火热邀测!DataWorks数据集成支持大模型AI处理
数字化浪潮下,数据已成为企业的“新石油”,但如何从海量、异构的数据矿藏中精准提炼价值,始终是AI时代的关键命题。传统的数据集成方案往往面临链路复杂、处理低效、非结构化数据支持薄弱等瓶颈。阿里云大数据开发治理平台 DataWorks 数据集成智能升级,以“ AI 释放数据价值”为核心,推出数据集成支持大模型 AI 处理功能,支持在数据同步过程中对数据进行高级分析和处理,帮助用户利用 AI 技术提升数据质量、挖掘数据价值。
核心产品能力-让数据集成与大模型无缝协同
DataWorks 支持在数据同步流程中无缝集成并调用AI大模型服务,目前支持调用阿里云百炼模型的部分通义千问模型,更多模型快速接入中。用户可通过自然语言和简单的配置定义,将大模型应用于同步的数据流中,如进行文本翻译、分类、情感分析等处理,并将处理结果写入到目标表中。整个过程开箱即用,无需提前部署调试,业务人员通过自然语言即可驱动海量数据的复杂处理。
适用场景-多行业多场景赋能企业AI落地
大模型数据处理在数据同步 ETL 流程中可广泛应用于多个企业场景,通过情感分析、摘要生成、关键词提取和翻译等能力提升数据处理效率与洞察深度。这些应用可以显著提升了企业的决策支持能力和运营智能化水平。
1. 电商客服场景:用户反馈分析与情感分类
示例,客户留言:“快递太慢了,等了半个月还没到!”
| 数据处理场景 | 提示语 | 处理结果示例 |
| 情感分析 | 对用户投诉/咨询文本进行情感分类(正面/负面/中性) | 负面 |
| 摘要生成 | 将长文本的用户反馈压缩为简短摘要,提取核心问题 | 用户投诉物流时效问题 |
| 关键词提取 | 识别高频问题关键词(如“物流延迟”“产品质量”) | 物流延迟、快递、时效 |
2. 智能汽车场景:设备日志分析与预测性维护
示例,日志内容:“The break pump pressure:abnormal; sensor exceeding : 15%”
| 数据处理场景 | 提示语 | 处理结果示例 |
| 文本总结 | 将设备运行日志中的故障描述压缩为关键信息 | 刹车泵浦压力超限,需立即检查 |
| 严重性判断 | 判断日志中描述的故障严重性(如“紧急”“警告”) | 高危 |
| 翻译 | 统一翻译为中文 | 刹车泵浦压力异常,传感器显示值高于阈值15% |
3. 供应链场景:供应商反馈分析与风险预警
示例,供应商邮件:“We are unable to fulfill the order due to a shortage of raw materials.”
| 数据处理场景 | 提示语 | 处理结果示例 |
| 情感分析 | 评估供应商合作态度(积极/消极) | 消极 |
| 摘要生成 | 提取供应商反馈的核心问题(如“交付延迟”) | 供应商因原材料短缺无法完成订单 |
| 翻译 | 将非中文供应商邮件翻译为中文 | 由于原材料短缺,我们无法完成该订单 |
4. 医疗场景:患者反馈分析与满意度调查
示例,患者留言:“医生态度很好,但排队时间太长了!”
| 数据处理场景 | 提示语 | 处理结果示例 |
| 情感分析 | 分析患者对医疗服务的满意度 | 中性 |
| 摘要生成 | 提取患者投诉的核心问题(如“候诊时间长”) | 患者认可医生服务,但抱怨候诊时间 |
| 关键词提取 | 识别高频医疗问题(如“药品副作用”) | 候诊时间、医生态度 |
5. 金融场景:客户投诉分类与风险识别
示例,客户投诉:“我的信用卡被未经授权扣款,请立即冻结账户!”
| 数据处理场景 | 提示语 | 处理结果示例 |
| 情感分析 | 判断客户投诉的紧急程度(如“账户被盗”为高危) | 高危(评分-1.0) |
| 主题分类 | 将投诉按业务类型分类(如“贷款”“信用卡”) | 信用卡安全 |
| 摘要生成 | 提取投诉的核心诉求(如“要求退款”) | 客户报告未经授权扣款,要求冻结账户 |
6. 法律场景:合同条款分析与风险标注
示例,合同条款:“In the event of force majeure, the delivery deadline may be extended.”
