K8s中间件Kafka上云部署
Kafka简介:
Kafka 是一个分布式的消息队列(MQ,Message Queue)系统,主要应用于大数据实时处理领域。
1、为什么需要消息队列(MQ)
(1)由于在高并发环境下,同步请求来不及处理,请求往往会发生阻塞。比如大量的请求并发访问数据库,导致行锁表锁,最后请求线程会堆积过多,从而触发 too many connection 错误,引发雪崩效应。
(2)我们使用消息队列,通过异步处理请求,从而缓解系统的压力。消息队列常应用于异步处理,流量削峰,应用解耦,消息通讯等场景。
(3)当前比较常见的 MQ 中间件有 ActiveMQ、RabbitMQ、RocketMQ、Kafka 等。
2、数据处理过程
Apache Kafka是一种流行的分布式流式消息平台。
Kafka生产者将数据写入分区主题,这些主题通过可配置的副本存储到群集broker(节点)上。
消费者来消费存储在broker分区上的数据。
Partion:分区,即分片
Topic消息主题--partion分成多个分片--replication每分片创建多个副本--分片副本存储到不同的broker节点
举例理解kafka:
场景:披萨店的点餐与配送系统
假设你开了一家火爆的披萨店,顾客下单量巨大,如何高效处理订单并确保每个订单都能准确送达?这时你可以用 Kafka 来优化流程。
1、核心角色
1)顾客(Producer生产者):下单的人,负责产生消息(比如“我要一份海鲜披萨”)。
2)订单柜台(Topic消息主题):所有订单按类型分类存放。比如:
① - 海鲜披萨订单队列(Partition 1)
② - 榴莲披萨订单队列(Partition 2)
Partition分区是为了并行处理,提高效率
3)外卖小哥(Consumer消费者/处理订单):从订单柜台取订单,按顺序配送。
4)记事本(Offset偏移量):记录每个外卖小哥当前配送到了哪个订单(防止重复或漏单)。
2、作流程
1)下单(Produce生产)
- 顾客A说:“海鲜披萨1份!” → 订单被放到 海鲜披萨队列(Partition 1) 的末尾。
- 顾客B说:“榴莲披萨2份!” → 订单进入 榴莲披萨队列(Partition 2)。
2)处理订单(Consume消费)
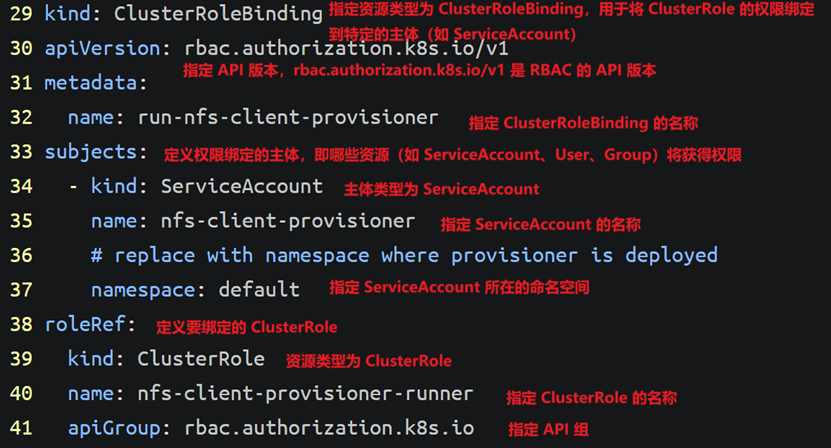
- 外卖小哥1专门处理海鲜披萨队列,从记事本看到上次送到第5单,现在取第6单。
- 外卖小哥2处理榴莲披萨队列,独立工作,互不干扰。
3)容灾备份(Replication)
- 订单柜台的每类订单都有备份副本(比如副本放在后厨),即使柜台被砸了,数据也不丢。
4)历史订单(Retention)
- 订单默认保存7天(可配置),超过时间自动清理,但重要订单可以永久保存(比如VIP客户的订单)。
5)关键特性
- 高吞吐量:多个队列(分区)并行处理,就像多个外卖小哥同时送餐。
- 持久化:订单即使被处理完也会保留一段时间(避免“我明明下单了,你说没记录?”)。
- 消费者组(Consumer Group):
- 如果多个外卖小哥同属一个团队(同一个消费者组),他们会分摊订单(比如小哥1送1-5单,小哥2送6-10单)。
- 如果是不同团队(不同消费者组),每个团队都会收到全部订单(比如美团和饿了么各自独立配送同样的订单)。
6)故障处理
- 外卖小哥崩溃了?
Kafka会检测到,并让同组的其他小哥接手他的任务(自动重新平衡)。
- 订单太多了?
可以随时增加外卖小哥(扩容消费者),或者增加订单队列(分区)。
总结:
Kafka 就像一套高效的订单管理系统:
- 生产者丢消息 → Topic/分区分类存储 → 消费者按需处理,且支持多团队协作。
- 核心优势:快、稳、可扩展,适合大数据场景(如日志处理、实时推荐等)。
一、环境准备

