【基于SpringBoot的图书管理系统】Redis在图书管理系统中的应用:加载和添加图书到Redis,从数据同步到缓存优化
引言
在当今互联网应用开发中,高性能和高并发处理能力已成为系统设计的核心考量。对于图书管理系统这类需要频繁进行数据查询的应用而言,数据库的访问效率往往成为系统性能的瓶颈。Redis作为一款高性能的键值存储数据库,凭借其内存存储特性和丰富的数据结构,成为解决这类问题的理想选择。
本项目围绕图书管理系统中的特价秒杀功能模块,深入探讨如何通过Redis实现数据缓存与加速。我们将从整体架构设计入手,逐步解析Redis序列化配置、数据同步机制、前后端交互流程等关键技术点,最终呈现一个完整的基于Redis优化的系统实现方案。通过本案例,读者将了解到如何在实际项目中有效利用Redis提升系统性能,以及如何处理缓存与数据库之间的数据一致性问题。

1. 整体的代码逻辑
1.1 Redis逻辑
在整个系统架构中,Redis承担着数据缓存的核心角色。其主要逻辑包括:
- 数据序列化与存储:通过自定义RedisTemplate配置,使用JSON序列化方式存储Java对象,确保数据在Redis中的正确存储与读取。
- 初始化数据加载:系统启动时自动将MySQL中符合条件的数据加载到Redis,实现缓存预热。
- 数据查询与分页:业务逻辑层直接从Redis获取数据,进行分页处理后返回给前端,减少数据库访问压力。
- 键值管理:采用统一的键命名规范(如"bookInfoId:"前缀),便于批量操作和管理。

1.2 Controller层逻辑
Controller层作为前端请求的入口,主要负责:
- 请求接收与参数验证:接收前端分页请求,验证页码和每页数据量等参数的合法性。
- 业务逻辑调用:将合法请求转发给Service层,获取处理结果。
- 响应封装:将Service层返回的数据封装为统一的Result格式,包含状态码、错误信息和数据内容,确保前后端交互的规范性。
1.3 Service层逻辑
Service层是业务逻辑的核心处理单元,主要功能包括:
- Redis数据操作:通过RedisTemplate实现对Redis数据的读取、解析和处理。
- 分页计算:根据前端请求的页码和每页数据量,计算数据偏移量,实现高效分页。
- 数据转换:将从Redis获取的数据进行业务处理,如状态码转换为可读的状态描述。
- 结果封装:将处理后的数据封装为分页结果对象,包含总数据量、当前页数据和分页参数。
1.4 Mapper层逻辑
Mapper层负责数据库交互,主要包括:
- SQL定义:通过MyBatis注解或XML配置定义数据库查询语句。
- 数据查询:执行SQL查询,从MySQL获取符合条件的图书信息(如特价秒杀状态的图书)。
- 结果映射:将数据库查询结果映射为Java对象,供上层服务使用。
2. Redis序列化配置和Redis加载Mysql数据
2.1 Redis序列化配置
在分布式系统中,数据序列化是实现跨节点通信和持久化存储的基础。Spring Data Redis提供了灵活的序列化配置机制,允许我们根据业务需求选择合适的序列化方式。以下是本项目中Redis序列化的核心配置:
@Configuration
public class RedisConfig {@Beanpublic RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory connectionFactory) {RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();redisTemplate.setConnectionFactory(connectionFactory);// 使用JSON序列化工具GenericJackson2JsonRedisSerializer jsonRedisSerializer = new GenericJackson2JsonRedisSerializer();// 配置Key的序列化方式为StringredisTemplate.setKeySerializer(RedisSerializer.string());redisTemplate.setHashKeySerializer(RedisSerializer.string());// 配置Value的序列化方式为JSONredisTemplate.setValueSerializer(jsonRedisSerializer);redisTemplate.setHashValueSerializer(jsonRedisSerializer);return redisTemplate;}
}
配置解析:
-
序列化方式选择:
- Key序列化:使用StringRedisSerializer,将键序列化为字符串,便于阅读和管理。
- Value序列化:使用GenericJackson2JsonRedisSerializer,将Java对象序列化为JSON格式,相比JDK序列化更紧凑、跨语言兼容性更好。
-
Hash结构序列化:
- 对Hash类型的键值对分别配置序列化器,确保Hash结构中的Key和Value都能正确序列化。
-
为什么不使用默认序列化:
- Spring Data Redis的默认序列化方式是JdkSerializationRedisSerializer,会在数据中添加大量元信息,导致存储空间浪费。
- JSON格式更易读,且在前后端交互中更为常用,便于调试和问题定位。
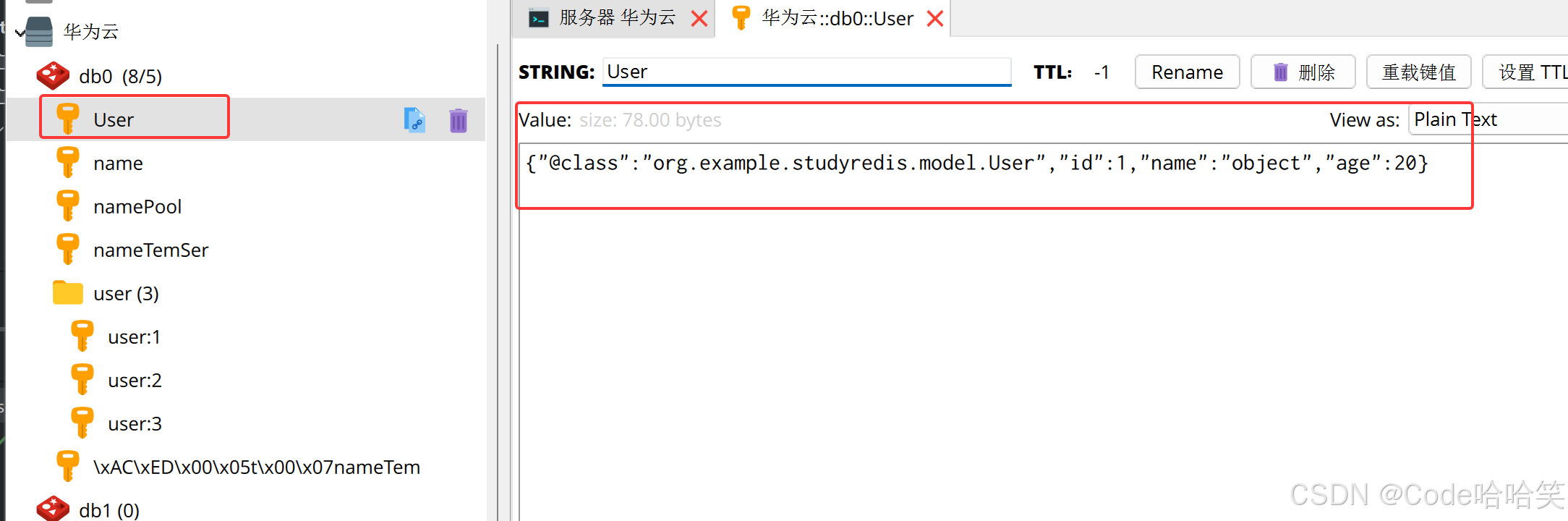
图中的@class内容为荣誉的内容。
2.2 Redis加载Mysql数据
