Qwen3 技术报告详解
TL;DR
- 2025 年通义实验室发布的最新模型 Qwen3,首次在 Qwen 系列中使用了 MoE 架构,并且在一个模型中同时支持了推理和非推理模式,同时使用了大量的合成数据训练,达到了开源模型的 SOTA 榜单效果。
Paper name
Qwen3 Technical Report
Paper Reading Note
Paper URL:
- https://github.com/QwenLM/Qwen3/blob/main/Qwen3_Technical_Report.pdf
Introduction
本文方案
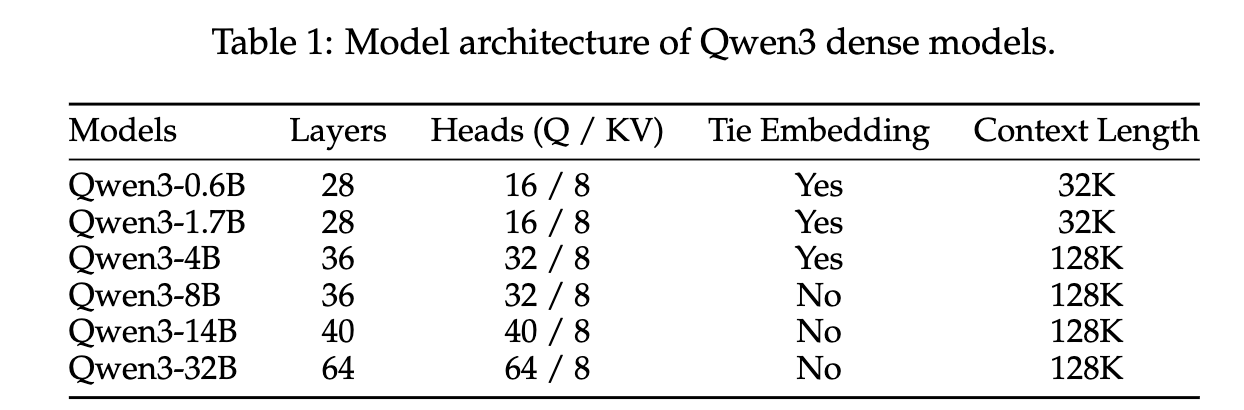
- 推出了 Qwen3,Qwen3 系列包括 6 个密集型模型,分别为:Qwen3-0.6B、Qwen3-1.7B、Qwen3-4B、Qwen3-8B、Qwen3-14B 和 Qwen3-32B ,以及 2 个 MoE(专家混合)模型:Qwen3-30B-A3B 和 Qwen3-235B-A22B。其中旗舰模型 Qwen3-235B-A22B 是一个 MoE 模型,总参数量为 235 亿,每个 token 激活约 22 亿参数。
- 在一个模型中整合了两种不同的运行模式:“思考模式”(用于复杂的多步骤推理)和“非思考模式”(用于快速上下文驱动响应)
- 引入了“思考预算”机制,使用户能够在任务执行过程中对模型所投入的推理努力程度进行细粒度控制
- 使用了一个包含约 36 万亿 token 的大规模数据集
Methods
模型架构
-
Qwen3 密集型模型的架构与 Qwen2.5(Yang 等,2024b)相似,包含以下关键技术组件:
- 分组查询注意力机制
- SwiGLU 激活函数
- 旋转位置编码
- 使用前置归一化的 RMSNorm