| 数据处理场景 | 提示语 | 处理结果示例 |
| 摘要生成 | 提取合同核心条款(如付款条件、违约责任) | 不可抗力条款允许延期交货 |
| 关键词提取 | 识别关键法律术语(如“不可抗力”“仲裁条款”) | 不可抗力、交货期限 |
| 翻译 | 将外文合同翻译为中文 | 若发生不可抗力,交货期限可延长 |
7. 教育场景:学生反馈分析与教学改进
示例,学生反馈:“课程内容很实用,但作业量太大了!”
| 数据处理场景 | 提示语 | 处理结果示例 |
| 情感分析 | 评估学生对课程的满意度 | 中性(正面+负面混合) |
| 主题分类 | 将反馈按课程模块分类(如“作业难度”“教学内容”) | 作业难度 |
| 摘要生成 | 提取学生提出的改进建议(如“增加实践环节”) | 学生认可课程实用性,但建议减少作业量 |
立即体验!
目前,该功能开放对外邀测,您可以点击此处申请测试资格,获得测试资格后体验该功能
功能入口:进入DataWorks工作空间列表页,在顶部切换至目标地域,新建工作空间(注意打开参加数据开发(Data Studio)公测开关),或找到已创建的参与公测的工作空间,单击操作列的快速进入 > Data Studio,进入 Data Studio。
Step 1 :在 DataStudio 里建立数据集成任务
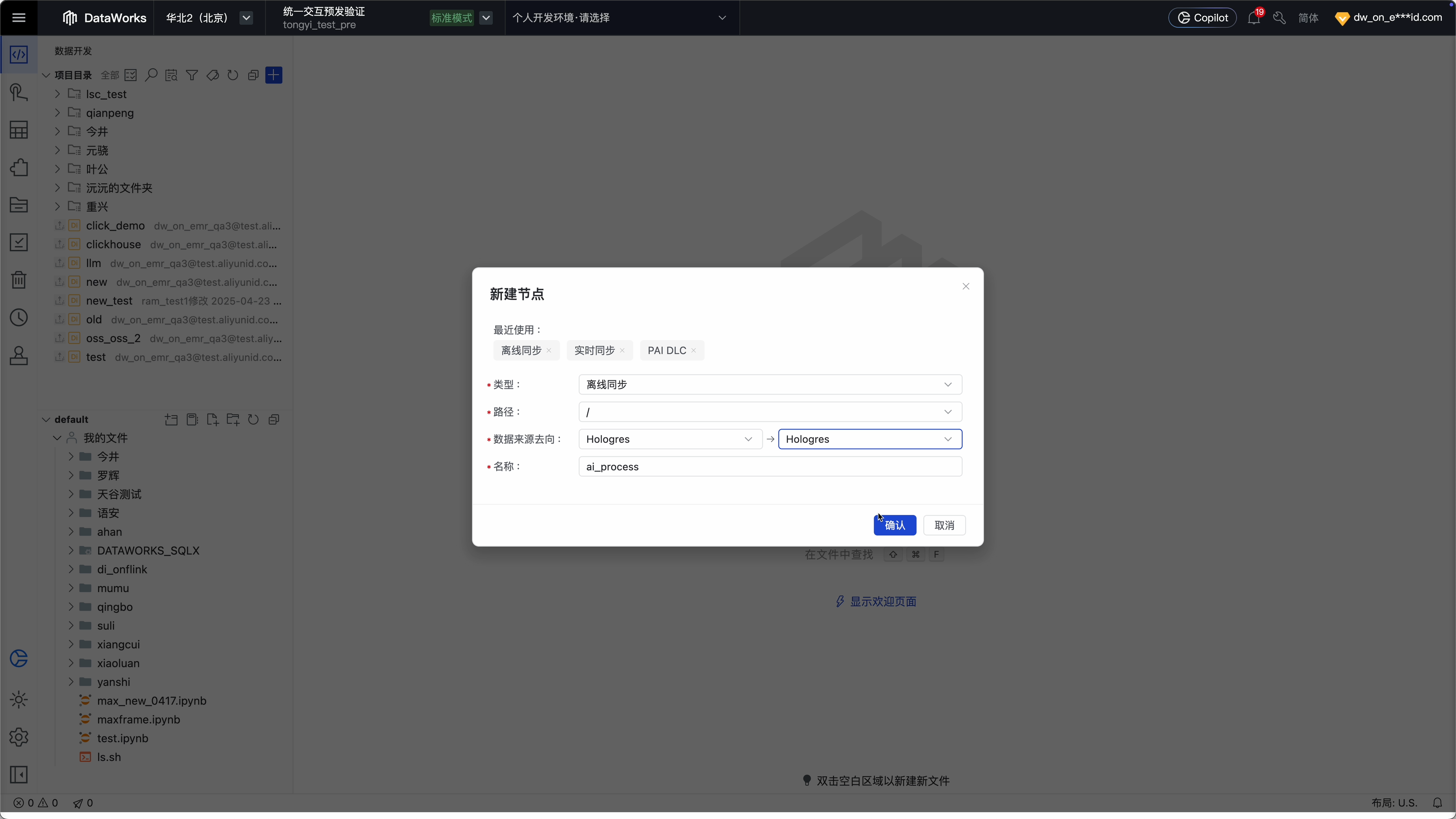
