经典文献阅读之--RT-Grasp(通过MLLM进行推理调优的机器人抓取)
0. 简介
在此之前,许多研究已探索了机器人抓取与语言模型结合的可能性:
在机器人抓取领域,传统方法依赖于几何分析或接触力优化,但在处理未知或形状复杂的物体时表现有限。数据驱动方法(如基于卷积神经网络的模型)虽然更具灵活性,但容易过拟合,且缺乏对物体属性(如材质或用途)的深入推理能力。
在语言与机器人操作结合方面,早期研究探索了基于语言描述的抓取检测与操作任务分解。但这些方法大多依赖大量示例或基础动作库,效率与灵活性受限。
《RT-Grasp: Reasoning Tuning Robotic Grasping via Multi-modal Large Language Model》本文通过Reasoning Tuning(推理调优)方法,创新性地将LLMs的推理能力与机器人抓取任务结合,提出了一个全新流程:在预测前先进行推理阶段,以挖掘LLMs丰富的先验知识和多模态推理能力。不仅让LLMs能生成上下文感知、可调的数值预测(如抓取位姿),还通过Reasoning Tuning VLM Grasp 数据集进一步优化模型性能。
1. 主要贡献
我们研究了两种经济高效的训练策略,以实现所提出的推理调优:预训练和低秩适应(Low-Rank Adaptation, LoRA)微调[9]。我们进行此项研究的目的是提出一种更具资源效率的方法,以将多模态大语言模型(LLMs)的能力转移到下游机器人任务中。总之,我们的工作重点是将多模态LLMs适应于数值预测任务,特别是在机器人抓取领域。与传统的确定性方法相比,我们的方法不仅融合了先进的推理能力,还引入了一种新的范式来优化预测,如图1所示。我们的主要贡献可以总结如下:
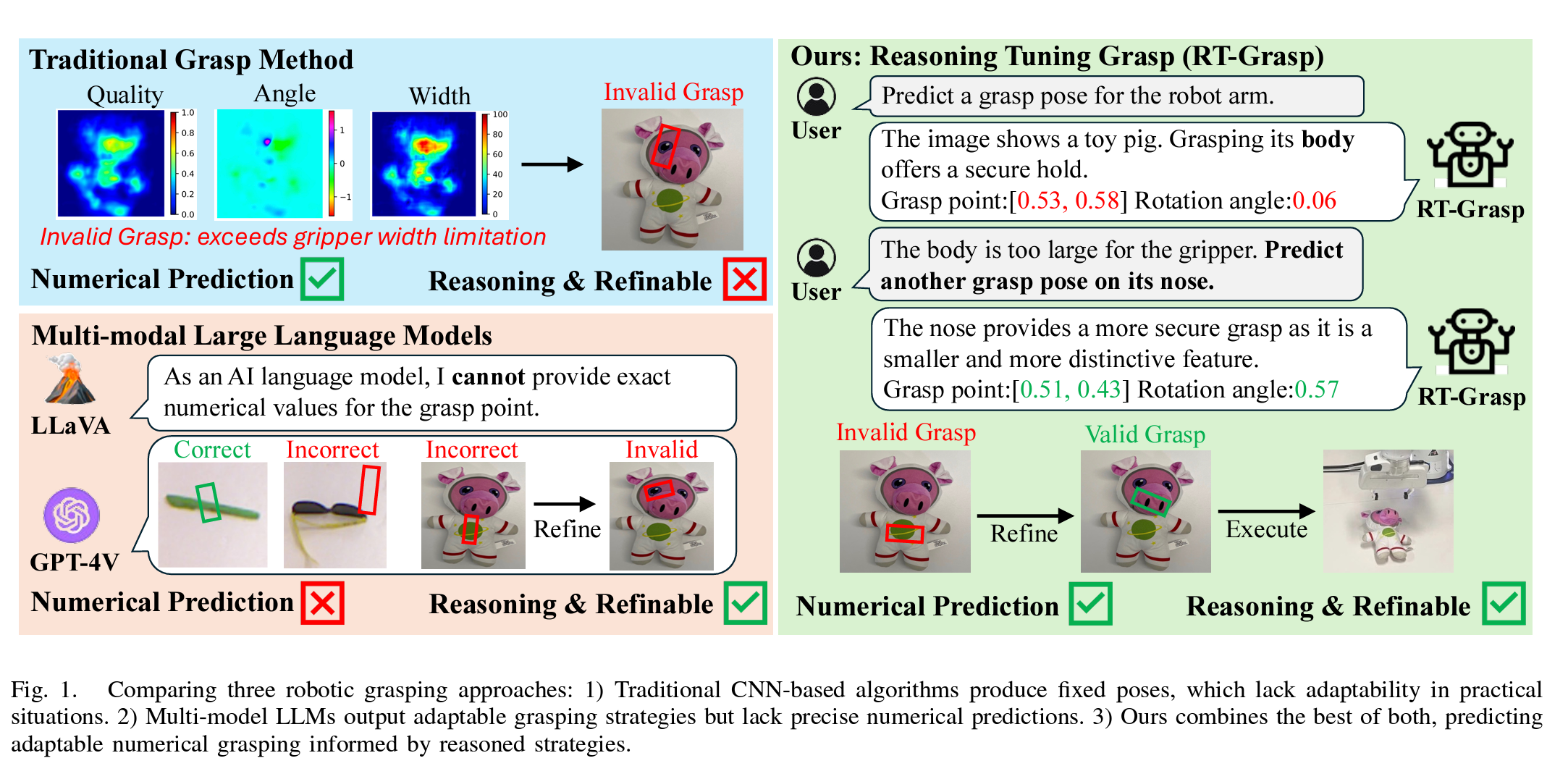
图1. 比较三种机器人抓取方法:1) 传统的基于卷积神经网络(CNN)算法产生固定的抓取姿态,缺乏在实际情况中的适应性。2) 多模态大语言模型(LLMs)输出适应性抓取策略,但缺乏精确的数值预测。3) 我们的方法结合了两者的优点,预测基于合理策略的适应性数值抓取。
- 我们提出了推理调优(Reasoning Tuning),这是一种新颖的方法,利用预训练多模态LLMs的固有先验知识,促进其适应需要数值预测的任务。
- 我们展示了我们的数据集——推理调优VLM抓取数据集,旨在为机器人抓取微调多模态LLMs。