安装好k8s集群
部署storageclass
使用NFS文件系统创建存储动态供给
PV对存储系统的支持可通过其插件来实现,目前官方插件是不支持NFS动态供给的,但是我们可以用第三方的插件来实现。
补充:安装配置nfs服务
所有节点都安装nfs-utils工具包服务
yum -y install nfs-utils
这里将192.168.10.14作为nfs服务器(192.168.10.14)
mkdir -p /data/nfs
vim /etc/exports

添加:
/data/nfs *(rw,sync,no_root_squash)

systemctl start nfs-server
systemctl enable nfs-server
showmount -e

worker1:
showmount -e 192.168.10.14

worker2:
showmount -e 192.168.10.14

(1)下载或上传storageclass-nfs.yml文件并创建storageclass(master1)
wget https://raw.githubusercontent.com/kubernetes-sigs/nfs-subdir-external-provisioner/master/deploy/class.yaml

mv class.yaml storageclass-nfs.yml
![]()
vim storageclass-nfs.yml

字段解析:
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner:
指定用于动态创建 PV 的 Provisioner。
这里的 k8s-sigs.io/nfs-subdir-external-provisioner 是一个常用的 NFS Provisioner,它会根据 PVC 的请求动态创建 PV,并在 NFS 共享目录下创建子目录。
该值必须与部署的 Provisioner 的 PROVISIONER_NAME 环境变量一致。
archiveOnDelete: "false":
指定删除 PVC 时是否将 NFS 子目录归档(重命名而不是删除)。
"true":归档(重命名为 archived-<目录名>)。
"false":直接删除子目录。
创建资源
kubectl apply -f storageclass-nfs.yml
![]()
查看当前 Kubernetes 集群中定义的 StorageClass 的详细信息
kubectl get storageclass