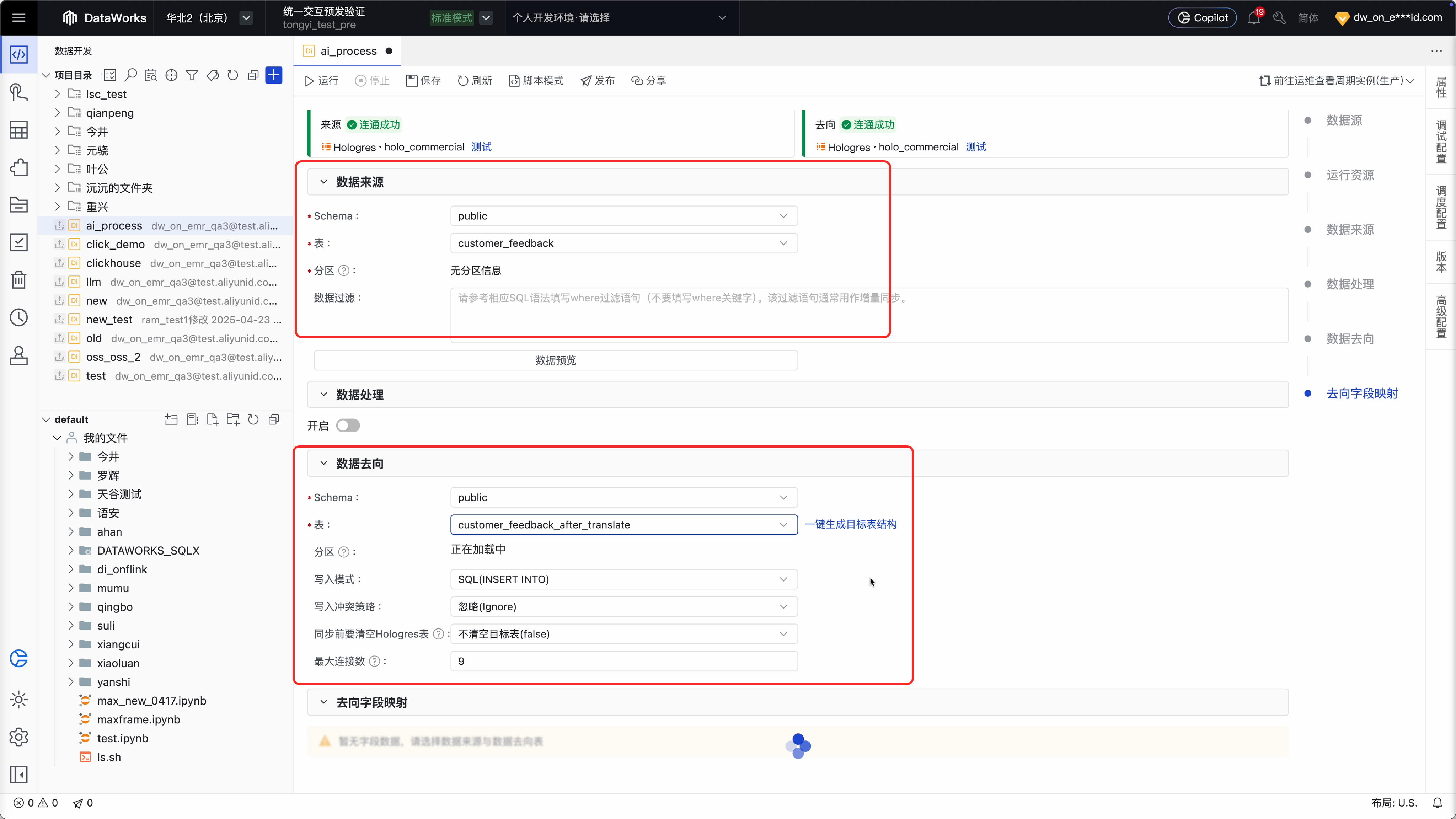
Step 2 :像一般同步任务一样,配置来源和去向数据源和对应表
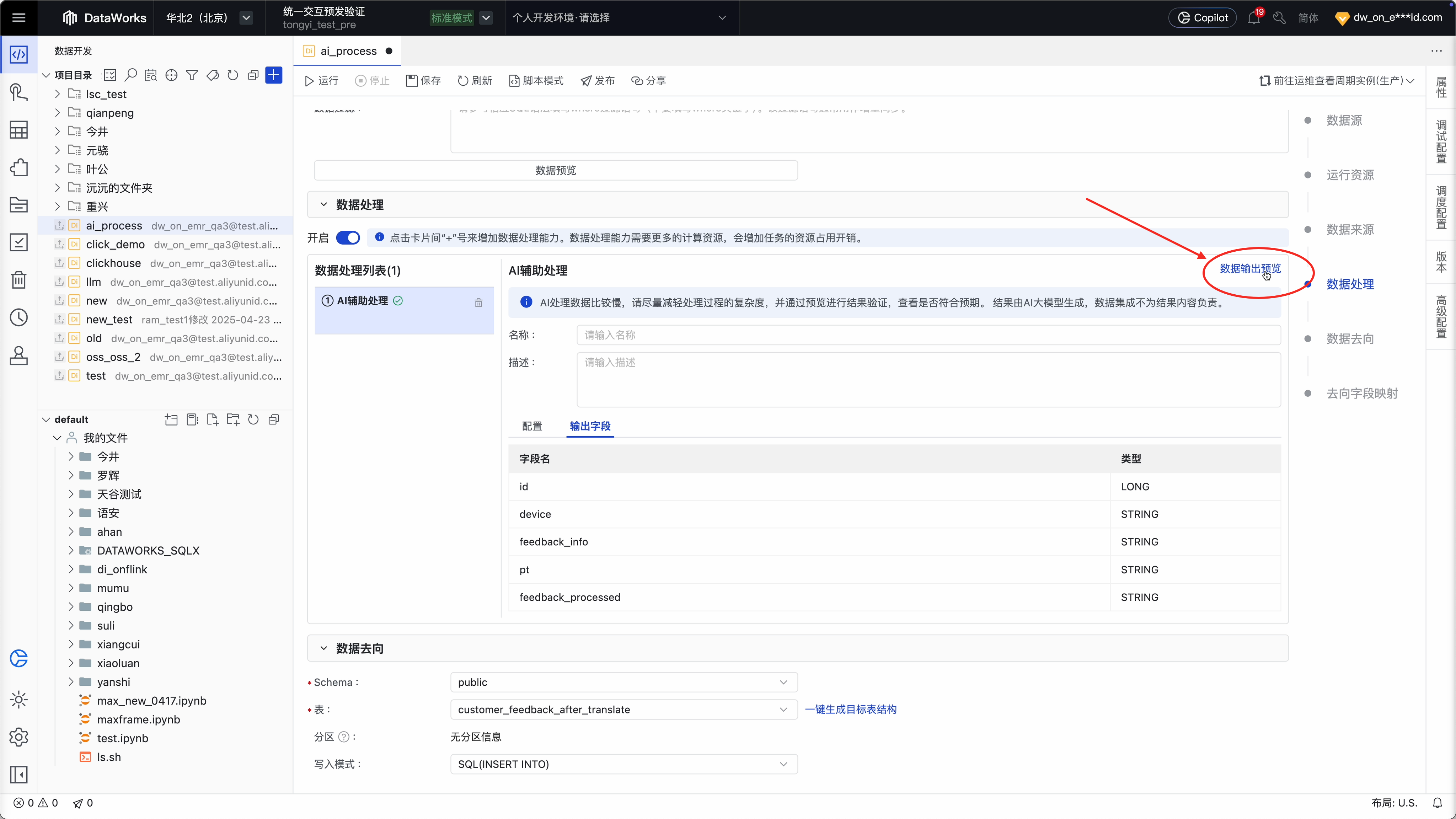
Step 3 :开启数据处理,新建“ AI 辅助处理”流程
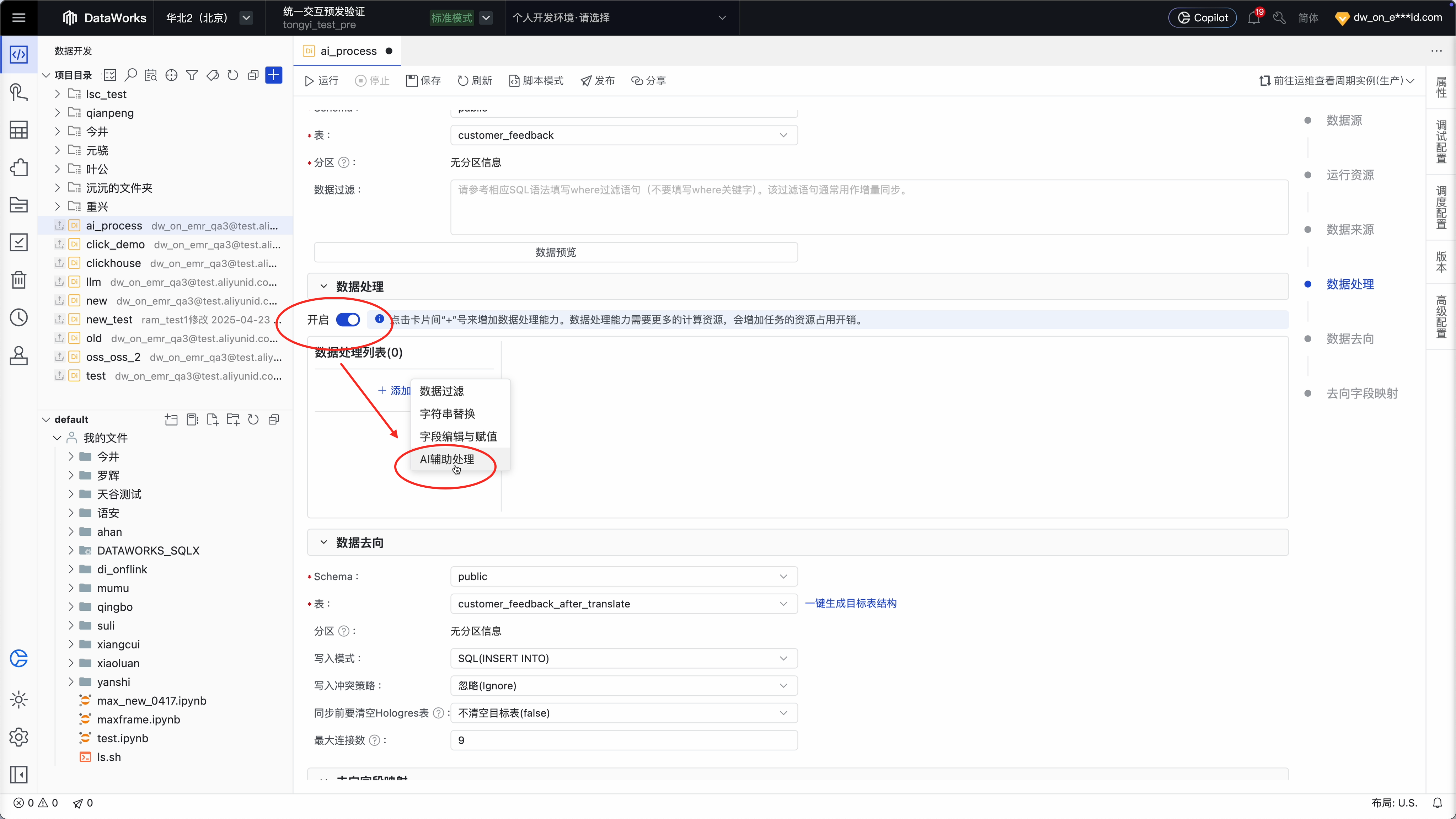
