4-香豆酸:CoA连接酶晶体-文献精读138
Crystal structures of a Populus tomentosa 4-coumarate:CoA ligase shed light on its enzymatic mechanisms
杨树(Populus tomentosa)4-香豆酸:CoA连接酶的晶体结构揭示了其酶促机制

摘要
4-香豆酸:CoA连接酶(4CL)是植物特有的苯丙烷类代谢途径的核心酶。它催化羟基肉桂酸-CoA硫酯的合成,这些硫酯是木质素和其他重要苯丙烷类化合物的前体,反应过程包括形成羟基肉桂酸-AMP酰胺和随后AMP被CoA取代的亲核替代反应。在本研究中,我们分别在2.4、2.5和1.9 Å分辨率下,确定了杨树(Populus tomentosa)4CL1的晶体结构,包括未修饰(apo)形式以及与AMP和腺苷5′-(3-(4-羟基苯基)丙基)磷酸(APP,一种中间体类似物)复合物的形式。4CL1由两个球状结构域通过一个灵活的连接区连接而成。较大的N-结构域包含底物结合口袋,而C-结构域包含催化残基。在APP结合后,C-结构域相对于N-结构域旋转了81°。4CL1-APP的晶体结构揭示了其底物结合口袋。通过晶体结构以及突变和酶活性研究,我们鉴定了催化活性所需的残基(Lys-438、Gln-443和Lys-523)以及底物结合的残基(Tyr-236、Gly-306、Gly-331、Pro-337和Val-338)。我们还证明了结合口袋的大小是决定4CL1底物特异性的最重要因素。这些发现为揭示4CL的酶促机制提供了新的见解,并为这些酶的生物工程改造奠定了坚实的基础。
引言
苯丙烷类代谢途径是植物中最重要的二次代谢途径之一。它将来自初级代谢途径的碳流(以苯丙氨酸形式)转化为一系列多样的产物,以应对内外部压力。这些产物在芳香气味、果实风味和颜色的形成中起着重要作用,并且作为分子信号、抗微生物物质、花卉色素、抗氧化剂和紫外线防护剂等发挥功能。这些产物对人类生活和生态系统具有重要意义。例如,许多类黄酮具有抗氧化和抗肿瘤的特性,几千年来一直作为促进健康的药物使用。该途径最突出的产物可能是木质素,它是仅次于纤维素的最丰富的天然聚合物。据估计,每年约有25%到30%的二氧化碳被转化并以木质素的形式沉积。木质素赋予植物生长所需的刚性和机械强度,并使植物对水和病原体的侵袭具有不可渗透性。然而,木质素不易降解,并且是造纸工业主要的污染源。它还降低了饲草的消化性和质量,从而减少了畜牧业的生产力。
近年来,作为可再生碳源的生物质用于生产生物燃料和生物材料变得越来越重要,这是追求可持续发展的一个关键领域。原料的组成,尤其是木质素的含量,极大地决定了生物质转化的效率和工业价值(Boudet等,2003;Ragauskas等,2006)。利用基因工程优化植物特性以便更好地利用生物质,将在这一领域中发挥至关重要的作用,这需要对木质素生物合成相关酶的结构与功能关系有深入的理解。
苯丙烷类代谢途径涉及许多酶。该途径从苯丙氨酸的脱氨反应开始,由苯丙氨酸氨基裂解酶催化,生成反式肉桂酸,随后由肉桂酸4-羟化酶羟化为4-香豆酸(4-羟基肉桂酸)。然后,4-香豆酸被4-香豆酸:CoA连接酶(4CL;EC 6.2.1.12)激活,转化为4-香豆酰CoA。该化合物通过羟基肉桂酰转移酶转化为4-香豆酰奎奈酸或4-香豆酰莰烯酸,随后被4-香豆酸3-羟化酶羟化为咖啡酰奎奈酸或咖啡酰莰烯酸。这些产物再被羟基肉桂酰转移酶转化为咖啡酰CoA硫酯,并且奎奈酸和莰烯酸被循环利用。咖啡酰-CoA随后通过咖啡酰-CoA O-甲基转移酶甲基化形成阿魏酰-CoA(Hoffmann等,2004)。4CL蛋白在该途径中起着至关重要的作用,因为其酶促反应的产物——羟基肉桂酰-CoA硫酯——是木质素、类黄酮、 stilbenes 及其他苯丙烷类化合物合成的前体。
4CL酶在木材的不同组织和发育阶段有差异性表达,并且在植物中存在多个具有不同底物特异性的同种型(Voo等,1995;Ehlting等,1999;Lindermayr等,2002;Zhang等,2003;Hamberger和Hahlbrock,2004),这表明4CL可能通过调节不同羟基肉桂酰CoA硫酯的合成速率,在苯丙烷类代谢途径的调控中发挥重要作用(Knobloch和Hahlbrock,1975)。以杨树(Populus tremuloides,震颤杨)为例,已鉴定出两种4CL同种型。其中之一被指定为4CL1,发现其在木材的发育木质部中表达,并与木质素的生物合成有关,而另一种4CL2则在茎和叶的表皮细胞中参与木质素以外的苯丙烷类物质的生物合成(Hu等,1998)。另一方面,4CL的活性决定了碳流向苯丙烷类代谢途径的整体方向。由于这些原因,4CL已成为遗传工程研究的重点,通过抑制4CL的表达进而减少木质素的生产,已取得不同程度的成功(Lee等,1997;Kajita等,2002;Li等,2003)。
大多数4CL蛋白存在于高等植物中。最近,Silber等(2008)在苔藓植物(Physcomitrella patens)中鉴定出了一个4CL基因家族。4CL是所谓的ANL超家族的成员。该超家族的名称来源于三个亚家族:脂酰-CoA合成酶亚家族(4CL属于其中);非核糖体肽合成酶的腺苷酸化结构域;以及荧光素酶亚家族(Gulick,2009)。它以前被称为腺苷酸形成超家族(Babbitt等,1992),因为该超家族的所有成员在其酶促机制中共享一个保守的腺苷酸化部分反应,尽管这些酶催化的整体反应非常多样。尽管ANL酶含有10个高度保守的氨基酸序列片段,分别称为A1到A10(Marahiel等,1997),但来自不同亚家族的蛋白质之间的总体序列相似性较低。迄今为止,已有多个非4CL蛋白的晶体结构被确定,并已广泛综述(Gulick,2009),但没有通过X射线晶体学对4CL进行表征。因此,4CL蛋白的晶体结构将大大提高我们对这一类酶的理解。