- 我们通过两种计算效率高的训练策略对所提方法进行了实证验证,并进行了真实世界的硬件实验。我们的结果证明了该方法的有效性及其根据用户指令优化抓取预测的能力。
2. 机器人抓取
在本研究中,机器人抓取问题被定义为在给定n通道图像和相应文本指令的情况下,寻找一个与平面表面垂直的对立抓取。类似于文献[35]和[8],抓取姿态可以参数化为 g = { x , y , θ , w } g = \{x,y,\theta,w\} g={x,y,θ,w},其中 ( x , y ) (x,y) (x,y) 表示抓取姿态中心点的二维坐标; θ \theta θ 表示夹具相对于水平轴的旋转角度; w w w 代表矩形抓取框的宽度,对应于夹具的宽度。然而,在许多研究中,由于夹具宽度限制的变化,通常认为将 w w w 包含在预测的抓取姿态 g g g 中并非必要[36]。为此,我们的研究主要集中在探讨大语言模型(LLMs)在数值预测任务中的有效性,假设 w w w 等于夹具的最大宽度。本文将抓取姿态定义为: p = { x , y , θ } p = \{x,y,\theta\} p={x,y,θ},(1) 其中 ( x , y ) (x,y) (x,y) 坐标分别通过图像宽度和图像高度进行归一化,旋转角度 θ \theta θ 以弧度表示,范围缩放至 ( − π 2 , π 2 ) (-\frac{\pi}{2}, \frac{\pi}{2}) (−2π,2π),如图2所示。
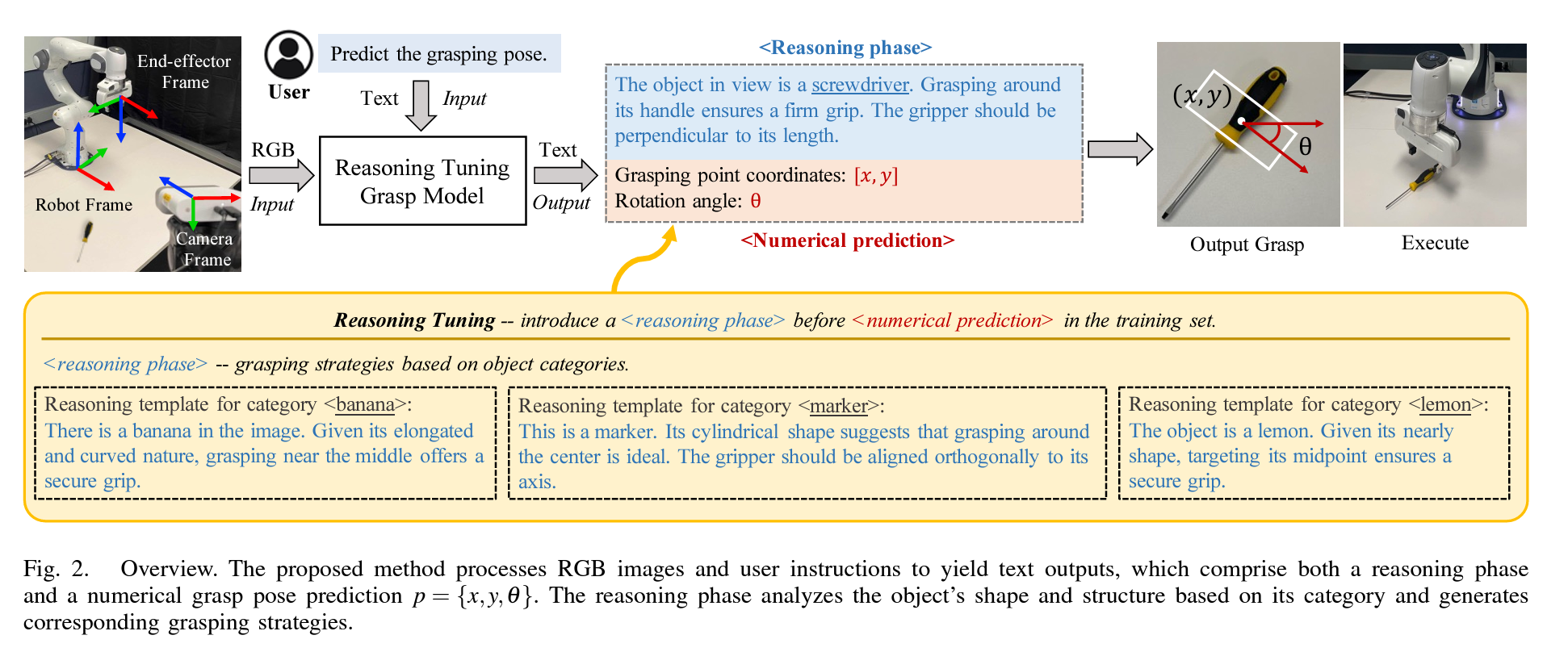
图2. 概述。所提出的方法处理RGB图像和用户指令,以生成文本输出,其中包括推理阶段和数值抓取姿态预测 p = { x , y , θ } p = \{x,y,\theta\} p={x,y,θ}。推理阶段根据物体的类别分析其形状和结构,并生成相应的抓取策略。
3. RT-GRASP
在本节中,我们介绍了用于机器人抓取的推理调优(RT-Grasp),这是一种新颖的方法,旨在弥合大型语言模型(LLMs)固有的文本中心特性与机器人任务的精确数值要求之间的差距。其主要目标是通过利用其广泛的封装先验知识,促进多模态LLMs进行数值预测。预训练的多模态LLM,例如LLaVA [37],在给定图像和文本指令时,可以以完全监督的方式直接进行微调。该模型通过顺序预测文本输出中的每个标记进行训练。所提出的推理调优引入了一个结构化的文本输出,其中包括一个推理阶段和随后的数值预测。