线性回归之多项式升维
文章目录
- 多项式升维简介
- 简单案例
- 实战案例
- 多项式升维优缺点
多项式升维简介
-
多项式升维(Polynomial Expansion)是线性回归中一种常用的特征工程方法,它通过将原始特征进行多项式组合来扩展特征空间,从而让线性模型能够拟合非线性关系。
-
标准的线性回归模型形式为:
y = w 0 + w 1 x 1 + w 2 x 2 + . . . + w n x n + ε y = w₀ + w₁x₁ + w₂x₂ + ... + wₙxₙ + ε y=w0+w1x1+w2x2+...+wnxn+ε -
多项式升维通过创建原始特征的高次项和交互项来扩展模型:
y = w 0 + w 1 x + w 2 x 2 + . . . + w d x d + ε y = w₀ + w₁x + w₂x² + ... + w_dx^d + ε y=w0+w1x+w2x2+...+wdxd+ε -
升维的目的是为了解决欠拟合的问题(提高模型的准确率),因为当维度不够时,对于预测结果考虑的因素不足,不能准确的计算出模型。
-
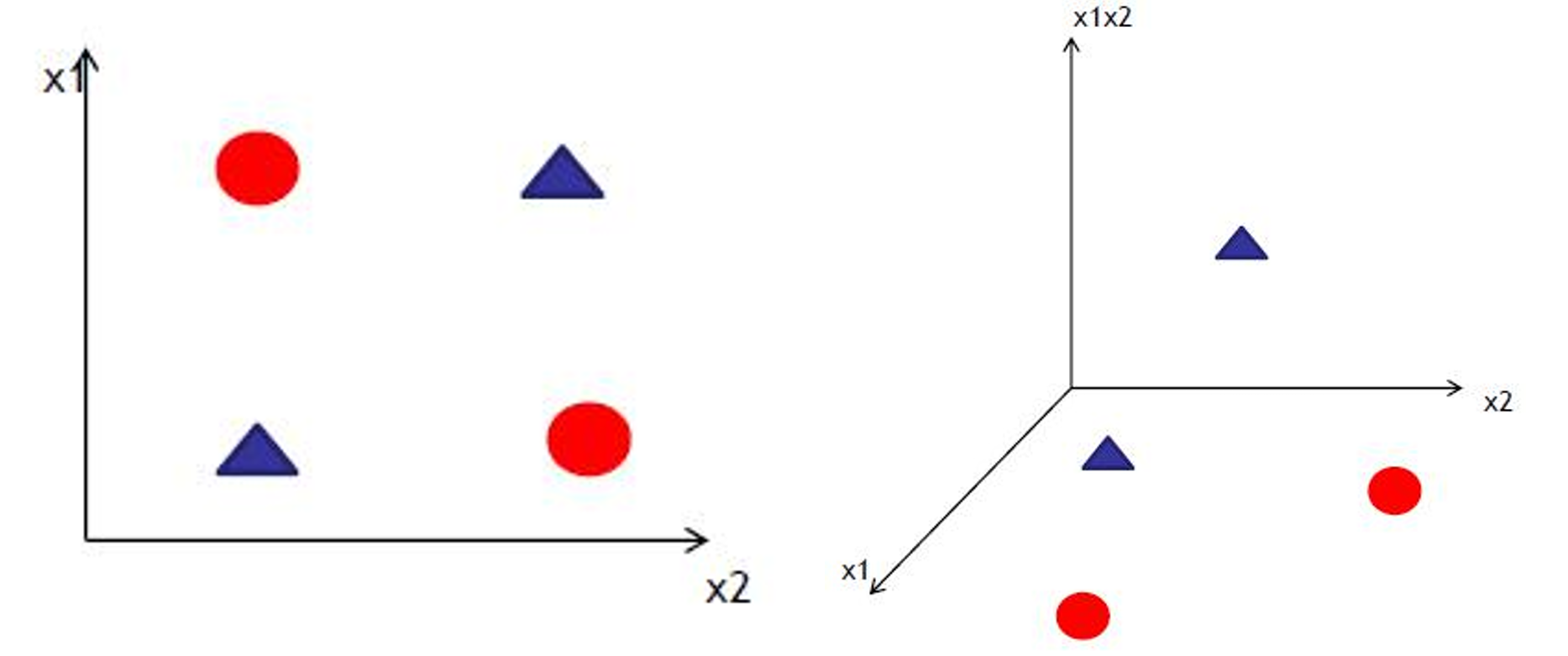
在做升维的时候,最常见的手段就是将已知维度进行相乘来构建新的维度,如下图所示。下图左展示的是线性不可分的情况,下图右通过升维使得变得线性可分。
-
多项式回归是机器学习中一种特殊的升维技术,虽然它可以被视为一种算法,但和归一化类似,通常被归类为数据预处理手段。在scikit-learn库中,它被放置在
sklearn.preprocessing模块下。其核心原理是通过将原始特征进行组合(包括特征自身的乘积),生成二阶或更高阶的新特征,从而扩展特征空间。 -
命名为"回归"的原因主要源于它常与线性回归配合使用。标准的线性回归模型旨在捕捉X和y之间的线性关系,但当数据呈现非线性特征时,我们有两种解决方案:
- 改用非线性模型(如回归树、神经网络等)直接拟合数据
- 坚持使用线性模型,但通过特征工程将数据转化为线性可分的形态
- 线性模型具有计算效率高的显著优势。通过多项式升维,我们既保留了线性模型的快速计算特性,又使其能够适应更复杂的数据分布。以医疗费用预测为例:当用年龄预测医疗支出时,若费用随年龄呈二次曲线增长(老年人医疗成本加速上升),简单的线性关系无法准确描述,这时多项式特征就能有效捕捉这种非线性模式。
Data 数据-->Algorithm 算法-->Model模型
Data 线性-->Algorithm 线性-->Model Good
Data 非线性-->Algorithm 非线性-->Model Good
Data 非线性-->Algorithm 线性-->Model Bad
Data 非线性-->Data线性--Algorithm 线性-->Model Good
y ^ = w 0 + w 1 x 1 + w 2 x 2 \hat y=w_0+w_1x_1+w_2x_2 y^=w0+w1x1+w2x2
y ^ = w 0 + w 1 x 1 + w 2 x 2 + w 3 x 1 2 + w 4 x 2 2 + w 5 x 1 x 2 \hat y=w_0+w_1x_1+w_2x_2+w_3x_{1}^{2}+w_4x_{2}^{2}+w_5x_1x_2 y^=w0+w1x1+w2x2+w3x12+w4x22+w5x1x2
简单案例
- 单变量多项式回归
