操作系统导论 第38章:廉价冗余磁盘阵列(RAID)
关键问题:如何得到大型、快速、可靠的磁盘
我们如何构建一个大型、快速和可靠的存储系统?关键技术是什么?不同方法之间的折中是什么?
本章将介绍廉价冗余磁盘阵列(Redundant Array of Inexpensive Disks),更多时候称为 RAID,这种技术使用多个磁盘一起构建更快、更大、更可靠的磁盘系统。
从外部看,RAID 看起来像一个磁盘:一组可以读取或写入的块。在内部,RAID 是一个复杂的庞然大物,由多个磁盘、内存(包括易失性和非易失性)以及一个或多个处理器来管理系统。硬件 RAID 非常像一个计算机系统,专门用于管理一组磁盘。
与单个磁盘相比,RAID 具有许多优点。一个好处就是性能。并行使用多个磁盘可以大大加快 I/O 时间。另一个好处是容量。大型数据集需要大型磁盘。最后,RAID可以提高可靠性。在多个磁盘上传输数据(无RAID技术)会使数据容易受到单个磁盘丢失的影响。通过某种形式的冗余(redundancy),RAID 可以容许损失一个磁盘并保持运行,就像没有错误一样。
令人惊讶的是,RAID 为使用它们的系统透明地(transparently)提供了这些优势,即 RAID 对于主机系统看起来就像一个大磁盘。当然,透明的好处在于它可以简单地用 RAID 替换磁盘,而不需要更换一行软件。操作系统和客户端应用程序无须修改,就可以继续运行。通过这种方式,透明极大地提高了 RAID 的可部署性(deployability),使用户和管理员可以使用 RAID,而不必担心软件兼容性问题。
一、接口和 RAID 内部
对于上面的文件系统,RAID 看起来像是一个很大的、(我们希望是)快速的、并且(希 望是)可靠的磁盘。就像使用单个磁盘一样,它将自己展现为线性的块数组,每个块都可以由文件系统(或其他客户端)读取或写入。
当文件系统向 RAID 发出逻辑 I/O 请求时,RAID 内部必须计算要访问的磁盘(或多个磁盘)以完成请求,然后发出一个或多个物理 I/O 来执行此操作。这些物理 I/O 的确切性质取决于 RAID级别,将在下面详细讨论。但是,举一个简单的例子,考虑一个 RAID, 它保留每个块的两个副本(每个都在一个单独的磁盘上)。当写入这种镜像(mirrored)RAID 系统时,RAID 必须为它发出的每一个逻辑 I/O 执行两个物理 I/O。
RAID 系统通常构建为单独的硬件盒,并通过标准连接(例如,SCSI 或 SATA)接入主机。然而,在内部,RAID 相当复杂。它包括一个微控制器,运行固件以指导 RAID 的操作。 它还包括DRAM 这样的易失性存储器,在读取和写入时缓冲数据块。在某些情况下,还包括非易失性存储器,安全地缓冲写入。它甚至可能包含专用的逻辑电路,来执行奇偶校验计算(在某些 RAID 级别中非常有用)。在很高的层面上,RAID是一个非常专业的计算机系统:它有一个处理器,内存和磁盘。然而,它不是运行应用程序,而是运行专门用于操作 RAID 的软件。
二、故障模型
理解并比较 RAID 的不同,考虑故障模型。RAID 旨在检测并从某些模型的磁盘故障恢复。因此,准确地知道哪些故障对于实现工作设计至关重要。
第一个故障模型非常简单,称为“ 故障—停止(fail-stop)” 故障模型。在这种模式下,磁盘可以处于两种状态之一:工作状态或故障状态。使用工作状态的磁盘时,所有块都可以读取或写入。相反,当磁盘出现故障时,我们认为它永久丢失。