在本文中,我们报告了通过X射线晶体学和突变分析对杨树(Populus tomentosa,白杨)4CL1的三维结构表征。4CL1是从该物种中鉴定出的两种4CL蛋白之一。与P. tremuloides类似,P. tomentosa中也鉴定出了4CL1和4CL2两个基因。P. tomentosa 4CL1与P. tremuloides 4CL1具有97%的序列相似性(图1)。我们分别在2.4、2.5和1.9 Å分辨率下解决了P. tomentosa 4CL1的apo型、AMP复合物型和腺苷5′-(3-(4-羟基苯基)丙基)磷酸(APP)复合物型的晶体结构。用于共晶的化合物APP是腺苷5′-香豆酰磷酸的模拟物,腺苷5′-香豆酰磷酸是4CL腺苷酸形成步骤的产物。与腺苷5′-香豆酰磷酸不同,APP是磷酸酯而非磷酸-羧酸酐,且其碳-碳双键被还原为碳-碳单键(图2)。基于这些晶体结构和基于结构的突变研究,我们鉴定了4CL1酶促机制所必需的残基。我们还确定了4CL1的底物结合口袋及其底物特异性的结构基础。我们的研究为理解这一重要酶的酶促机制和生物工程提供了坚实的基础。

图 1. 本文中提到的几种 ANL 酶的序列比对。 P. tomentosa 4CL1、P. tremuloides 4CL1、G. max 4CL1、Arabidopsis 4CL4、P. patens 4CL1(去除了 36 个 N 端残基以简化图示)和 S. enterica Acs。黑底白字表示完全保守的残基,灰底白字表示高度保守的残基,灰底黑字表示保守的残基。与羟基肉桂酸结合相关的残基用三角形标出,与酶功能相关的残基用星号标出。
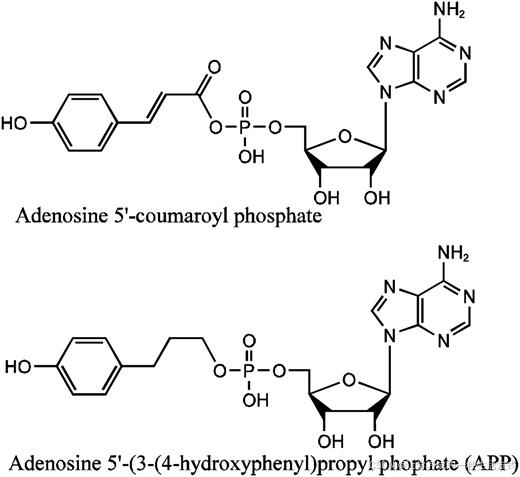
图 2. 4CL1 的中间体及其中间体类似物。 腺苷 5′-香豆酰磷酸的分子结构,这是 4CL 酶反应的中间体,以及其类似物 APP,后者用于结晶化。
结果
整体结构
P. tomentosa 4CL1 蛋白由 536 个残基组成。4CL1 的 apo 蛋白晶体结构通过单一异常散射法结合分子替代法解决,使用萤火虫荧光素酶(Conti et al., 1996)作为模型。然后,该结构作为模型,用于解决 AMP-4CL1 和 APP-4CL1 复合物的结构,均使用分子替代法。所有结构的质量都非常优秀(表 1)。晶体学 R 因子分别为 0.192、0.204 和 0.176,自由 R 因子分别为 0.243、0.241 和 0.196,分别对应于 apo、AMP 复合物和 APP 复合物形式。
Table 1.
Statistics on Data Collection, Structure Refinement, and Model Assessment
| Crystal | SeMet apo-4CL1 | apo-4CL1 | AMP-4CL1 | APP-4CL1 |
|---|---|---|---|---|
| Space group | P212121 | P212121 | I213 | I213 |
| Cell parameters (Å) | a = 51.738, b = 78.739, c = 118.787 | a = 51.740, b = 78.736, c = 118.789 | a = b = c = 162.34 | a = b = c = 161.51 |
| Wavelength (Å) | 0.9791 (peak) | 1.000 | 1.5418 | 0.97916 |
| Resolution (last shell) (Å) | 50–3.0 (3.11–3.0) | 50–2.4 (2.48–2.4) | 57–2.5 (2.64–2.5) | 34–1.9 (2.0–1.9) |
| Total reflections | 144,516 | 253,168 | 124,694 | 527,176 |
| Unique reflections | 18,855 | 19,643 | 24,708 | 55,010 |
| Completeness (last shell) | 100.0% (99.9%) | 97.1% (87.2%) | 99.9% (99.5%) | 100.0% (100.0%) |
| Redundancy (last shell) | 7.7 (5.8) | 12.9 (12.5) | 5.0 (3.9) | 9.6 (8.9) |
| I/σ(I) (last shell) | 13.8 (3.9) | 38.1 (8.3) | 17.8 (3.2) | 17.2 (6.2) |
| Rsym (last shell) | 12.6% (36.3%) | 8.2% (28.7%) | 8.5% (38.1%) | 8.8% (35.0%) |
| Refinement Statistics | ||||
| R | 19.2% | 20.4% | 17.7% | |
| Free R | 24.3% | 24.1% | 19.6% | |
