Flash Attention:让Transformer飞起来的硬件优化技术
最近在研究大模型优化的时候,深入了解了Flash Attention这个技术。说实话,刚开始听到这个名字的时候,我还以为是某种新的注意力机制,后来才发现这其实是一个非常巧妙的硬件优化方案。今天想和大家分享一下我对Flash Attention的理解。
为什么需要Flash Attention?
要理解Flash Attention,首先得明白传统Attention计算的瓶颈在哪里。
我在二、大模型原理:图文解析Transformer原理与代码这篇文章中有提到,注意力的计算量非常大,我们需要计算Q×K^T,这会产生一个N×N的矩阵(N是序列长度)
问题不仅仅是矩阵大,更关键的是后续的softmax、dropout等操作都属于内存密集型运算,而不是计算密集型。这意味着大量时间都花在了内存读写上,而不是实际的数学运算上。
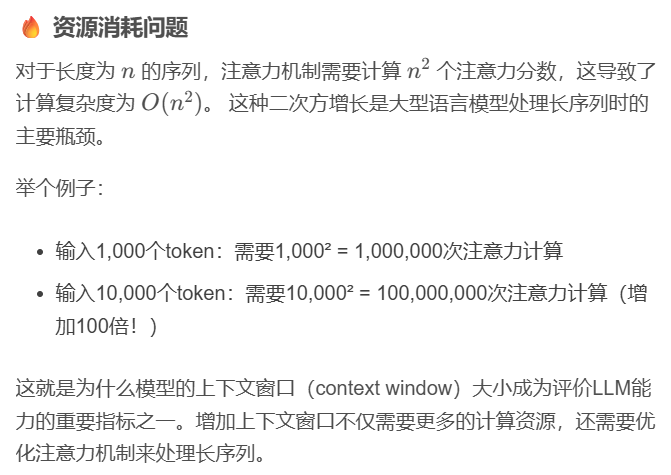
注意力机制的耗时最多的是在
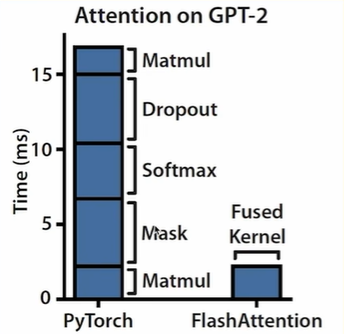
GPU内存层次结构
要理解Flash Attention的工作原理,需要先了解GPU的内存架构:
HBM(High Bandwidth Memory):这是GPU的主内存,容量大(比如A100有40G或80G),但相对较慢,传输速度约1.5TB/s。我们平时说的"显存不够了"指的就是这块内存。
SRAM(Static RAM):这是GPU芯片上的缓存,速度极快(约19TB/s),但容量很小。以A100为例,每个SM(Streaming Multiprocessor)只有192KB的SRAM,整个GPU有108个SM。
传统的注意力计算全程都在HBM中进行,而Flash Attention的核心思想就是把计算转移到速度更快的SRAM中。
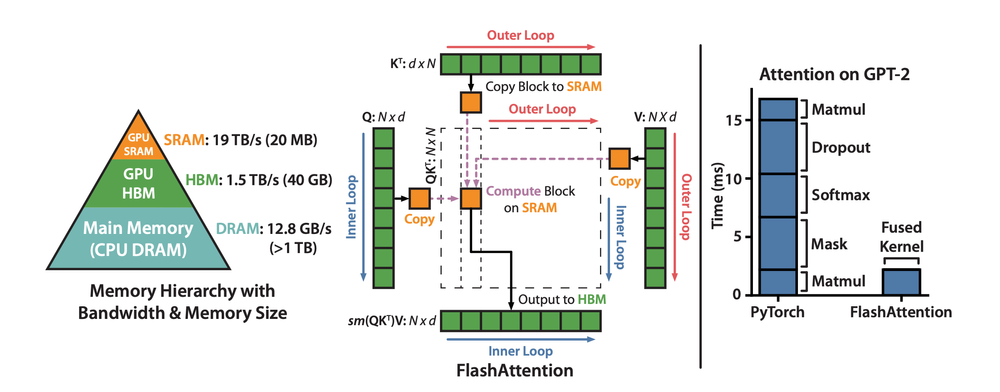
Flash Attention的核心策略
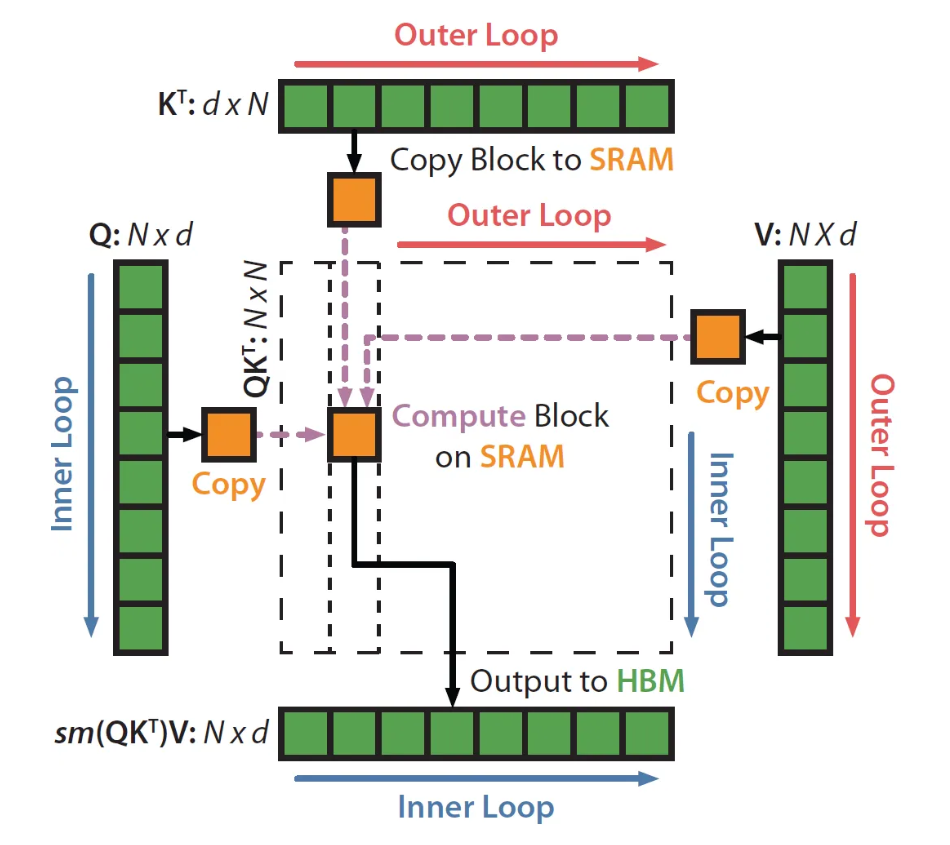