返回字段解析:
NAME:StorageClass 的名称,这里是 nfs-client。在创建 PVC 时,可以通过 storageClassName: nfs-client 引用该 StorageClass。
PROVISIONER:指定用于动态创建 PV 的 Provisioner。这里是 k8s-sigs.io/nfs-subdir-external-provisioner,表示使用 NFS 子目录外部 Provisioner。
RECLAIMPOLICY:定义 PV 的回收策略,即当 PVC 被删除时,PV 的处理方式。
Delete:删除 PVC 时,自动删除对应的 PV 和底层存储资源。
其他选项包括 Retain(保留 PV 和底层存储资源)和 Recycle(已弃用)。
VOLUMEBINDINGMODE:定义 PV 和 PVC 的绑定时机。
Immediate:在 PVC 创建时立即绑定 PV。
其他选项包括 WaitForFirstConsumer(延迟绑定,直到 Pod 使用 PVC 时再绑定 PV)。
ALLOWVOLUMEEXPANSION:是否允许动态扩展 PVC 的存储容量。
false:不允许扩展。
如果设置为 true,则可以动态调整 PVC 的存储大小。
AGE:StorageClass 的创建时间,这里是 46s,表示该 StorageClass 已经创建了 46 秒。
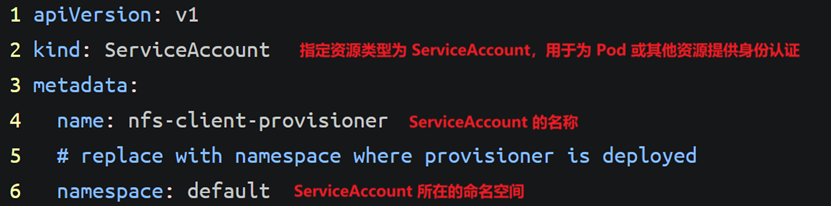
(2)下载或上传rbac.yaml文件配置清单文件,创建rbac(创建账号,并授权)(master1)
因为storage自动创建pv需要经过kube-apiserver,所以需要授权。
RBAC(Role-Based Access Control):基于角色的访问控制
定义:
RBAC(Role-Based Access Control,基于角色的访问控制)是一种访问控制模型,它通过将用户分配到不同的角色,并为每个角色定义权限,从而实现对资源的访问控制。用户通过其所属的角色获得相应的权限,而无需直接为每个用户分配权限。
核心组件:
用户(User):需要访问系统资源的主体,如员工、客户等。
角色(Role):一组权限的集合,代表用户在系统中的职责或身份。例如,“管理员”、“普通用户”等。
权限(Permission):允许用户对资源进行的操作,如“读取”、“写入”、“删除”等。
资源(Resource):系统中需要保护的对象,如文件、数据库、网络设备等。
wget https://raw.githubusercontent.com/kubernetes-sigs/nfs-subdir-external-provisioner/master/deploy/rbac.yaml