为了实现缓存预热,系统需要在启动时将数据库中的数据加载到Redis中。本项目通过InitializingBean接口实现这一功能:
@Slf4j
@Service
public class DataInitService implements InitializingBean {@Autowiredprivate DataSyncService dataSyncService;@Overridepublic void afterPropertiesSet() throws Exception {log.info("InitializingBean触发数据同步...");dataSyncService.syncMysqlToRedis();}
}
初始化机制解析:
-
InitializingBean接口:
- 实现该接口的bean在初始化完成后会自动调用afterPropertiesSet方法,确保在系统启动时执行数据同步。
- 相比使用@PostConstruct注解,InitializingBean提供了更规范的初始化回调机制。
-
数据同步核心逻辑:
@Slf4j
@Service
public class DataSyncService {@Autowiredprivate RedisMapper redisMapper;@Autowiredprivate RedisTemplate<String, Object> redisTemplate;public void syncMysqlToRedis() {log.info("开始同步MySQL数据到Redis...");long startTime = System.currentTimeMillis();try {// 从MySQL查询特价秒杀状态的图书List<BookInfo> bookInfoList = redisMapper.getBookInfoList();if (bookInfoList == null) {log.info("MySQL中无数据可同步");return;}// 批量存入Redisfor (BookInfo bookInfo : bookInfoList) {String id = "bookInfoId:" + bookInfo.getId();redisTemplate.opsForValue().set(id, bookInfo);}long endTime = System.currentTimeMillis();log.info("数据同步完成,共同步{}条数据,耗时{}ms", bookInfoList.size(), endTime - startTime);} catch (Exception e) {log.error("数据同步失败", e);throw new RuntimeException("Redis数据预加载失败", e);}}
}
-
数据同步流程:
- 查询阶段:通过RedisMapper从MySQL查询状态为特价秒杀(status=3)的图书信息。
- 存储阶段:使用"bookInfoId:"+id的键格式,将每条图书信息存储到Redis中。
- 性能监控:记录同步开始和结束时间,计算同步耗时,便于性能分析和优化。
-
键命名规范:
- 采用"模块名:实体名:id"的命名方式,如"bookInfoId:1",确保键的唯一性和可识别性。
- 统一的命名规范便于后续的键管理和批量操作(如使用keys命令获取所有图书键)。
3. Controller层代码解析
Controller层作为前后端交互的桥梁,负责请求的接收、参数验证和响应封装。以下是特价秒杀管理的核心控制器:
@Slf4j
@RequestMapping("/special")
@RestController
public class SpecialDealAdminController {@Autowiredprivate SpecialDealAdminService specialDealAdminService;@RequestMapping("/getSpecialListByPage")public Result addSpecialBookInfo(PageRequest pageRequest, HttpSession session) {log.info("Controller--特价秒杀展示");// 参数校验if (pageRequest.getPageSize() < 1 || pageRequest.getCurrentPage() <= 0) {Result result = new Result();result.setStatus(ResultStatus.FAIL);result.setErrorMessage("参数验证失败");return result;}PageResult<BookInfo> pageResult = null;try {pageResult = specialDealAdminService.getSpecialBookListByPage(pageRequest);} catch (Exception e) {log.error("查询翻页信息错误:" + e);}return Result.success(pageResult);}
}
控制器核心功能解析:
-
请求映射与路由:
- 使用@RequestMapping(“/special”)定义基础路径,所有特价秒杀相关请求都以/special开头。
- "/getSpecialListByPage"处理分页查询请求,支持GET和POST方法(默认)。
-
参数验证:
