python_入门基础语法(2)
这是第三天, 已经完成了python 基础语法的学习, 可以去学ros2了
条件语句
语法格式
(1) if
(2)if - else
(3)if - elif - else
#输入 1 表示愿意认真学习, 输入 2 表示躺平摆烂
choice = input('输入 1 表示愿意认真学习, 输入 2 表示躺平摆烂:')
if choice == '1':print('你能找到好的工作')
elif choice == '2':print('你废了')
else:print('按照要求!笨蛋')缩进和代码块
代码块 指的是一组放在一起执行的代码.
相当于缩进就是相当于c++里面if{} 括起来 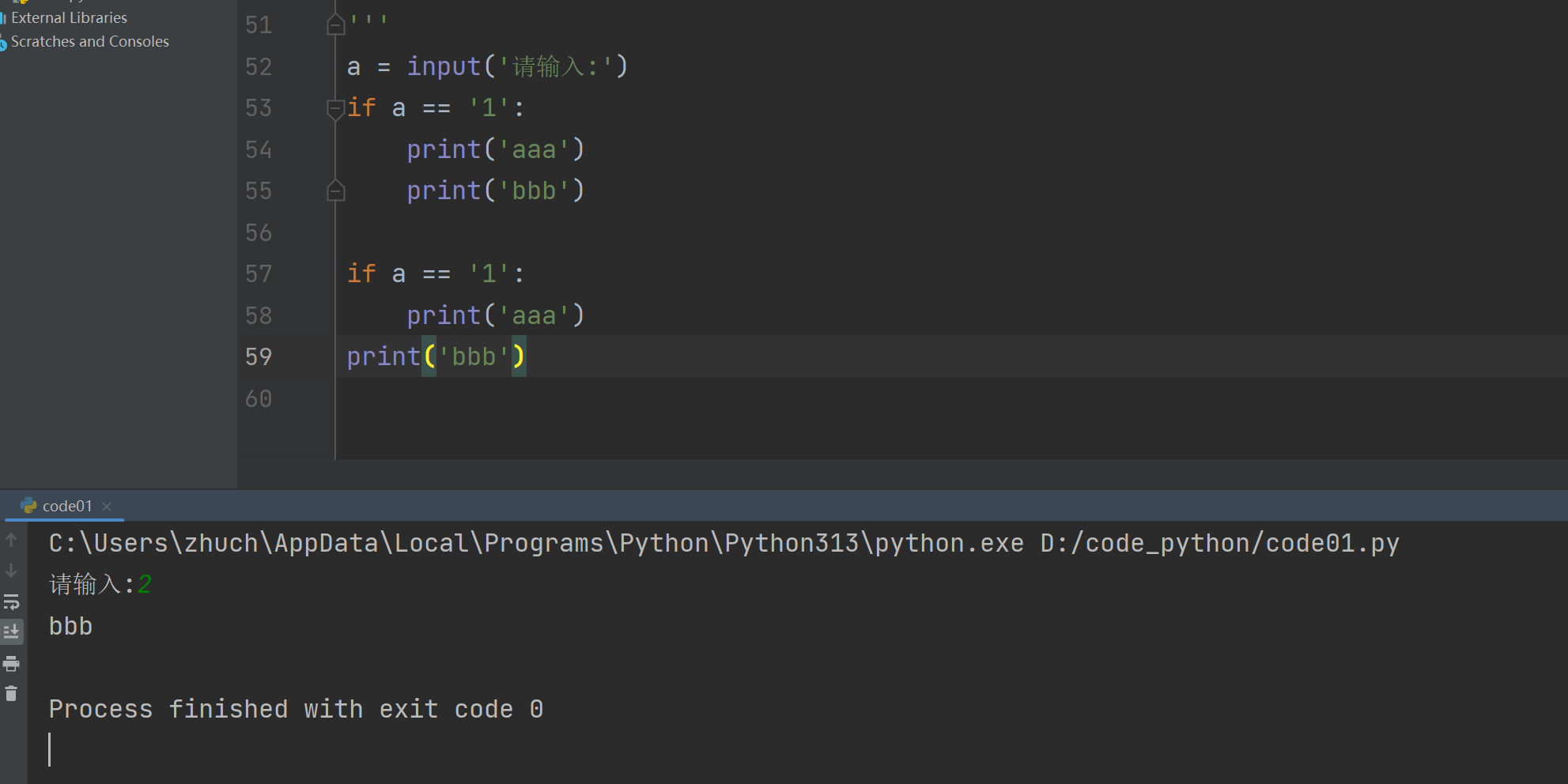
python中,缩进表示代码块,在if,else elif .while.for 等等,需要跟上代码块的部分,都是需要使用缩进来表示.