| Protein atoms | 3,946 | 4,048 | 4,055 | |
| Water molecules | 243 | 124 | 555 | |
| Heteroatoms | 0 | 23 | 78 | |
| RMSDs from ideal model | ||||
| Bond (Å) | 0.007 | 0.007 | 0.005 | |
| Angles | 1.36° | 1.31° | 1.33° | |
| Ramachandran plots | ||||
| Most favored region | 90.4% | 90.5% | 91.2% | |
| Additionally allowed region | 9.2% | 9.0% | 8.4% | |
| Generously allowed region | 0.4% | 0.4% | 0.4% | |
| Disallowed regions | 0% | 0% | 0% |
4CL1 的整体结构由两个独特的球状结构域组成。较大的结构域由 N 端的 434 个残基组成,而较小的结构域由第 435 到 536 位的残基组成(图 3A)。在本文中,这两个结构域分别称为 N 结构域和 C 结构域。
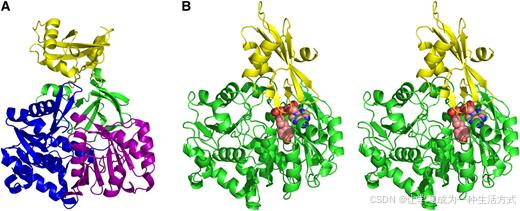
图 3. 4CL1 的整体结构。 (A) apo-4CL1 的结构。C 结构域显示为黄色。N 结构域的三个亚结构域,分别为 N1、N2 和 N3,按 Conti 等人(1996)使用的方案,分别显示为蓝色、紫色和绿色。
(B) 4CL1-APP 复合物的立体视图。N 结构域和 C 结构域分别显示为绿色和黄色。APP 显示为球体,C、O 和 N 原子分别以粉红色、红色和蓝色表示。立体视图的三维视觉信息可以通过立体镜查看,或者通过聚焦左右眼在左、右立体图像上直接观察。
4CL1 的 N 结构域可以分为三个亚结构域,如萤火虫荧光素酶的结构所示(Conti 等人,1996)。这三个亚结构域,分别命名为 N1、N2 和 N3,是由 N 结构域中不连续的残基组成(图 3A)。N1 和 N2 是两个较大的亚结构域,它们具有非常相似的结构。每个亚结构域都有一个中央的八股 β-折叠,并且在一侧被两个 α-螺旋夹住,在另一侧被四个 α-螺旋夹住。两个中央 β-折叠都由六个平行 β-链和两个反向平行的 β-链构成,位于折叠的两端。这两个亚结构域的拓扑结构也非常相似(Conti 等人,1996)。N3 亚结构域比其他两个小。该亚结构域的大部分是由八个 β-链形成的扭曲 β-桶;其中只有一个 α-螺旋和一个短的 310-螺旋。该 β-桶近似呈碗形,凹面朝向 N 结构域的中心。来自该亚结构域的两个短 β-链与其他两个亚结构域中央 β-折叠的反向平行 β-链紧密配对。
4CL1 的 C 结构域的中心是一个由三条 β-链组成的混合 β-折叠。折叠的一侧有两个 α-螺旋和一个短的、由两条反向平行 β-链组成的 β-折叠;另一侧则有一个单独的 α-螺旋。
结构比较表明,整体折叠在 ANL 酶之间高度保守。实际上,所有这些蛋白的 N 结构域与 4CL1 的 N 结构域对接后,355 到 391 个 Cα 原子的均方根偏差(RMSD)为 1.9 到 2.2 Å,而 C 结构域的 RMSD 为 0.9 到 1.7 Å,涉及 71 到 103 个 Cα 原子。与 4CL1 APP 复合物结构最为相似的是人类酰基辅酶 A 合成酶中链家族成员 2A 与丁酸 CoA 硫酯的复合物。在这两个结构的两个结构域中,共有 481 个 Cα 原子,RMSD 为 1.9 Å。
APP 和 AMP 结合的 4CL1 晶体是同形的(表 1)。这两种复合物形式的 4CL1 结构基本相同,RMSD 为 0.4 Å。因此,除非另有说明,否则我们将在后续讨论中不区分 AMP 和 APP 复合物的结构。
羟基肉桂酸结合口袋
在 4CL1 结构中,发现了一个位于较大 N 结构域中的腔体。在 APP 复合物结构中,一组强电子密度峰与 APP 分子高度吻合(图 4A),位于该腔体内部。结构比较表明,这个腔体与其他 ANL 酶的配体结合口袋重合良好,明确证明该腔体是 4CL1 的配体结合位点。
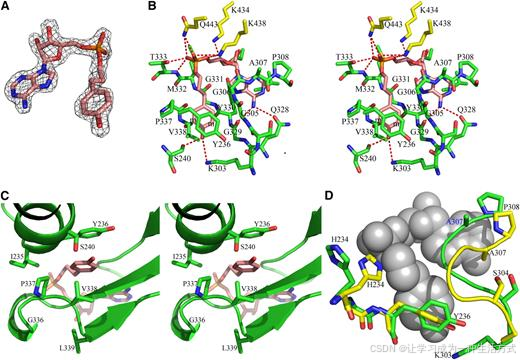
图 4. 4CL1 配体结合位点与 APP-4CL1 交互作用。 (A) 结合的 APP 分子周围的 σA 加权 2Fo−Fc 去除图,等高线为 6σ。该图与配体的最终模型重叠。配体的 C、O 和 N 原子分别以粉红色、红色和蓝色表示。
(B) 4CL1-APP 交互作用的立体视图。APP 的 C、O 和 N 原子分别显示为粉红色、红色和蓝色。C 结构域的残基显示为黄色。APP 与 4CL1 之间的氢键用红色虚线表示。字母 m 标记了苯环的 meta 位点,在这些位置发生取代。
(C) 以与 (B) 不同的视角显示的结合位点立体视图,突出显示了 Pro-337 和 Val-338 残基。
(D) APP 结合后 4CL1 羟基肉桂酸结合口袋的结构变化。apo 型和 APP 复合型的 4CL1 结构分别显示为黄色和绿色。结合的 APP 显示为球体。为了突出 Tyr-236 和 S304GGAP308 的变化,删除了一些残基。
羟基肉桂酸结合口袋
4CL1 结构中的羟基肉桂酸和 AMP 结合口袋位于腔体的两个相对独立的部分,并且它们具有不同的蛋白质-底物相互作用模式。4CL1 的羟基肉桂酸结合口袋定义得非常明确。沿着与 APP 的 4-羟基苯基的垂直方向,这个结合口袋由一侧的 Tyr-236 侧链和另一侧的 Tyr-330 和 Gly-331 主链定义。在 4-羟基苯基的横向,结合口袋由一侧的 Gly-305 主链和另一侧的 Pro-337 和 Val-338 残基定义(图 4B 和 4C)。
这个羟基肉桂酸结合口袋有两个独特的结构特征。第一个特征是 Tyr-236 侧链和 Tyr-330-Gly-331 主链之间的接近和平行排列。Tyr-330 侧链指向远离口袋的一侧,因此该残基的主链仅有助于底物结合。另一方面,如果 Gly-331 被其他非 Gly 残基取代,它的侧链将指向结合的底物。APP 的 4-羟基苯基被插入在 Tyr-236 侧链和 Tyr-330 和 Gly-331 主链之间,并与其形成非常接近的接触(图 4B)。APP 的两个 4-羟基苯基与 Tyr-236 几乎平行,平面间距约为 4 Å(图 4B 和 4C)。Tyr-330 和 Gly-331 的主链与 APP 的 4-羟基苯基平行,并形成紧密的范德华相互作用,原子间距离最小可达 3.4 Å(即 Gly-331 的羰基碳原子与丙基部分的 C3 原子之间)。Val-338 的侧链也与这侧的 4-羟基苯基相互作用(图 4B 和 4C)。
该结合口袋的第二个重要结构特征是沿着与 APP 的 4-羟基苯基横向的方向,由 Gly-336、Pro-337 和 Val-338 残基形成的高度膨胀的环。这一环位于一个 310-螺旋和一个 β-折叠之间(图 4C)。在 apo 和复合物结构中,它都采取相同的构象。这一不寻常的结构是由环的两端之间的短距离以及 Gly-336 和 Pro-337 之间的顺式肽键造成的。这个膨胀的环沿横向方向形成了结合口袋的一侧,而 Gly-305、Gly-306 和 Gly-329 的主链则位于另一侧(图 4B)。
在所有的主链-底物相互作用中,主链总是与底物在垂直于肽平面的方向上相互作用,从而排除了氢键的形成,确保只有疏水相互作用参与底物结合。事实上,APP 的 4-羟基苯基几乎完全由 4CL1 的疏水基团保持,只有 4-羟基基团与 Ser-240 和 Lys-303 的侧链形成氢键。
AMP 结合口袋
AMP-和 APP-复合物结构中的 AMP 部分主要与 N 结构域相互作用。A5,是 10 个高度保守序列之一(Fulda 等,1994;Marahiel 等,1997),对应于 4CL1 中的 Q328GYGMTEA335,提供了结合口袋大部分的表面。这个结合模体在 4CLs 中几乎完全保守(图 1)。
结合的 AMP 的腺苷环通过广泛的范德华相互作用被固定,其中一侧由 Tyr-330 的侧链苯基与环的一个侧面相互作用,另一侧由 Gly-306 和 Ala-307 的主链和侧链基团与环的另一侧相互作用。此外,腺苷的 N6 原子向 Gly-329 的羰基氧原子提供了一个氢键。N1 原子接受来自附近水分子的氢键(图 4B)。
几个氢键在核糖氧原子和 Arg-432、Lys-434、Lys-438 的侧链之间形成(图 4B)。磷酸基团与 Thr-333 和 Gln-443 的侧链以及 Thr-333 的主链 NH 基团形成氢键(图 4B)。核糖和磷酸基团的结合涉及到 N 结构域和 C 结构域的残基。尽管来自 N 结构域的残基(即 Thr-333 和 Arg-432)在 apo 型和 APP/AMP 复合物结构之间的位置变化很小,但 C 结构域的残基(即 Lys-434、Lys-438 和 Gln-443)只有在 4CL1 从 apo 形式的开放构象转变为复合物形式的闭合构象时,才能与 APP/AMP 发生相互作用(下面将讨论域间运动)。这三个残基位于 C 结构域的 N 末端,并在 ANL 酶中高度保守。它们可能负责 4CL1 配体结合诱导的构象变化。
配体结合诱导的构象变化
在 APP 或 AMP 结合后,观察到 4CL1 结构中既有局部也有全局的构象变化。
在 apo-4CL1 中,N 结构域和 C 结构域之间观察到一个较大的裂缝(图 3A),该裂缝通过 C 结构域相对于 N 结构域的 81°旋转而关闭(图 3B)。由于在 N 结构域和 C 结构域中都未发现重大内部变化,因此在 AMP 或 APP 结合后,结构域间裂缝的关闭是一个刚体运动。在其他 ANL 酶中也观察到了类似的现象。事实上,apo 和 AMP/APP 复合物结构的 N 结构域和 C 结构域可以分别以 1.1 和 0.9 Å 的 RMSD 重叠。已知 ANL 酶通过这种类型的结构域间运动,将来自 C 结构域的不同催化残基带到底物结合位点,进而催化各自的部分反应(Gulick, 2009)。
在 APP 结合后,还观察到一些局部的结构变化,特别是在羟基肉桂酸结合口袋中。在 APP 复合物结构中,Tyr-236 侧链绕 Cβ-Cγ 键旋转约 90°,且其主链原子相对于 apo 和 AMP 复合物结构的位置发生了约 1 Å 的位移(图 4D)。侧链的旋转为容纳羟基肉桂酸底物腾出了空间,而主链原子的位移则使得侧链的羟基能够与 Val-277 的羰基氧原子形成氢键。His-234 的侧链在 APP 结合后也发生了构象变化,其扭转角度 χ1 从 AMP 复合物结构中的 −175° 变为 APP 复合物结构中的 −75°(图 4D)。在 Alcaligenes sp 4-氯苯甲酸:CoA 连接酶中,类似的构象变化被认为在调节 CoA 进入活性中心方面起着重要作用(Reger 等,2008)。在 AMP 和 APP 复合物结构中,His-234 分别采取了形成腺苷酸和硫酯的构象。His-234 和 Tyr-236 的结构变化仅在 4CL1 结合其羟基肉桂酸底物时发生,因为这些残基在 apo 和 AMP 复合物结构中具有相同的构象。