- 对pageRequest中的pageSize和currentPage进行校验,确保pageSize≥1,currentPage>0,避免非法参数导致系统异常。
- 验证失败时返回包含错误信息的Result对象,前端可根据状态码进行相应处理。
-
业务逻辑调用:
- 将合法的分页请求转发给SpecialDealAdminService处理,获取分页结果PageResult。
- 异常处理:捕获业务逻辑层可能抛出的异常,记录日志但不直接返回错误给前端,保持接口的稳定性。
-
响应封装:
- 使用统一的Result类封装响应结果,包含状态码(ResultStatus)、错误信息和数据内容。
- 通过Result.success方法快速构建成功响应,减少重复代码。
统一响应格式设计:
public class Result {private ResultStatus status;private String errorMessage;private Object data;public static Result success(Object data) {Result result = new Result();result.setStatus(ResultStatus.SUCCESS);result.data = data;return result;}// getter and setter
}public enum ResultStatus {SUCCESS(200),UNLOGIN(-1),FAIL(-2);private Integer status;ResultStatus(Integer status) {this.status = status;}// getter
}
统一响应格式的优势:
- 前后端约定:明确的响应结构便于前后端协作,减少沟通成本。
- 错误处理标准化:前端可根据status统一处理成功、未登录、失败等不同场景。
- 扩展性强:如需添加新的状态码或响应字段,只需修改枚举类和Result类,不影响现有接口。
4. Service层代码解析
Service层是业务逻辑的核心实现层,负责处理从Redis获取数据、分页计算和业务规则应用。以下是特价秒杀管理的服务实现:
@Slf4j
@Service
public class SpecialDealAdminService {@Autowiredprivate RedisTemplate<String, Object> redisTemplate;public PageResult<BookInfo> getSpecialBookListByPage(PageRequest pageRequest) {if (pageRequest == null) {return null;}// 获取Redis中所有特价图书List<BookInfo> allBooks = getAllBookInfoFromRedis();int total = allBooks.size();// 获取当前页数据List<BookInfo> currentPageBooks = getRequestPage(pageRequest, allBooks);// 状态码转换为中文描述for (BookInfo book : currentPageBooks) {book.setStatusCN(BookInfoStatusEnum.getNameByCode(book.getStatus()).getName());}// 封装分页结果return new PageResult<>(total, currentPageBooks, pageRequest);}private List<BookInfo> getRequestPage(PageRequest pageRequest, List<BookInfo> allBooks) {int offset = pageRequest.getOffset();int pageSize = pageRequest.getPageSize();int total = allBooks.size();// 计算实际获取的结束索引int endIndex = Math.min(offset + pageSize, total);return allBooks.subList(offset, endIndex);}private List<BookInfo> getAllBookInfoFromRedis() {List<BookInfo> resultList = new ArrayList<>();String keyPattern = "bookInfoId:*";Set<String> keys = redisTemplate.keys(keyPattern);for (String key : keys) {BookInfo bookInfo = (BookInfo) redisTemplate.opsForValue().get(key);resultList.add(bookInfo);}return resultList;}
}
核心业务逻辑解析:
-
Redis数据获取:
- 使用redisTemplate.keys(“bookInfoId:*”)获取所有以"bookInfoId:"开头的键,实现批量查询。
- 遍历键集合,逐个获取对应的值,转换为BookInfo对象。
-
分页计算:
- 根据pageRequest中的currentPage和pageSize计算偏移量offset=(currentPage-1)*pageSize。
- 使用subList方法从全量数据中提取当前页数据,避免一次性加载大量数据到内存。