故障—停止模型的一个关键方面是它关于故障检测的假定。具体来说,当磁盘发生故障时,认为这很容易检测到。例如,在 RAID 阵列中,假设 RAID 控制器硬件(或软件)可以立即观察磁盘何时发生故障。
因此,暂时不必担心更复杂的“无声”故障,如磁盘损坏。也不必担心在其他工作磁盘上无法访问单个块(有时称为潜在扇区错误)。稍后会考虑这些更复杂的(遗憾的是,更现实的)磁盘错误。
三、如何评估 RAID
从3个方面评估每种 RAID 设计。第一个方面是容量(capacity)。在给定一组 N 个磁盘的情况下,RAID 的客户端可用的容量有多少?没有冗余,答案显然是 N。 不同的是,如果有一个系统保存每个块的两个副本,我们将获得 N/2 的有用容量。不同的方案(例如,基于校验的方案)通常介于两者之间。
第二个方面是可靠性(reliability)。给定设计允许有多少磁盘故障?根据故障模型,我们只假设整个磁盘可能会故障。在后面的章节(例如,关于数据完整性的第44章) 中,我们将考虑如何处理更复杂的故障模式。
最后,第三个方面是性能(performance)。性能有点难以评估,因为它在很大程度上取决于磁盘阵列提供的工作负载。因此,在评估性能之前,将首先提出一组应该考虑的典型工作负载。
现在考虑 3 个重要的 RAID 设计:RAID 0级(条带化),RAID 1级(镜像)和 RAID 4/5 级(基于奇偶校验的冗余)。这些设计中的每一个都被命名为一“级 ”。
四、RAID 0级:条带化
第一个 RAID 级别实际上不是 RAID 级别,因为没有冗余。但是,RAID 0级(即条带化,striping)因其更为人所知,可作为性能和容量的优秀上限。
最简单的条带形式将按 表38.1 所示的方式在系统的磁盘上将块条带化(stripe),假设此处为 4 个磁盘阵列。
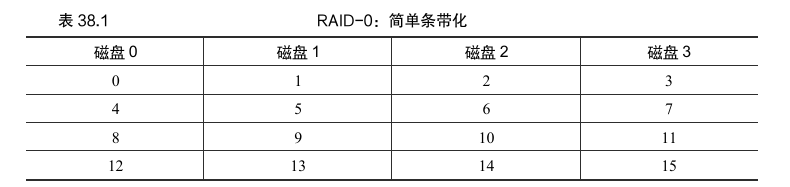
通过表 38.1,基本思想: 以轮转方式将磁盘阵列的块分布在磁盘上。这种方法的目的是在对数组的连续块进行请求时,从阵列中获取最大的并行性(例如,在一个大的顺序读取中)。将同一行中的块称为条带,因此,上面的块0、1、2和3在相同的条带中。
在这个例子中,做了一个简化的假设,在每个磁盘上只有1个块(每个大小为4KB) 放在下一个磁盘上。但是,这种安排不是必然的。例如,我们可以像 表38.2 那样在磁盘上安排块。
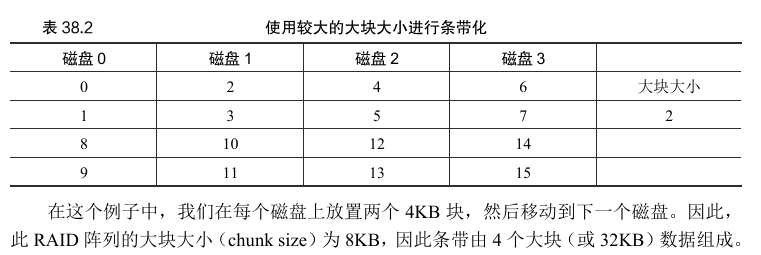
大块大小
一方面,大块大小主要影响阵列的性能。例如,较小的大块意味着许多文件将跨多个磁盘进行条带化,从而增加了对单个文件的读取和写入的并行性。但是,跨多个磁盘访问块的定位时间会增加,因为整个请求的定位时间由所有驱动器上请求的最大定位时间决定。
另一方面,较大的大块减少了这种文件内的并行性,因此依靠多个并发请求来实现高吞吐量。但是,较大的大块大小减少了定位时间。例如,如果一个文件放在一个块中并放置在单个磁盘上,则访问它时发生的定位时间将只是单个磁盘的定位时间。
因此,确定“ 最佳 ”的大块大小是很难做到的(并行性与定位时间的考虑),因为它需要大量关于提供给磁盘系统的工作负载的知识。
回到 RAID-0 分析
评估条带化的容量、可靠性和性能。从容量的角度来看,它是顶级的:给定 N 个磁盘,条件化提供 N 个磁盘的有用容量。从可靠性的角度来看,条带化是顶级糟糕:任何磁盘故障都会导致数据丢失。最后,性能非常好:通常并行使用所有磁盘来为用户 I/O 请求提供服务 。
评估 RAID 性能