mv rbac.yaml storageclass-nfs-rbac.yaml
![]()
vim storageclass-nfs-rbac.yaml

创建资源
kubectl apply -f storageclass-nfs-rbac.yaml
![]()
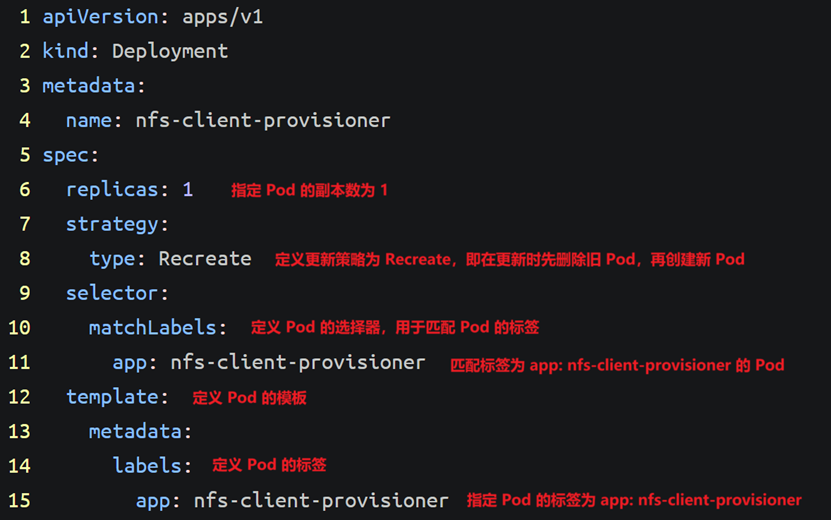
(3)创建动态供给的deployment(master1)
需要一个deployment来专门实现pv与pvc的自动创建
vim deploy-nfs-client-provisioner.yml
![]()
添加:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-client-provisioner
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-client-provisioner
template:
metadata:
labels:
app: nfs-client-provisioner
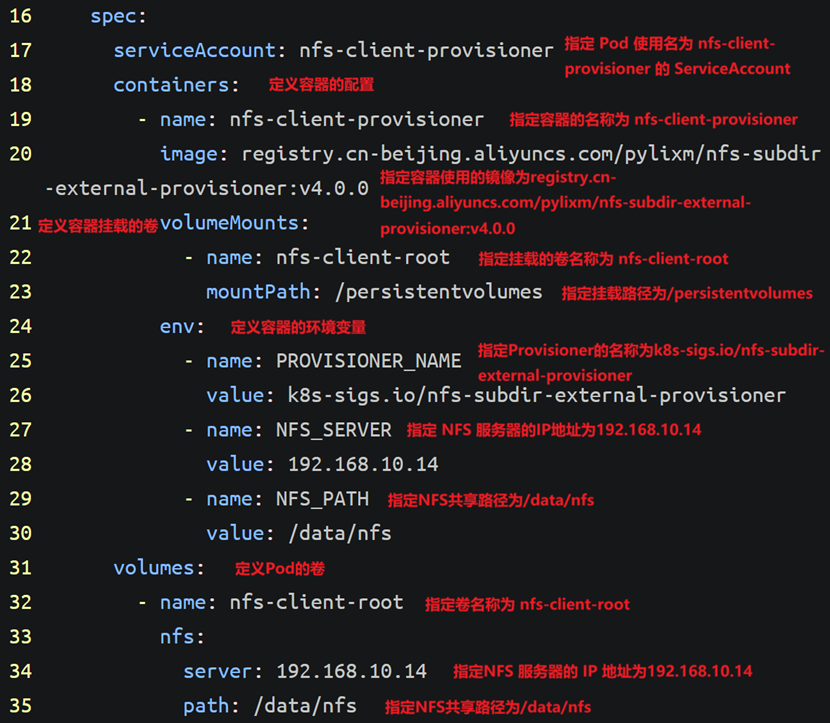
spec:
serviceAccount: nfs-client-provisioner
containers:
- name: nfs-client-provisioner
image: registry.cn-beijing.aliyuncs.com/pylixm/nfs-subdir-external-provisioner:v4.0.0
volumeMounts:
- name: nfs-client-root
mountPath: /persistentvolumes
env:
- name: PROVISIONER_NAME
value: k8s-sigs.io/nfs-subdir-external-provisioner
- name: NFS_SERVER
value: 192.168.10.14
- name: NFS_PATH
value: /data/nfs
volumes:
- name: nfs-client-root
nfs:
server: 192.168.10.14
path: /data/nfs
创建资源
kubectl apply -f deploy-nfs-client-provisioner.yml
![]()
kubectl get pod | grep nfs-client-provisioner