- 处理边界情况:当请求的结束索引超过总数据量时,调整为总数据量,防止IndexOutOfBoundsException。
-
业务规则应用:
- 将数据库中的状态码(如3)转换为可读的中文描述(“特价秒杀”),通过BookInfoStatusEnum枚举类实现。
- 枚举类提供getNameByCode静态方法,根据状态码返回对应的状态名称,提高代码的可读性和可维护性。
性能优化点:
-
批量操作:
- 使用keys命令批量获取键,减少Redis交互次数,相比逐个查询效率更高。
- 虽然keys命令在数据量很大时可能影响Redis性能,但在本案例中数据量可控,且仅在分页查询时使用,影响有限。
-
内存优化:
- 使用subList进行分页,避免加载全量数据后再进行过滤,减少内存占用。
- 直接操作Redis中的数据,减少数据库查询次数,降低数据库压力。
-
状态转换优化:
- 使用枚举类进行状态码转换,相比if-else或switch语句更高效且易于维护。
- 枚举类在内存中是单例的,多次调用不会产生额外的对象创建开销。
5. Mapper层代码解析
Mapper层负责数据库交互,通过MyBatis实现SQL查询和结果映射。以下是Redis数据同步的Mapper接口:
@Mapper
public interface RedisMapper {@Select("select id,book_name,author,count,price,publish,status," +"create_time,update_time from book_info " +"where status =3 order by id asc ")List<BookInfo> getBookInfoList();
}
数据库查询逻辑解析:
-
SQL语句设计:
- 查询条件:where status=3,仅获取特价秒杀状态的图书信息,符合缓存场景的业务需求。
- 排序:order by id asc,确保查询结果有序,便于后续处理。
- 字段选择:只查询需要的字段,避免查询无用数据,减少网络传输和内存占用。
-
结果映射:
- MyBatis自动将查询结果映射为BookInfo对象,字段名与对象属性名通过驼峰命名法匹配(如book_name映射为bookName)。
- 对于Date类型字段(create_time, update_time),MyBatis会自动转换为Java中的Date对象,无需额外配置。
BookInfo模型类设计:
@Data
public class BookInfo {private Integer id;private String bookName;private String author;private Integer count;private BigDecimal price;private String publish;private Integer status;private String statusCN; // 非数据库字段,状态中文描述private Date createTime;private Date updateTime;// 时间字段设置方法public void setCreateTime() {ZonedDateTime zonedDateTime = LocalDateTime.now().atZone(ZoneId.systemDefault());createTime = Date.from(zonedDateTime.toInstant());}public void setUpdateTime() {ZonedDateTime zonedDateTime = LocalDateTime.now().atZone(ZoneId.systemDefault());updateTime = Date.from(zonedDateTime.toInstant());}
}
模型类设计要点:
- 非数据库字段:statusCN用于存储状态中文描述,不对应数据库字段,由业务逻辑层填充。
- 时间处理:提供setCreateTime和setUpdateTime方法,使用Java 8的日期时间API生成带时区的时间,确保时间一致性。
- JSON格式化:price字段使用@JsonFormat(shape = JsonFormat.Shape.STRING)注解,避免浮点数精度问题,前端显示更准确。
6. 前端代码解析
前端页面采用HTML+JavaScript+Bootstrap实现,主要负责数据展示和用户交互。以下是特价秒杀管理页面的核心代码:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><meta name="viewport" content="width=device-width, initial-scale=1.0"><title>特价秒杀管理</title><link rel="stylesheet" href="css/bootstrap.min.css"><link rel="stylesheet" href="css/list.css"><script type="text/javascript" src="js/jquery.min.js"></script><script type="text/javascript" src="js/bootstrap.min.js"></script><script src="js/jq-paginator.js"></script>
</head>
<body>