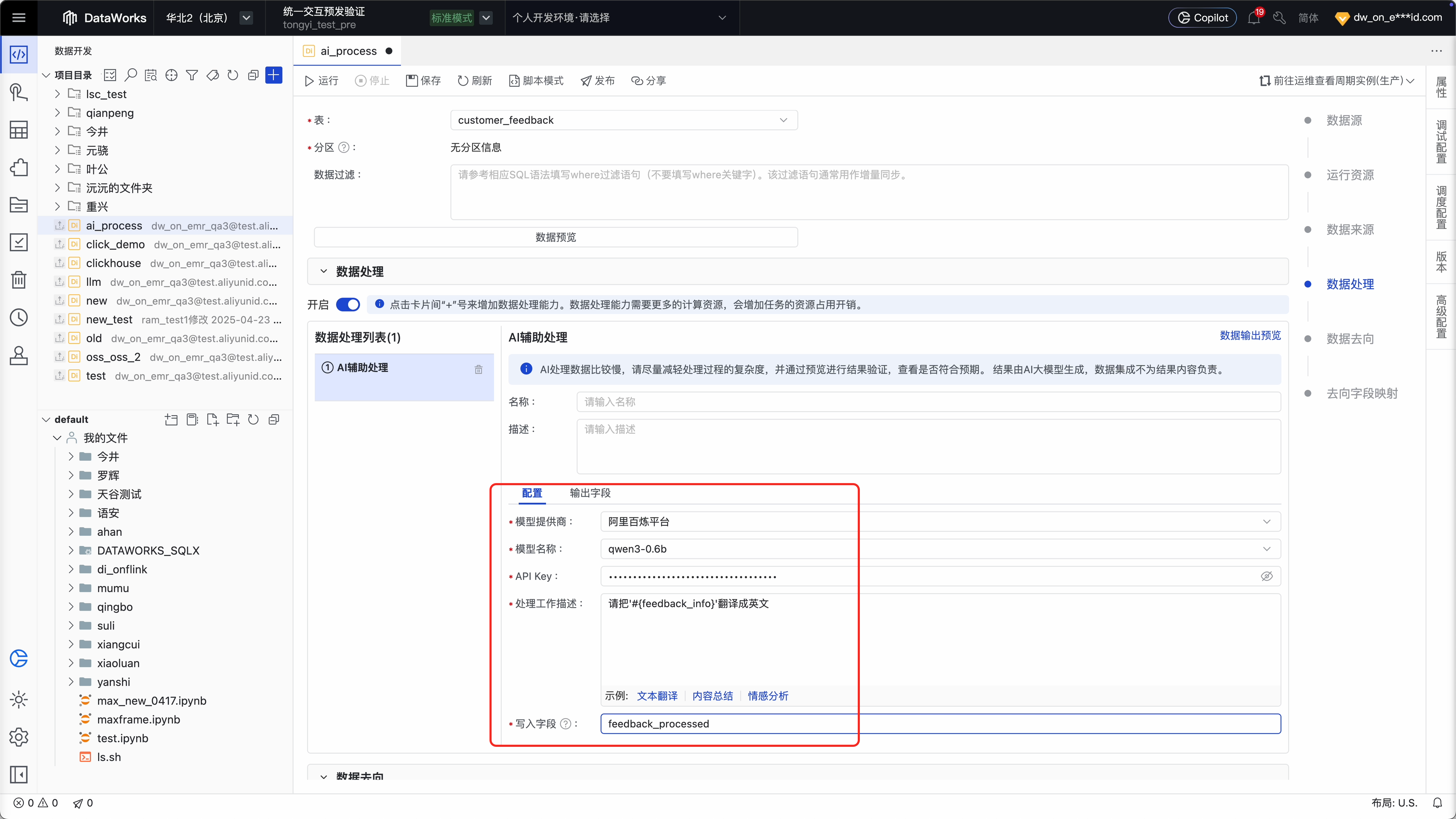
Step 4:选择 AI 模型和配置处理指令
Step 5 :将处理结果存储在目标表的指定字段上
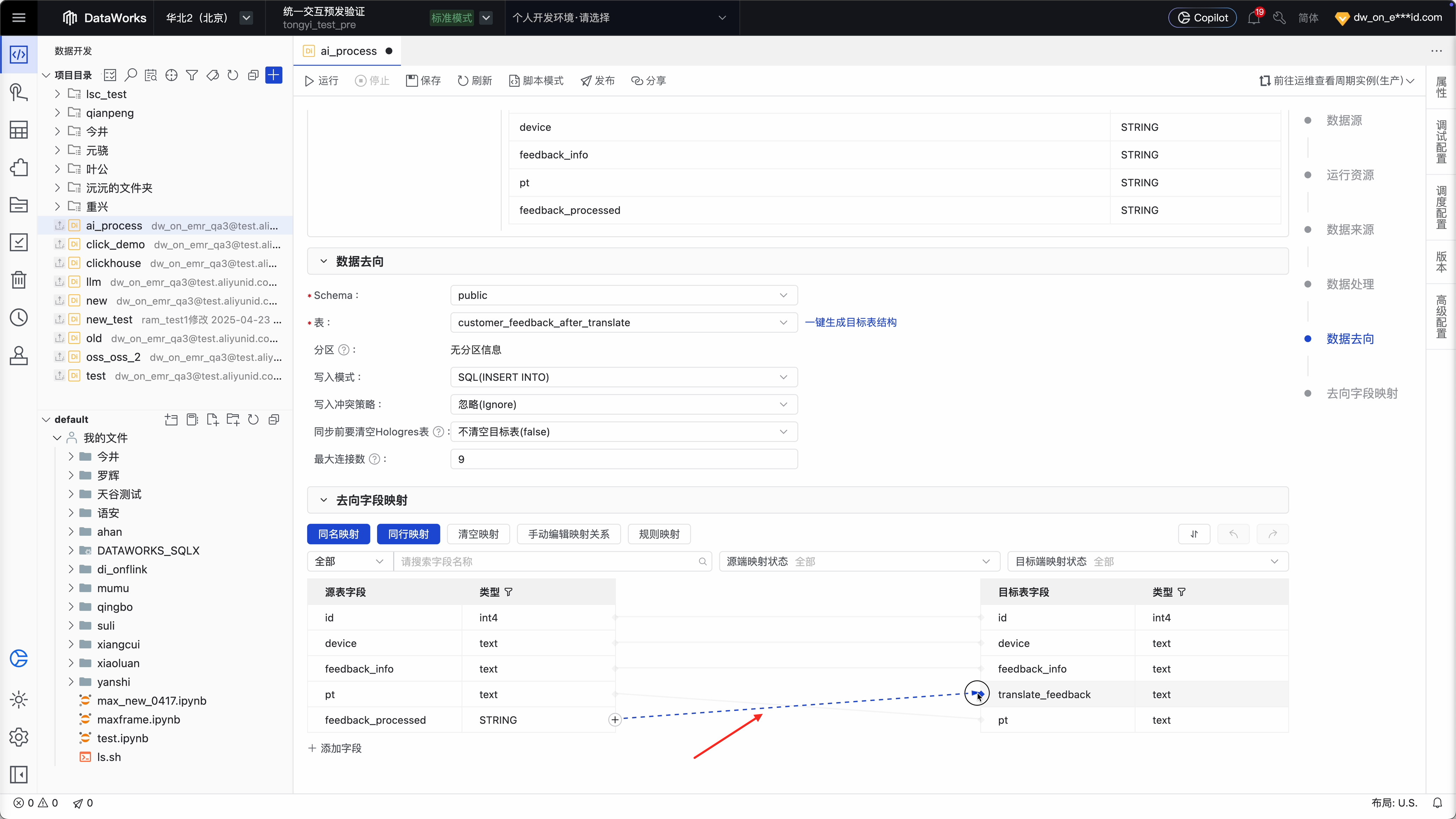
至此已完成所有配置,保存提交发布即可!
