Learning Transferable Visual Models From Natural Language Supervision
目录
摘要
Abstract
CLIP
模型框架
图像编码器
文本编码器
对比学习目标函数
框架创新
实验
训练策略
代码
总结
摘要
CLIP是由OpenAI于2021年提出的一种多模态模型,通过自然语言监督信号学习可迁移的视觉表征。其核心改进源于对传统视觉模型依赖固定类别标签的局限性反思,转而采用对比学习框架,将图像与文本嵌入同一语义空间。CLIP基于超大规模数据集训练,解决了传统模型泛化能力差、需大量标注数据的问题。在30余个视觉任务上实现了零样本迁移,性能媲美甚至超越监督学习模型,如ImageNet上零样本准确率与ResNet-50相当。其创新性在于将自然语言作为监督信号,为多模态理解和生成任务奠定了基础。
Abstract
CLIP is a multimodal model proposed by OpenAI in 2021, which learns transferable visual representations through natural language supervision signals. Its core improvement stems from a reflection on the limitations of traditional visual models that rely on fixed category labels, and instead adopts a contrastive learning framework to embed images and text in the same semantic space. Trained on a massive dataset, CLIP addresses the issues of poor generalization ability and the need for large amounts of labeled data in traditional models. It achieves zero-shot transfer on more than 30 visual tasks, with performance comparable to or even surpassing supervised learning models, such as achieving zero-shot accuracy on ImageNet that is comparable to ResNet-50. Its innovation lies in using natural language as a supervision signal, laying the foundation for multimodal understanding and generation tasks.
CLIP
传统计算机视觉模型依赖固定类别标签,需大量标注数据且泛化能力受限。例如:模型无法区分“橘猫”与“奶牛猫”等细粒度类别,也无法适应新任务而不重新标注数据。此外,现有方法如VirTex尝试从文本生成图像标题,但训练效率低下,难以扩展。
CLIP的提出旨在通过自然语言监督信号,利用互联网海量图文对数据,构建灵活、可迁移的视觉模型。
项目地址:https://github.com/OpenAI/CLIP
模型框架
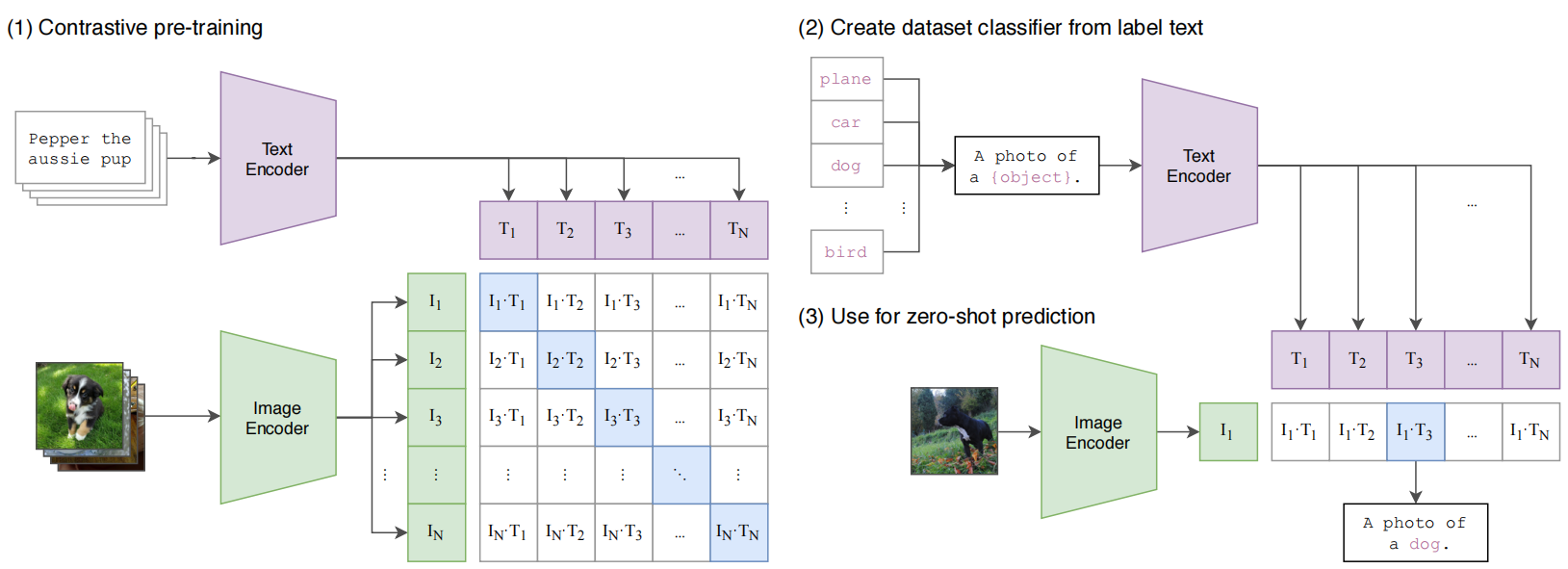
图像编码器
Vision Transformer:将图像分割为固定大小的Patch序列,通过Transformer处理全局上下文:
- ViT-B/32:基础版,Patch大小为32x32。
- ViT-B/16、ViT-L/14:更高分辨率(如ViT-L/14使用14x14的Patch),显著提升细节捕捉能力,最终模型采用ViT-L/14。
图像预处理:
- 输入分辨率:默认224x224;
- 标准化:RGB通道均值与标准差归一化;
- 数据增强:仅使用随机裁剪和水平翻转,避免过度复杂增强策略。
文本编码器
架构:基于Transformer的编码器,但仅保留编码部分。
输入处理:
- 文本序列化:使用字节级BPE分词,最大长度限制为77个token;
- Prompt模板:将类别标签(如“dog”)扩展为句子(如“A photo of a dog”),增强语义表达。
结构细节:
- 层数:12层Transformer
- 隐藏层维度:512
- 多头注意力头数:8
- 位置编码:可学习的绝对位置编码
对比学习目标函数
CLIP的核心训练目标是通过对比损失对齐图像和文本的嵌入向量:
批处理:
- 每个训练批次包含N个图像-文本对。
- 图像编码器输出N个图像特征向量:
;
- 文本编码器输出N个文本特征向量:
;
- 所有特征向量经过L2归一化,确保相似度计算基于余弦距离。
相似度矩阵计算:
- 计算图像与文本的余弦相似度矩阵
,其中
;
- 正样本:对角线元素
表示匹配的图文对;
- 负样本:非对角线元素
)表示不匹配的图文对。
对称交叉熵损失:
- 图像到文本损失:对每张图像,计算其与所有文本的Softmax概率,并取对角线元素的负对数似然:
- 文本到图像损失:类似地,对每个文本计算损失:
- 总损失:两者平均,
,其中
为可学习参数。
框架创新
模态对齐的统一空间:
- 图像和文本嵌入共享维度(如ViT-L/14输出768维向量),使跨模态检索(如图搜文、文搜图)成为可能。
零样本迁移能力:
- 分类任务中,将类别标签扩展为Prompt(如“A photo of a {label}”),通过计算图像特征与所有文本Prompt特征的相似度实现预测,无需微调。
灵活性:
- 支持多种图像编码器(ResNet/ViT),可根据任务需求平衡速度与精度。
实验
训练策略
超大规模数据集:
- WebImageText:包含4亿公开可用的互联网图文对,覆盖广泛的视觉概念和语言描述。
高效训练优化:
- 混合精度训练:使用FP16精度加速计算,结合梯度缩放避免数值下溢;
- 大批次训练:单批次高达32 768个样本,提升对比学习中的负样本数量;
- 梯度缓存:在GPU内存不足时,分片存储中间梯度,支持更大模型训练。
模型缩放规律:
- 实验发现:模型性能随计算量(数据量、模型大小、训练时长)呈幂律增长,因此优先扩展模型规模。
代码
CLIP.py
import hashlib
import os
import urllib
import warnings
from packaging import version
from typing import Union, Listimport torch
from PIL import Image