但是c++中缩进不是硬性要求! 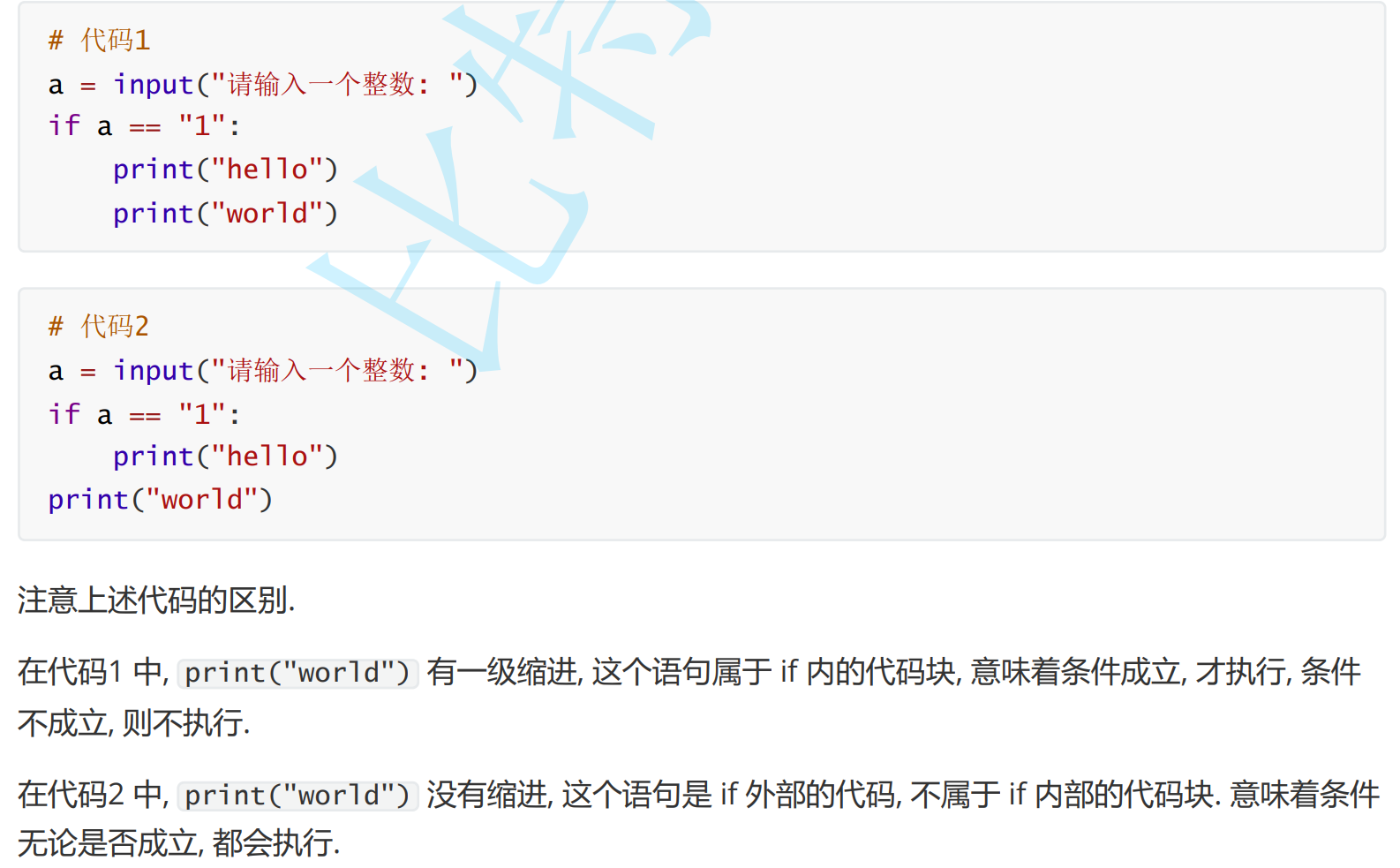
像 C++ / Java 这些语言, 即使完全不写缩进, 语法也不会报错. 代码可读性就比较差.
但是这样也有缺点:嵌套太多层的时候就难搞了
if a == 1:if b == 2:if c == 3:if d == 4:if e == 5:if f == 6:if g == 7:print("hello")print("1")print("2")因此, 就有了 "写 Python 需要自备游标卡尺" 这个梗.
空语句 pass
if 后面不能直接跟 else 那么这里就可以放一个pass
因为python对语法格式和代码块的要求较高,所以啥都不放(只写个注释),是不符合语法要求的
a = input('请输入a:')
a = int(a)
if a != 1:pass
else :print('你真棒')
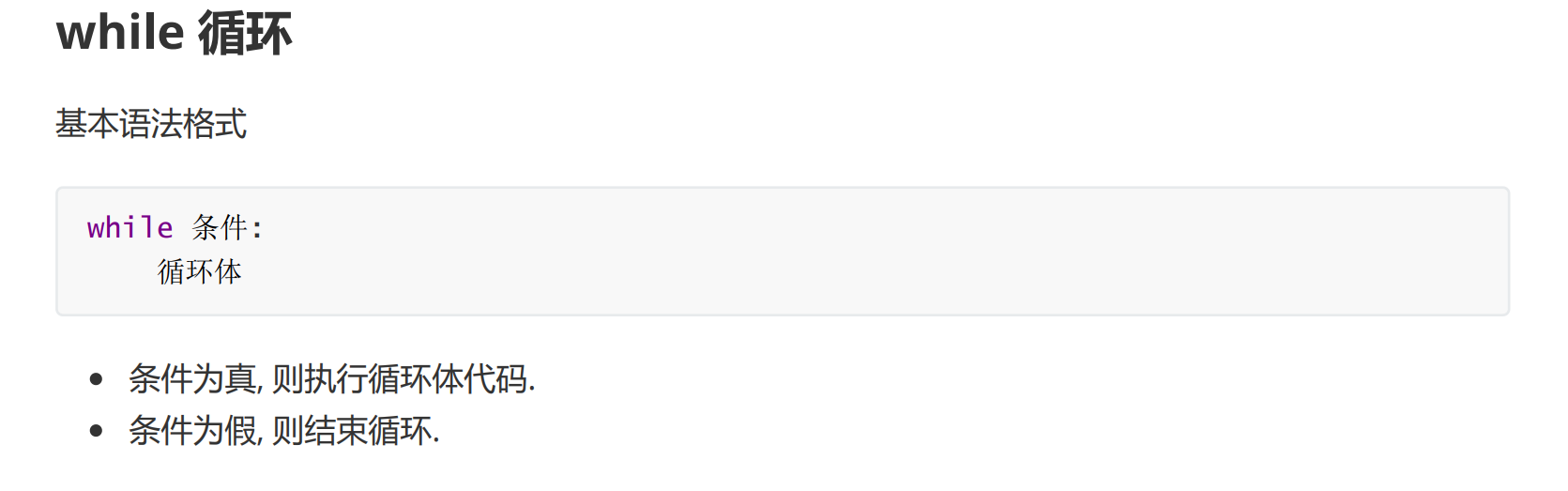
循环语句
while循环
for 循环

python 的 for 和其他语言不同, 没有 "初始化语句", "循环条件判定语句", "循环变量更新语句", 而是
更加简单
所谓的 "可迭代对象", 指的是 "内部包含多个元素, 能一个一个把元素取出来的特殊变量"
使用 range 函数, 能够生成一个可迭代对象. 生成的范围是 [1, 11), 也就是 [1, 10]
同时range函数的第三个变量, 也可以控制迭代的时候的步长
下面是演示
a = 0
for i in range(1, 10):print(i)for i in range(1, 10, 2):print(i)for i in range(10, -1, -1):print(i)
a = 0
for i in range(1, 101):a += i
print(a)python里面有一个sum 内嵌函数,我们自己定义sum就会起冲突哦
其实就是修改一下就可以了 ,shift+F6 就可以修改所有的变量名字