另一个显著的结构变化发生在 apo 结构与 APP 和 AMP 复合物结构之间,特别是在 S304GGAP308 段中,与 apo 结构相比,在 APP 和 AMP 复合物结构中该段向底物移动了约 4 Å。Ala307-Pro308 的肽键也在底物结合时经历了从顺式到反式的转换,从而使 Ala-307 侧链移开(图 4D)。
涉及底物结合的残基的诱变研究
为了研究排列在 4CL1 羟基肉桂酸结合口袋中的残基的重要性,我们制备了多种突变体,如 Y236A、Y236F、Y236W、G331A、G305A、S240A 和 K303A,并对它们的酶活性进行了检测。
像 G331A 和 Y236W 这样的突变在结合位点引入空间冲突,完全抑制了 4CL1 活性,这可能是因为这些突变破坏了 4CL1 对其底物的亲和力。另一方面,Y236A 突变增强了 4CL1 活性(图 5),这可能是因为它减少了空间冲突,并增加了蛋白质对底物的亲和力。这些结果与 Gly-331 主链、Tyr-236 侧链和 4CL1 底物之间的紧密排列一致。有趣的是,Y236F 突变大大降低了 4CL1 对咖啡酸和阿魏酸的活性,但对 4-香豆酸的活性没有影响,尽管一些 4CL 蛋白在这一位置有 Phe。 这可能是因为该突变破坏了 Tyr-236 与 Val-277 之间的氢键,导致底物结合的热力学稳定性降低,特别是对于体积较大的底物。
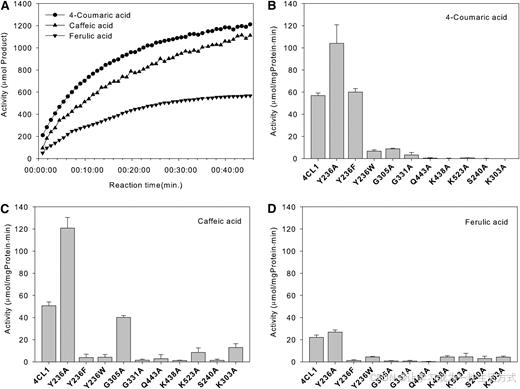
图 5. 4CL1 及其突变体的酶活性测试 (A) 野生型 4CL1 对 4-香豆酸、咖啡酸和阿魏酸的活性。
(B) 4CL1 及突变体对 4-香豆酸的活性。结果为 (B) 到 (D) 的五次测量的平均值,标准偏差已标示。
(C) 4CL1 及突变体对咖啡酸的活性。
(D) 4CL1 及突变体对阿魏酸的活性。
作为结合口袋的一部分,残基 Gly-305 位于 apo 结构中的一个环区域,该区域的温度因子非常高(60 到 70 Ų),而在 AMP 和 APP 复合物结构中则明显较低(20 到 30 Ų)。在底物结合后,这个环区域发生了显著的结构变化(图 4D)。这表明该区域的突变引入的空间冲突可以更容易地被解除。因此,G305A 突变减少了,但并未完全消除 4CL1 对 4-香豆酸和咖啡酸的活性(图 5)。
氢键的形成在 4CL1-APP 交互作用中也起着重要作用。Ser-240 和 Lys-303 突变,这些残基与 APP 的羟基形成氢键,会完全抑制 4CL1 的活性(图 5)。残基 Ser-240 在 4CLs 中高度保守,而 Lys-303 则不保守,其与底物的氢键也非常弱(氢键长度为 3.52 Å)。因此,我们提出,Ser-240 与底物的氢键在 4CLs 中是至关重要的,而 Lys-303 的氢键则重要但非必需。
催化中心
已知 ANL 酶具有两个独特的催化中心,均位于 C 结构域,负责两步部分反应。通过结构域间的运动,这些催化中心被带到底物结合位点,以催化各自的部分反应(Gulick, 2009)。一个严格保守的赖氨酸残基(在 4CL1 中为 Lys-523,图 1)已被确定为腺苷化半反应的催化中心(Conti 等,1997;May 等,2002;Gulick 等,2003;Jogl 和 Tong,2004;Nakatsu 等,2006)。突变(Branchini 等,2000;Horswill 和 Escalante-Semerena,2002)和乙酰化(Starai 等,2002)该残基会使 ANL 酶的底物腺苷化半反应完全失活,但对其硫酯形成活性的影响较小。酶活性测试显示,Lys-523 变为 Ala 会完全消除 4CL1 的活性(图 5),证明了该残基在酶机制中的重要性。
在 APP-4CL1 复合物结构中,Lys-438 和 Gln-443 的侧链靠近磷酸基团,并与之形成多个氢键。我们提出这两个残基构成了第二步部分反应的催化中心。在催化过程中,我们提出 Lys-438 的侧链将与香豆酰-AMP 复合物的羰基形成氢键,从而激活该化合物,以便通过 CoA 的巯基进行亲核取代。在 APP-4CL1 结构中,Lys-438 侧链的 Nε 原子与丙基部分的 C1 原子之间的距离为 3.9 Å(图 4B)。当香豆酰-AMP 复合物(4CL 腺苷化反应的产物)结合时,Lys-438 Nε 原子与 C1 上的羰基氧原子之间的距离将处于氢键形成的范围内。Gln-443 的侧链与磷酸基团形成了两个氢键。我们提出该残基的作用是在香豆酰-AMP 裂解和最终硫酯产品形成过程中,稳定磷酸基团上的负电荷。
我们制备了 K438A 和 Q443A 突变体,以及 K438A/Q443A 双突变体,并测试了它们的活性。这些突变完全消除了 4CL1 的活性(图 5)。这一结果验证了这些残基在 P. tomentosa 4CL1 酶机制中的关键作用。
讨论