from sklearn.preprocessing import PolynomialFeatures
import numpy as np# 假设我们有单变量数据
X = np.array([1, 2, 3, 4, 5]).reshape(-1, 1)# 创建二次多项式特征
poly = PolynomialFeatures(degree=2)
X_poly = poly.fit_transform(X)
- 多变量多项式回归
# 假设有双变量数据
X = np.array([[1, 2], [3, 4], [5, 6]])# 创建二次多项式特征(包括交互项)
poly = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly.fit_transform(X)
实战案例
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error# 设置支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falsenp.random.seed(42)
m = 1000
X = 6 * np.random.rand(m, 1) - 3
Y = 0.5 * X ** 2 + X + 2 + np.random.randn(m, 1)# 数据集的划分 训练集和测试集
X_train = X[:800]
X_test = X[800:]
Y_train = Y[:800]
Y_test = Y[800:]# 真实数据
plt.plot(X, Y, 'b.', label='真实数据')
plt.title("真实数据分布")
plt.xlabel("特征值 X")
plt.ylabel("目标值 Y")
plt.legend()
# plt.show()# 构建字典 保证后面使用一阶、二阶、十阶多项回归的时候可以使用不同的图示
my_dict = {1: 'g-', 2: 'r+', 10: 'y*'}# 循环执行 数据预处理、模型训练、模型评估
for i in my_dict:ploy_feature = PolynomialFeatures(degree=i, include_bias=True)X_poly_train = ploy_feature.fit_transform(X_train)X_poly_test = ploy_feature.fit_transform(X_test)print(f"第{i}阶的多项式回归")print('原始数据集')print(X_train[0])print("升维数据集", )print(X_poly_train[0])print('原始数据集维度')print(X_train.shape)print('升维数据集维度')print(X_poly_train.shape)lin_reg = LinearRegression(fit_intercept=False)lin_reg.fit(X_poly_train, Y_train)print(lin_reg.intercept_, lin_reg.coef_)Y_train_predict = lin_reg.predict(X_poly_train)Y_test_predict = lin_reg.predict(X_poly_test)plt.plot(X_train, Y_train_predict, my_dict[i], label=f'{i}阶拟合曲线')print("训练集的均方误差")print(mean_squared_error(Y_train, Y_train_predict))print("测试集的均方误差")print(mean_squared_error(Y_test, Y_test_predict))print("======")plt.title(f"多项式回归拟合结果 (最高阶数: {max(my_dict.keys())})")
plt.xlabel("特征值 X")
plt.ylabel("目标值 Y")
plt.legend()
plt.show()# 新增: 绘制检验效果模型的图标
plt.figure(figsize=(12, 6))
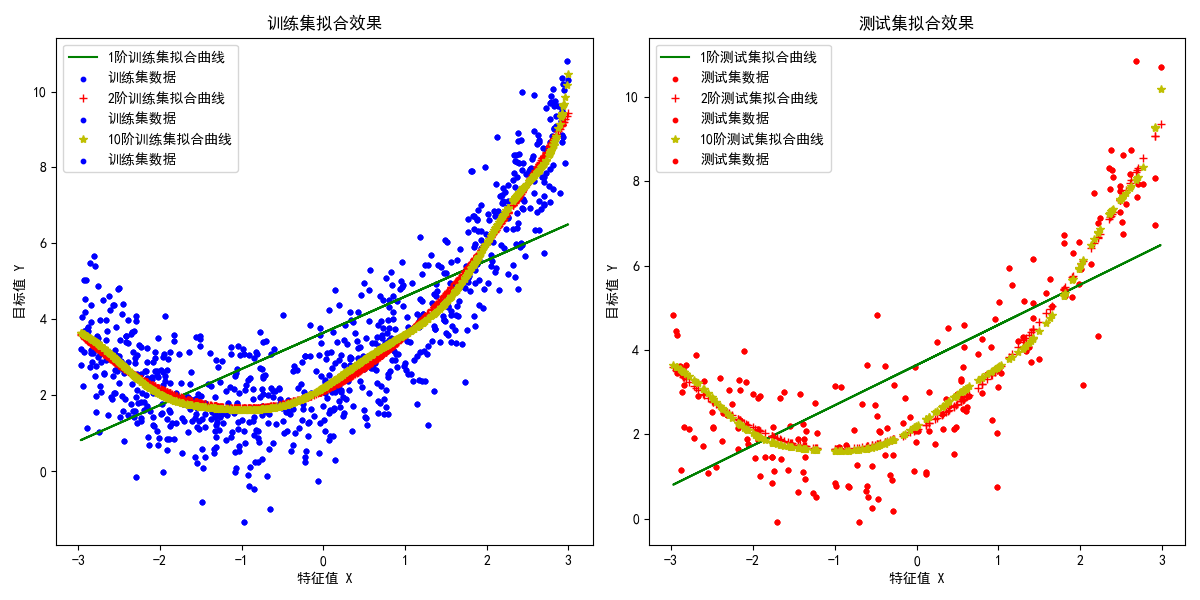
for i in my_dict:ploy_feature = PolynomialFeatures(degree=i, include_bias=True)X_poly_train = ploy_feature.fit_transform(X_train)X_poly_test = ploy_feature.fit_transform(X_test)lin_reg = LinearRegression(fit_intercept=False)lin_reg.fit(X_poly_train, Y_train)Y_train_predict = lin_reg.predict(X_poly_train)Y_test_predict = lin_reg.predict(X_poly_test)# 训练集和测试集的拟合曲线plt.subplot(1, 2, 1)plt.plot(X_train, Y_train_predict, my_dict[i], label=f'{i}阶训练集拟合曲线')plt.scatter(X_train, Y_train, color='blue', s=10, label='训练集数据')plt.subplot(1, 2, 2)plt.plot(X_test, Y_test_predict, my_dict[i], label=f'{i}阶测试集拟合曲线')plt.scatter(X_test, Y_test, color='red', s=10, label='测试集数据')plt.subplot(1, 2, 1)
plt.title("训练集拟合效果")
plt.xlabel("特征值 X")
plt.ylabel("目标值 Y")
plt.legend()plt.subplot(1, 2, 2)
plt.title("测试集拟合效果")
plt.xlabel("特征值 X")
plt.ylabel("目标值 Y")
plt.legend()plt.tight_layout()
plt.show()
多项式升维优缺点
优点:
- 拟合非线性关系:让线性模型能够捕捉数据中的非线性模式
- 灵活性:通过调整degree参数控制模型的复杂度
- 保持线性模型优势:仍然可以使用正规方程等线性回归的优化方法
缺点:
- 维度灾难:随着特征数量和degree增加,特征空间会急剧膨胀
- 过拟合风险:高阶多项式容易过拟合训练数据
- 外推性能差:多项式模型在训练数据范围外的预测可能不可靠