day37打卡
知识点回顾:@浙大疏锦行
- 过拟合的判断:测试集和训练集同步打印指标
- 模型的保存和加载
- 仅保存权重
- 保存权重和模型
- 保存全部信息checkpoint,还包含训练状态
- 早停策略
作业:对信贷数据集训练后保存权重,加载权重后继续训练50轮,并采取早停策略
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.optim as optim
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from tqdm import tqdm
import matplotlib.pyplot as plt
import warnings
from sklearn.metrics import classification_reportwarnings.filterwarnings("ignore")# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 设置GPU设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 数据预处理
data = pd.read_csv(r'data.csv')
data = data.drop(['Id'], axis=1)# 标签编码
home_ownership_mapping = {'Own Home': 1,'Rent': 2,'Have Mortgage': 3,'Home Mortgage': 4
}
data['Home Ownership'] = data['Home Ownership'].map(home_ownership_mapping)years_in_job_mapping = {'< 1 year': 1,'1 year': 2,'2 years': 3,'3 years': 4,'4 years': 5,'5 years': 6,'6 years': 7,'7 years': 8,'8 years': 9,'9 years': 10,'10+ years': 11
}
data['Years in current job'] = data['Years in current job'].map(years_in_job_mapping)# 独热编码
data = pd.get_dummies(data, columns=['Purpose'])# Term列映射与重命名
term_mapping = {'Short Term': 0,'Long Term': 1
}
data['Term'] = data['Term'].map(term_mapping)# 列名验证
original_columns = data.columns.tolist()
data.rename(columns={'Term': 'Long Term'}, inplace=True)
new_columns = data.columns.tolist()if 'Long Term' not in new_columns:print(f"警告:列名重命名失败!原始列名: {original_columns}")if 'Term' in new_columns:print("使用原始列名'Term'继续处理...")else:raise KeyError("无法找到'Term'或'Long Term'列!")# 重新生成连续特征列表并验证
continuous_features = data.select_dtypes(include=['int64', 'float64']).columns.tolist()
print(f"连续特征列表: {continuous_features}")# 缺失值处理
for feature in continuous_features:if feature not in data.columns:print(f"警告:列 '{feature}' 不存在,跳过该列!")continueif data[feature].isnull().sum() > 0:if data[feature].dtype in [np.float64, np.int64]:fill_value = data[feature].median()else:fill_value = data[feature].mode()[0]data[feature].fillna(fill_value, inplace=True)print(f"已填充 {feature} 列的 {data[feature].isnull().sum()} 个缺失值,填充值: {fill_value}")# 划分训练集和测试集
X = data.drop(['Credit Default'], axis=1)
y = data['Credit Default']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 归一化数据
scaler = MinMaxScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)# 转换为PyTorch张量并移至GPU
X_train = torch.FloatTensor(X_train).to(device)
y_train = torch.LongTensor(y_train.values).to(device)
X_test = torch.FloatTensor(X_test).to(device)
y_test = torch.LongTensor(y_test.values).to(device)# 定义MLP模型
class MLP(nn.Module):def __init__(self, input_size):super(MLP, self).__init__()self.fc1 = nn.Linear(input_size, 10)self.relu = nn.ReLU()self.fc2 = nn.Linear(10, 2)def forward(self, x):out = self.fc1(x)out = self.relu(out)out = self.fc2(out)return out# 实例化模型
input_size = X_train.shape[1]
model = MLP(input_size).to(device)# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练模型
def train_model(model, optimizer, num_epochs, save_path, is_continue=False):best_test_loss = float('inf')best_epoch = 0patience = 50counter = 0early_stopped = Falsetrain_losses = []test_losses = []epochs = []start_time = time.time()if is_continue:total_epochs = num_epochsprint(f"继续训练 {num_epochs} 轮")else:total_epochs = num_epochsprint(f"开始初始训练 {num_epochs} 轮")with tqdm(total=total_epochs, desc="训练进度", unit="epoch") as pbar:for epoch in range(total_epochs):# 前向传播model.train()outputs = model(X_train)loss = criterion(outputs, y_train)# 反向传播和优化optimizer.zero_grad()loss.backward()optimizer.step()# 记录损失值并更新进度条if (epoch + 1) % 200 == 0:model.eval()with torch.no_grad():test_outputs = model(X_test)test_loss = criterion(test_outputs, y_test)model.train()train_losses.append(loss.item())test_losses.append(test_loss.item())epochs.append(epoch + 1)# 调试输出:打印当前损失值print(f"Epoch {epoch+1}, Train Loss: {loss.item():.4f}, Test Loss: {test_loss.item():.4f}")pbar.set_postfix({'Loss': f'{loss.item():.4f}'})# 早停逻辑if test_loss.item() < best_test_loss:best_test_loss = test_loss.item()best_epoch = epoch + 1counter = 0torch.save(model.state_dict(), save_path)else:counter += 1if counter >= patience:print(f"早停触发!