我们创建了一个用于机器人抓取的图像-文本数据集,命名为推理调优VLM(视觉语言模型)抓取数据集,用于微调多模态LLMs。此外,我们还介绍了一种使用GPT-3.5 [38]自动生成此类图像-文本数据集的方法,该方法可以应用于超出机器人抓取的任务数据集。更多细节将在IV-A节中介绍。此外,我们在IV-B节中讨论了在实验中采用的两种成本效益高的训练策略。
4. 推理调优
在本节中,我们介绍了推理调优,这是一种使用图像-文本对作为输入并生成结构化文本输出的多模态LLMs微调方法。该结构化输出包括一个初始推理阶段,随后是数值预测,如图2所示。值得注意的是,整个输出均为文本形式,模型被训练为顺序预测相应的标记。通过在输出的开头引入推理阶段,我们鼓励模型基于特定任务的逻辑推理生成精确的预测。对于机器人抓取,我们创建了一个新的数据集,用于微调多模态LLMs,称为推理调优VLM抓取数据集。每个数据样本包括一张RGB图像和一条文本指令,提示模型预测抓取姿态(参见图3)。此外,该数据集中结构化的目标文本包含输入图像中物体的推理阶段,随后是真实的抓取姿态。推理阶段提供了对物体的一般描述,涵盖形状和位置等方面,并建议相应的抓取策略。例如,考虑杯子,它们可能在颜色、设计或材料上有所不同,但针对它们的通用抓取策略是通过目标把手或上边缘来实现的。整合这样的推理阶段引导模型建立对物体及相关抓取策略的广泛理解,从而在后续步骤中促进更为准确的数值预测。

图3. 来自推理调优VLM抓取数据集的数据样本示例。结构化文本答案包含推理阶段和真实抓取姿态。
现有的机器人抓取数据集通常仅包含图像和数值真实抓取姿态。相比之下,我们的推理调优VLM数据集提供了专门为将多模态LLMs整合到机器人抓取中而量身定制的图像-文本对。在该数据集中,图像来源于基准的康奈尔抓取数据集 [13],而随附的结构化文本则由推理阶段和以文本格式呈现的真实抓取姿态组成。接下来,我们详细介绍了用于自动生成我们数据集中相应文本的方法。对于结构化文本中的推理阶段,我们基于物体类别生成模板,因为同一类型物体的抓取策略通常是相似的。对于每个类别,我们创建了一系列不同的推理模板。在每个数据样本的结构化文本中,根据物体类别随机选择一个推理模板,然后附加以文本形式呈现的真实抓取姿态(参见图3)。为了确保这些推理模板的质量,我们采用了多步骤的方法。首先,我们提示GPT-3.5 [38]生成针对每个类别量身定制的模板集合。随后,我们指示其对这些草稿进行精炼,删除冗余或不相关的句子。最后,作为质量检查,我们手动验证生成模板的正确性和相关性。这些推理模板通常描述物体的形状并提供一般的抓取策略。我们在图4中展示了一些推理模板的示例,完整的集合和GPT-3.5提示可以在我们的项目页面上找到。