在分析 RAID 性能时,可以考虑两种不同的性能指标。首先是单请求延迟。了解单个 I/O 请求对 RAID 的满意度非常有用,因为它可以揭示单个逻辑 I/O 操作期间可以存在多少并行性。第二个是 RAID 的稳态吞吐量,即许多并发请求的总带宽。由于 RAID 常用于高性能环境,因此稳态带宽至关重要,因此将成为我们分析的主要重点。
为了更详细地理解吞吐量,提出一些工作负载。假设有两种类型的工作负载:顺序(sequential)和 随机(random)。对于顺序的工作负载,假设对阵列的请求大部分是连续的。例如,一个请求(或一系列请求)访问 1MB 数据,始于块(B),终于(B+1MB),这被认为是连续的。顺序工作负载在很多环境中都很常见(想想在一个大文件中搜索关键字),因此被认为是重要的。
对于随机工作负载,我们假设每个请求都很小,并且每个请求都是到磁盘上不同的随机位置。例如,随机请求流可能首先在逻辑地址10 处访问 4KB,然后在逻辑地址 550000 处访问,然后在 20100 处访问,等等。一些重要的工作负载(例如数据库管理系统(DBMS)上的事务工作负载)表现出这种类型的访问模式,因此它被认为是一种重要的工作负载。
真正的工作负载并不是那么简单,往往混合了顺序和类似随机的部分,行为介于两者之间。
顺序和随机工作负载会导致磁盘的性能特征差异很大。对于顺序访问,磁盘以最高效的模式运行,花费很少时间寻道并等待旋转,大部分时间都在传输数据。对于随机访问,情况恰恰相反:大部分时间花在寻道和等待旋转上,花在传输数据上的时间相对较少。为了在分析中捕捉到这种差异,将假设磁盘可以在连续工作负载下以 S MB/s传输数据,并且在随机工作负载下以 R MB/s传输数据。一般来说,S 比 R 大得多。
理解这些差异,做一个简单联系。具体来说,给定以下磁盘特征,计算 S 和 R。假设平均大小为 10MB 的连续传输,平均为 10KB 的随机传输。另外,假设以下磁盘特征:

计算 S,需要首先计算在典型的 10MB 传输中花费的时间。首先,花 7ms 寻找,然后 3ms 旋转。最后,传输开始。10MB @ 50MB/s导致 1/5s,即 200ms 的传输时间。 因此,对于每个10MB 的请求,花费了 210ms 完成请求。要计算S,只需要除一下:


再此回到 RAID-0 分析
评估条带化的性能,如上面所说,通常很好。例如,从延迟角度来看,单块请求的延迟应该与单个磁盘的延迟几乎相同。毕竟,RAID-0 将简单地将该请求重定向到其磁盘之一。
从稳态吞吐量的角度来看,期望获得系统的全部带宽。因此,吞吐量等于 N(磁盘数量)乘以 S(单个磁盘的顺序带宽)。对于大量的随机 I/O,可以再次使用所有的磁盘, 从而获得 N·R MB/s 。这些值都是最简单的计算值,并且将作为与其他 RAID 级别比较的上限。
五、RAID 1级:镜像
第一个超越条带化的 RAID 级别称为 RAID 1级,即镜像。对于镜像系统,只需生成系统中每个块的多个副本。当然,每个副本应该放在一个单独的磁盘上。通过这样做,可以容许磁盘故障。
在一个典型的镜像系统中,将假设对于每个逻辑块,RAID 保留两个物理副本。表38.3为例
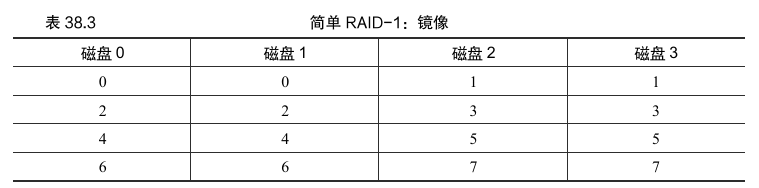