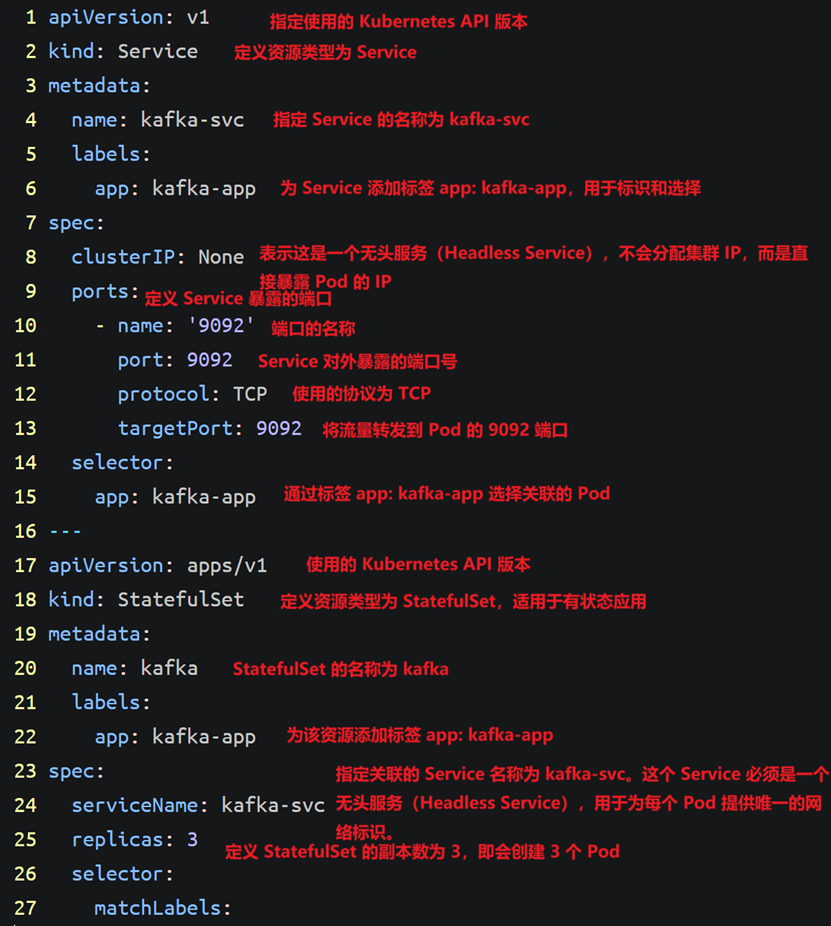
二、Kafka部署及部署验证(master1)
创建YAML文件
vim kafka.yaml

