【周输入】517周阅读推荐-3
前文
【周输入】510周阅读推荐-1-CSDN博客
【周输入】510周阅读推荐-2-CSDN博客
【周输入】510周阅读推荐-3-CSDN博客
【周输入】517周阅读推荐-1-CSDN博客
【周输入】517周阅读推荐-2-CSDN博客
本次推荐
Agent是当前快速发展的核心方案,今天阅读阿里云技术公共号的Agent相关文章,有理论有实操,指导性强,非常详细。
技术方案
如何让 Agent 规划调用工具
文章核心观点
为什么要在调用工具(function call)的时候,需要规划:能提升工具调用效果
(OpenAI使用Prompt引导模型思考+后训练提升这一指令遵循/Anthropic让模型调用思考工具,提供示例,并在调用前后思考)
文章中方案选择思考工具形式(工具调用有更结构化的输出;工具调用相对于做规划plan指令更加明确可评判)
其中,相对提升/绝对提升,pass@1等指标,相对于类Manus(规划和执行解耦,规划能力会更好,但是适用于几分分钟的长程任务),本方案适合快速任务
实现方案:
思考和规划工具:(1)模型选择规划和工具调用能力较强的DS V3,支持并行工具调用;(2)使用端到端模式:即模型会被反复调用,除非模型不再调用工具直接回复,模型调用次数到上限;思考和规划工具,参数配置已公开,对应的prompt也已经公开;
其中并行调用配置,即在模型的一次调用中调用多个工具,适合调用没有依赖关系的多个工具。注意:并行工具和串行工具,对模型的智能有要求;
业务工具:按照需求选择业务工具;业务prompt;
注意:参照Anthropic的建议,工具定义和规范,需要和整体提示词一样受到提示工程的高度重视,即打造良好的智能体-计算机接口 ACI。甚至实际可能会投入更多精力优化工具而非整体提示词;
规范
1,站在模型调用角度思考,是否一目了然,是否需要仔细斟酌(示例、边界情况、输入格式要求,和其它工具的区分)
2,参数名和描述是否清晰;(特别是多工具调用情况)
3,大量输入示例,观察模型可靠性;
4,防呆设计:参数设置,降低犯错;
方案对比
【直接推理模型】vs【非推理模型+思考工具】,Anthropic实验结构表明,后者更好。
原因猜测:(1)推理模型思维链的空间是由模型自由探索的,prompt无法干预推理模型输出的思维链,后训练一般针对最终输出的结果进行提升效果质量(2)推理模型的历史思考内容会在上下文中删掉(根据Claude文档仅保留第一次调用工具前输出的思考内容,后续不再打开思考)
我的思考
1,规划的重要是新一代AI OS的核心能力,在OS成熟起来之前,一些早期的产品落地方案,需要根据业务情况(长程任务/短程任务,相应时间要求等等),进行方案设计;
2,对比评测思维,潜在方案对比,文章有2个例子:(1)prompt引导模型和tool use方案,进行思考和规划,明确的优缺点;(2)推理模型直接思考和规划和非推理模型调用思考规划工具的对比;大模型微调知识与实践分享
文章核心观点
介绍大模型基础知识
模型结构:Attention is All you Need文章,介绍transformer,Encoder(一个Multi-Header Attention/Decoder(2个Multi-Header Attention);
模型参数:B的参数大小;和计算法则:L层数*(12*h隐藏层数*h+13h)+V词表大小*h,h很大时,12Lh*h;
模型显存:M=1.2*(P参数量*4每个参数的字节数)/(32/Q),即INT8量化直接等于P*1.2;
模型存储:P*2
Prompt:在微调之前,基于base模型优化prompt和fewshot探索模型能力边界,能否解决现有问题;效果保证后,微调得到更加稳定的效果和更小的size部署要求;
数据构造:
含有特征的数据决定了机器学习的上限,模型和算法只是逼近这个上限而已;
self-instruct介绍:核心思想是通过建立种子集,然后prompt模型输出目标格式的数据,通过后置ROUGE-L等筛选方法去重,不断的加入种子集合,来提升产出数据的多样性和质量。关注数据的质量和丰富度;
生成的数据是否符合预期,有先验的判断:规则+模型和人做数据验证;
关注数据分布关系,产生不同任务的高质量数据;
全参数微调成本高,PEFT (Parameter-Efficient Fine-Tuning),对一部分参数进行微调,结果和全参数微调接近;
Lora微调:核心思想就是通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练。(秩是矩阵中最长的独立行数或列数)
强化学习:在SFT模型的基础做强化学习的训练往往会提升模型的表现。
DPO:DPO的优化目的可以理解为通过训练, 最大化正样本上的奖励 和负样本上的奖励两者的间距(margin)
微调实操:具体平台还不太清楚;
分词和向量化
前端大模型入门:编码(Tokenizer)和嵌入(Embedding)解析 - llm的输入_tokenizer embedding-CSDN博客
Tokenizer 是一种将自然语言文本转化为模型可以处理的数字表示的工具。
Tokenizer通过查表的方式,将每个单词、子词或者字符映射为一个唯一的整数ID。“我” -> 1
“喜欢” -> 2, 3
“学习” -> 4, 5Embedding 是将Tokenizer生成的整数ID转化为稠密的向量表示的过程。与Tokenizer将文本转换为离散的整数ID不同,Embedding生成的是连续的实数值向量,这些向量能够捕捉词之间的语义关系。
这个向量通常是一个固定维度的向量(例如,300维、512维或768维),用来表示单词或子词的语义特征。
例如,经过Tokenizer处理的文本“我喜欢学习”可能会生成整数ID序列 [1, 2, 3, 4, 5]。在Embedding阶段,这些ID会被转换为稠密向量表示,如:
“我” -> [0.25, -0.34, 0.15, ...]