图4. 推理调优VLM数据集中的推理模板示例。
对于我们数据集中的输入文本指令,我们还使用GPT-3.5生成了一系列与机器人抓取任务相关的一致指令模板,示例模板见图3。值得注意的是,创建此图像-文本数据集的方法适用于超出机器人抓取的其他数值预测任务。调整推理阶段中的策略可以利用嵌入在LLMs中的适当先验知识,以适应不同的任务。
5. 训练策略
在我们的数据集中,对于每个图像 I,我们有一个单轮对话数据形式 (S,A),其中 S 代表输入指令,A 是相关的目标答案。本文实施了两种训练策略:预训练和 LoRA 微调,如图 5 所示。这两种策略都采用了自回归训练目标,遵循 LLaVA [37] 的方法。具体而言,对于长度为 l 的序列,生成目标答案 A 的概率被公式化为
p ( A ∣ I , S ) = ∏ i = 1 l p θ m ( a i ∣ I , S , A < i ) , p(A|I,S) = \prod_{i=1}^{l} p_{\theta_m}(a_i|I,S,A_{<i}), p(A∣I,S)=i=1∏lpθm(ai∣I,S,A<i),
其中 θ m \theta_m θm 是模型中的可训练参数; a i a_i ai 代表当前预测的标记; A < i A_{<i} A<i 表示当前标记 a i a_i ai 之前的答案标记。在我们的推理调优 VLM 数据集中,我们定义目标答案 A = { A r , A p } A = \{A_r, A_p\} A={Ar,Ap},其中 A r A_r Ar 代表推理阶段的文本, A p A_p Ap 表示包括坐标 [ x , y ] [x,y] [x,y] 和旋转角度 θ \theta θ 的抓取姿态预测。值得注意的是,由于这些数值预测 A p A_p Ap 本质上也是文本格式,它们首先由大型语言模型(LLMs)生成为标记,然后转换为文本数字。然后,公式 2 可以重写为