continue
for i in range(1, 11):if i == 3:print('吃到了虫子!!!!!!!!!')else:continueprint(f'吃到了第{i}个包子')break
Sum = 0
i = 0
while True:a = input('请输入a:')if a == ';':breakelse:a = int(a)Sum += ai += 1
print(f'结果是{Sum / i}')#random 是一个python的模块
但是如果想引入其他模块,需要先使用inport语句,把模块的名字给导入进来
PyCharm 有一个功能,能够自动导入当前目前的模块
函数
语法格式
def calcSum(begin, end):theSum = 0for i in range(begin, end + 1):theSum += iprint(theSum)calcSum(1, 100)
calcSum(1, 10)
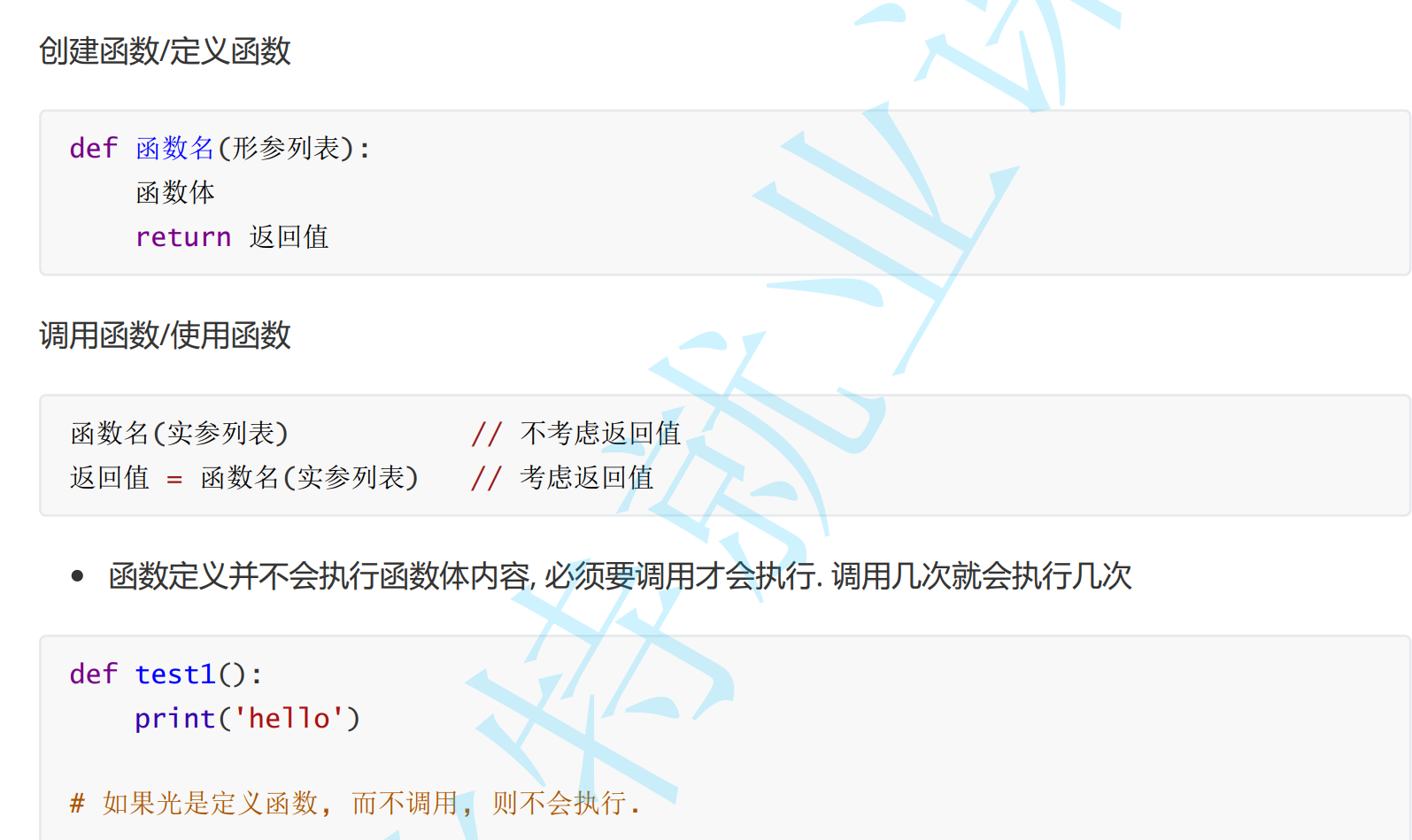
和 C++ / Java 不同, Python 是动态类型的编程语言, 函数的形参不必指定参数类型. 换句话说, 一个函数可以支持多种不同类型的参数
python 的函数名字和变量名最好是小写,要不然会有警告
 这两个就是在函数定义前后至少要有2个空行
这两个就是在函数定义前后至少要有2个空行
PEP 8是python里面的一个编程规范(写代码的软性要求)
函数返回值
def calc_sum(begin, end):the_sum = 0for i in range(begin, end + 1):the_sum += ireturn the_sumret1 = calc_sum(1, 100)
ret2 = calc_sum(1, 10)
print(ret1)
print(ret2)一个函数中可以有多个 return 语句
一个函数是可以一次返回多个返回值的. 使用 , 来分割多个返回值.