“喜欢” -> [0.12, 0.57, -0.22, ...], [0.11, -0.09, 0.31, ...]
“学习” -> [0.33, -0.44, 0.19, ...], [0.09, 0.23, -0.41, ...]
微调各种方案对比
通义 - 你的实用AI助手
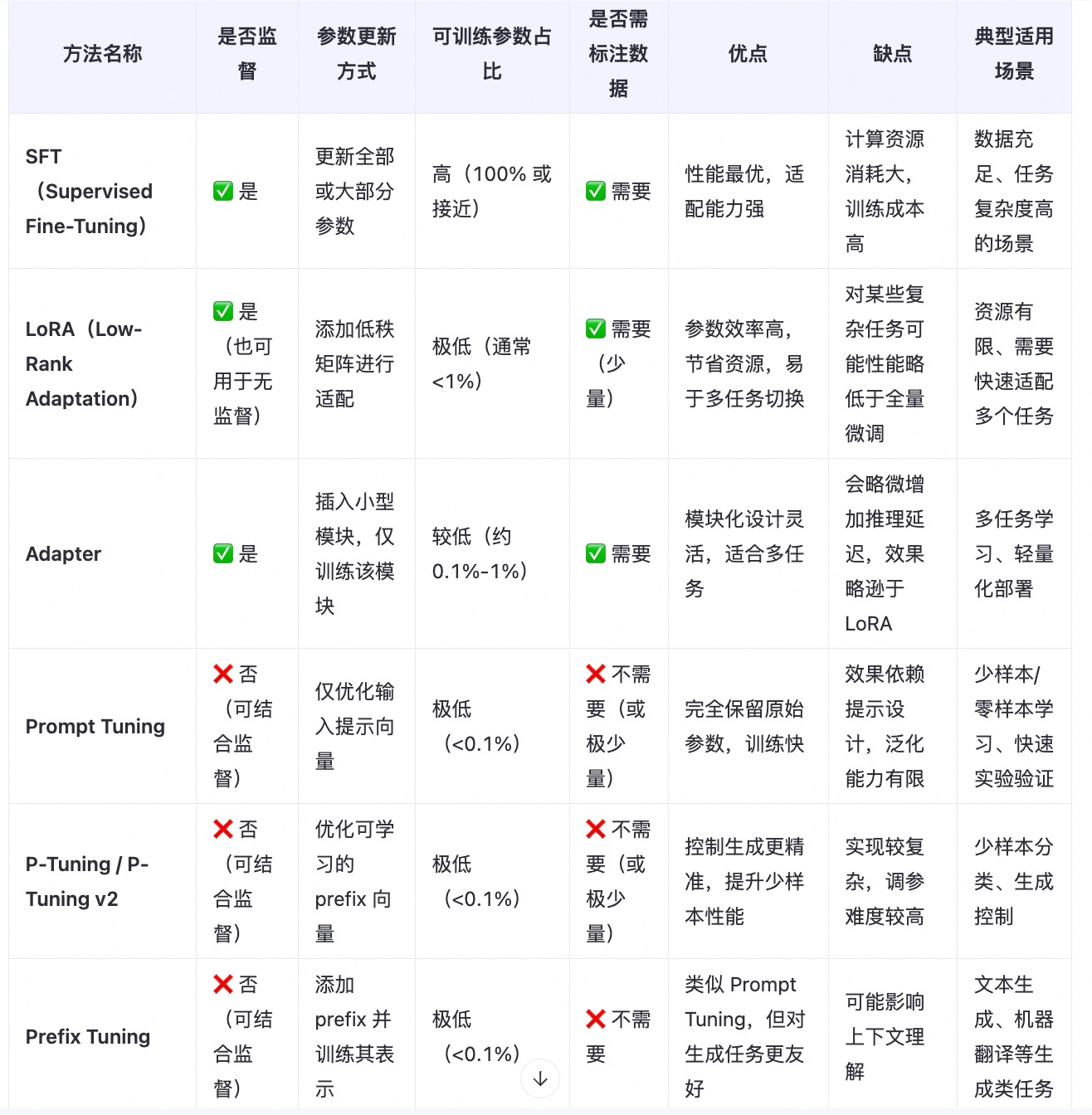
监督 vs 无监督:
- SFT 是典型的监督微调;
- Prompt Tuning 和 Prefix Tuning 常用于无监督或弱监督场景;
- LoRA 可结合监督或无监督目标使用。
参数高效(PEFT)方法:
- 包括:LoRA、Adapter、Prompt Tuning、P-Tuning、Prefix Tuning、IA³ 等;
- 特点是:只训练极少部分新增参数,保留原始模型冻结状态。
是否适合私有化部署:
- 所有 PEFT 方法都更适合资源受限的私有化部署环境;
- SFT 更适合计算资源充足的云环境。
如何理解transformer Decoder里面的2个Multi-Header Attention
让通义回答此问题,链接:通义 - 你的实用AI助手
好的!我们用一个具体的例子来形象地解释Transformer模型在中英文翻译中的工作原理,尤其是Decoder中的两个Multi-Head Attention模块的作用。
---
### **场景:翻译句子“我有一本书” → “I have a book”**
#### **1. 编码器(Encoder)的作用**
- **输入**:中文句子“我有一本书”被拆分成词语(或字):`[我, 有, 一, 本, 书]`。
- **编码器的任务**:
- 通过**自注意力机制(Self-Attention)**,让每个词(如“我”)关注整个句子的其他词(如“书”),理解它们之间的关系。
- 例如,“我”和“书”之间可能存在隐含的关联(“我”拥有“书”),编码器会捕捉这种关联。
- 最终,编码器将输入句子转化为一个**上下文相关的向量表示**,这些向量包含了整个句子的全局信息。---
#### **2. 解码器(Decoder)的作用**
解码器的任务是根据编码器的输出,逐步生成目标语言(英文)的句子:“I have a book”。##### **第一步:解码器的“自注意力机制”(Masked Self-Attention)**
- **输入**:解码器开始时只有一个特殊符号`<start>`,表示翻译的开始。
- **任务**:生成第一个词“I”。
- **Masked Self-Attention**的作用:
- 解码器只能看到自己已经生成的部分(即当前已有的词),不能“偷看”未来的词。
- 例如,当生成“I”时,解码器只能基于`<start>`的信息;当生成“have”时,只能基于`<start> I`的信息。
- **掩码(Mask)**会屏蔽未来的位置(右侧),确保生成顺序正确。