- 移除了 Qwen2 中使用的 QKV 偏置项,引入了 QK-Norm
-
MoE 架构如下

预训练
数据
所有 Qwen3 模型均在由 119 种语言与方言构成、总计 36 万亿个标记 的大型多样化语料上训练。
- 利用 Qwen2.5-VL (Bai 等,2025) 对大量类 PDF 文档进行文字识别;随后用 Qwen2.5 (Yang 等,2024b) 精修识别结果,获得数万亿高质量文本标记
- 使用 Qwen2.5、Qwen2.5-Math (Yang 等,2024c) 与 Qwen2.5-Coder (Hui 等,2024) 在教材、问答、指令与代码片段等数十个领域合成了数万亿标记
- 构建了多语言数据标注系统,支持实例级别的数据混合
预训练阶段
Qwen3 的预训练分三阶段进行:
-
通用阶段 (S1)
- 训练标记:> 30 万亿
- 序列长度:4 096
- 目标:语言能力与通识世界知识(119 种语言/方言)。
-
推理阶段 (S2)
- 在 S1 基础上增加 5 万亿 高质量标记,提升 STEM、编码、推理与合成数据占比;
- 序列长度仍为 4 096;
- 采用更快的学习率衰减。
-
长上下文阶段
- 收集高质量长文本,将序列长度扩展至 32 768;
- 训练标记:数百亿;
- 语料构成:75 % 长度 16 384–32 768,25 % 长度 4 096–16 384。
- 技术:
- 将 RoPE 基频由 10 000 调至 1 000 000(ABF,Xiong 等,2023);
- 引入 YARN (Peng 等,2023) 与 Dual Chunk Attention (DCA) (An 等,2024),推理时序列长度能力提升 4 倍。
预训练评测
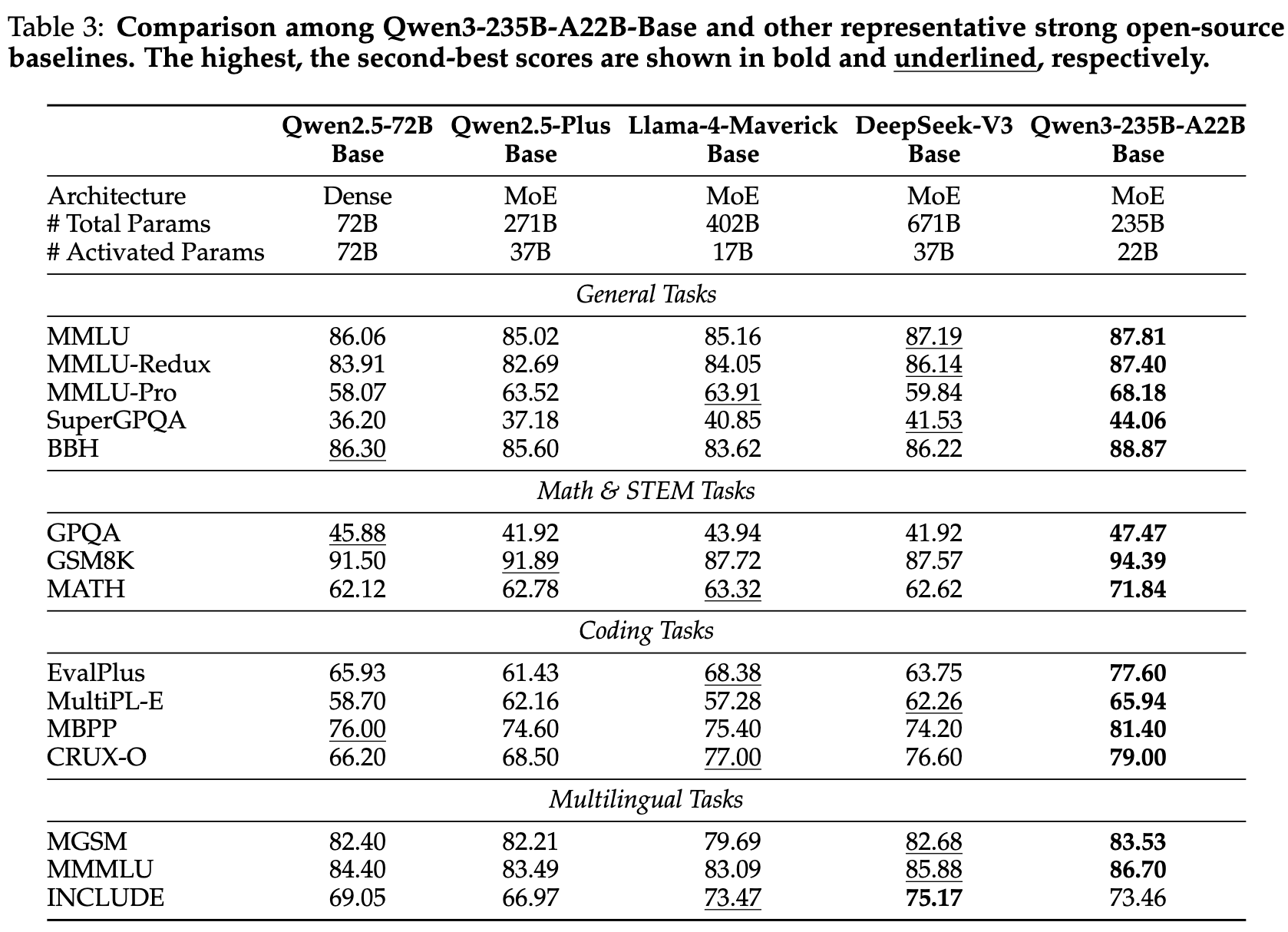