添加:
apiVersion: v1
kind: Service
metadata:
name: kafka-svc
labels:
app: kafka-app
spec:
clusterIP: None
ports:
- name: '9092'
port: 9092
protocol: TCP
targetPort: 9092
selector:
app: kafka-app
---
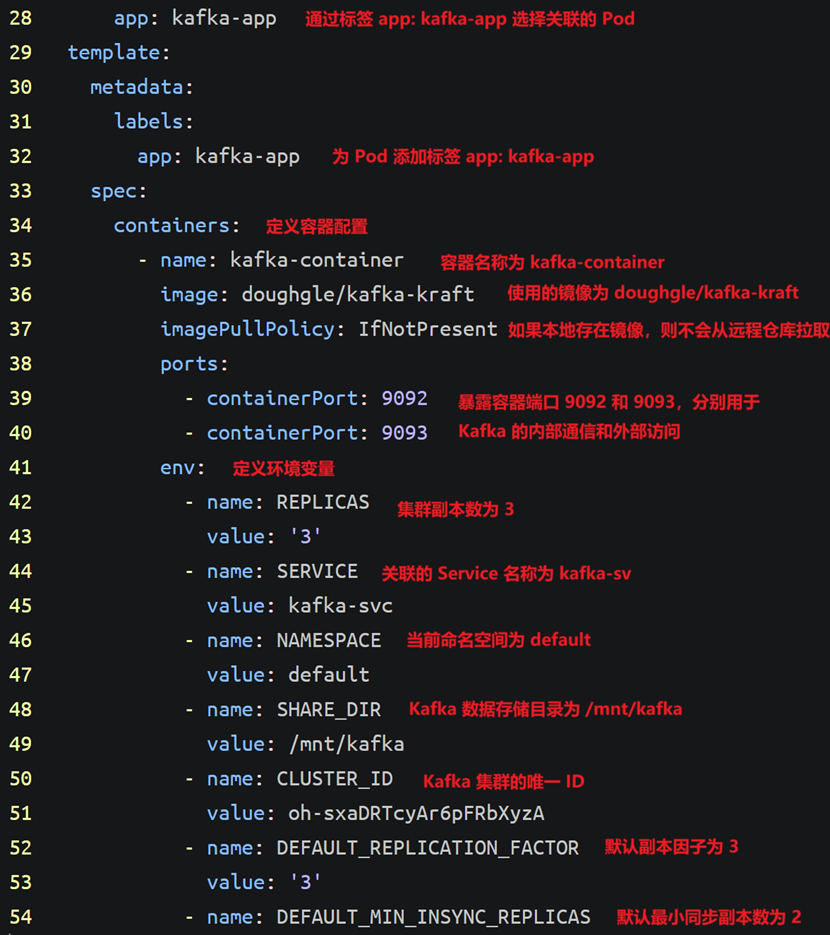
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: kafka
labels:
app: kafka-app
spec:
serviceName: kafka-svc
replicas: 3
selector:
matchLabels:
app: kafka-app
template:
metadata:
labels:
app: kafka-app
spec:
containers:
- name: kafka-container
image: doughgle/kafka-kraft
imagePullPolicy: IfNotPresent
ports:
- containerPort: 9092
- containerPort: 9093
env:
- name: REPLICAS
value: '3'
- name: SERVICE
value: kafka-svc
- name: NAMESPACE
value: default
- name: SHARE_DIR
value: /mnt/kafka
- name: CLUSTER_ID
value: oh-sxaDRTcyAr6pFRbXyzA
- name: DEFAULT_REPLICATION_FACTOR
value: '3'
- name: DEFAULT_MIN_INSYNC_REPLICAS
value: '2'
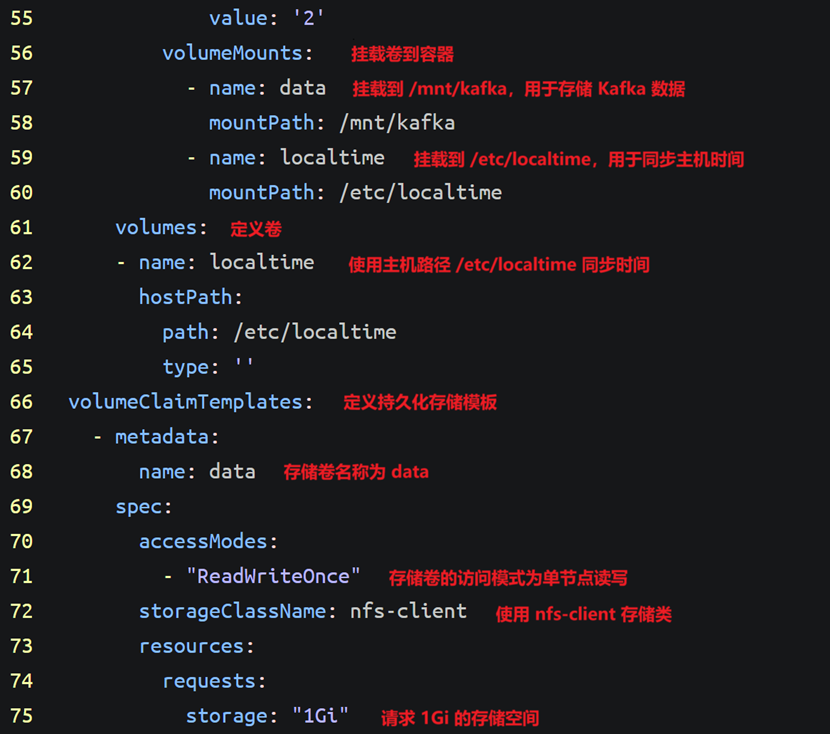
volumeMounts:
- name: data
mountPath: /mnt/kafka
- name: localtime
mountPath: /etc/localtime
volumes:
- name: localtime
hostPath:
path: /etc/localtime
type: ''
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes:
- "ReadWriteOnce"
storageClassName: nfs-client
resources:
requests:
storage: "1Gi"
镜像准备(worker1、worker2)
下载方法:docker pull doughgle/kafka-kraft
上传kafka.tar镜像包并导入方法:docker load -i kafka.tar
创建资源
kubectl apply -f kafka.yaml
![]()
kubectl get pod