这就跟c/c++ 区别很大了
如果只想关注其中的部分返回值, 可以使用 _ 来忽略不想要的返回值.
def get_point():a = 20b = 10return a, bc, d = get_point()
print(c)
print(d)
_, f = get_point()
print(f)变量的作用域
x = 20def test():global xx = 10print(f'局部域中的x: {x}')test()
print(f'全局域中的x: {x}')
如果是想在函数内部, 修改全局变量的值, 需要使用 global 关键字声明
要不然函数里面的x, 和函数外面全局变量不是同一个变量
函数内部的变量一个新的变量
如果此处没有 global , 则函数内部的 x = 10 就会被视为是创建一个局部变量 x, 这样就和全局变量 x 不相关了
if / while / for 等语句块不会影响到变量作用域
函数执行过程
这里发现, python 也支持缺省参数

关键字参数
在调用函数的时候, 需要给函数指定实参. 一般默认情况下是按照形参的顺序, 来依次传递实参的.但是我们也可以通过 关键字参数, 来调整这里的传参顺序, 显式指定当前实参传递给哪个形参.
def test(x, y):print(f'x: {x}')print(f'y: {y}')test(x = 1, y = 2)
test(y = 100,x = 200)
列表和元组
说白了就是数组(c/C++)
元组和列表相比, 是非常相似的, 只是列表中放哪些元素可以修改调整, 元组中放的元素是创建元组的时候就设定好的, 不能修改调整.

创建列表
因为 list 本身是 Python 中的内建函数, 不宜再使用 list 作为变量名, 因此命名为 alist
#创建列表
# 1. 直接用字面值来创建
# [] 就表示一个空的列表
a = []
print(type(a))# 2. 使用list() 来创建
b = list()
print(type(b))# 3. 可以在创建列表的时候可以在[] 中指定列表的初始值
c = [1, 2, 3, 4]
print(c)# 不同变量
d = [1, 'hellow', 234]
print(d)#访问下标
print(d[2])列表中存放的元素允许是不同的类型. (这一点和 C++ Java 差别较大).
python里面无限制
因为下标是从 0 开始的, 因此下标的有效范围是 [0, 列表长度 - 1]. 使用 len 函数可以获取到列表的 元素个数.
下标可以取负数. 表示 "倒数第几个元素"
其实就是得到a[len(a)-1] == a[-1] ,也可以理解为-1这个下标其实也是最后一个元素
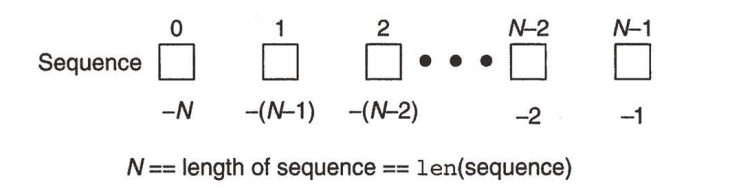
切片操作
通过下标操作是一次取出里面第一个元素.
通过切片, 则是一次取出一组连续的元素, 相当于得到一个 子列表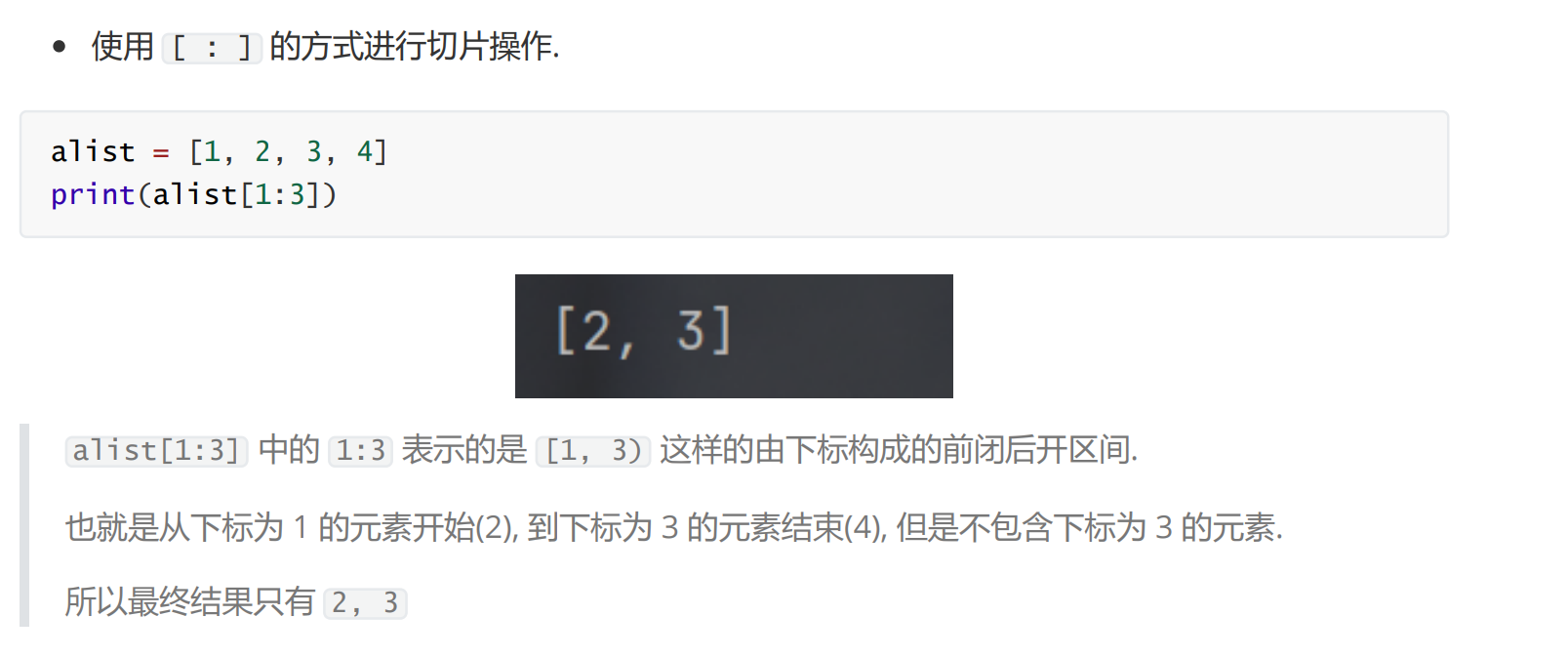

遍历列表元素
这里跟c++中的范围for一模一样
下面就是三种遍历方式
a = [1, 2, 3, 4]
for e in a:print(e)
for i in range(0,len(a)):print(a[i])
i = 0
while i < len(a):print(a[i])i += 1新增元素
a = [1, 2, 3, 4, 1]
a.insert(1, 100)
a.append('hellow')
print(a)
查找元素
使用 in 操作符, 判定元素是否在列表中存在. 返回值是布尔类型.
