vision transformer图像分类模型结构介绍
Vision Transformer (ViT) 是一种基于纯Transformer架构的图像分类模型,由Google Research在2020年提出(论文《An Image is Worth 16x16 Words》)。
它将图像分割为固定大小的图像块(patches),通过线性嵌入和位置编码后,像处理NLP中的单词序列一样输入Transformer编码器进行分类。以下是ViT的详细结构解析:
1. 整体架构
ViT的核心思想是将图像视为一个由局部块(patch)组成的序列,通过标准的Transformer编码器处理这些块,最后用分类头(MLP)输出类别概率。
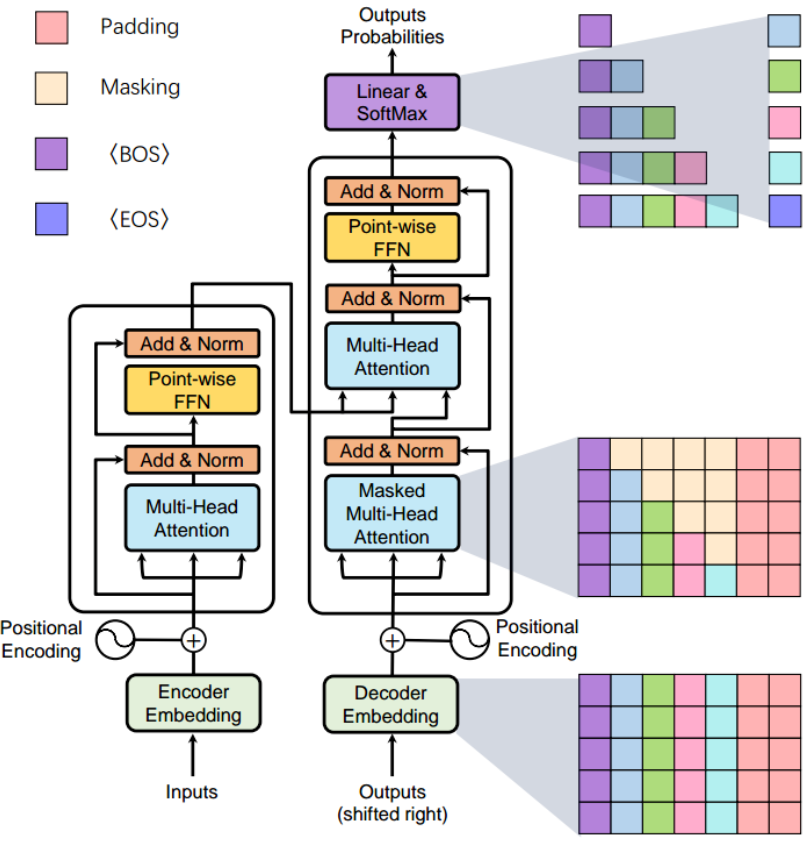
其结构分为以下主要模块:
1.1 图像分块(Patch Partition)
-
输入图像:假设输入为
H × W × C(如224×224×3)。 -
分块处理:将图像划分为
N个大小为P × P的非重叠块(默认P=16),得到N = (H×W)/P²个块(如224×224→14×14=196个16×16的块)。 -
展平:每个块展平为
P²×C的向量(16×16×3=768维)。
1.2 线性投影(Patch Embedding)
-
可学习矩阵:通过线性层(
D维,如768)将每个块映射为嵌入向量(Patch Embeddings)。 -
输出:得到
N × D的序列(196×768)。
1.3 分类令牌(Class Token)
-
附加令牌:在序列开头插入一个可学习的
[class]令牌(1 × D),用于聚合全局信息(类似BERT的[CLS])。 -
输出序列:
(N+1) × D(197×768)。
1.4 位置编码(Position Embedding)
-
位置信息:为每个块添加可学习的1D位置编码(与Patch Embeddings同维度),保留空间顺序。
-
方式:直接相加(
Embedding + Position)。
2. Transformer编码器
由 L 个相同的Transformer层堆叠而成(如ViT-Base为12层),每层包含:
2.1 多头自注意力(MSA)
-
输入:
(N+1) × D的序列。 -
自注意力:计算查询(Q)、键(K)、值(V)的注意力权重,捕捉块间关系。
-
多头机制:将Q/K/V拆分为
h个头(如12头),并行计算后拼接。
2.2 层归一化(LayerNorm)
-
应用于MSA和前馈网络(MLP)之前(Pre-Norm结构)。
2.3 多层感知机(MLP)
-
结构:两层全连接,中间用GELU激活。
-
扩展比:通常隐藏层维度为
4D(如3072)。
2.4 残差连接(Residual Connection)
-
每个子层(MSA、MLP)均有残差连接,缓解梯度消失。
3. 分类头(MLP Head)
-
输入:仅取
[class]令牌对应的输出(1 × D)。 -
结构:轻量级MLP(通常一层LayerNorm + 全连接)。
-
输出:类别概率(如ImageNet-1k为1000维)。
4. 关键细节
4.1 位置编码方式
-
可学习参数:ViT默认使用可训练的1D位置编码,后续研究(如Swin Transformer)探索了相对位置编码或2D编码。
4.2 归纳偏置(Inductive Bias)
-
局部性缺失:ViT缺乏CNN固有的平移不变性和局部性,依赖大量数据(需在JFT-300M等大数据集预训练后迁移)。