基座模型在 15 个基准上评估:
- 通用任务:MMLU (5-shot)、MMLU-Pro (5-shot + CoT)、MMLU-redux (5-shot)、BBH (3-shot + CoT)、SuperGPQA (5-shot + CoT)。
- 数学 & STEM:GPQA (5-shot + CoT)、GSM8K (4-shot + CoT)、MATH (4-shot + CoT)。
- 编码:EvalPlus (0-shot,汇总 HumanEval, MBPP 等)、MultiPL-E (0-shot;Python、C++、Java…)、MBPP-3shot、CRUXEval-CRUX-O (1-shot)。
- 多语:MGSM (8-shot + CoT)、MMMLU (5-shot)、INCLUDE (5-shot)。
评测结果
- 与开源模型对比
- Qwen3-235B-A22B-Base 以显著更少的总参数或激活参数,在大多数任务上超越 DeepSeek-V3 Base、Llama-4-Maverick Base、Qwen2.5-72B-Base 等 SOTA 稠密/MoE 模型。
- Qwen3 稠密模型在同等或更小参数量下整体与或优于 Qwen2.5。特别在 STEM、编码、推理任务上,低参 Qwen3 稠密模型已超越高参 Qwen2.5
后训练
四阶段后训练流程
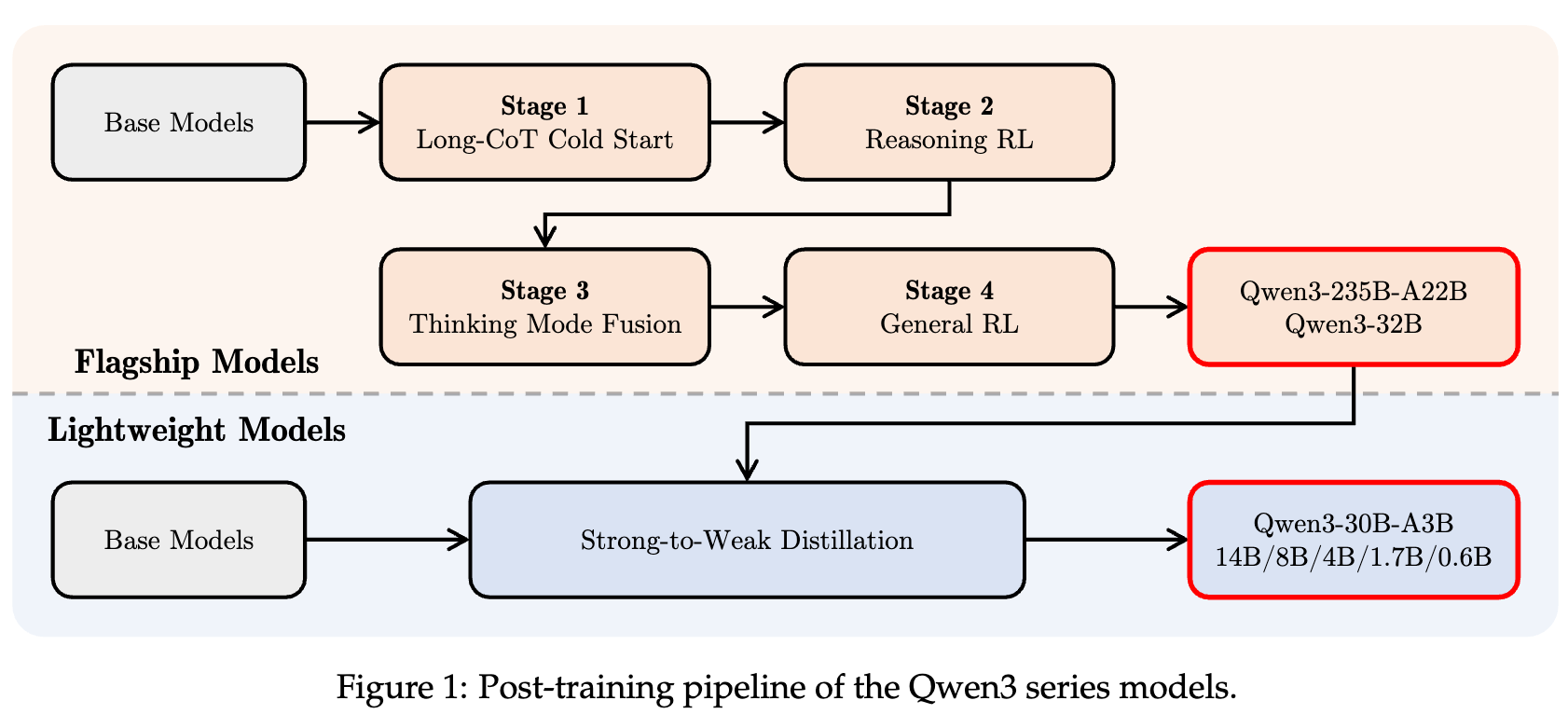
Qwen3 系列的后训练流程(见 图 1)围绕两大核心目标设计:
-
思维控制(Thinking Control)
- 同时集成 “非思考” 与 “思考” 两种模式,让用户可选择模型是否进行推理,并通过设置思考令牌预算来控制推理深度。
-
强–弱蒸馏(Strong-to-Weak Distillation)