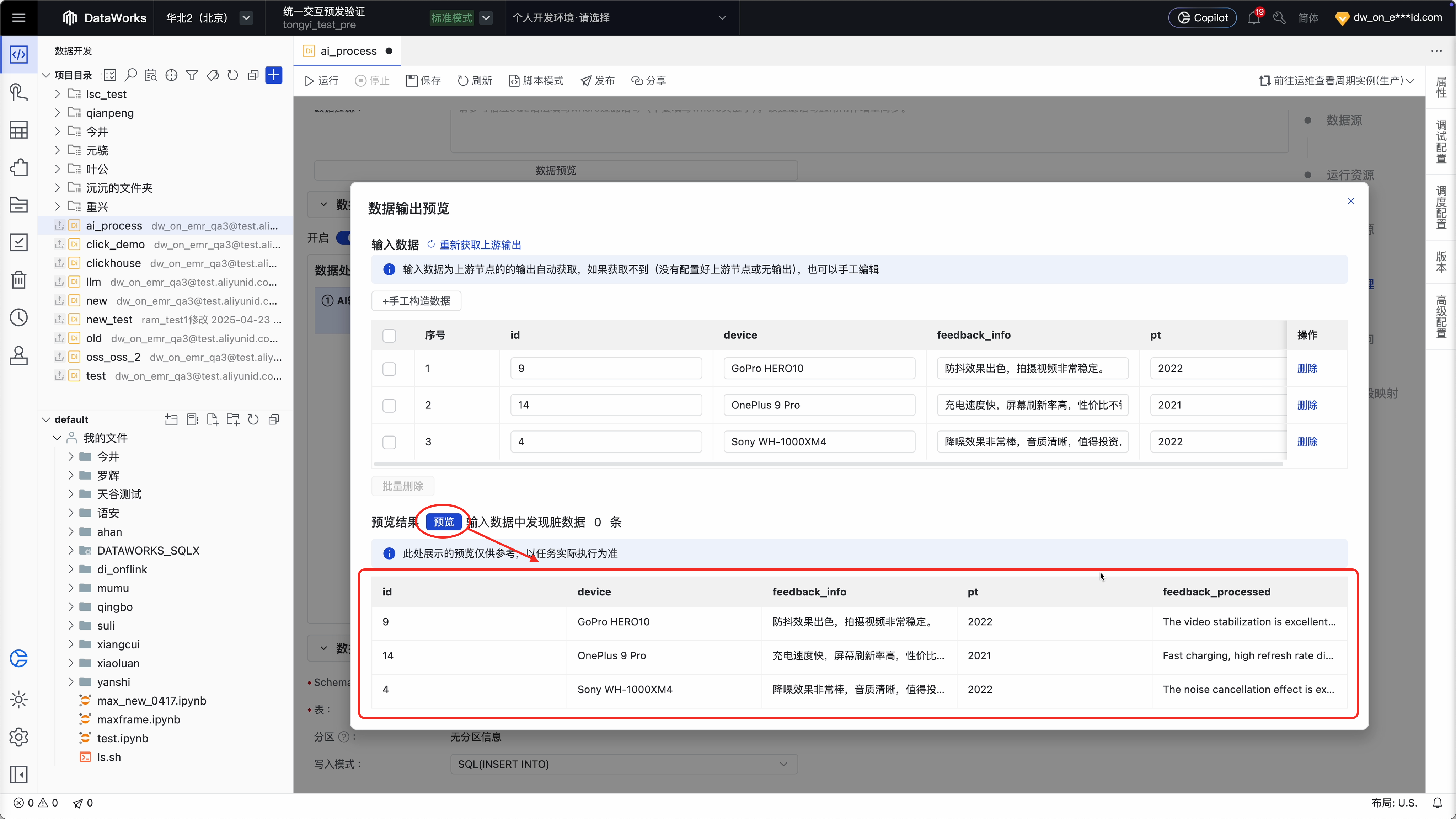
当然,也可以在发布前通过“数据输出预览”,提前查看是否运行正