使用 index 方法, 查找元素在列表中的下标. 返回值是一个整数. 如果元素不存在, 则会抛出异常.
抛异常的原因就是python的下标支持负数,所以直接抛异常
a = [1, 2, 3, 4, 5]
print(10 in a)
print(1 in a)print(a.index(1))
print(a.index(10))删除元素
其实就是用pop()里面不传就是尾删,传就是按照下标删除
或者直接用remove()删除元素
a = [1, 2, 3, 4, 5]
a.pop()
a.remove(1)
print(a)
连接列表
1 可以用+ (这跟c++ 里面的运算符重载一样)
2使用 extend 方法, 相当于把一个列表拼接到另一个列表的后面.


关于元组
元组不能修改里面的元素, 列表则可以修改里面的元素
因此, 像读操作,比如访问下标, 切片, 遍历, in, index, + 等, 元组也是一样支持的.
但是, 像写操作, 比如修改元素, 新增元素, 删除元素, extend 等, 元组则不能支持.
这里注意,虽然extend 不支持,但是+(这个连接元组是可以的)
另外, 元组在 Python 中很多时候是默认的集合类型. 例如, 当一个函数返回多个值的时候.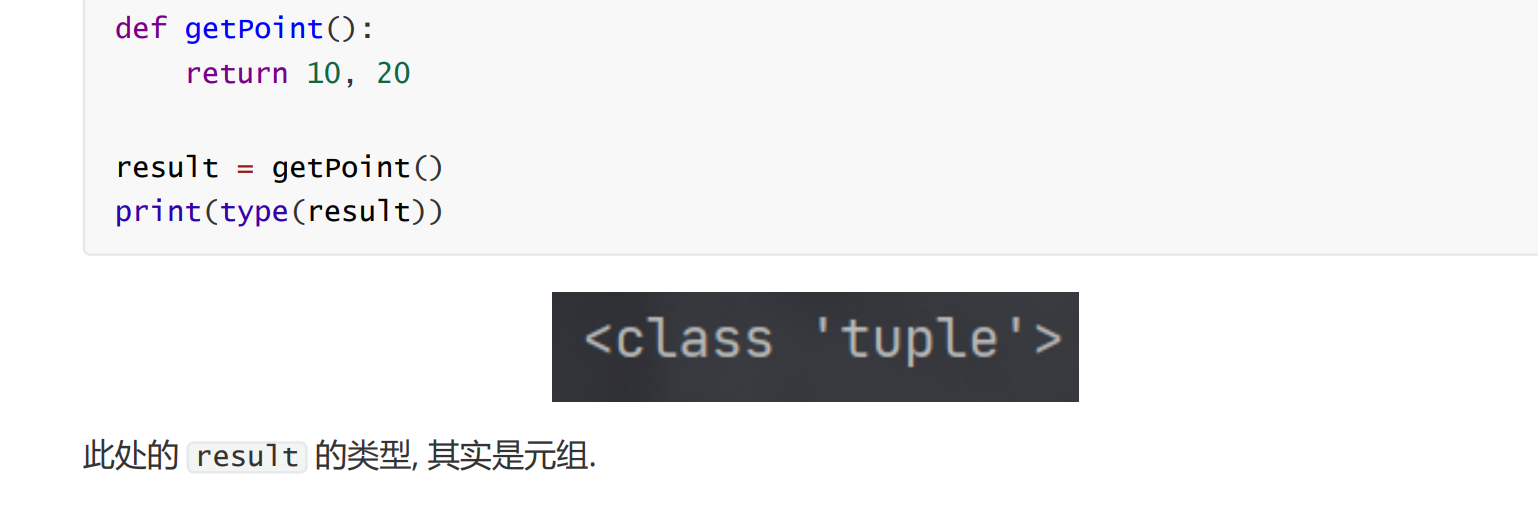
字典
对于字典来说, 使用in 或者 [ ] 来获取value , 都是非常高效的
但是对于列表来说,使用 in 是比较低效的, 而使用 [ ] 是比较高效的(不用去遍历一遍)
创建字典
b = {}
c = dict()
新增/修改元素
这个就是用 [ ] 来新增,不存在就去新增, 存在就去修改
删除元素
就是用pop() , 去传一个key
遍历字典元素
直接使用 for 循环能够获取到字典中的所有的 key, 进一步的就可以取出每个值了.
取出所有 key 和 value
使用 keys 方法可以获取到字典中的所有的 key
使用 values 方法可以获取到字典中的所有 value
此处 dict_values 也是一个特殊的类型, 和 dict_keys 类似
使用 items 方法可以获取到字典中所有的键值对.