- 通过大模型向轻量模型传递知识,显著降低小模型训练与开发成本。
旗舰模型采用 四阶段 训练流程:前两阶段着重培养“思考”能力,后两阶段将强大的“非思考”功能融入模型。预实验表明,直接对轻量学生模型进行教师 logits 蒸馏,在保持细粒度推理控制的同时,可显著提升性能:
- Pass@1 提高,
- Pass@64 探索能力增强,
- 训练效率提升——GPU 时长仅为完整四阶段训练的 1/10。
下文依次介绍四阶段训练及强-弱蒸馏策略。
4.1 Long-CoT 冷启动
-
数据集构建:覆盖数学、代码、逻辑推理、通用 STEM 等类别,每道题配备验证答案或代码测试用例。
-
两阶段过滤
-
查询过滤:用 Qwen2.5-72B-Instruct 剔除难以验证、子问题过多、或无需 CoT 即可答对的简单问题,并为每个查询标注领域,保证均衡。
-
回复过滤:对 QwQ-32B 生成的候选进行人工复审,剔除
- 答案错误、
- 大段重复、
- 明显猜测、
- 思路与结论不一致、
- 风格混乱、
- 或与验证集过于相似的答案。
-
-
冷启动训练:仅用少量精筛样本与训练步骤,为模型注入基础推理模式,为后续 RL 留出改进空间。
4.2 推理 RL
-
查询-验证器对 需满足:
- 冷启动阶段未使用;
- 对冷启动模型可学;
- 足够具有挑战性;
- 子领域覆盖广。
-
最终收集 3 995 组对,采用 GRPO 算法 (Shao 等,2024) 进行 RL。
-
关键做法:大批量、每问多次 rollout、离策略训练、熵控制平稳上升。
-
例:Qwen3-235B-A22B 在 170 步 RL 中,AIME’24 得分由 70.1 → 85.1。
4.3 思维模式融合
目标:在同一模型内融合同步支持思考 / 非思考两种能力,方便动态切换并降低部署复杂度。
