MathQ-Verify:数学问题验证的五步流水线,为大模型推理筑牢数据基石
MathQ-Verify:数学问题验证的五步流水线,为大模型推理筑牢数据基石
大语言模型在数学推理领域进展显著,但现有研究多聚焦于生成正确推理路径和答案,却忽视了数学问题本身的有效性。MathQ-Verify,通过五阶段流水线严格过滤 ill-posed 或描述不明确的数学问题,为构建可靠的数学数据集提供了可扩展且准确的解决方案,一起来了解这一创新方法吧!
论文标题
Let’s Verify Math Questions Step by Step
来源
arXiv:2505.13903v1 [cs.CL] + https://arxiv.org/abs/2505.13903
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
研究背景
大语言模型(LLMs)在数学推理方面取得了显著进步,其推理能力在很大程度上归功于高质量的数据源和高效的训练框架。然而,大多数现有的大规模数学问答数据集主要由合成的问答对组成,若问题本身存在缺陷,答案也不可能正确,因此问题的正确性至关重要。
研究问题
1. 缺乏全面的问题验证方法:虽然最近有几项研究开始关注数学问题的有效性,但它们的重点通常局限于诸如假设缺失或前提模糊等狭窄的错误类型,未能建立一个系统而全面的框架来识别 ill-posed 或有缺陷的问题,导致许多数据集仍包含存在内部不一致、逻辑矛盾或违反基本数学原理的问题。
2. 缺乏用于问题验证的分步高难度基准:现有的基准,如 MathClean,没有提供足够有挑战性的问题,也没有包含评估多步问题验证流水线每个阶段所需的细粒度、分步注释,这限制了严格评估模型检测和推理数学问题表述中复杂缺陷的能力。
主要贡献