大多数参与苯丙烷途径的酶已经通过 X 射线晶体学被表征(Ferrer 等,2008);然而,之前对 4CL 的结晶尝试未能成功。其他间接技术,如同源建模(Stuible 和 Kombrink,2001;Schneider 等,2003)和分子工程(Ehlting 等,2001;Lindermayr 等,2003),被用来研究 4CL 的结构与功能关系,利用非 4CL ANL 酶的结构作为模型。这些研究强调了 4CL 结构在理解这些蛋白功能中的重要性。由于 4CL 和非 4CL ANL 蛋白之间的序列同源性较低,这些方法并不十分令人满意。例如,在其中一项研究中,Schneider 等人(2003)基于同源建模、广泛的突变和活性测试,提出了阿拉伯芥 4CL2 的一个底物结合口袋。作者正确识别了像 Lys-320 和 Val-355(分别对应 P. tomentosa 4CL1 的 Lys-303 和 Val-338)这样的残基是底物结合口袋的一部分,但他们未能识别出 Tyr-253,P. tomentosa 4CL1 中 Tyr-236 的等位体,作为结合口袋的关键残基。我们发现 Y236A 突变体比野生型 P. tomentosa 4CL1 更具活性,突出了在缺乏晶体结构的情况下,同源建模和突变研究的局限性。
本研究提供的综合、高分辨率的结构信息,以及突变研究,使我们能够识别出 P. tomentosa 4CL1 和其他 4CL 酶中对催化活性和底物结合至关重要的残基,以及决定底物特异性的结构元素。
毛白杨 (P. tomentosa) 4CL1 的底物特异性由底物结合口袋的大小决定
毛白杨 4CL1 的羟基肉桂酸底物结合口袋主要由疏水基团构成(图 4B)。这与疏水相互作用在蛋白质与其小分子配体结合中起主要作用的发现相一致(Wang 等,2004)。因此,毛白杨 4CL1 的配体特异性并非基于氢键的形成,而是基于结合口袋对配体大小的识别,特别是由前述的结构特征决定。
第一个结构特征(即 Tyr-236 侧链与 Tyr330-Gly331 主链之间的紧密平行排列)被认为是 4CLs 特异性的决定因素,尤其是对非芳香族化合物的排除,因为 Gly-331 与 Tyr-236 之间的距离仅允许苯基衍生物的结合。其他化合物则过于厚实,无法容纳其中。Y236A 突变解除该区域的空间冲突,提高了毛白杨 4CL1 的活性,可能是因为该突变体对羟基肉桂酸底物具有更高亲和力,但以牺牲特异性为代价。
APP 分子中 4-羟苯基基团的两个间位处于不同环境,这可能解释了毛白杨 4CL1 对不同取代羟基肉桂酸底物的特异性。其中一个间位紧密堆叠在毛白杨 4CL1 结构上,几乎没有空间容纳取代基(图 4B)。另一个间位则位于 Val-338 侧链附近,并被一个空腔包围(图 4C),该空腔可容纳咖啡酸和阿魏酸中的 3-羟基和 3-甲氧基。这解释了毛白杨 4CL1 无法激活像松柏酸这样的 3,5-双取代羟基肉桂酸底物。
由于底物结合口袋周围残基的高度保守性,大多数 4CL 蛋白的底物结合口袋预计与毛白杨 4CL1 类似。大多数已表征的 4CL 酶对松柏酸无活性,是因为它们的底物结合口袋不够大,无法容纳该底物,这与毛白杨 4CL1 一样。有趣的是,大豆(Glycine max)4CL1(Lindermayr 等,2002)和拟南芥 4CL4(Schneider 等,2003;Hamberger 和 Hahlbrock,2004)对松柏酸具有活性。序列比较显示,这两种蛋白在毛白杨 4CL1 中与 Val-338 对应的位置上都有缺失突变,该位点位于上述隆起环中。将相应残基从 G. max 4CL2 和 4CL3 中删除,使突变体获得了对松柏酸的活性(Lindermayr 等,2003)。由于 G336PV338 隆起环是 4CLs 底物结合口袋的一部分,我们推测删除 Val-338 会使该隆起变直,去除结合口袋的一侧,显著扩大口袋,从而使 4CL 酶能够结合更大的松柏酸。
CoA 结合通道的鉴定
虽然在一些结晶条件中加入了 CoA,毛白杨 4CL1 始终以不含 CoA 的形式结晶。几种 ANL 酶,例如 Salmonella enterica 乙酰 CoA 合成酶(Gulick 等,2003)、Alcaligenes sp 4-氯苯甲酸:CoA 合成酶(Reger 等,2008)以及中链酰基 CoA 合成酶 2A,已与 CoA 或最终 CoA 硫酯产物共结晶。这些结构也恰好与 APP-复合物的毛白杨 4CL1 最为相似。当将这些结构与毛白杨 4CL1 基于 Cα 原子进行叠合时,它们的底物与毛白杨 4CL1 中的香豆酰基部分高度重叠(图 6A),它们的泛酸结合通道与毛白杨 4CL1 结构中的通道相对应,且这些蛋白中结合通道内衬残基与毛白杨 4CL1 中相应残基高度一致。这些结构中的泛酸部分可完美嵌入毛白杨 4CL1 的一个通道(图 6B)。仅在毛白杨 4CL1 的表面观察到一些较小的空间冲突,这些冲突可以通过局部结构调整轻易消除。此外,His-234(对应于 4-氯苯甲酸:CoA 合成酶的 His-207,且在 ANL 酶中保守为芳香族残基)在 APP-4CL1 复合物中采取了与 4-氯苯甲酸:CoA 合成酶硫酯形成复合物相同的构象(Reger 等,2008)。另一方面,在 AMP-复合物的毛白杨 4CL1 结构中,该残基处于与 4-氯苯甲酸:CoA 合成酶的腺苷酸形成复合物相对应的构象,阻止 CoA 接近活性位点。因此,合理推测 CoA 会以与这些蛋白中观察到的方式非常相似的方式结合到毛白杨 4CL1 上。
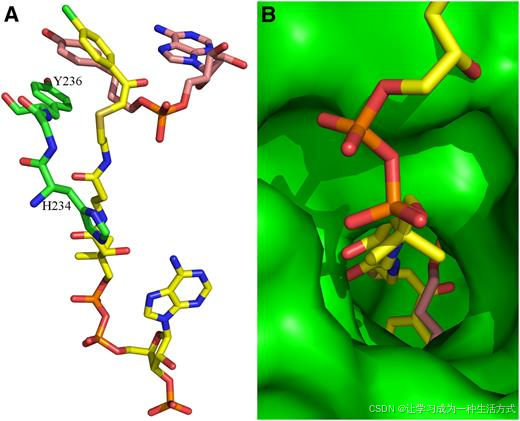
图 6. 4CL1 的 CoA 结合位点