- **Q=K=V**:此时解码器的输入是`<start>`,所以查询(Q)、键(K)、值(V)都来自`<start>`的向量。##### **第二步:解码器的“编码器-解码器注意力”(Encoder-Decoder Attention)**
- **任务**:结合编码器的输出(中文句子的上下文信息)来生成下一个词。
- **Q来自解码器的输出**(例如`<start> I`),**K和V来自编码器的输出**(中文句子的向量表示)。
- 解码器会计算当前生成的词(如“I”)与中文句子中每个词(如“我”)的相关性。
- 例如,当生成“I”时,解码器可能发现它与中文的“我”高度相关,从而强化“I”的生成。
- 这一步确保解码器能**利用中文句子的全局信息**(比如“书”对应英文的“book”)来生成正确的翻译。##### **第三步:重复上述过程**
- **生成“have”**:
- Masked Self-Attention:解码器只能基于`<start> I`的信息。
- Encoder-Decoder Attention:结合中文句子的上下文,可能发现“有”对应“have”。
- **生成“a”和“book”**:
- 类似地,解码器逐步生成每个词,同时结合中文句子的全局信息。
- **结束符**:当解码器生成`<end>`时,翻译完成。---
### **总结:两个Attention模块的作用**
1. **Masked Self-Attention(自注意力)**:
- **确保生成顺序正确**:解码器只能看到已生成的部分,不能偷看未来。
- **例子**:生成“I”后,解码器只能基于“I”生成“have”,不能直接跳到“book”。2. **Encoder-Decoder Attention(编码器-解码器注意力)**:
- **结合输入句子的上下文**:解码器通过查询中文句子的向量,找到与当前生成词最相关的中文词。
- **例子**:生成“I”时,可能发现它与中文的“我”相关;生成“book”时,可能发现它与中文的“书”相关。---
### **类比:翻译就像“一边写一边查字典”**
- **编码器**:把中文句子翻译成一本“中文词典”,记录每个词的上下文。
- **解码器**:
1. **Masked Self-Attention**:你只能看到自己已经写的部分(比如“I”),不能提前翻后面的页。
2. **Encoder-Decoder Attention**:你需要查阅那本“中文词典”,找到当前英文词对应的中文词(比如“I”→“我”,“book”→“书”)。---
### **为什么需要两个Attention模块?**
- **如果只有Masked Self-Attention**:解码器只能生成顺序正确的词,但无法结合中文句子的上下文(比如不知道“书”对应“book”)。
- **如果只有Encoder-Decoder Attention**:解码器可以结合中文上下文,但可能生成乱序的词(比如直接生成“I book have”)。因此,**两个模块缺一不可**:一个确保生成顺序正确,一个确保翻译准确!