此处 dict_items 也是一个特殊的类型, 和 dict_keys 类似.
c++ 里面哈希表的键值对是无序的, 但是python里面不同, python里面的哈希表进行了特殊处理, 能够以插入的顺序打印
a = {'id': 1,'name': 'shanghai' ,'score': 90}
print(a)
for e in a:print(e, a[e])
print(a.keys())
print(type(a.keys()))
print(a.values())
print(type(a.values()))
print(a.items())
print(type(a.items()))
b = a.keys()
for e in b:print(e)
//其他的类似, 我们就把这几种特殊的类型当作列表就行合法的 key 类型
不是所有的类型都可以作为字典的 key. 字典本质上是一个 哈希表,
哈希表的 key 要求是 "可哈希的", 也就是可以计算出一个哈希值.
可以使用 hash 函数计算某个对象的哈希值.
但凡能够计算出哈希值的类型, 都可以作为字典的 key.
#用hash 函数可以计算出一个变量的哈希值
print(hash(0))
print(hash(3.14))
print(hash('hellow'))
print(hash(True))
print(hash((1, 2, 3)))#有的类型是不能计算hash
print(hash([1, 2, 3]))
print(hash({1 : 'xiao', 2 : 'da'}))
不可变的对象, 一般就是可哈希的
可变的对象,一般就是不可哈希的
文件
文件路径
一个机器上, 会存在很多文件, 为了让这些文件更方面的被组织, 往往会使用很多的 "文件夹"(也叫做目录) 来整理文件.
实际一个文件往往是放在一系列的目录结构之中的.
为了方便确定一个文件所在的位置, 使用 文件路径 来进行描述.
例如, 上述截图中的 QQ.exe 这个文件, 描述这个文件的位置, 就可以使用路径 D:\program\qq\Bin\QQ.exe 来表示.
D: 表示 盘符. 不区分大小写.
每一个 \ 表示一级目录. 当前 QQ.exe 就是放在 "D 盘下的 program 目录下的 qq 目录下的 Bin目 录中" .
目录之间的分隔符, 可以使用 \ 也可以使用 / . 一般在编写代码的时候使用 / 更方便.
文件操作
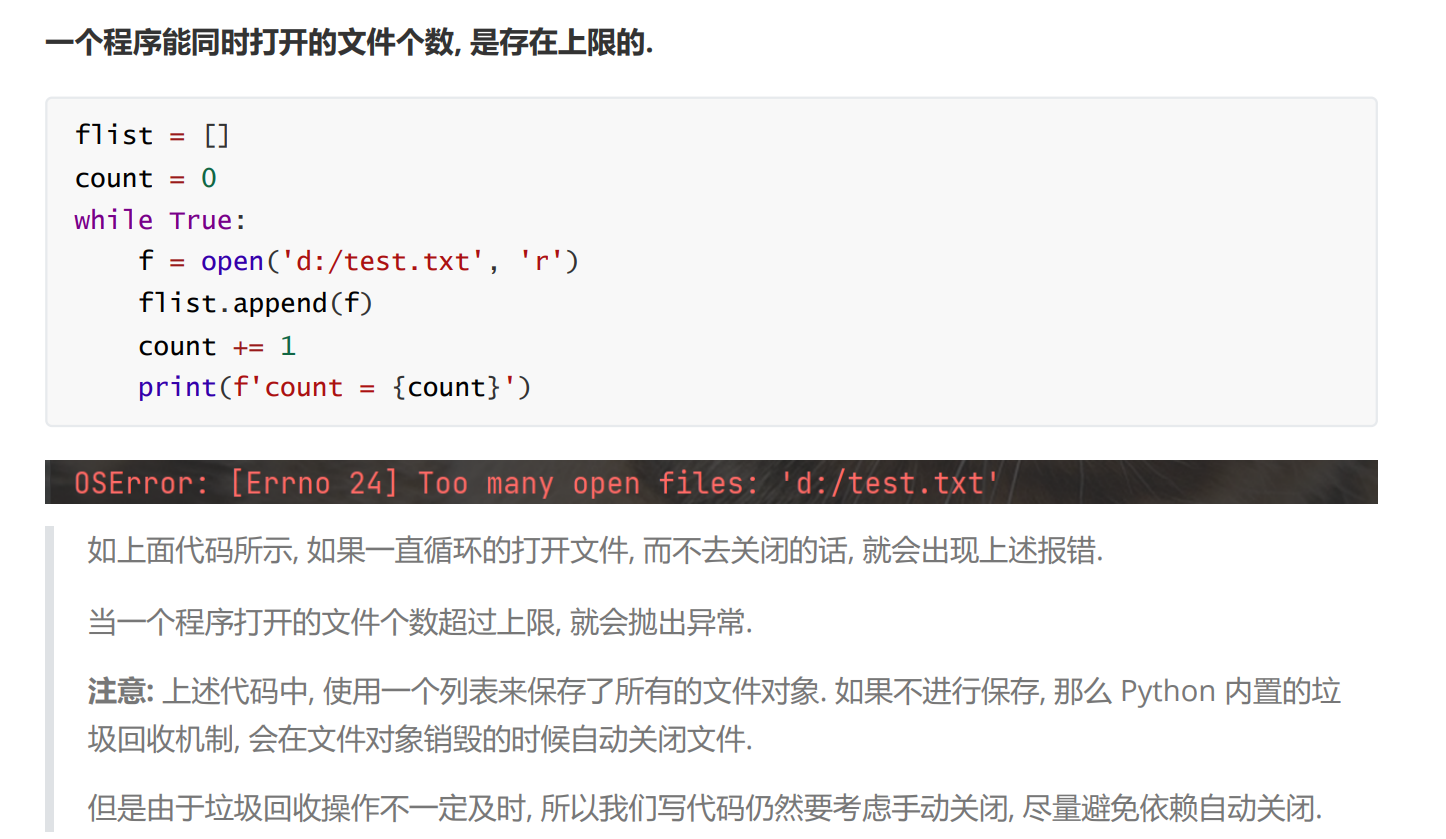
要使用文件, 主要是通过文件来保存数据, 并且在后续把保存的数据读取出来. 但是要想读写文件, 需要先 "打开文件", 读写完毕之后还要 "关闭文件".
1 打开文件
就是用open 函数
第一个参数是一个字符串, 表示要打开的文件路径 第二个参数是一个字符串, 表示打开方式.