(A) 当 4-氯苯甲酸:CoA 合成酶的硫酯形成构象与 APP-4CL1 复合物结构叠合时,前者结构中硫酯产物(黄色)的 4-氯苯基基团与后者结构中的香豆酰基基团(粉红色)高度重叠。His-234 和 Tyr-236,在调节 CoA 进入活性中心及羟基肉桂酸结合中分别起重要作用,用绿色表示。
(B) 4-氯苯甲酸:CoA 合成酶硫酯形成结构中的硫酯产物可以完美嵌入 APP-4CL1 结构的泛酸结合通道中。
该泛酸结合通道位于跨域界面上。 在 apo-4CL1 结构中,可能在 4CL1-APP 复合物中与 CoA 结合的残基彼此相距较远,通道完全暴露,使蛋白无法与 CoA 结合。例如,Gly-441 的 Cα 原子在 4CL1-APP 复合物中是 CoA 结合口袋的一部分,但在 apo-4CL1 结构中偏移超过 22 Å。我们推测这种机制防止了毛白杨 4CL1 在缺乏腺苷酸化产物时提前与 CoA 结合。
毛白杨 4CL1 的可能酶催化机制
根据广泛的结构和酶学研究,已建立了 ANL 蛋白的酶催化机制,即 域交替理论,这一理论由 Gulick(2009)系统综述。根据这一理论,ANL 蛋白在两个不同的催化中心中催化两个部分反应。这两个中心均位于 C-域表面,通过 C-域相对于 N-域的大幅移动被带到底物结合位点,在反应的不同阶段发挥作用。
在 ANL 蛋白的两步反应中,腺苷酸化反应及其催化机制高度保守。这一反应总是由保守序列 A10 中的一个赖氨酸残基催化(Gulick, 2009)。我们确定 Lys-523 是毛白杨 4CL1 的催化残基。尽管我们未能获得毛白杨 4CL1 腺苷酸化构象的晶体结构,但腺苷酸化反应的高度保守性以及 K523A 突变完全丧失毛白杨 4CL1 活性(图 5)验证了该酶的腺苷酸化机制与其他 ANL 蛋白相同。
ANL 蛋白的第二步反应多样性较大。例如,萤火虫荧光素酶在此步骤中催化腺苷酸中间体的氧化脱羧反应(de Wet 等,1985)。因此,该步反应的催化中心保守性较低。我们提出毛白杨 4CL1 在 APP-4CL1 复合物结构中采用硫酯形成构象。这一假设基于以下观察:在 APP-4CL1 复合物结构中,泛酸结合通道形成于跨域界面(图 6B),且 His-234 侧链采用硫酯形成构象(图 4D)。此外,APP-4CL1 复合物的构象与 S. enterica Acs 三元复合物(含底物类似物和 CoA)相同,后者已被证明是硫酯形成步骤的催化构象(Gulick 等,2003)。因此,我们提出残基 Lys-438 和 Gln-443 构成了毛白杨 4CL1 硫酯形成步骤的催化中心。对这两个残基的突变导致 4CL1 活性完全丧失,验证了它们的重要性(图 5)。
基于上述考虑及 域交替理论(Gulick, 2009),我们提出了毛白杨 4CL1 的酶催化机制: 该机制从 ATP 和羟基肉桂酸底物结合开始,结合后 4CL1 采用腺苷酸化反应的催化构象,Lys-523 侧链与羟基肉桂酸底物羧基相互作用并定位,使其对 ATP α-磷酸进行亲核攻击,形成 AMP-羟基肉桂酸中间体和 PPi。PPi 的释放推动 4CL1 进入硫酯形成步骤的催化构象(如 APP 复合物所示)。在该构象中,泛酸结合通道形成于跨域界面,His-234 侧链摆向一侧,允许 CoA 进入与 AMP-羟基肉桂酸结合中间体接近。AMP-羟基肉桂酸中间体和 CoA 随后在 Lys-438 和 Gln-443 侧链催化下形成最终的硫酯产物。C-域再次旋转,暴露底物结合位点,释放硫酯产物和 AMP。
总结
我们解析了毛白杨 4CL1 的 apo 结构及其与 AMP 和中间体类似物 APP 的二元复合物结构。基于这些结构和突变研究,我们确定了 4CL1 的催化残基 Lys-438、Gln-443 和 Lys-523。我们还识别了羟基肉桂酸结合口袋及与 4CL1 底物特异性相关的重要残基。该底物结合模型可很好地解释 G. max 4CL1 和拟南芥 4CL4 等 4CL 酶对松柏酸的特异性。我们还表明,APP 结合引发了构象变化,在毛白杨 4CL1 的跨域界面形成了 CoA 结合口袋,该复合物构象可能适用于硫酯形成步骤的催化。我们基于结构和突变研究提出了酶催化机制。由于植物 4CLs 的序列同源性较高,且 ANL 蛋白结构高度保守,4CL1 的高分辨率晶体结构将极大提升我们对这一重要蛋白家族结构-功能关系的理解。鉴定出控制毛白杨 4CL1 底物特异性的关键残基为未来 4CL 酶的分子工程奠定了坚实基础。
方法
蛋白纯化
毛白杨 (Populus tomentosa) 4CL1 基因通过 PCR 从毛白杨 cDNA 中扩增,使用引物对 5′-CGCAATGGACGCCACAATGAAT-3′ 和 5′-ACTGTCTTACGTTGGGTACG-3′,并克隆到 pMD18-T (TaKaRa) 载体中。随后,该基因使用引物对 5′-CGGGATCCCGCAATGGACGCCACAATGAAT-3′ 和 5′-CCCCCGGGGGCATCTTCAGTTA-3′ 通过 PCR 亚克隆,并用 BamHI 内切酶切割后,连接到 pQE31 过表达载体 (Qiagen) 的 BamHI 限制位点中。最终获得的 pQE31-4CL1 质粒在毛白杨 4CL1 N 端表达标签 MRGSHHHHHHTDPAMDAT。将 pQE31-4CL1 质粒转化的 Escherichia coli 菌株 M15(pREP4) 在 Luria-Bertani 培养基中生长,并在 300K 温度下用 0.4 mM 异丙基-β-D-1-硫代半乳糖苷(IPTG) 诱导表达。细胞通过 2500g 离心收集,并用超声波破碎。裂解液通过 20,000g 离心澄清,上清液加载到 Ni-NTA 亲和柱中。使用含 50 mM Na₂HPO₄(pH 8.0)、0.3 M NaCl 和 0.25 M 咪唑的溶液洗脱 4CL1。进一步使用 HiLoad 16/60 Superdex 75 XK 分子筛柱 (GE Healthcare) 纯化,洗脱溶液为含 50 mM Tris-HCl 缓冲液(pH 8.0)。