p ( A ∣ I , S ) = p ( A r ∣ I , S ) ⋅ p ( A p ∣ I , S , A r ) = ∏ i = 1 ∣ A r ∣ p θ m ( a i ∣ I , S , A r < i ) ⋅ ∏ j = 1 ∣ A p ∣ p θ m ( a j ∣ I , S , A r , A p < j ) , p(A|I,S) = p(A_r|I,S) \cdot p(A_p|I,S,A_r) = \prod_{i=1}^{|A_r|} p_{\theta_m}(a_i|I,S,A_{r<i}) \cdot \prod_{j=1}^{|A_p|} p_{\theta_m}(a_j|I,S,A_r,A_{p<j}), p(A∣I,S)=p(Ar∣I,S)⋅p(Ap∣I,S,Ar)=i=1∏∣Ar∣pθm(ai∣I,S,Ar<i)⋅j=1∏∣Ap∣pθm(aj∣I,S,Ar,Ap<j),
其中 p ( A r ∣ I , S ) p(A_r|I,S) p(Ar∣I,S) 表示生成推理文本的概率, p ( A p ∣ I , S , A r ) p(A_p|I,S,A_r) p(Ap∣I,S,Ar) 是在输入图像 I I I、指令 S S S 和推理阶段文本 A r A_r Ar 的条件下生成抓取姿态预测的概率。整个文本答案 A A A 的总长度为 l = ∣ A r ∣ + ∣ A p ∣ l = |A_r| + |A_p| l=∣Ar∣+∣Ap∣。
-
预训练:在这一训练策略中,视觉编码器和 LLM 的权重保持冻结状态。只有投影层的权重被更新,该层将图像特征与 LLM 的词嵌入空间对齐。
-
LoRA 微调:为了进一步提升性能,我们采用 LoRA [9] 微调,这是一种计算效率高的技术,它向现有的 LLM 添加了一个外部模型。具体而言,我们将 LoRA 注入到 LLM 中的所有线性层中。值得注意的是,视觉编码器和原始 LLM 保持冻结状态。只有添加的 LoRA 和投影层的权重被设置为可训练参数。
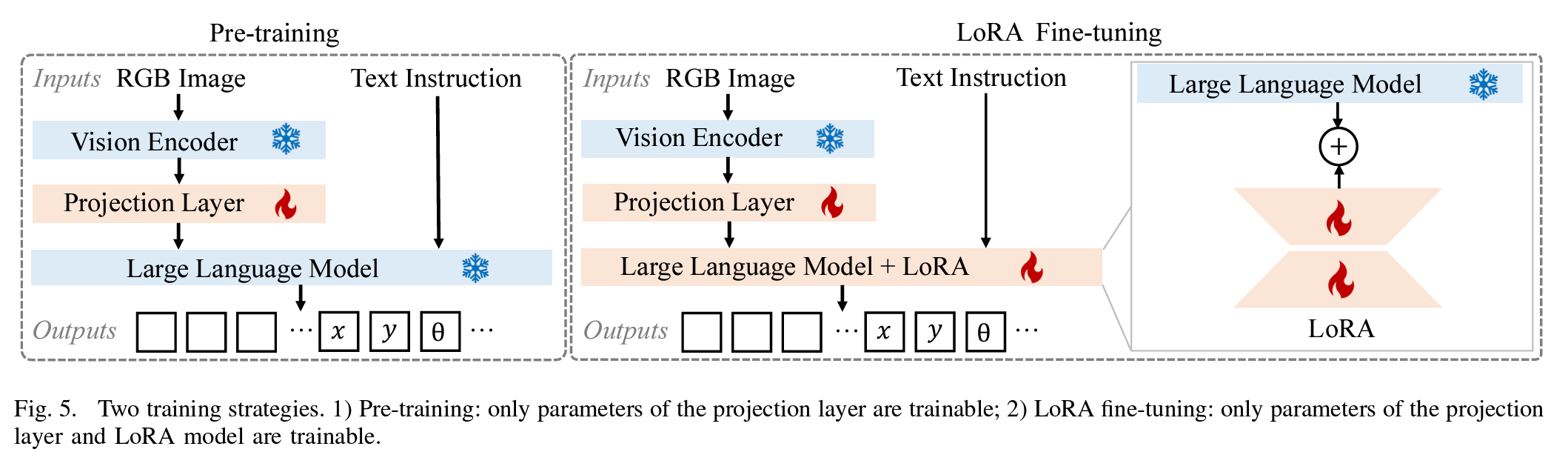
图 5. 两种训练策略。1) 预训练:仅投影层的参数可训练;2) LoRA 微调:仅投影层和 LoRA 模型的参数可训练。
6. 结论
本研究强调了大型语言模型(LLMs)在传统文本中心应用之外的潜力。我们提出的方法利用了 LLMs 的广泛先验知识进行数值预测,特别是在机器人抓取方面。通过在基准数据集和现实场景中进行的全面实验,我们证明了我们方法的有效性。未来的工作中,我们计划通过将其应用于包含更广泛物体的抓取数据集(如 Jacquard 数据集 [42])来扩展我们方法的验证。此外,将多模态 LLMs 适应于其他机器人操作任务中的数值预测也是一个有前景的研究方向。