-
SFT 数据
- 思考数据:对阶段 2 查询用阶段 2 模型拒绝采样获得;
- 非思考数据:覆盖编码、数学、指令遵循、多语、创作、问答、角色扮演等任务,并用自动清单检查回复质量;
- 低资源语言翻译任务占比提高。
-
聊天模板 (见表 9)
- 在用户或系统消息中加入
/think与/no think标志; - 助手回复中
<think>…</think>包含推理内容; - 默认思考模式,复杂多轮对话随机插入标志,模型遵循最后一次标志。
- 在用户或系统消息中加入
-
思考预算
-
当
<think>长度达到用户设定阈值即插入停思指令:Considering the limited time by the user…
-
随后模型基于现有推理生成最终答案。该能力为自然涌现,无需显式训练。
-
4.4 通用 RL
构建覆盖 20+ 任务的奖励体系,重点提升:
| 领域 | 目标 |
|---|---|
| 指令遵循 | 准确满足内容、格式、长度、结构要求 |
| 格式遵循 | 正确处理 /think / /no think,使用 <think> 标签分隔 |
| 偏好对齐 | 提升回答的有用性、风格与互动性 |
| Agent 能力 | 通过真实环境多轮交互,稳定调用工具 |
| 专用场景 | 如 RAG,降低幻觉风险 |
奖励类型:
- 规则奖励(高精度防 hacking);
- 参考答案-模型奖励(Qwen2.5-72B-Instruct 打分,避免纯规则误判);
- 无参考-模型奖励(基于人类偏好训练的 RM,适用更广)。
4.5 强-弱蒸馏
针对 5 个稠密(0.6B-14B)与 1 个 MoE(30B-A3B)轻量模型:
-
离策略蒸馏
- 收集教师模型
/think与/no think输出并蒸馏,赋予基本推理与模式切换能力。
- 收集教师模型
