validation_0-rmse:0.813742 validation_1-rmse:0.906246
[45] validation_0-rmse:0.813137 validation_1-rmse:0.905782
[46] validation_0-rmse:0.812666 validation_1-rmse:0.905902
[47] validation_0-rmse:0.812359 validation_1-rmse:0.905807
[48] validation_0-rmse:0.811902 validation_1-rmse:0.905914
[49] validation_0-rmse:0.81132 validation_1-rmse:0.90593
[50] validation_0-rmse:0.810779 validation_1-rmse:0.90599
[51] validation_0-rmse:0.810446 validation_1-rmse:0.905962
[52] validation_0-rmse:0.810068 validation_1-rmse:0.906491
[53] validation_0-rmse:0.809446 validation_1-rmse:0.907076
[54] validation_0-rmse:0.808975 validation_1-rmse:0.90696
[55] validation_0-rmse:0.808728 validation_1-rmse:0.906884
Stopping. Best iteration:
[45] validation_0-rmse:0.813137 validation_1-rmse:0.905782Y_pred = model.predict(X_valid).clip(0, 20)
Y_test = model.predict(X_test).clip(0, 20)submission = pd.DataFrame({"ID": test.index, "item_cnt_month": Y_test
})
submission.to_csv('xgb_submission.csv', index=False)