1. 构建新数据集 ValiMath:通过整合 NuminaMath 中的合成问题并为其丰富结构化的分步标签,专门设计用于支持对数学问题正确性的全面评估。该数据集包含 2,147 个问题(1,299 个正确,848 个错误),覆盖五种不同的错误类型,为模型评估提供了更全面的支持。
2. 提出 MathQ-Verify 流水线:通过将数学问题分解为结构化组件,并根据形式化标准检查每个部分,逐步验证数学问题的正确性。该流水线在 MathClean 的两个评估集上取得了最先进的结果,与直接验证基线相比,在 ValiMath 上 F1 提高了近 15%。
3. 验证各组件有效性:通过消融研究,系统地验证了 MathQ-Verify 流水线中每个验证阶段对整体性能的单独贡献。此外,证明了在验证输出中加入多数投票策略可显著提高精度,达到 90% 以上,突显了该方法的稳健性和可靠性。
方法论精要
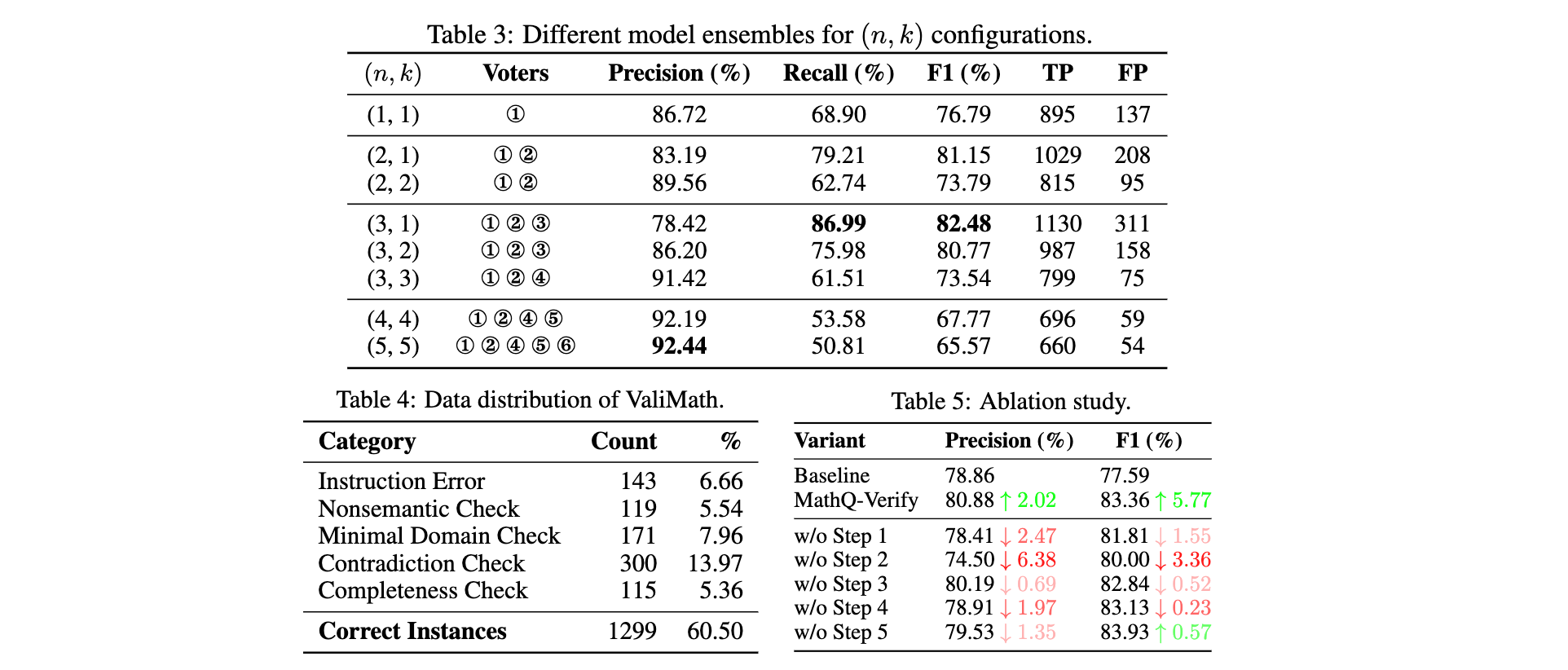
1. 核心算法/框架:MathQ-Verify 是一个五阶段的验证流水线,包括污染指令检测、语言错误检测、原子条件错误检测、跨条件冲突检测和条件完整性验证。该框架通过逐步分解和验证数学问题的各个组成部分,确保对问题质量进行全面评估。
2. 关键参数设计原理:在污染指令检测中,通过定义二进制指令有效性指标,确保问题是真正的数学问题,没有误导性语言模式和明确的答案泄露。在语言错误检测中,采用 Qwen-2.5-7B-Instruct 模型检测拼写错误、语法错误和 LaTeX 格式异常等语言层面的问题。在原子条件错误检测中,严格验证每个原子条件是否符合相应数学领域的规则,任何与基本定义矛盾的条件都被严格拒绝。
3. 创新性技术组合:将问题分解为原子条件和目标目标两个结构化组件,作为验证的基础。采用多模型投票策略,通过聚合多个独立训练模型的预测来增强条件验证的稳健性,通过调整投票阈值来平衡精度和召回率。

