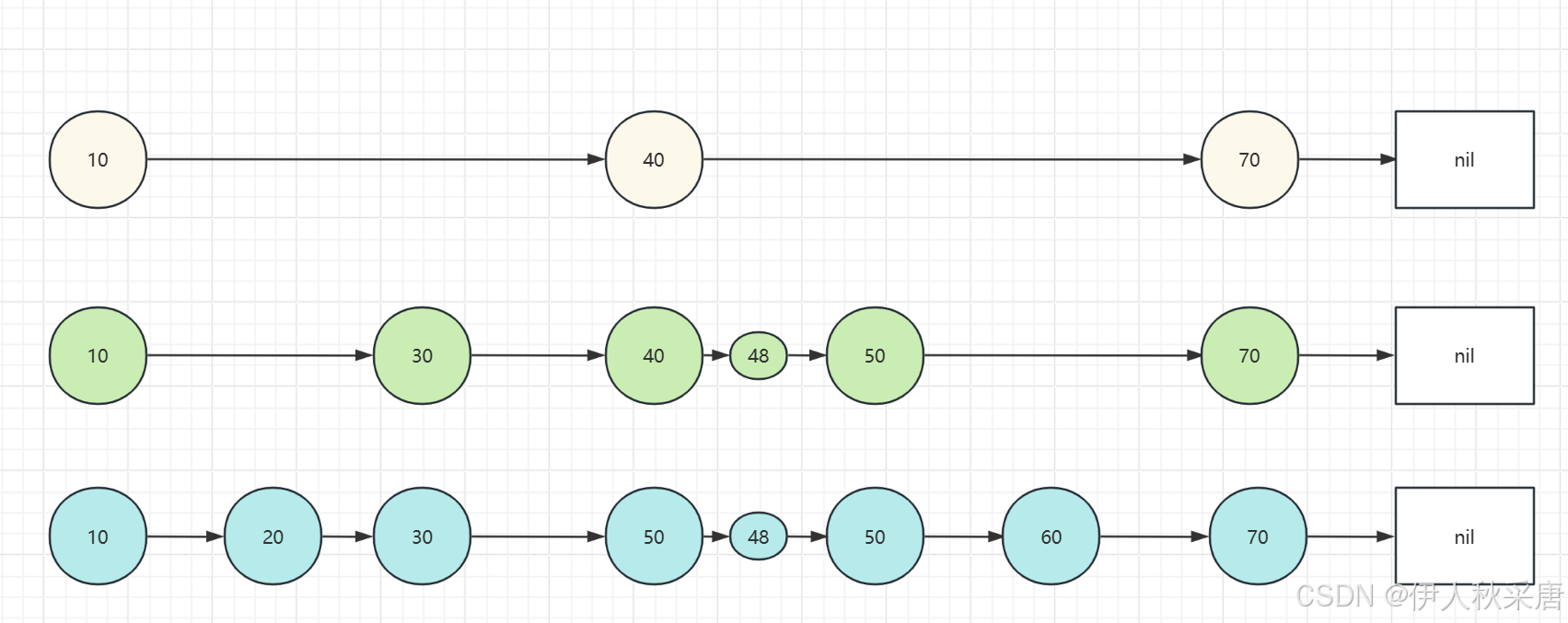
Redis 中跳表
跳表主要是通过多层链表来实现,底层链表保存所有元素,而每一层链表都是下一层的子集。 插入时,首先从最高层开始查找插入位置,然后随机决定新节点的层数,最后在相应的层中插入节点并更新指针。 删除时,同样从最高层开始查找要删除的节点,并在各层中更新指针,以保持跳表的结构。 查找时,从最高层开始,逐层向下,直到找到目标元素或确定元素不存在。查找效率高,时间复杂度为0(logn)。
跳表,一句话概括:就是一个多层索引的链表,每一层索引的元素在最底层的链表中可以找到的元素(这一点 和B+树是一样的),如下图所示,这就是一个简单的跳表实现了,每个颜色代表一层,绿色的就是链表的最底层了。
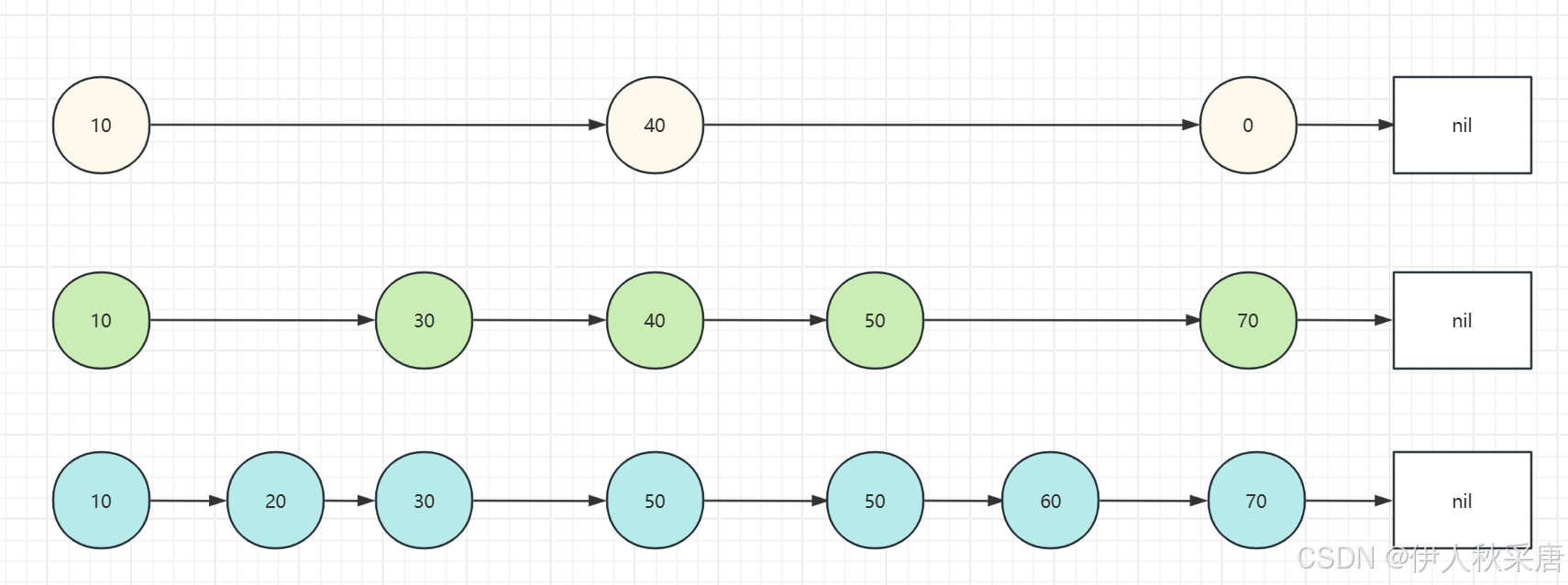
1) 查询元素:
这里我们与传统的链表进行对比,来了解跳表查询的高效。假设我们要查找 50 这个元素,如 果通过传统链表的话(看最底层的查询路线),需要查找4次,查找的时间复杂度为 O(n)。