kubectl get svc

注:
出于安全考虑,默认配置下Kubernetes不会将Pod调度到Master节点。
如果希望将k8s-master也当作Node使用,可以执行如下命令:
检查 Kubernetes 集群中名为 master1 的节点的 污点(Taints) 信息。污点是 Kubernetes 中用于标记节点的一种机制,通常用于控制 Pod 的调度行为
kubectl describe node master1 | grep Taints

返回值解析:
污点键(Key): node-role.kubernetes.io/control-plane 这是一个内置的污点键,用于标记 Kubernetes 控制平面节点(如 Master 节点)。
污点效果(Effect): NoSchedule 表示 Kubernetes 调度器不会将 Pod 调度到该节点上,除非 Pod 明确容忍(Tolerate)这个污点。
从 Kubernetes 节点 master1 上移除一个污点(Taint)
kubectl taint node master1 node-role.kubernetes.io/control-plane-

命令解析:
kubectl taint:用于管理节点污点的命令
node master1:指定目标节点为 master1
node-role.kubernetes.io/control-plane-:
node-role.kubernetes.io/control-plane: 污点的键
-: 表示移除该污点
kubectl describe node master1 | grep Taints

返回值解析:
输出 Taints: <none> 表示节点 master1 当前 没有设置任何污点(Taints),Kubernetes 调度器可以自由地将 Pod 调度到该节点上,无需考虑污点的限制。
如果想取消被调度,执行如下命令即可,不会影响已经被调度的pod
在 Kubernetes 节点 master1 上添加一个污点(Taint)。这个污点的作用是阻止 Kubernetes 调度器将 Pod 调度到该节点上
kubectl taint node master1 node-role.kubernetes.io/control-plane:NoSchedule

kubectl describe node master1 | grep Taints

三、Kafka应用测试(master1)
镜像准备(worker1、worker2)
下载方法:docker pull bitnami/kafka:3.1.0
上传kafka_client.tar镜像包并导入方法:docker load -i kafka_client.tar
创建客户端Pod
kubectl run kafka-client --rm -it --image bitnami/kafka:3.1.0 -- bash

命令解析:
kubectl run: 用于在 Kubernetes 中创建并运行一个 Pod。
kafka-client: 指定 Pod 的名称为 kafka-client。
--rm: 表示在退出 Pod 后自动删除该 Pod。
-it: 启动一个交互式终端(-i 表示交互式,-t 表示分配一个伪终端)。
--image bitnami/kafka:3.1.0: 指定使用的镜像为 bitnami/kafka,版本为 3.1.0。
-- bash: 在 Pod 中执行的命令是 bash,即启动一个 Bash shell。
cd /opt/bitnami/kafka/bin/
![]()
列出 Kafka 集群中的所有主题Topics(Topic即消息主题)
kafka-topics.sh --list --bootstrap-server kafka-svc.default.svc.cluster.local:9092

命令解析:
kafka-topics.sh:Kafka 提供的命令行工具,用于管理主题(Topics)。
--list:列出 Kafka 集群中的所有主题。
--bootstrap-server kafka-svc.default.svc.cluster.local:9092:
--bootstrap-server: 指定 Kafka 集群的引导服务器地址。
kafka-svc.default.svc.cluster.local:9092: Kafka 服务的完整域名(FQDN)和端口号。
kafka-svc: Kafka 服务的名称。
default: Kafka 服务所在的命名空间。
svc.cluster.local: Kubernetes 集群的内部域名后缀。
9092: Kafka 服务的默认端口。
在 Kafka 集群中创建一个新的主题(Topic)
kafka-topics.sh --bootstrap-server kafka-svc.default.svc.cluster.local:9092 --topic test01 --create --partitions 3 --replication-factor 2

命令解析:
--bootstrap-server kafka-svc.default.svc.cluster.local:9092:
--bootstrap-server: 指定 Kafka 集群的引导服务器地址。
kafka-svc.default.svc.cluster.local:9092: Kafka 服务的完整域名(FQDN)和端口号。
kafka-svc: Kafka 服务的名称。
default: Kafka 服务所在的命名空间。
svc.cluster.local: Kubernetes 集群的内部域名后缀。
9092: Kafka 服务的默认端口。
--topic test01: 指定要创建的主题名称为 test01。
--create: 表示这是一个创建主题的命令。
--partitions 3: 指定主题的分区数为 3。
--replication-factor 2: 指定主题的副本因子为 2。
列出 Kafka 集群中的所有主题Topics
kafka-topics.sh --list --bootstrap-server kafka-svc.default.svc.cluster.local:9092

启动一个控制台生产者(Console Producer),将消息发送到指定的 Kafka 主题(Topic)
kafka-console-producer.sh --topic test01 --request-required-acks all --bootstrap-server kafka-svc.default.svc.cluster.local:9092
输入hello world使用Ctrl+c结束

命令解析:
--topic test01: 指定要发送消息的主题名称为 test01。
--request-required-acks all:
--request-required-acks: 指定生产者发送消息时需要等待的确认机制。
all: 表示需要等待所有副本(ISR,In-Sync Replicas)都确认收到消息后,生产者才会认为消息发送成功。
--bootstrap-server kafka-svc.default.svc.cluster.local:9092:
--bootstrap-server: 指定 Kafka 集群的引导服务器地址。
kafka-svc.default.svc.cluster.local:9092: Kafka 服务的完整域名(FQDN)和端口号。
启动一个控制台消费者(Console Consumer),从指定的 Kafka 主题(Topic)中消费消息
kafka-console-consumer.sh --topic test01 --from-beginning --bootstrap-server kafka-svc.default.svc.cluster.local:9092