4. 实验验证方式:使用 MathClean 基准的 GSM8K 和 MATH 合成注释版本作为主要评估数据集,同时纳入 ValiMath 数据集进行全面评估。对比基线为直接评估每个输入问题正确性的方法,不采用 MathQ-Verify 框架的分解或多步验证程序。通过准确率、精确率、召回率、F1 分数、无效输出数量和分步准确率等标准评估指标来衡量模型性能。
实验洞察
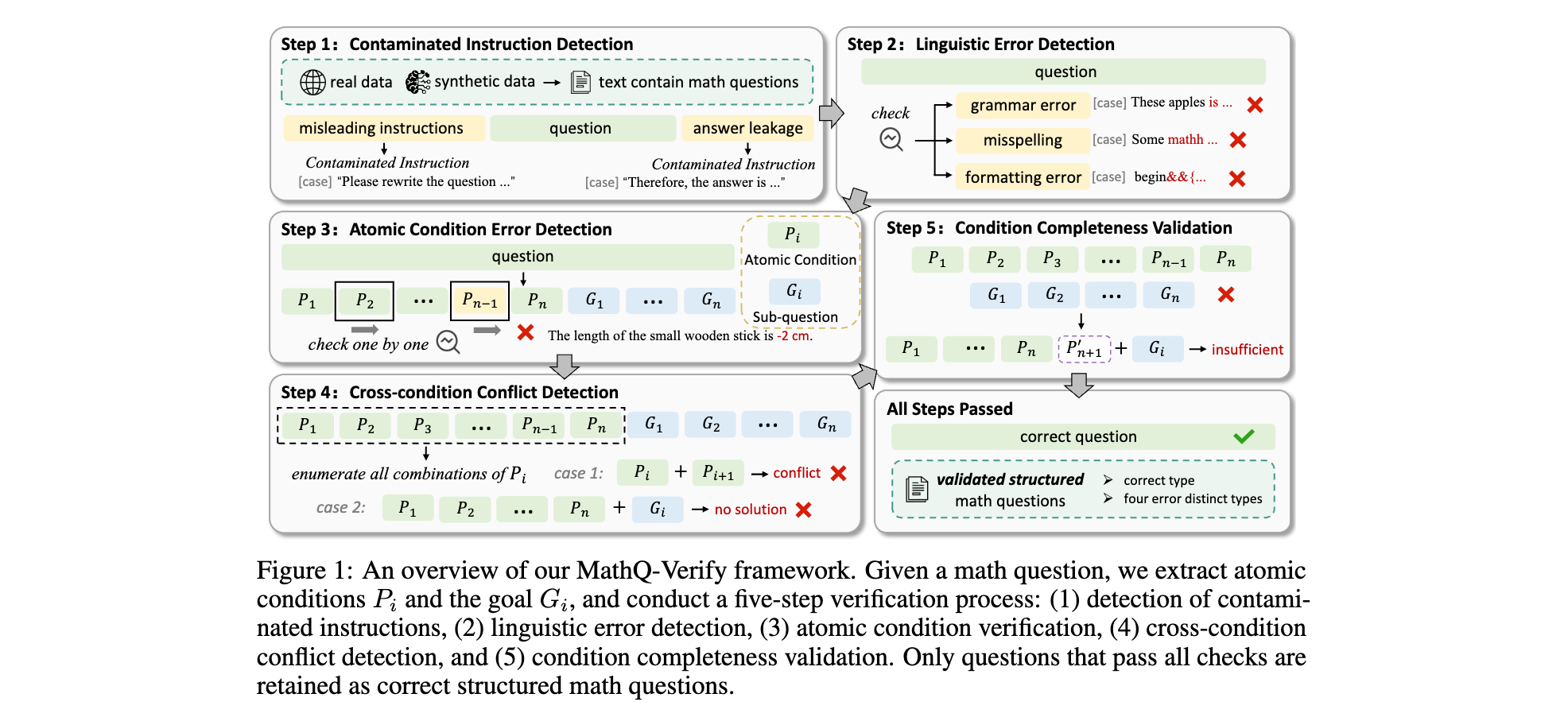
1. 性能优势:在 MathClean-GSM8K 上,Qwen2.5-7B 基线的 F1 为 74.02%,MathQ-Verify 提升至 76.09%;在 MathClean-MATH 上,Llama-3.1-8B 基线的 F1 为 58.82%,MathQ-Verify 提升至 72.42%。在 ValiMath 上,GPT-o4-mini 基线的 F1 为 77.59%,MathQ-Verify 提升至 83.36%,且精确率达到 80.88%。
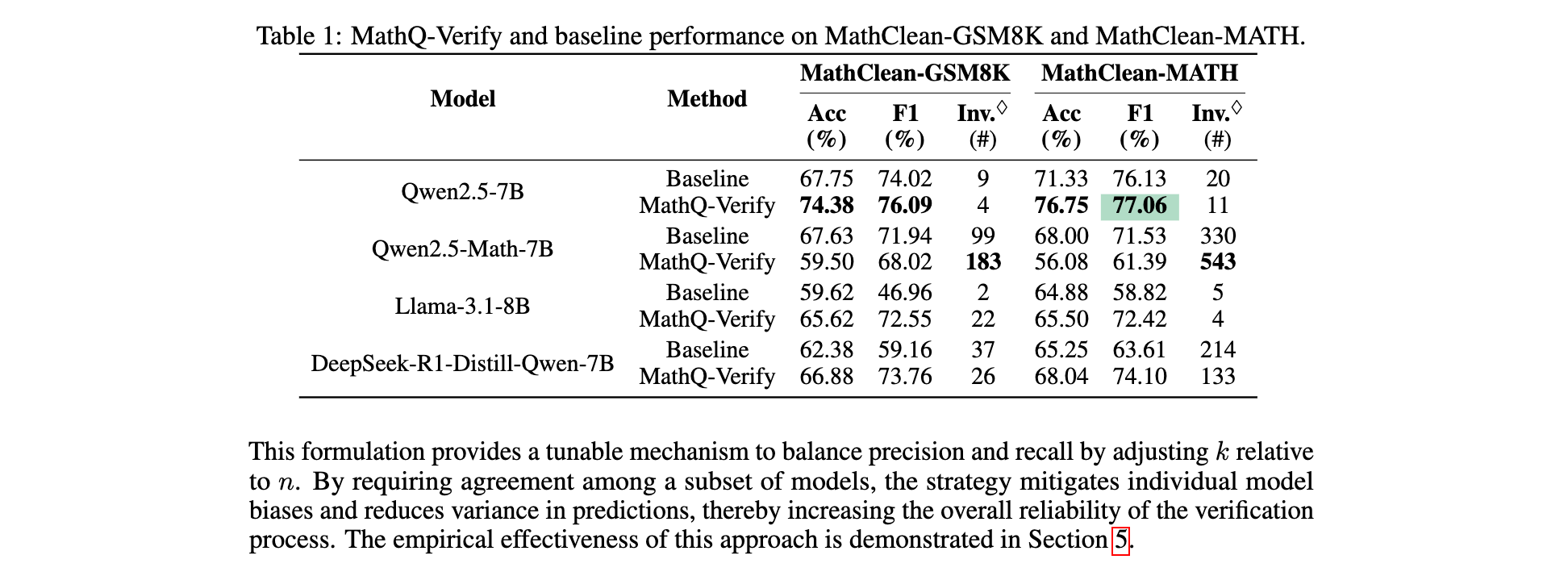
2. 效率突破:通过多模型投票策略,在 (3, 3) 配置下,虽然召回率有所下降,但精确率可达 91.42%;在 (3, 1) 配置下,F1 达到 82.48%,召回率为 86.99%,在保证一定召回率的同时有效提升了预测质量。
3. 消融研究:省略前两个验证步骤(污染指令检测和语言错误检测)导致精度和 F1 分别下降超过 6% 和 3%;移除矛盾检测(第四步)使精度下降约 2%;移除条件完整性验证(第五步)F1 略有提升但精度下降,表明各模块均有独特贡献,组合使用可实现最佳的精确率 - 召回率平衡。