克隆与定点突变
4CL1 突变体基因通过使用 pQE31-4CL1 质粒为模板进行定点突变法获得。PCR 反应使用 TaKaRa Bio 提供的 LA Taq DNA 聚合酶,按照供应商的协议进行。突变体按照上述野生型 4CL1 蛋白纯化流程纯化。
4CL1 结晶
4CL1 游离蛋白的晶体通过悬滴法 (McPherson, 1999) 获得。含有 20 mg/mL 4CL1 的蛋白溶液,溶液成分为 50 mM Tris-HCl(pH 7.5)、10% (v/v) 甘油、0.1 M NaCl、2 mM DTT 和 1 mM EDTA,与含有 50 mM CAPSO(pH 9.8)、35% (w/v) PEG8000 和 0.25 M NaCl 的沉淀剂溶液按 1:1 比例混合,并用石蜡油封闭。针状晶体通常在 24 小时内出现,3 至 4 天内长至最大尺寸。
与 AMP 或 APP 复合的 4CL1 晶体通过悬挂滴法 (McPherson, 1999) 获得。所用 4CL 蛋白样品溶液与上述相同,唯一不同是在结晶前加入 10 mM AMP (Sigma-Aldrich) 或 APP (Laviana)。沉淀剂溶液含有 50 mM MES(pH 6.0)和 1.8 M 柠檬酸铵。立方晶体通常在 1 周内出现。
数据采集
在日本高能加速器研究机构(KEK)光子工厂 5A 光束线,使用波长 1.0000 Å 对毛白杨 (apo-4CL1) 晶体采集了 2.4 Å 分辨率的数据集。 在中国北京同步辐射装置 (BSRF),使用硒衍生 apo-4CL1 晶体,在硒峰波长 0.9790 Å 采集了 3.0 Å 分辨率的数据集。 在同步辐射装置上收集的数据帧使用 HKL2000 软件包进行积分。 含 AMP 的 4CL 晶体数据集使用安装在 Rigaku 转阴极 X 射线发生器(运行于 45 kV/45 mA)上的 Raxis-IV++ 图像板面积探测器采集。含 APP 的 4CL 晶体数据集在中国上海同步辐射光源 (SSRF) 17U 光束线采集。 收集到的数据帧使用 MOSFLM 程序进行积分,并使用 CCP4 软件包中的 SCALA 程序对数据进行标定。
结构解析与精修
apo-4CL1 结构通过分子置换解法和硒异常散射相位信息解析。PHASER 程序(McCoy 等,2005)使用萤火虫荧光素酶的 N 和 C 端结构域(Conti 等,1996)作为两个独立集合体,获得分子置换解。RESOLVE 程序(Terwilliger, 2000)用于去除模型偏差。SOLVE 程序(Terwilliger 和 Berendzen, 1999)用于确定和精修硒原子的位点,RESOLVE 程序结合了分子置换解和硒异常散射相位信息,并通过溶剂展平法精修相位。O 图形程序(Jones 等,1991)用于根据电子密度图构建残基和手动调整模型。使用 CNS 程序(Brünger 等,1998)对结构进行精修,其中 5% 的反射点被随机选作 Rfree 计算,并从结构精修中排除。通过交替进行 CNS 精修和手动模型重构,直到模型质量令人满意为止。
含 AMP 和 APP 的 4CL1 复合物结构通过 PHASER 程序(McCoy 等,2005)采用分子置换法解析,使用 apo 结构的 N 和 C 端结构域作为独立集合体。后续模型精修遵循上述相同的流程。
酶活性测定
使用 Bradford 法测定 4CL1 及其突变体蛋白浓度,以 BSA 作为蛋白标准(Bradford, 1976)。酶活性测定根据 Knobloch 和 Hahlbrock (1975) 的方法,进行了少许修改。 具体步骤如下: 490 μL 反应缓冲液中含有 5 mM ATP、0.3 mM CoA、5 mM Mg²⁺、0.2 mM 底物(4-香豆酸、咖啡酸或阿魏酸)和 0.2 M Tris-HCl(pH 7.8),在 300K 条件下孵育。空白对照中含有 0.2 mM 底物、5 mM Mg²⁺ 和 0.2 M Tris-HCl(pH 7.8)。 加入 2 μg 纯化蛋白(10 μL 溶液)启动酶反应,利用空白对照作为背景,每隔 40 秒连续记录紫外吸光度,持续 1 小时。检测波长分别为:333 nm(4-香豆酰-CoA 酯)、362 nm(咖啡酰-CoA 酯)和 346 nm(阿魏酰-CoA 酯)(Stöckigt 和 Zenk, 1975)。 根据反应前 6~8 分钟的测定数据计算 4CL1 及其突变体的酶活性。
登录号
毛白杨 4CL1 的游离(apo)、AMP 复合体及 APP 复合体晶体的坐标和结构因子已提交至蛋白质数据库(www.rcsb.org),登录号分别为 3A9U、3A9V 和 3NI2。 中链酰基-CoA 合成酶家族成员 2A 的 PDB 登录号为 3EQ6。 毛白杨 4CL1 的序列数据已提交至 GenBank/EMBL 数据库,登录号为 AY043495。