在这个例子中,磁盘0 和 磁盘1 具有相同的内容,而 磁盘2 和 磁盘3 也具有相同的内容。数据在这些镜像对之间条带化。实际上,有多种不同的方法可以在磁盘上放置块副本。上面的安排是常见的安排,有时称为 RAID-10(或RAID 1+0),因为它使用镜像对(RAID-1),然后在其上使用条带化(RAID-0)。另一种常见安排是 RAID-01(或 RAID 0+1),它包含两个大型条带化(RAID-0)阵列,然后是镜像(RAID-1)。目前, 讨论只是假设上面布局的镜像。
从镜像阵列读取块时,RAID 有一个选择:它可以读取任一副本。例如,如果对 RAID 发出对 逻辑块5 的读取,则可以自由地从 磁盘2 或 磁盘3 读取它。但是,在写入块时,不存在这样的选择:RAID 必须更新两个副本的数据,以保持可靠性。但请注意,这些写入可以并行进行。例如,对 逻辑块5 的写入可以同时在 磁盘2 和 3上进行。
RAID-1分析
评估一下RAID-1。从容量的角度来看,RAID-1 价格昂贵。在镜像级别=2的情况下,我们只能获得峰值有用容量的一半。因此,对于 N 个磁盘,镜像的有用容量为 N/2。
从可靠性的角度来看,RAID-1 表现良好。它可以容许任何一个磁盘的故障。想象一下,在表38.3中,磁盘 0 和磁 盘2都故障了。在这种情况下,没有数据丢失!更一般地说,镜像系统(镜像级别为2)肯定可以容许一个磁盘故障,最多可容许 N/2个磁盘故障,这取决于哪些磁盘故障。因此,大多数人认为镜像对于处理单个故障是很好的。
最后,分析性能。从单个读取请求的延迟角度来看,我们可以看到它与单个磁盘上的延迟相同。所有 RAID-1 都会将读取导向一个副本。写入有点不同:在完成写入之前, 需要完成两次物理写入。这两个写入并行发生,因此时间大致等于单次写入的时间。然而, 因为逻辑写入必须等待两个物理写入完成,所以它遭遇到两个请求中最差的寻道和旋转延迟,因此(平均而言)比写入单个磁盘略高。
分析稳态吞吐量,从顺序工作负载开始。顺序写入磁盘时,每个逻辑写入必定导致两个物理写入。例如,当我们写入逻辑块 0(在表38.3中)时,RAID 在内部会将它写入 磁盘0 和 磁盘1。因此,可以得出结论,顺序写入镜像阵列期间获得的最大带宽是(N/2 *S),即峰值带宽的一半。
在顺序读取过程中获得了完全相同的性能。有人可能会认为顺序读取可能会更好,因为它只需要读取一个数据副本,而不是两个副本。但是,让我们用一个例子来说明为什么这没有多大帮助。想象一下,我们需要读取块0、1、2、3、4、5、6和7。 假设我们将 0 读到 磁盘0,将 1 读到磁盘2,将2读到磁盘1,读取3到磁盘3。继续分别向磁盘0、2、1和3发出读取请求4、5、6和7。有人可能天真地认为,因为我们正在利用所有磁盘,所以得到了阵列的全部带宽。
但是,要看到情况并非如此,请考虑单个磁盘接收的请求(例如磁盘 0)。首先,它收到 块0的请求。然后,它收到块4的请求(跳过块2)。实际上,每个磁盘都会接收到每个其他块的请求。当它在跳过的块上旋转时,不会为客户提供有用的带宽。因此,每个磁盘只能提供一半的峰值带宽。因此,顺序读取只能获得 (N/2*S)MB/s 的带宽。
随机读取是镜像RAID的最佳案例。在这种情况下,可以在所有磁盘上分配读取数据,从而获得完整的可用带宽。因此,对于随机读取,RAID-1 提供N·R MB/s。
最后,随机写入按照你预期的方式执行: N/2·R MB/s。每个逻辑写入必须变成两个物理写入,因此在所有磁盘都将被使用的情况下,客户只会看到可用带宽的一半。尽管对逻辑块X 的写入变为对两个不同物理磁盘的两个并行写入,但许多小型请求的带宽只能达到我们看到的条带化的一半。
六、RAID 4级:通过奇偶校验节省空间