Flash Attention采用了"分块计算"的策略。既然SRAM容量小,那就把大矩阵切成小块,每次只处理一小块。但这种传输并不是无开销的!
分块计算过程
假设我们有:
- Q矩阵:4096×512(4K序列长度,512维特征)
- K矩阵:512×4096(转置后)
- V矩阵:4096×512
Flash Attention会将这些矩阵按块切分:
- 每个块的大小由公式
M/(4×D)确定,其中M是SRAM容量,D是特征维度 - 对于A100,这个块大小大约是93×512
计算过程变成:
- 将K、V的一个块加载到SRAM
- 依次将Q的每个块加载到SRAM
- 在SRAM中完成QK相乘、softmax、乘V的全过程
- 将结果写回HBM
这样做的好处是所有耗时的内存密集型操作都在高速的SRAM中完成,速度提升了约20倍。
最大的技术挑战:分块Softmax
Flash Attention最巧妙也最复杂的部分是如何处理softmax运算。
Softmax需要知道整行的所有值才能计算每个元素的概率,但分块计算时我们只能看到部分值。这就像盲人摸象,如何从局部信息推断全局?
Flash Attention的解决方案使用了巧妙的数学技巧:
- 追踪最大值:记录每个块中每行的最大值
- 累积分母:逐步累加softmax分母的值
- 动态更新:每处理一个新块,就重新调整之前的结果
具体来说,它维护三个关键变量:
m:当前最大值l:当前分母累积o:当前输出结果
每处理一个新块,这些值都会根据复杂的公式进行更新,确保最终结果与不分块计算完全一致。
性能表现
根据论文的测试结果,Flash Attention 2在A100 GPU上的性能表现令人印象深刻:
- 比标准PyTorch实现快数倍
- 比Flash Attention 1还要快
- 支持更长的序列长度
- 内存使用更高效
最重要的是,Flash Attention没有精度损失,这与一些近似方法(如稀疏注意力)不同。
实际应用考虑
虽然Flash Attention很强大,但也有一些限制:
硬件兼容性:对GPU型号有要求,早期的GPU可能不支持。
编译复杂性:需要底层CUDA编程,针对不同GPU优化,配置可能比较麻烦。
时空权衡:反向传播时采用重计算策略,用时间换空间,训练可能稍慢但内存效率更高。