但如果使用跳表的话,其只需要从最上面的 10开始,首先跳到40,发现目标元素比40大,然后对比后一个元素比70 小,于是就前往下一层进行查找,然后 40 的下个 50 刚好符合目标,就直接返回就可以了,这个过程的 跳转次数是3次,即 10->40(顶层)->40(第二层)->50(第二层),其流程如下图所示:
跳表的平均时间查询复杂度是O(logn),最差的时间复杂度是O(n)。
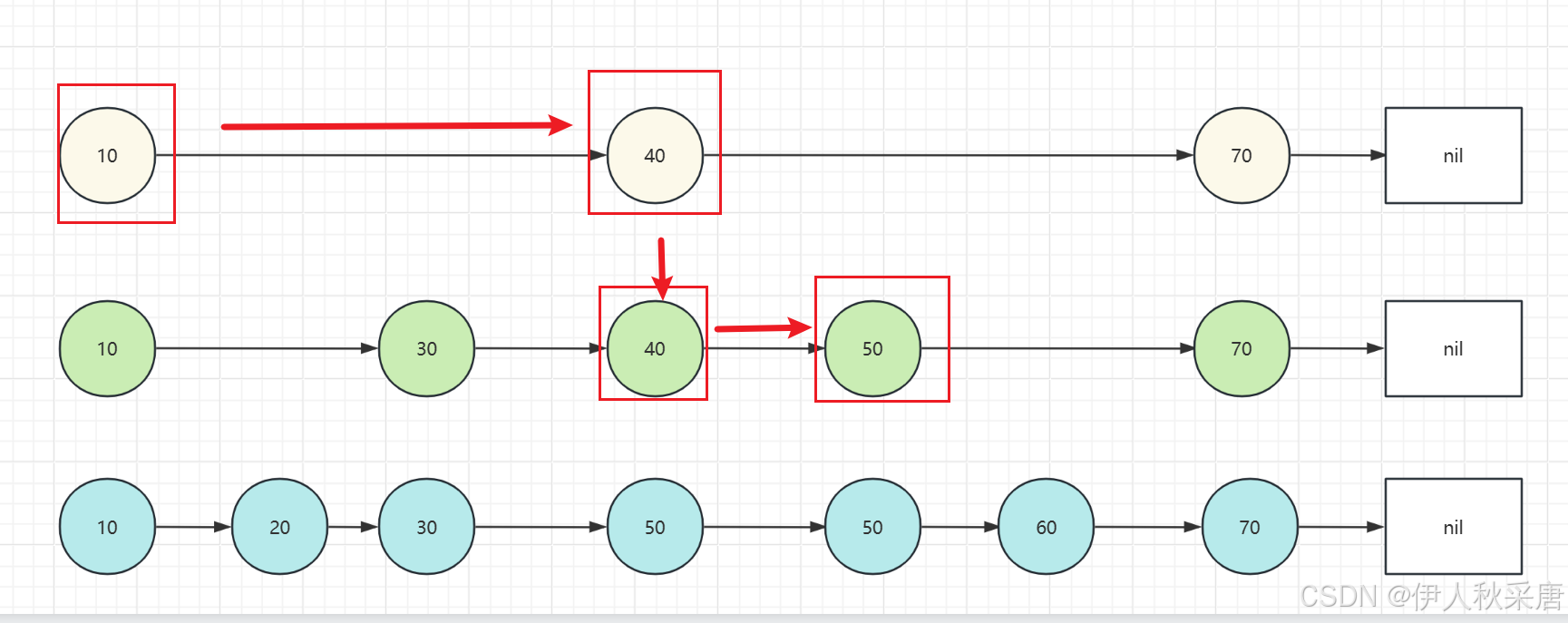
2)插入元素:
我们插入一条 score 为 48 的数据先需要定位到第一个比 score 大的数据。如图所示,一下子就可以定位到 50 了,这里和查询的过程(上文所示)是一样的。 在定位到对应节点之后,具体是在当前节点创建数据还是增加一个层级这个是随机的,这里假设设置为2 层定位层级后,再将每一层的链表节点进行补齐,就是在 40 与 50 之间插入一个新的链表节点 48,插入 过程与链表插入是一样的。 最终实现的效果如下图所示: