EfficientLLM: Efficiency in Large Language Models 高效大模型
目录
- 第1章:引言
- 第2章:观察与见解
- 2.1 总体观察(Overall Observations)
- 2.2 从EfficientLLM基准中得出的新见解
- 第3章:背景
- 3.1 大语言模型(LLMs)
- 3.2 提升LLMs效率的方法
- 3.2.1 硬件创新
- 3.2.2 软件优化
- 3.2.3 算法改进
- 第4章:提升LLMs效率的技术
- 4.1 LLMs效率的维度(Dimensions of LLM Efficiency)
- 4.2 预算效率:扩展法则(Budget Efficiency: Scaling Laws)
- 4.3 数据效率(Data Efficiency)
- **4.4 架构效率(Architecture Efficiency)**
- 4.5 训练和微调效率(Training and Tuning Efficiency)
- **4.6 推理效率(Inference Efficiency)**
- 第5章:评估
- **5.1 EfficientLLM评估原则(Assessment Principles of EFFICIENTLLM)**
- **5.2 EfficientLLM实验设置(Preliminaries of EFFICIENTLLM)**
- **5.3 架构预训练效率评估(Assessment of Architecture Pretraining Efficiency)**
- **5.4 训练和微调效率评估(Assessment of Training and Tuning Efficiency)**
- 5.5 量化推理效率评估(Assessment of Bit-Width Quantization Inference Efficiency)
- 第6章:EfficientLLM基准的可扩展性
- 6.1 Transformer基础的LVMs架构预训练效率(Efficiency for Transformer Based LVMs Architecture Pretraining)
- 6.2 PEFT在LVMs上的评估(Assessment of PEFT on LVMs)
- 6.3 PEFT在VLMs上的评估(Assessment of PEFT on VLMs)
- 6.4 PEFT在多模态模型上的评估(Assessment of PEFT on Multimodal Models)
- 第7章:相关工作
- 7.1 分布式训练和系统级优化(Distributed Training and System-Level Optimizations)
- 7.2 对齐和强化学习效率(Alignment and RLHF Efficiency)
- 7.3 推理时间加速策略(Inference-Time Acceleration Strategies)
- 7.4 动态路由和模型级联(Dynamic Routing and Model Cascades)
- 7.5 硬件感知训练计划(Hardware-aware Training Schedules)
- 7.6 讨论(Discussion)
- 结论
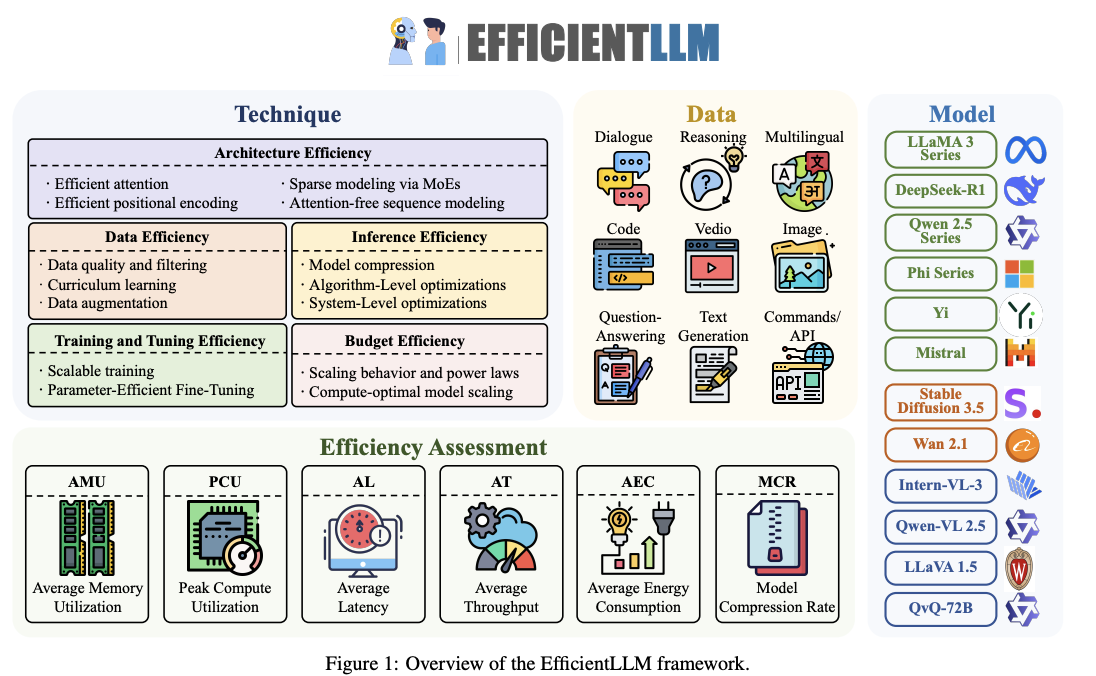
