多查询检索在RAG中的应用及为什么平均嵌入向量效果好
随着用 RAG 的人越来越多,我们也发现了好多能让这些系统更准、更快的方法。这里就有一个简单又高效的小妙招,能帮你提升 RAG 的性能。
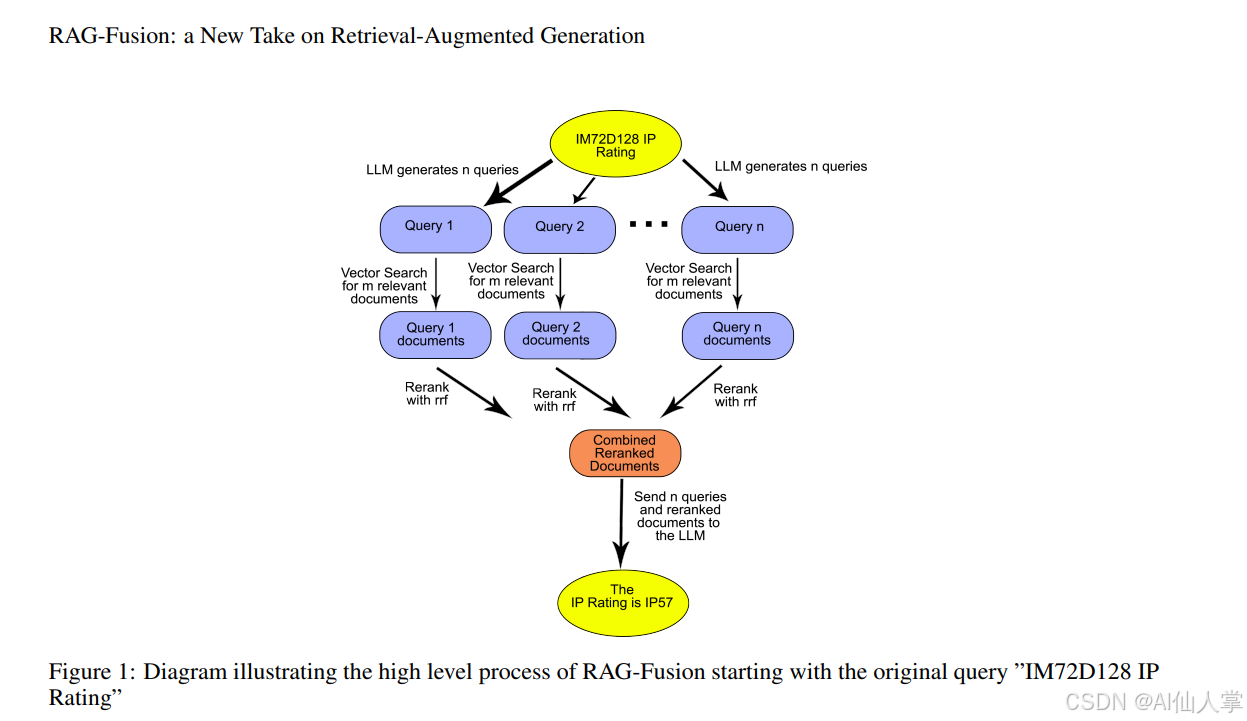
多查询检索
一个问题可以有好多种问法,很多不同的表述其实意思都差不多。在 RAG 里,用户想怎么问就怎么问,这可能会让检索结果有点波动。比如,两个问题可能很像,但答案却不一样。为了缓解这个问题,我们可以用多查询的方法来检索。也就是说,我们先把原始问题扩展成好几个版本,然后用这些版本去检索 RAG 的上下文。
这通常是通过向一个生成式大语言模型(LLM)提问来实现的,让模型生成几个和原始问题相似但又不完全一样的问题。比如,你可以这样提示模型:
生成 10 个和以下问题相似但不完全相同的问题。
{query}
在机器学习里,你通常会用集成方法来减少波动,这里用的原理也是一样的。通过生成几个相似且相关的问题,我们可以针对每个问题从向量存储中检索上下文,这样就能得到更多的上下文片段。这些片段可以重新排序和裁剪,最终作为上下文发送给生成式模型,让模型用自然语言回答用户的问题。
结果合并
好啦,如果我们把所有新问题相关的片段都检索出来,那信息量就太大啦,根本没法处理。这里有两种方法可以把我们的方法精简一下。
互惠排名融合
当我们生成了一组新的问题,并且完成了针对每个问题的 k 近邻搜索(knn-search)以找到上下文之后,就需要把它们拼凑起来啦。这可以用互惠排名融合(Reciprocal Rank Fusion,RRF)算法来实现。
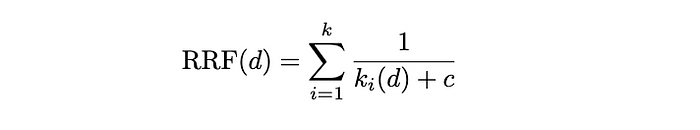
互惠排名融合。
这个函数会给每个文档(d)一个新的分数,其中会考虑文档在某个给定问题(k_i)检索中的排名。在这个函数里,c 只是一个常数,通常用 60 这个值。
在每个文档重新排名之后,你就可以根据 RRF 排名挑选出排名前 k 的文档,把它们作为上下文。这样就能得到一组和多个问题都相关的文档,而不仅仅是原始问题,从而减少波动。这种组合方法在 RAG-Fusion 论文中用到了,而且大幅提升了检索的准确性。
平均嵌入向量
虽然 RRF 是一个很强大的排名方法,但还有另一种出人意料的简单技巧,效果也很好:平均嵌入向量。RRF 是为所有生成的问题检索相关文档,而这种方法则是把所有问题合并成一个。也就是说,我们把所有问题的嵌入向量平均一下,然后用这个平均值去查询上下文。
一开始你可能会觉得这主意不太好。加法可不是一一对应的,好几组向量加起来可能得到相同的平均值。而且,你怎么能确定一组问题的中心点在嵌入空间里有任何相关性呢?