<div class="bookContainer"><h2>特价秒杀管理</h2><div class="navbar-justify-between"><div><button class="btn btn-outline-info" type="button" onclick="batchDelete()">批量删除</button><button class="btn btn-outline-info" type="button" onclick="location.href='special_admin_add.html'">添加图书</button></div></div><table><thead><tr><td>选择</td><td class="width100">图书ID</td><td>书名</td><td>作者</td><td>数量</td><td>定价</td><td>出版社</td><td>状态</td><td class="width200">操作</td></tr></thead><tbody></tbody></table><div class="demo"><ul id="pageContainer" class="pagination justify-content-center"></ul></div><script>getBookList();function getBookList() {$.ajax({url: "/special/getSpecialListByPage" + location.search,type: "get",success: function(result) {if (result.status == "FAIL") {location.href = "login.html";}if (result.status == "UNLOGIN") {location.href = "login.html";}var finalHtml = "";result = result.data;// 构建表格内容for (var book of result.bookInfoList) {finalHtml += '<tr>'finalHtml += '<td><input type="checkbox" name="selectBook" value="' + book.id + '" id="selectBook" class="book-select"></td>'finalHtml += '<td>' + book.id + '</td>'finalHtml += '<td>' + book.bookName + '</td>'finalHtml += '<td>' + book.author + '</td>'finalHtml += '<td>' + book.count + '</td>'finalHtml += '<td>' + book.price + '</td>'finalHtml += '<td>' + book.publish + '</td>'finalHtml += '<td>' + book.statusCN + '</td>'finalHtml += '<td><div class="op">'finalHtml += '<a href="special_admin_update.html?bookId=' + book.id + '">修改</a>'finalHtml += '<a href="javascript:void(0)" onclick="deleteBook(' + book.id + ')">删除</a>'finalHtml += '</div></td></tr>'}$("tbody").html(finalHtml);// 初始化分页$("#pageContainer").jqPaginator({totalCounts: result.total,pageSize: result.pageRequest.pageSize,visiblePages: 5,currentPage: result.pageRequest.currentPage,first: '<li class="page-item"><a class="page-link">首页</a></li>',prev: '<li class="page-item"><a class="page-link" href="javascript:void(0);">上一页</a></li>',next: '<li class="page-item"><a class="page-link" href="javascript:void(0);">下一页</a></li>',last: '<li class="page-item"><a class="page-link" href="javascript:void(0);">最后一页</a></li>',page: '<li class="page-item"><a class="page-link" href="javascript:void(0);">{{page}}</a></li>',onPageChange: function (page, type) {if (type == "change") {location.href = "book_list.html?currentPage=" + page;}}});}});}// 删除图书function deleteBook(id) {var isDelete = confirm("确认删除?");if (isDelete) {$.ajax({type: "post",url: "/special/updateBookInfo",data: {id: id, status: 0},success: function(result) {if (result == "") {alert("删除成功!");location.href = "book_list.html";} else {alert("删除失败:" + result);}},error: function(error) {alert("请求失败,请联系管理员");}});}}// 批量删除function batchDelete() {var isDelete = confirm("确认批量删除?");if (isDelete) {var ids = [];$("input:checkbox[name='selectBook']:checked").each(function () {ids.push($(this).val());});$.ajax({type: "post",url: "/special/batchDeleteBookInfoById?idList=" + ids,success: function(result) {if (result == "") {alert("批量删除成功!");location.href = "book_list.html";} else {alert("删除失败");}},error: function(error) {console.log("请求失败");}});}}</script>
</div>
</body>
</html>
前端交互逻辑解析:
-
页面初始化:
- 页面加载时自动调用getBookList()函数,通过AJAX请求获取特价图书列表。
- 使用location.search获取URL中的查询参数(如currentPage),实现分页状态的保持。
-
数据展示:
- 将后端返回的BookInfoList转换为HTML表格行,动态插入到tbody中。
- 展示字段包括:选择框、图书ID、书名、作者、数量、定价、出版社、状态和操作按钮。
- 状态字段直接展示后端填充的statusCN(中文描述),无需前端再次转换。
-
分页实现:
- 使用jqPaginator插件实现分页功能,配置总数据量、每页数据量、当前页码等参数。
- 分页切换时,通过location.href重新加载页面并传递currentPage参数,触发后端重新查询对应页数据。
-
删除操作:
- 单条删除:通过deleteBook函数发送POST请求,传递图书ID和status=0(逻辑删除)。
- 批量删除:收集选中的图书ID,拼接成idList参数发送请求,实现批量逻辑删除。
前后端交互协议:
-
请求格式:
- GET请求:用于查询数据,如分页查询。
- POST请求:用于修改数据,如删除图书。
-
参数传递:
- 查询参数:通过URL查询字符串传递(如?currentPage=2)。
- 表单数据:通过请求体传递(如删除操作的id和status)。
-
响应处理:
- 成功响应:解析data字段,获取分页结果并展示。
- 错误响应:根据status字段判断错误类型,重定向到登录页或显示错误提示。

7. 总结
7.1 技术亮点总结
-
Redis缓存策略:
- 采用初始化加载策略,确保系统启动时完成缓存预热,避免首次访问时的缓存穿透问题。
- 合理使用JSON序列化,兼顾存储效率和可读性,相比默认序列化更优。
-
分页查询优化:
- 前端分页与后端分页结合,后端负责数据获取和粗分页,前端通过插件实现友好的分页展示。
- 使用subList进行内存分页,避免大量数据传输和内存占用。
-
代码结构设计:
- 严格遵循MVC架构,各层职责分明,降低耦合度。
- 统一的响应格式和异常处理机制,提升系统的可维护性和稳定性。
7.2 可优化方向
-
Redis性能优化:
- 目前使用单个键值对存储每条图书信息,可考虑使用Redis的Hash结构存储,减少键数量。
- 批量操作优化:使用pipeline或Lua脚本减少Redis交互次数,提升批量查询性能。
-
缓存更新策略:
- 目前仅在初始化时加载数据,未实现缓存过期和更新机制,可添加定时任务或数据库变更监听,实现缓存的自动更新。
- 考虑使用Redis的过期时间特性,设置合理的缓存过期时间,避免长时间使用过期数据。
-
并发处理:
- 未处理高并发场景下的缓存一致性问题,可考虑使用分布式锁或乐观锁机制。
- 对于秒杀场景,可进一步优化Redis操作,如使用Lua脚本实现原子性操作。
-
前端体验优化:
- 分页切换时整页刷新,可优化为局部刷新,提升用户体验。
- 添加加载动画和错误提示,增强用户交互反馈。
7.3 项目拓展思考
-
分布式部署:
- 在分布式环境中,需考虑Redis的集群部署(如哨兵模式或集群模式),确保高可用性。
- 初始化数据加载需避免多节点重复加载,可使用分布式锁实现单节点执行。
-
数据安全:
- 生产环境中需添加Redis访问认证和数据加密,防止数据泄露。
- 对敏感数据(如价格)可考虑在前端展示时进行脱敏处理。
-
监控与告警:
- 添加Redis性能监控(如内存使用、QPS等),设置阈值告警机制。
- 记录关键操作日志,便于问题追溯和性能分析。
通过本项目的实践,我们深入了解了Redis在实际项目中的应用场景和实现方式。从初始化数据加载到分页查询优化,从前后端交互到业务逻辑处理,每一个环节都体现了Redis在提升系统性能方面的优势。同时,我们也认识到缓存技术在带来性能提升的同时,也引入了数据一致性、并发处理等新的挑战,需要在实际应用中不断优化和完善。