-
在策略蒸馏
- 学生模型按两模式生成回复,再与教师 logits 对齐,最小化 KL 散度。
4.6 后训练评测
采用自动基准,分别评估思考 / 非思考模式下表现。
-
通用任务:MMLU-Redux、GPQA-Diamond、C-Eval、LiveBench (2024-11-25)
-
对齐任务:IFEval、Arena-Hard、AlignBench v1.1、Creative Writing V3、WritingBench
-
数学 & 文本推理:MATH-500、AIME’24/’25、ZebraLogic、AutoLogi
-
Agent & 编码:BFCL v3、LiveCodeBench (v5, 2024.10-2025.02)、CodeElo-Codeforces
-
多语任务:
- 指令遵循:Multi-IF (8 语)
- 知识:INCLUDE (44 语)、MMMLU (14 语)
- 数学:MT-AIME2024 (55 语)、PolyMath (18 语)
- 推理:MLogiQA (10 语)
采样设置
- 思考模式:temperature 0.6, top-p 0.95, top-k 20
- 非思考模式:temperature 0.7, top-p 0.8, top-k 20
- 两模式均设 presence penalty 1.5,输出上限 32 768 tokens(AIME 至 38 912)。
与顶尖模型比
- 推理模型
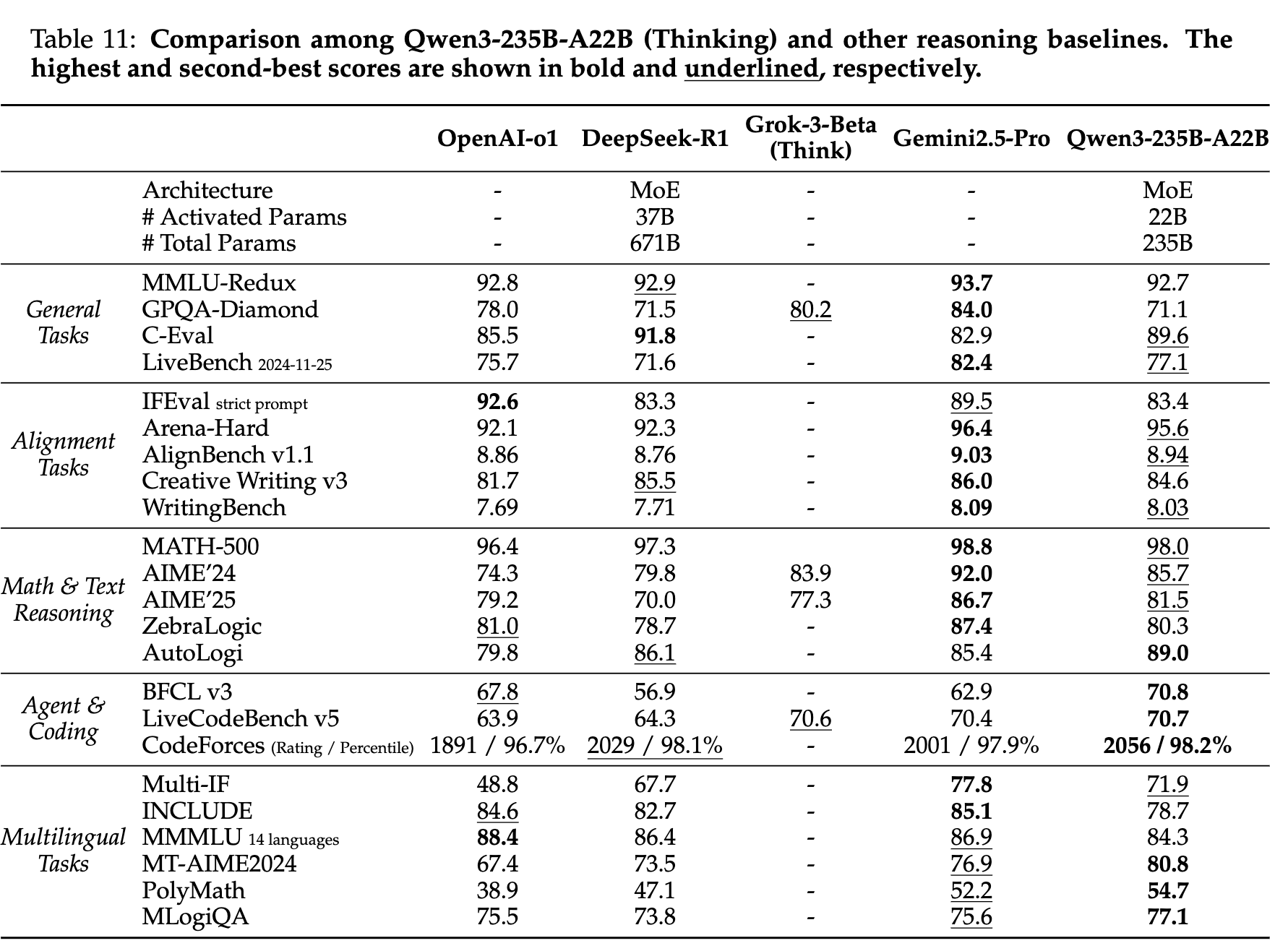
- 非推理模型
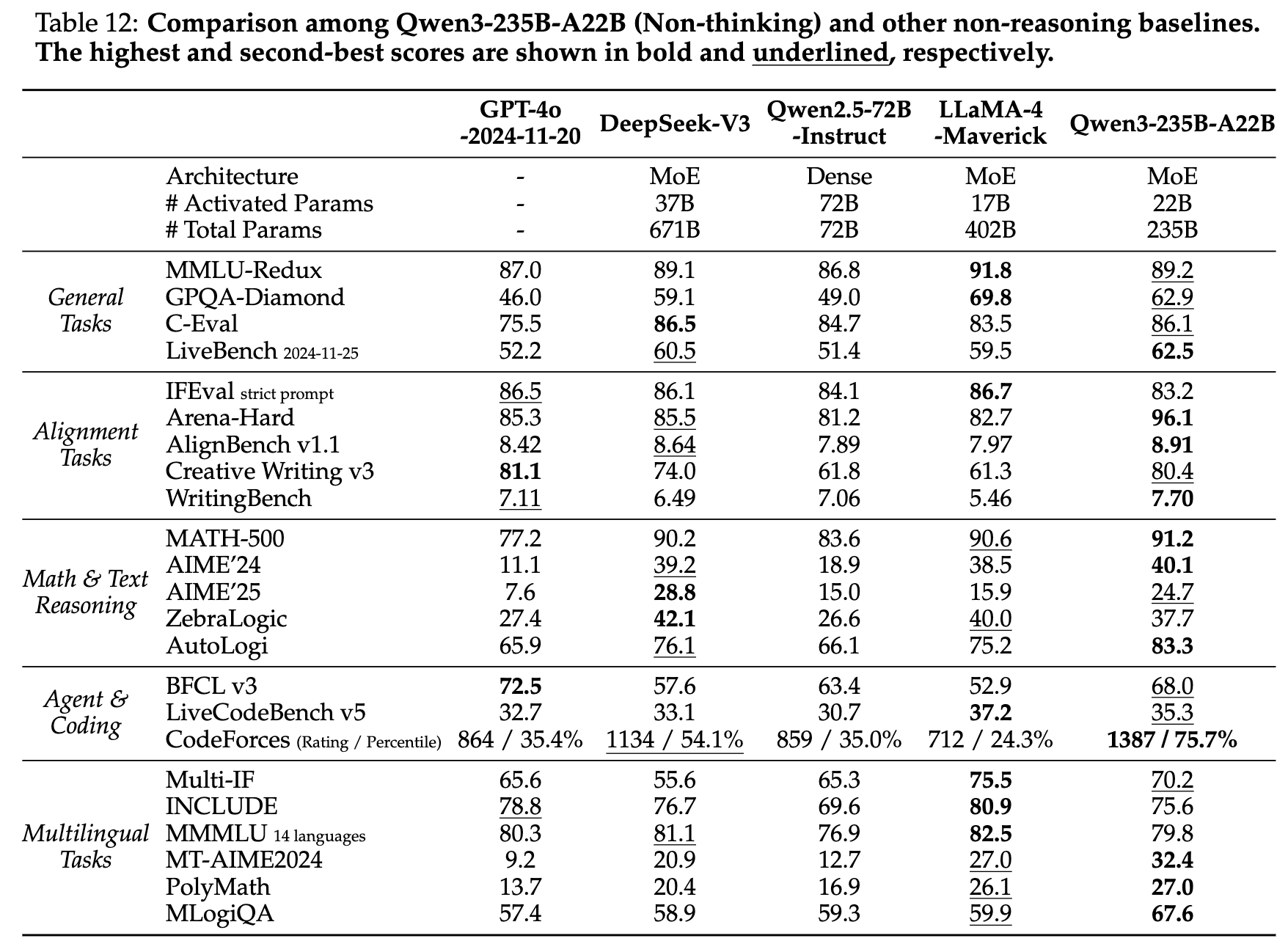
与开源模型比
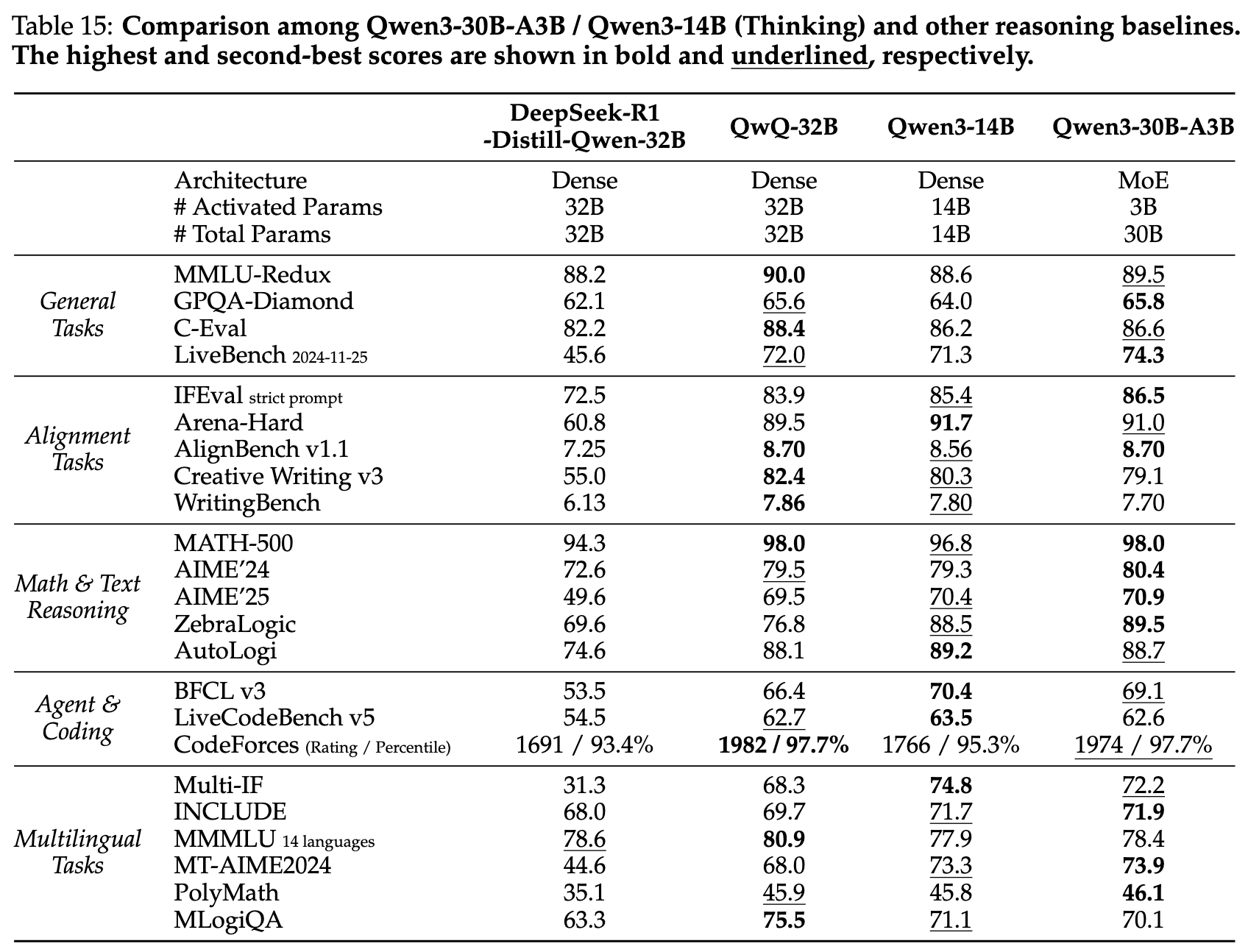

消融实验
