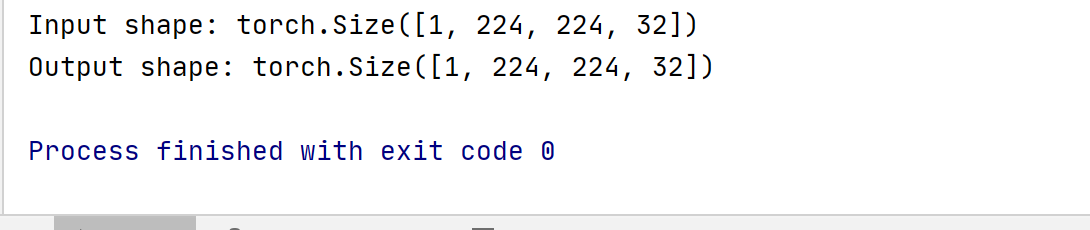
name ‘selective_scan_fn‘ is not defined运行出现这个错误
 1.第一步先在这个代码中找到try以及except这部分,
1.第一步先在这个代码中找到try以及except这部分,
 2.在这个部分最下边编写一个打印输出
2.在这个部分最下边编写一个打印输出
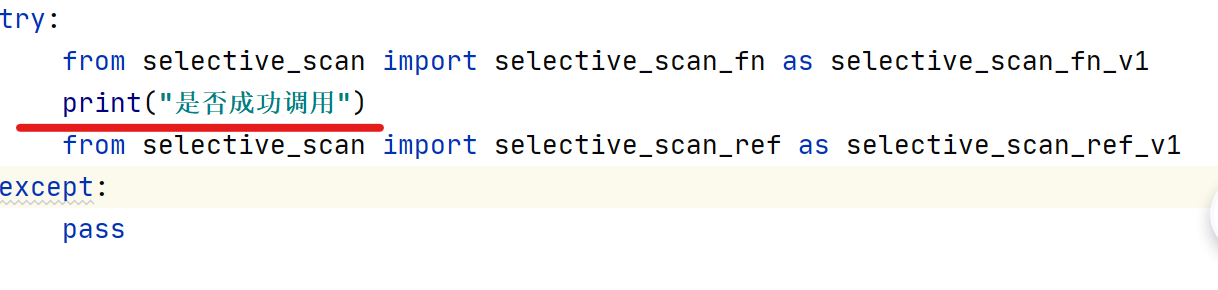 添加打印之后重新运行出现还是当前的错误
添加打印之后重新运行出现还是当前的错误

3.那么选择在第二部分pass之后另起一行复制下列代码,完成添加SelectiveScanFn这个类,就可以在此处调用了
class SelectiveScanFn(torch.autograd.Function):
@staticmethod
def forward(ctx, u, delta, A, B, C, D=None, z=None, delta_bias=None, delta_softplus=False,
return_last_state=False):
if u.stride(-1) != 1:
u = u.contiguous()
if delta.stride(-1) != 1:
delta = delta.contiguous()
if D is not None:
D = D.contiguous()
if B.stride(-1) != 1:
B = B.contiguous()
if C.stride(-1) != 1:
C = C.contiguous()
if z is not None and z.stride(-1) != 1:
z = z.contiguous()
if B.dim() == 3:
B = rearrange(B, "b dstate l -> b 1 dstate l")
ctx.squeeze_B = True
if C.dim() == 3:
C = rearrange(C, "b dstate l -> b 1 dstate l")
ctx.squeeze_C = True
out, x, *rest = selective_scan_cuda.fwd(u, delta, A, B, C, D, z, delta_bias, delta_softplus)
ctx.delta_softplus = delta_softplus
ctx.has_z = z is not None
last_state = x[:, :, -1, 1::2] # (batch, dim, dstate)
if not ctx.has_z:
ctx.save_for_backward(u, delta, A, B, C, D, delta_bias, x)
return out if not return_last_state else (out, last_state)
else:
ctx.save_for_backward(u, delta, A, B, C, D, z, delta_bias, x, out)
out_z = rest[0]
return out_z if not return_last_state else (out_z, last_state)
@staticmethod
def backward(ctx, dout, *args):
if not ctx.has_z:
u, delta, A, B, C, D, delta_bias, x = ctx.saved_tensors
z = None
out = None
else:
u, delta, A, B, C, D, z, delta_bias, x, out = ctx.saved_tensors
if dout.stride(-1) != 1:
dout = dout.contiguous()