4.3 混合结构(Hybrid Architecture)
-
CNN+ViT:可用CNN backbone(如ResNet)提取特征图后再分块输入Transformer,提升小数据集表现。
5. 常见变体
| 模型 | 层数 (L) | 隐藏层 (D) | 头数 (h) | MLP尺寸 | 参数量 |
|---|---|---|---|---|---|
| ViT-Tiny | 12 | 192 | 3 | 768 | ~5M |
| ViT-Small | 12 | 384 | 6 | 1536 | ~22M |
| ViT-Base | 12 | 768 | 12 | 3072 | ~86M |
| ViT-Large | 24 | 1024 | 16 | 4096 | ~307M |
6. 优缺点
-
优点:
-
全局建模能力:自注意力机制捕捉长程依赖。
-
可扩展性:堆叠更多层或增大D/h可提升性能。
-
-
缺点:
-
计算复杂度高:序列长度随图像分辨率平方增长。
-
数据依赖性强:小数据易过拟合,需预训练。
-
7. 代码示例(PyTorch风格)
import torch
import torch.nn as nnclass ViT(nn.Module):def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dim=768, depth=12, num_heads=12):super().__init__()self.num_patches = (img_size // patch_size) ** 2self.patch_embed = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))self.pos_embed = nn.Parameter(torch.zeros(1, self.num_patches + 1, embed_dim))self.blocks = nn.ModuleList([nn.TransformerEncoderLayer(d_model=embed_dim, nhead=num_heads, dim_feedforward=4*embed_dim) for _ in range(depth)])self.head = nn.Linear(embed_dim, num_classes)def forward(self, x):x = self.patch_embed(x) # [B, D, H/P, W/P]x = x.flatten(2).transpose(1, 2) # [B, N, D]cls_token = self.cls_token.expand(x.shape[0], -1, -1)x = torch.cat((cls_token, x), dim=1) # [B, N+1, D]x = x + self.pos_embedfor blk in self.blocks:x = blk(x)cls_out = x[:, 0] # [class] tokenreturn self.head(cls_out)总结
ViT通过将图像转化为序列数据并应用标准Transformer,突破了CNN在视觉任务中的主导地位。
其核心创新在于分块嵌入和全局自注意力机制,但需注意其对数据规模和计算资源的要求。
后续的DeiT、Swin Transformer等模型进一步优化了效率和性能。