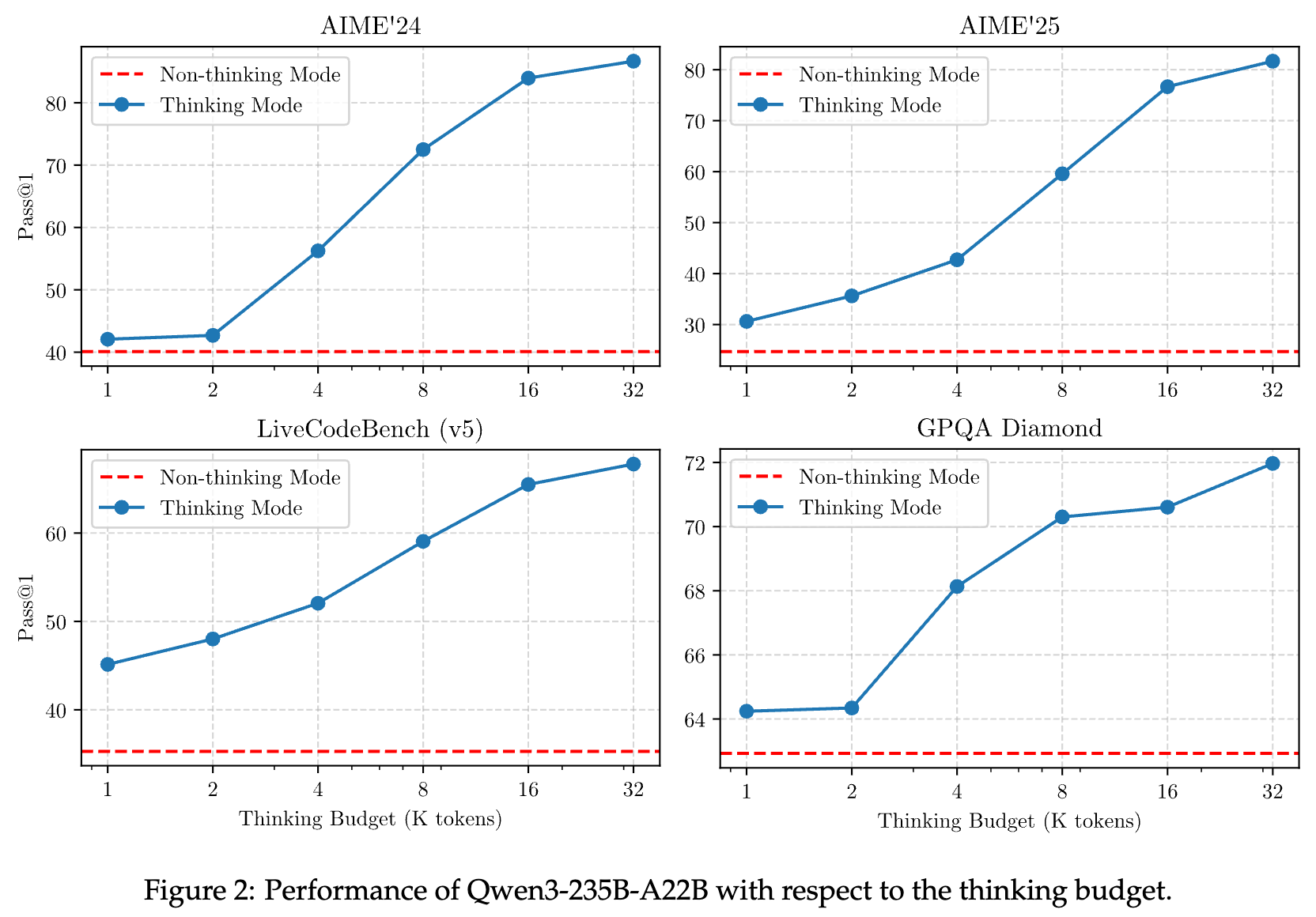
推理预算的有效性
在数学、编程和 STEM 领域的四个基准测试中调整了分配的推理预算。图2展示了相应的性能变化曲线。结果显示,Qwen3 的性能随着推理预算的增加而呈现出可扩展且平滑的提升趋势。
策略内蒸馏的有效性与效率
通过比较在相同离线策略蒸馏得到的 8B 检查点基础上,经过策略内蒸馏 (on-policy distillation)与直接使用强化学习(reinforcement learning)后的性能表现及计算成本(以 GPU 小时衡量),评估该蒸馏方法的有效性和效率。
仅关注数学和编程相关的问题。结果汇总于表21中,可以看到:
- 蒸馏方法相比强化学习取得了显著更优的性能;
- 同时,它所需的 GPU 时间仅为后者的约十分之一。
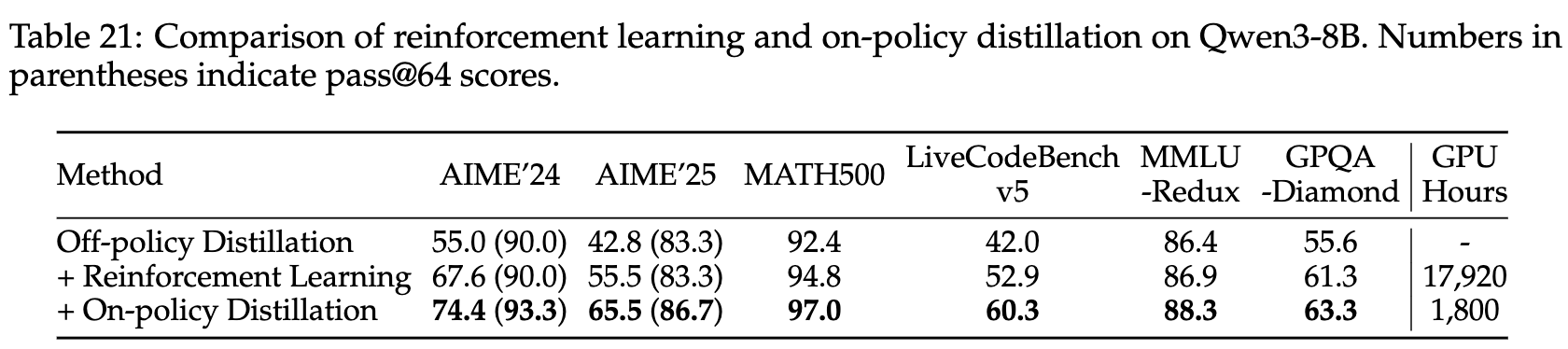
更重要的是,来自教师模型 logit 的蒸馏使学生模型能够拓展其探索空间并增强推理潜力。例如,在 AIME’24 和 AIME’25 基准测试中,蒸馏后的 pass@64 分数明显优于初始检查点。相比之下,强化学习并未带来任何 pass@64 分数的提升。
推理模式融合与通用强化学习的影响
为了评估在后训练阶段中推理模式融合 (Thinking Mode Fusion)和通用强化学习 (General RL)的效果,我们在 Qwen-32B 模型的不同训练阶段进行了评估。
除了之前提到的数据集之外,我们还引入了一些内部构建的基准测试,用于监控其他能力。这些基准包括:
- CounterFactQA :包含反事实问题,要求模型识别问题不真实并避免生成幻觉答案;
- LengthCtrl :包含有长度限制的创意写作任务,最终得分基于生成内容长度与目标长度之间的差异;