其中 r 表示按照读方式打开.
w 表示按照写方式打开.
a 表示追加写方式打开.
如果打开文件成功, 返回一个文件对象. 后续的读写文件操作都是围绕这个文件对象展开.
如果打开文件失败(比如路径指定的文件不存在), 就会抛出异常.
open 的返回值就是一个文件对象, 如何理解?
此处的文件对象就是内存上的一个变量, 后续读写文件操作都是拿着这个文件对象来进行操作的
计算机中把这样的额远程操控的遥控器称为句柄(handler)
2 关闭文件
就是用close 函数
3 写文件
文件打开后就可以写文件了,就是用open (以写的形式打开, 第二个函数就是传w)
然后就用write函数直接写就可以了
使用 'w' 一旦打开文件成功, 就会清空文件原有的数据.
使用 'a' 实现 "追加写", 此时原有内容不变, 写入的内容会存在于之前文件内容的末尾.
f = open('d:/code_python/test/test.txt','a')
print(f)
print(type(f))#f.write('world,danshi')
f.write("dfadsfasdfffffffffffffffffffffffffff")
f.close()
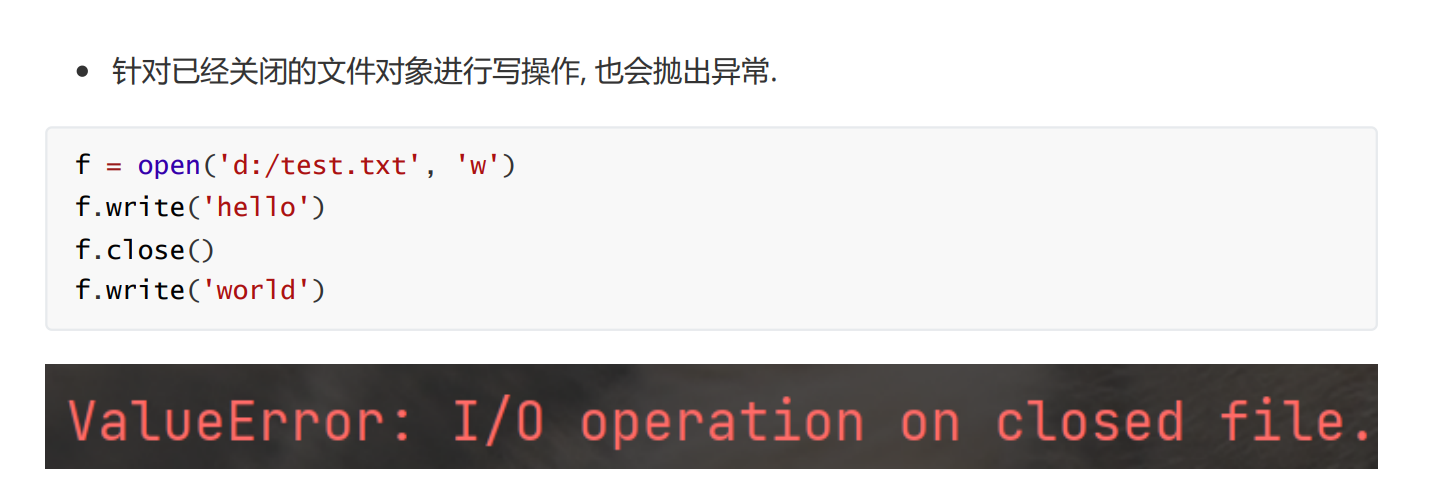
4 读文件
读文件内容需要使用 'r' 的方式打开文件
使用 read 方法完成读操作. 参数表示 "读取几个字符"
如果想按照行来取, 就用for循环就可以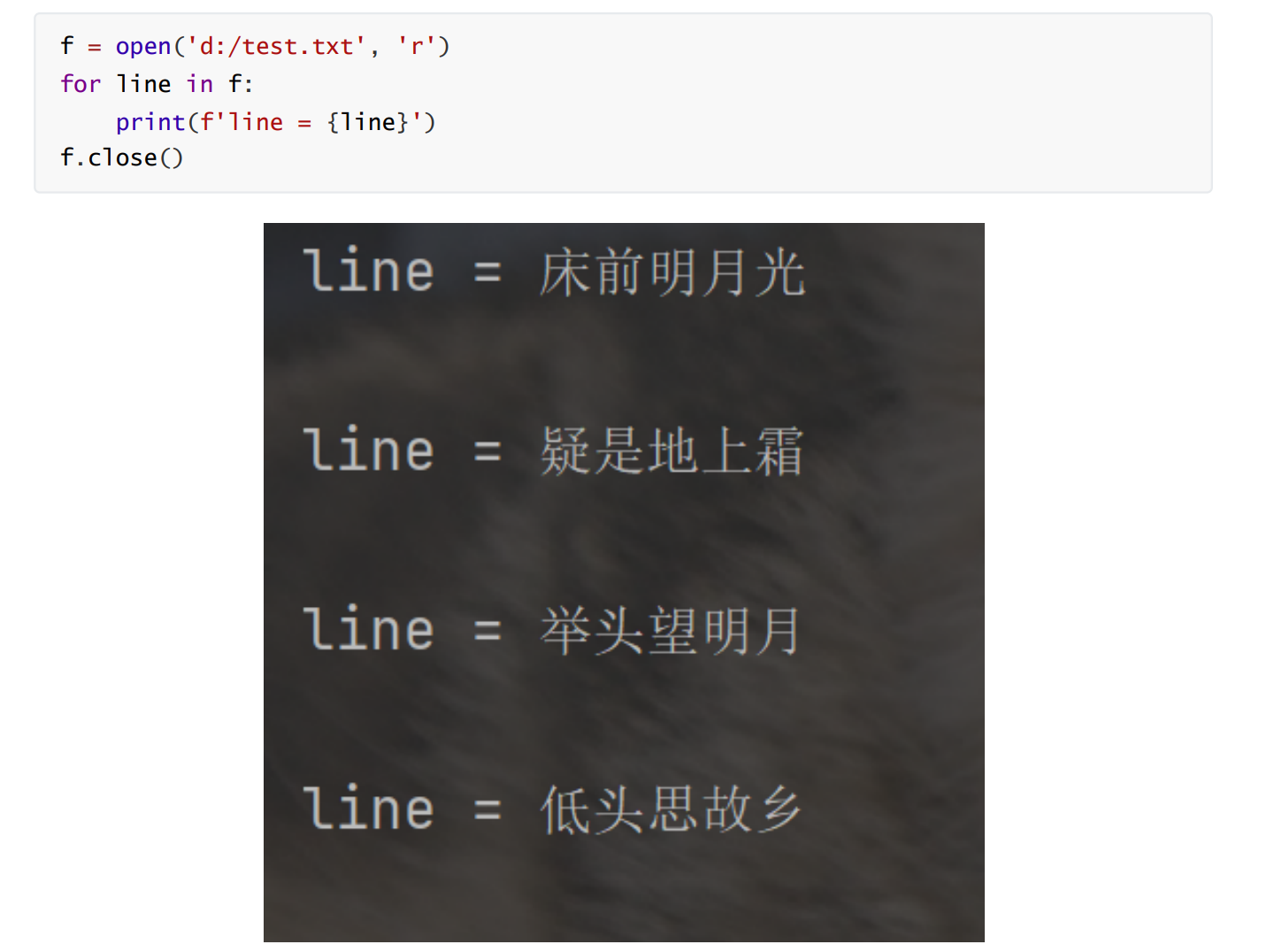
注意: 由于文件里每一行末尾都自带换行符, print 打印一行的时候又会默认加上一个换行符, 因此 打印结果看起来之间存在空行.
使用 print(f'line = {line}', end='') 手动把 print 自带的换行符去掉.
使用 readlines 直接把文件整个内容读取出来, 返回一个列表. 每个元素即为一行.
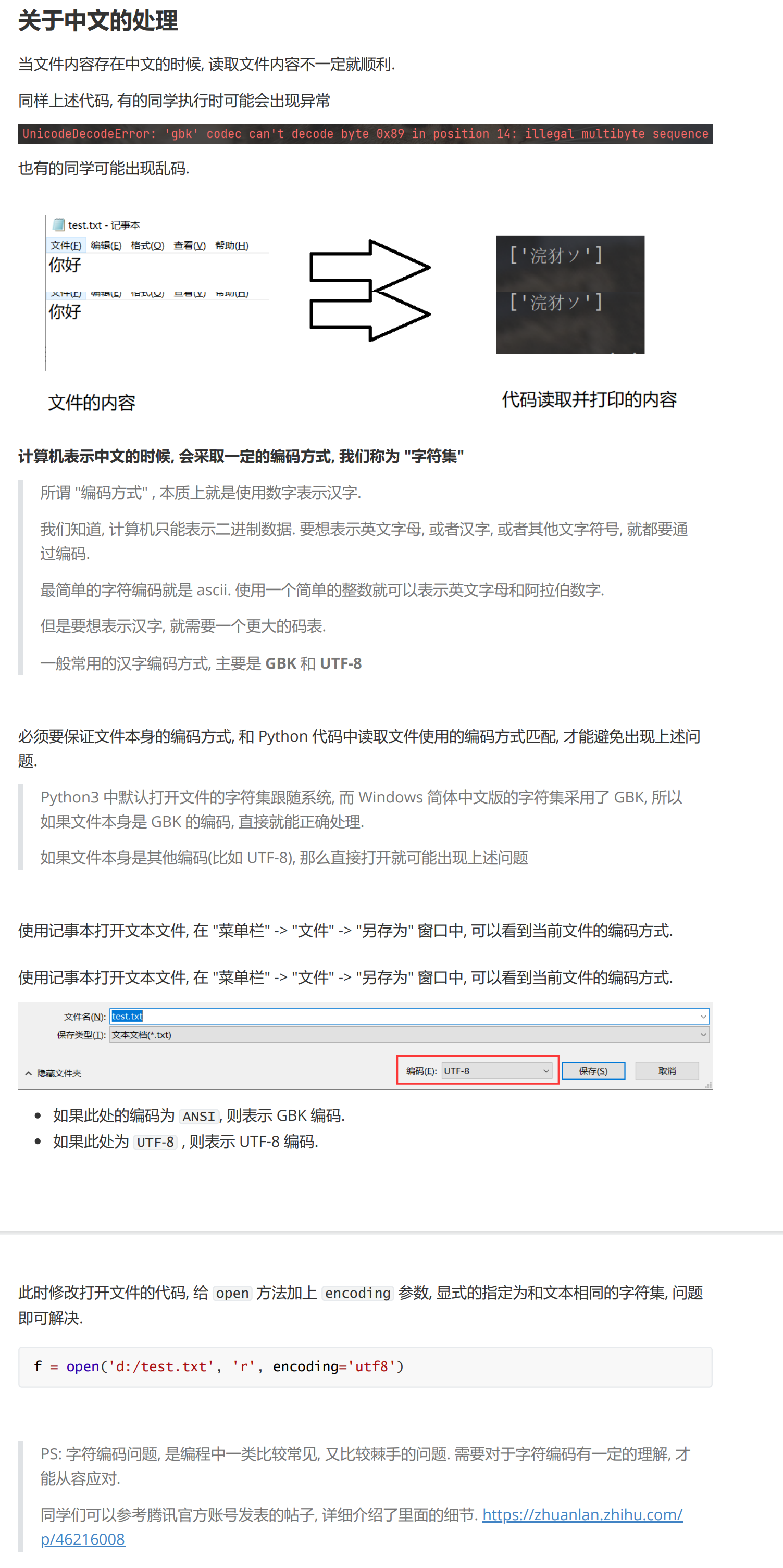
标准库