《EfficientLLM: Efficiency in Large Language Models》由Zhengqing Yuan等人撰写,系统地研究了大语言模型(LLMs)的效率问题,并提出了一个全面的基准框架EfficientLLM,用于评估不同效率优化技术在架构预训练、微调和量化方面的表现。以下是对论文每一章节内容的脉络概览:
第1章:引言
- 研究背景
LLMs的突破性进展:LLMs如GPT系列和Pathways Language Model(PaLM)在自然语言处理(NLP)领域取得了显著进展。这些模型通过深度学习技术在大规模文本数据上进行训练,能够生成复杂、连贯的语言内容,并在多种任务中表现出色。
模型规模和资源需求:随着模型参数规模的不断增大(如Deepseek R1的671B参数),训练和推理所需的计算资源、内存容量和能源消耗也急剧增加。例如,训练GPT-3(175B参数)需要约3640 Petaflop/s-days的计算量,成本高达数百万美元。
资源需求对应用的影响:这种资源需求的增长限制了LLMs的广泛应用,尤其是在资源受限的环境中。因此,提高LLMs的效率成为了一个关键的研究方向。 - 研究动机
效率挑战:尽管LLMs在性能上取得了巨大进步,但其高昂的计算和能源成本使其在实际部署中面临挑战。例如,GPT-3的训练成本高达数百万美元,推理时的硬件需求和能源消耗也非常可观。
现有研究的局限性:现有的研究通常只关注特定的效率技术,缺乏对多种技术在不同模型规模和任务上的系统性比较。此外,许多研究缺乏对现代硬件(如GPU)能耗的全面评估,或者依赖于理论分析而非大规模实证验证。
EfficientLLM框架的必要性:为了填补这一空白,作者提出了EfficientLLM框架,旨在通过大规模实证研究,系统评估LLMs在架构预训练、微调和量化方面的效率优化技术。 - 研究目标
系统性评估:EfficientLLM框架通过在生产级集群(48×GH200,8×H200 GPUs)上进行大规模实验,系统评估了超过100种模型与技术组合的效率表现。
多维度效率评估:提出了六个细粒度的效率评估指标,包括平均内存利用率(AMU)、峰值计算利用率(PCU)、平均延迟(AL)、平均吞吐量(AT)、平均能耗(AEC)和模型压缩率(MCR),以全面捕捉硬件饱和度、延迟-吞吐量平衡和碳成本。
提供实际指导:通过实验结果,为研究人员和工程师在设计、训练和部署LLMs时提供数据驱动的指导,帮助他们在资源受限的环境中做出更明智的决策。 - EfficientLLM框架的核心概念
架构预训练效率:评估不同架构优化技术(如高效注意力机制、稀疏建模等)在模型预训练阶段的效率表现。这些技术直接影响模型的计算和能源成本。
参数高效微调(PEFT):评估多种参数高效微调方法(如LoRA、RSLoRA等)在适应特定下游任务时的效率和性能。这些方法通过更新模型的一小部分参数来减少微调所需的资源。
量化推理效率:评估不同量化技术(如int4、float16等)在减少模型大小和推理延迟方面的效果。这些技术可以在不重新训练的情况下直接应用于部署。 - 研究贡献
系统性分类和回顾:对LLMs的效率技术进行了系统性分类和回顾,涵盖了架构、训练和推理等多个方面。
新的评估指标:提出了一套新的详细评估指标,用于评估LLMs的多维效率,包括硬件利用率、性能、能耗和模型压缩。
大规模实证基准:通过在大规模GPU集群上进行实验,提供了关于LLMs效率的系统性、大规模实证比较。