# The kernel supports passing in a pre-allocated dz (e.g., in case we want to fuse the
# backward of selective_scan_cuda with the backward of chunk).
# Here we just pass in None and dz will be allocated in the C++ code.
du, ddelta, dA, dB, dC, dD, ddelta_bias, *rest = selective_scan_cuda.bwd(
u, delta, A, B, C, D, z, delta_bias, dout, x, out, None, ctx.delta_softplus,
False # option to recompute out_z, not used here
)
dz = rest[0] if ctx.has_z else None
dB = dB.squeeze(1) if getattr(ctx, "squeeze_B", False) else dB
dC = dC.squeeze(1) if getattr(ctx, "squeeze_C", False) else dC
return (du, ddelta, dA, dB, dC,
dD if D is not None else None,
dz,
ddelta_bias if delta_bias is not None else None,
None,
None)
def selective_scan_fn(u, delta, A, B, C, D=None, z=None, delta_bias=None, delta_softplus=False,
return_last_state=False):
"""if return_last_state is True, returns (out, last_state)
last_state has shape (batch, dim, dstate). Note that the gradient of the last state is
not considered in the backward pass.
"""
return selective_scan_ref(u, delta, A, B, C, D, z, delta_bias, delta_softplus, return_last_state)
def selective_scan_ref(u, delta, A, B, C, D=None, z=None, delta_bias=None, delta_softplus=False,
return_last_state=False):
"""
u: r(B D L)
delta: r(B D L)
A: c(D N) or r(D N)
B: c(D N) or r(B N L) or r(B N 2L) or r(B G N L) or (B G N L)
C: c(D N) or r(B N L) or r(B N 2L) or r(B G N L) or (B G N L)
D: r(D)
z: r(B D L)
delta_bias: r(D), fp32
out: r(B D L)
last_state (optional): r(B D dstate) or c(B D dstate)
"""
dtype_in = u.dtype
u = u.float()
delta = delta.float()
if delta_bias is not None:
delta = delta + delta_bias[..., None].float()
if delta_softplus:
delta = F.softplus(delta)
batch, dim, dstate = u.shape[0], A.shape[0], A.shape[1]
is_variable_B = B.dim() >= 3
is_variable_C = C.dim() >= 3
if A.is_complex():
if is_variable_B:
B = torch.view_as_complex(rearrange(B.float(), "... (L two) -> ... L two", two=2))
if is_variable_C:
C = torch.view_as_complex(rearrange(C.float(), "... (L two) -> ... L two", two=2))
else:
B = B.float()
C = C.float()
x = A.new_zeros((batch, dim, dstate))
ys = []
deltaA = torch.exp(torch.einsum('bdl,dn->bdln', delta, A))
if not is_variable_B:
deltaB_u = torch.einsum('bdl,dn,bdl->bdln', delta, B, u)
else:
if B.dim() == 3:
deltaB_u = torch.einsum('bdl,bnl,bdl->bdln', delta, B, u)
else:
B = repeat(B, "B G N L -> B (G H) N L", H=dim // B.shape[1])
deltaB_u = torch.einsum('bdl,bdnl,bdl->bdln', delta, B, u)
if is_variable_C and C.dim() == 4:
C = repeat(C, "B G N L -> B (G H) N L", H=dim // C.shape[1])
last_state = None
for i in range(u.shape[2]):
x = deltaA[:, :, i] * x + deltaB_u[:, :, i]
if not is_variable_C:
y = torch.einsum('bdn,dn->bd', x, C)
else:
if C.dim() == 3:
y = torch.einsum('bdn,bn->bd', x, C[:, :, i])
else:
y = torch.einsum('bdn,bdn->bd', x, C[:, :, :, i])
if i == u.shape[2] - 1:
last_state = x
if y.is_complex():
y = y.real * 2
ys.append(y)
y = torch.stack(ys, dim=2) # (batch dim L)
out = y if D is None else y + u * rearrange(D, "d -> d 1")
if z is not None:
out = out * F.silu(z)
out = out.to(dtype=dtype_in)
return out if not return_last_state else (out, last_state)
def mamba_inner_fn(
xz, conv1d_weight, conv1d_bias, x_proj_weight, delta_proj_weight,
out_proj_weight, out_proj_bias,
A, B=None, C=None, D=None, delta_bias=None, B_proj_bias=None,
C_proj_bias=None, delta_softplus=True
):
return mamba_inner_ref(xz, conv1d_weight, conv1d_bias, x_proj_weight, delta_proj_weight,
out_proj_weight, out_proj_bias,
A, B, C, D, delta_bias, B_proj_bias, C_proj_bias, delta_softplus)
最后重新运行这段代码,就可以运行成功了