Ben Coleman 写了一篇很棒的文章,叫《为什么可以平均嵌入向量?》,专门讲的就是这个话题。简单来说,就是“维度的祝福”让两个不相关的向量在嵌入空间里靠得很近的可能性非常小,而那些靠得很近的向量肯定是有关系的。
我们来研究一下一组向量的平均值在检索设置中的表现。根据点积的规则,一个向量和一组向量之和的点积等于它们各自点积的和。这意味着,当我们计算一个向量 a 和一组向量的平均值之间的余弦相似度时,得到的结果就是每个向量与向量 a 的余弦相似度的平均值。所以,平均操作保留了所有查询的总体语义信号。
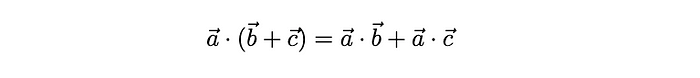
点积是分配的。
好的,那我们可以把平均嵌入向量看作是对所有向量的一种总结。这和我们一开始说的多查询设置有什么关系呢?如果我们把一组查询向量收集起来并平均一下,这就相当于对所有相似的查询做了一个总结,从而减少了检索的波动。
我们来定义 X_i 为查询向量 v_i 与向量 u 的余弦相似度。
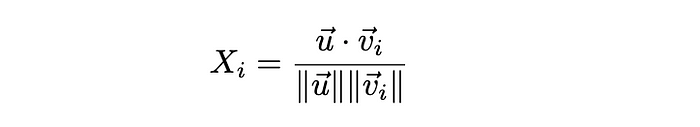
余弦相似度的定义。
由于点积是分配的,我们可以发现,我们这组向量与向量 u 的平均余弦相似度和使用所有向量的平均值是相同的。
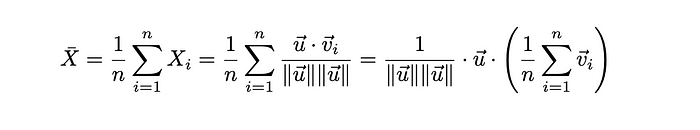
所有向量与向量 u 的平均余弦相似度等于使用平均向量的余弦相似度。
现在我们可以做一个熟悉的计算,也就是计算平均余弦相似度的方差。
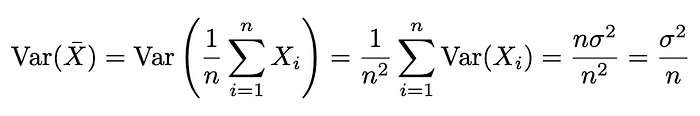
平均向量的方差降低了 1/n。
正如我们所见,方差降低了 1/n,其中 n 是查询的数量。所以如果我们用 10 个查询向量并把它们平均一下,检索的方差就会是只用原始查询时的 10%。所以这种方法显著降低了用户选择的查询表述的相似度波动。
比较
什么时候用 RRF,什么时候平均向量呢?这得看你的需求。RRF 在计算上更贵,因为你得为每个查询检索 k 个文档。平均之后,你只需要对平均向量做一次检索。这就导致了更低的延迟。
然而,当你使用 RRF 时,你可以保留每个查询的更多信息。这对于原始查询非常复杂的情况很有用,比如包含多个问题或者详细标准的查询。对于这样的问题,你可以用多查询的方法把任务拆开,每个生成的查询回答问题的一部分。平均向量在这种情况下就不行,而 RRF 就很适合。
总结
多查询 RAG 应用效果很好,也很容易实现。有很多方法可以处理这些结构,每种方法都有不同的优势。平均一组嵌入向量对于检索来说效果很好,因为它降低了检索的方差。
参考文献
为什么可以平均嵌入向量? — Ben Coleman, 2020
RAG-Fusion:一种新的检索增强生成方法 — Zackary Rackauckas, 2024