命令解析:
--topic test01: 指定要消费消息的主题名称为 test01。
--from-beginning:
表示消费者将从主题的最早的偏移量(Offset)开始消费消息,即消费主题中的所有历史消息。
如果不指定该选项,消费者默认从当前最新的偏移量开始消费消息。
--bootstrap-server kafka-svc.default.svc.cluster.local:9092:
--bootstrap-server: 指定 Kafka 集群的引导服务器地址。
kafka-svc.default.svc.cluster.local:9092: Kafka 服务的完整域名(FQDN)和端口号。
查看指定主题(Topic)的详细信息
kafka-topics.sh --describe --topic test01 --bootstrap-server kafka-svc.default.svc.cluster.local:9092

命令解析:
--describe: 表示这是一个描述主题的命令,用于查看主题的详细信息。
--topic test01: 指定要查看的主题名称为 test01。
--bootstrap-server kafka-svc.default.svc.cluster.local:9092:
--bootstrap-server: 指定 Kafka 集群的引导服务器地址。
kafka-svc.default.svc.cluster.local:9092: Kafka 服务的完整域名(FQDN)和端口号。
返回字段解析:
主题概览
Topic: test01: 主题名称为 test01。
TopicId: tA2XicqtRRuur4X756KKUQ: 主题的唯一标识符(Topic ID)。
PartitionCount: 3: 主题有 3 个分区。
ReplicationFactor: 2: 每个分区有 2 个副本。
Configs: 主题的配置参数:
min.insync.replicas=2: 最小同步副本数为 2。
segment.bytes=1073741824: 每个日志段文件的大小为 1 GiB(1073741824 字节)。
分区详细信息
分区 0
Partition: 0: 分区 ID 为 0。
Leader: 0: 领导者副本在 Broker ID 为 0 的节点上。
Replicas: 0,1: 分区的副本分布在 Broker ID 为 0 和 1 的节点上。
Isr: 0,1: 同步副本列表为 Broker ID 为 0 和 1 的节点。
分区 1
Partition: 1: 分区 ID 为 1。
Leader: 1: 领导者副本在 Broker ID 为 1 的节点上。
Replicas: 1,2: 分区的副本分布在 Broker ID 为 1 和 2 的节点上。
Isr: 1,2: 同步副本列表为 Broker ID 为 1 和 2 的节点。
分区 2
Partition: 2: 分区 ID 为 2。
Leader: 2: 领导者副本在 Broker ID 为 2 的节点上。
Replicas: 2,0: 分区的副本分布在 Broker ID 为 2 和 0 的节点上。
Isr: 2,0: 同步副本列表为 Broker ID 为 2 和 0 的节点。
显示内容解释如下:
Topic: test01: 这是正在描述的主题名称。
Partition: X: 这里的 X 是分区编号,例如 0、1 或 2。每个分区都是主题的一个子集,可以独立地存储和处理消息。
Leader: 每个分区都有一个领导者(Leader),负责协调来自客户端的读写请求。其他副本(Replicas)会从领导者那里同步数据。
Replicas: 这是分区数据的副本列表,它们分布在不同的 Kafka 代理(Broker)上,以提供数据冗余和高可用性。
Isr: 这是同步副本列表(In-Sync Replicas,简称 ISR),包含当前与领导者同步的副本。
分区 0 的领导者是 Broker 1,副本在 Broker 1 和 2 上,且这两个副本都在 ISR 列表中,这意味着它们都是活跃的并且与领导者同步。
分区 1 的领导者是 Broker 2,副本在 Broker 2 和 0 上,同样这两个副本也都在 ISR 列表中。
分区 2 的领导者是 Broker 0,副本在 Broker 0 和 1 上,这两个副本也在 ISR 列表中。
这个输出显示了 Kafka 集群的健康状态,所有分区的副本都处于活跃状态,并且与领导者同步。
这表明 Kafka 集群正在正常运行,并且主题 test01 的数据具有高可用性。