在第{epoch+1}轮,测试集损失已有{patience}轮未改善。")print(f"最佳测试集损失出现在第{best_epoch}轮,损失值为{best_test_loss:.4f}")early_stopped = Truebreak# 更新进度条pbar.update(1)time_all = time.time() - start_timeprint(f'Training time: {time_all:.2f} seconds')# 调试输出:打印损失列表print(f"训练完成后,记录了 {len(epochs)} 个损失值")if epochs:print(f"Epochs范围: {min(epochs)} 到 {max(epochs)}")print(f"训练损失范围: {min(train_losses):.4f} 到 {max(train_losses):.4f}")print(f"测试损失范围: {min(test_losses):.4f} 到 {max(test_losses):.4f}")return model, best_test_loss, best_epoch, early_stopped, train_losses, test_losses, epochs# 第一阶段训练
initial_save_path = 'initial_model.pth'
model, best_test_loss, best_epoch, early_stopped, train_losses1, test_losses1, epochs1 = train_model(model, optimizer, num_epochs=20000, save_path=initial_save_path
)# 可视化第一阶段损失曲线
plt.figure(figsize=(10, 6))
plt.plot(epochs1, train_losses1, label='初始训练 - 训练损失')
plt.plot(epochs1, test_losses1, label='初始训练 - 测试损失')# 设置坐标轴范围
if epochs1: # 确保有数据plt.xlim(min(epochs1), max(epochs1))all_losses = train_losses1 + test_losses1plt.ylim(min(all_losses) * 0.9, max(all_losses) * 1.1)plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('初始训练阶段的损失曲线')
plt.legend()
plt.grid(True)
plt.show()# 评估初始训练模型
model.eval()
with torch.no_grad():outputs = model(X_test)_, predicted = torch.max(outputs, 1)correct = (predicted == y_test).sum().item()accuracy = correct / y_test.size(0)print(f'初始训练后的测试集准确率: {accuracy * 100:.2f}%')print(classification_report(y_test.cpu().numpy(), predicted.cpu().numpy(), target_names=['未违约', '违约']))# 第二阶段训练:加载权重并继续训练50轮
print("\n===== 开始第二阶段训练:加载权重并继续训练50轮 =====")# 重新实例化模型
continued_model = MLP(input_size).to(device)
continued_model.load_state_dict(torch.load(initial_save_path))# 定义新的优化器
continued_optimizer = optim.SGD(continued_model.parameters(), lr=0.001)# 继续训练50轮
continued_save_path = 'continued_model.pth'
continued_model, best_test_loss2, best_epoch2, early_stopped2, train_losses2, test_losses2, epochs2 = train_model(continued_model, continued_optimizer, num_epochs=50, save_path=continued_save_path, is_continue=True
)# 可视化第二阶段损失曲线
plt.figure(figsize=(10, 6))
plt.plot(epochs2, train_losses2, label='继续训练 - 训练损失')
plt.plot(epochs2, test_losses2, label='继续训练 - 测试损失')# 设置坐标轴范围
if epochs2: # 确保有数据plt.xlim(min(epochs2), max(epochs2))all_losses2 = train_losses2 + test_losses2plt.ylim(min(all_losses2) * 0.9, max(all_losses2) * 1.1)# 添加调试输出
print(f"绘图数据 - Epochs: {epochs2}")
print(f"绘图数据 - 训练损失: {[round(loss, 4) for loss in train_losses2]}")
print(f"绘图数据 - 测试损失: {[round(loss, 4) for loss in test_losses2]}")plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('继续训练阶段的损失曲线')
plt.legend()
plt.grid(True)
plt.show()# 评估继续训练后的模型
continued_model.eval()
with torch.no_grad():outputs = continued_model(X_test)_, predicted = torch.max(outputs, 1)correct = (predicted == y_test).sum().item()accuracy = correct / y_test.size(0)print(f'继续训练后的测试集准确率: {accuracy * 100:.2f}%')print(classification_report(y_test.cpu().numpy(), predicted.cpu().numpy(), target_names=['未违约', '违约']))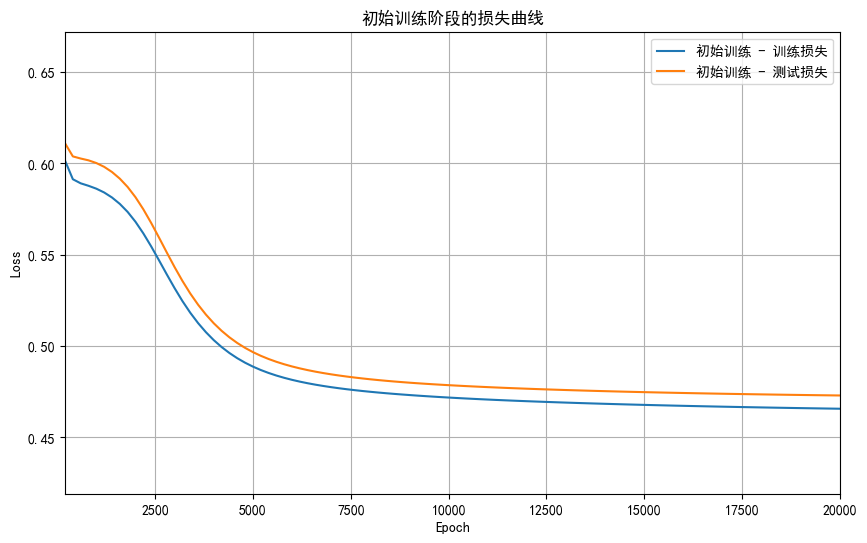
Training time: 0.19 seconds
训练完成后,记录了 0 个损失值
绘图数据 - Epochs: []
绘图数据 - 训练损失: []
绘图数据 - 测试损失: []
继续训练后的测试集准确率: 76.73%precision recall f1-score support未违约 0.75 0.99 0.86 1059违约 0.93 0.22 0.36 441accuracy 0.77 1500macro avg 0.84 0.61 0.61 1500
weighted avg 0.81 0.77 0.71 1500