实际应用指导:为研究人员和工程师在选择高效模型架构和优化技术时提供了基于实际数据的指导,而不是仅依赖理论分析或启发式选择。
第2章:观察与见解
2.1 总体观察(Overall Observations)
效率优化的多目标权衡:EfficientLLM基准研究发现,没有任何单一方法能够在所有效率维度上实现最优。每种技术在提升某些指标(如内存利用率、延迟、吞吐量、能耗或压缩率)的同时,都会在其他指标上有所妥协。例如,Mixture-of-Experts(MoE)架构虽然通过减少FLOPs和提升准确性来优化计算效率,但会增加显存使用量(约40%),而int4量化虽然显著降低了内存和能耗(最高可达3.9倍),但平均任务分数下降了约3–5%。这些结果验证了“没有免费午餐”(No-Free-Lunch, NFL)定理在LLMs效率优化中的适用性,即不存在一种通用的最优方法。
资源驱动的权衡:在资源受限的环境中,不同的效率技术表现出不同的优势。例如,MQA在内存和延迟方面表现出色,适合内存受限的设备;MLA在困惑度(perplexity)方面表现最佳,适合对质量要求较高的任务;而RSLoRA在14B参数以上的模型中比LoRA更高效,表明效率技术的选择需要根据模型规模和任务需求进行调整。

2.2 从EfficientLLM基准中得出的新见解
架构预训练效率:
注意力机制的多样性:在预训练阶段,不同的高效注意力变体(如MQA、GQA、MLA和NSA)在内存、延迟和质量之间存在不同的权衡。MQA在内存和延迟方面表现最佳,MLA在困惑度方面表现最佳,而NSA在能耗方面表现最佳。
MoE的计算-内存权衡:MoE架构在预训练时可以显著提高性能(如提升3.5个百分点的准确性),同时减少训练FLOPs(约1.8倍),但会增加显存使用量(约40%)。这表明在计算和内存资源之间存在明显的权衡。
注意力自由模型的效率:注意力自由模型(如Mamba)在预训练时表现出较低的内存使用量和能耗,但困惑度有所增加。RWKV在延迟方面表现最佳,而Pythia在生成质量方面表现最佳,尽管其困惑度较高。
深度-宽度比的平坦最优区域:实验结果表明,Chinchilla的深度-宽度比在预训练时存在一个平坦的最优区域,这意味着在该区域内调整模型的深度和宽度对性能的影响较小,为硬件对齐的架构调整提供了灵活性。
训练和微调效率:
PEFT方法的规模依赖性:LoRA及其变体(如LoRA-plus)在1B到3B参数的模型中表现最佳,而RSLoRA在14B参数以上的模型中更有效。参数冻结(只更新特定层或组件)在需要快速微调的场景中表现出最低的延迟,尽管可能会略微降低最终任务的准确性。
全微调的收益递减:对于24B参数以上的模型,全微调的收益递减,损失改进通常小于0.02,而能耗翻倍。这表明在大规模模型适应中应优先采用PEFT方法。
DoRA的延迟权衡:DoRA在微调过程中保持了稳定的损失,但引入了显著的延迟开销,使其更适合于批处理微调管道,而不是实时或延迟敏感的部署场景。
量化推理效率:
量化对性能的影响:int4后训练量化显著提高了资源效率,将内存占用和吞吐量(每秒生成的token数)提高了约3.9倍,但平均任务分数下降了约3–5%。bfloat16在现代Hopper GPU架构上的一致性优于float16,分别在延迟和能耗上分别提高了约6%和9%。
量化精度的选择:bfloat16在延迟和能耗方面表现优于float16,而int4量化在资源受限的