- ThinkFollow :包含多轮对话,其中随机插入 /think 和 /no think 标志,测试模型是否能根据用户指令正确切换推理模式;
- ToolUse :评估模型在单轮、多轮以及多步骤工具调用过程中的稳定性,评分包括意图识别准确率、格式准确率和参数准确率。

得出以下结论: - 第三阶段 在已有前两个阶段训练出的推理能力基础上,将“非推理模式”整合进模型。ThinkFollow 得分为 88.7,表明模型已具备初步的模式切换能力,尽管偶尔仍会出错。
此阶段也增强了模型在推理模式下的通用能力和指令遵循能力,CounterFactQA 提升了 10.9 分,LengthCtrl 提升了 8.0 分。 - 第四阶段 进一步增强了模型在推理与非推理两种模式下的通用能力、指令遵循能力和代理(agent)能力。特别是 ThinkFollow 得分提升至 98.9,几乎实现了准确的模式切换。
- 对于知识类、STEM 类、数学类和编程类任务,推理模式融合 和通用强化学习 并没有带来显著提升。相反,在 AIME’24 和 LiveCodeBench 等高难度任务上,这两个训练阶段反而导致推理模式下的性能下降。
推测这种下降是由于模型在更广泛的通用任务上接受了训练,可能削弱了其处理复杂问题的专业能力。在 Qwen3 的开发过程中,选择接受这一性能权衡,以提升模型整体的多功能性和适用性。
Conclusion
- Qwen3 具备推理模式与非推理模式两种工作方式,使用户能够动态管理用于复杂推理任务的 token 数量。该模型在包含 36 万亿 token 的大规模数据集上进行了预训练,具备对 119 种语言和方言的理解和生成能力。
- 虽然论文的模型点数在开源中算很高的了,但是论文整体的创新度与信息量和 dsv3 这种模型比还是差距很大,可能这就是为什么 deepseek 会出圈的原因吧