from torchvision.transforms import Compose, Resize, CenterCrop, ToTensor, Normalize
from tqdm import tqdmfrom .model import build_model
from .simple_tokenizer import SimpleTokenizer as _Tokenizertry:from torchvision.transforms import InterpolationModeBICUBIC = InterpolationMode.BICUBIC
except ImportError:BICUBIC = Image.BICUBICif version.parse(torch.__version__) < version.parse("1.7.1"):warnings.warn("PyTorch version 1.7.1 or higher is recommended")__all__ = ["available_models", "load", "tokenize"]
_tokenizer = _Tokenizer()_MODELS = {"RN50": "https://openaipublic.azureedge.net/clip/models/afeb0e10f9e5a86da6080e35cf09123aca3b358a0c3e3b6c78a7b63bc04b6762/RN50.pt","RN101": "https://openaipublic.azureedge.net/clip/models/8fa8567bab74a42d41c5915025a8e4538c3bdbe8804a470a72f30b0d94fab599/RN101.pt","RN50x4": "https://openaipublic.azureedge.net/clip/models/7e526bd135e493cef0776de27d5f42653e6b4c8bf9e0f653bb11773263205fdd/RN50x4.pt","RN50x16": "https://openaipublic.azureedge.net/clip/models/52378b407f34354e150460fe41077663dd5b39c54cd0bfd2b27167a4a06ec9aa/RN50x16.pt","RN50x64": "https://openaipublic.azureedge.net/clip/models/be1cfb55d75a9666199fb2206c106743da0f6468c9d327f3e0d0a543a9919d9c/RN50x64.pt","ViT-B/32": "https://openaipublic.azureedge.net/clip/models/40d365715913c9da98579312b702a82c18be219cc2a73407c4526f58eba950af/ViT-B-32.pt","ViT-B/16": "https://openaipublic.azureedge.net/clip/models/5806e77cd80f8b59890b7e101eabd078d9fb84e6937f9e85e4ecb61988df416f/ViT-B-16.pt","ViT-L/14": "https://openaipublic.azureedge.net/clip/models/b8cca3fd41ae0c99ba7e8951adf17d267cdb84cd88be6f7c2e0eca1737a03836/ViT-L-14.pt","ViT-L/14@336px": "https://openaipublic.azureedge.net/clip/models/3035c92b350959924f9f00213499208652fc7ea050643e8b385c2dac08641f02/ViT-L-14-336px.pt",
}def _download(url: str, root: str):os.makedirs(root, exist_ok=True)filename = os.path.basename(url)expected_sha256 = url.split("/")[-2]download_target = os.path.join(root, filename)if os.path.exists(download_target) and not os.path.isfile(download_target):raise RuntimeError(f"{download_target} exists and is not a regular file")if os.path.isfile(download_target):if hashlib.sha256(open(download_target, "rb").read()).hexdigest() == expected_sha256:return download_targetelse:warnings.warn(f"{download_target} exists, but the SHA256 checksum does not match; re-downloading the file")with urllib.request.urlopen(url) as source, open(download_target, "wb") as output:with tqdm(total=int(source.info().get("Content-Length")), ncols=80, unit='iB', unit_scale=True, unit_divisor=1024) as loop:while True:buffer = source.read(8192)if not buffer:breakoutput.write(buffer)loop.update(len(buffer))if hashlib.sha256(open(download_target, "rb").read()).hexdigest() != expected_sha256:raise RuntimeError("Model has been downloaded but the SHA256 checksum does not not match")return download_targetdef _convert_image_to_rgb(image):return image.convert("RGB")def _transform(n_px):return Compose([Resize(n_px, interpolation=BICUBIC),CenterCrop(n_px),_convert_image_to_rgb,ToTensor(),Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)),])def available_models() -> List[str]:"""Returns the names of available CLIP models"""return list(_MODELS.keys())def load(name: str, device: Union[str, torch.device] = "cuda" if torch.cuda.is_available() else "cpu", jit: bool = False, download_root: str = None):"""Load a CLIP modelParameters----------name : strA model name listed by `clip.available_models()`, or the path to a model checkpoint containing the state_dictdevice : Union[str, torch.device]The device to put the loaded modeljit : boolWhether to load the optimized JIT model or more hackable non-JIT model (default).download_root: strpath to download the model files; by default, it uses "~/.cache/clip"Returns-------model : torch.nn.ModuleThe CLIP modelpreprocess : Callable[[PIL.Image], torch.Tensor]A torchvision transform that converts a PIL image into a tensor that the returned model can take as its input"""if name in _MODELS:model_path = _download(_MODELS[name], download_root or os.path.expanduser("~/.cache/clip"))elif os.path.isfile(name):model_path = nameelse:raise RuntimeError(f"Model {name} not found; available models = {available_models()}")with open(model_path, 'rb') as opened_file:try:# loading JIT archivemodel = torch.jit.load(opened_file, map_location=device if jit else "cpu").eval()state_dict = Noneexcept RuntimeError:# loading saved state dictif jit:warnings.warn(f"File {model_path} is not a JIT archive. Loading as a state dict instead")jit = Falsestate_dict = torch.load(opened_file, map_location="cpu")if not jit:model = build_model(state_dict or model.state_dict()).to(device)if str(device) == "cpu":model.float()return model, _transform(model.visual.input_resolution)# patch the device namesdevice_holder = torch.jit.trace(lambda: torch.ones([]).to(torch.device(device)), example_inputs=[])device_node = [n for n in device_holder.graph.findAllNodes("prim::Constant") if "Device" in repr(n)][-1]def _node_get(node: torch._C.Node, key: str):"""Gets attributes of a node which is polymorphic over return type.From https://github.com/pytorch/pytorch/pull/82628"""sel = node.kindOf(key)return getattr(node, sel)(key)def patch_device(module):try:graphs = [module.graph] if hasattr(module, "graph") else []except RuntimeError:graphs = []if hasattr(module, "forward1"):graphs.append(module.forward1.graph)for graph in graphs:for node in graph.findAllNodes("prim::Constant"):if "value" in node.attributeNames() and str(_node_get(node, "value")).startswith("cuda"):node.copyAttributes(device_node)model.apply(patch_device)patch_device(model.encode_image)patch_device(model.encode_text)# patch dtype to float32 on CPUif str(device) == "cpu":float_holder = torch.jit.trace(lambda: torch.ones([]).float(), example_inputs=[])float_input = list(float_holder.graph.findNode("aten::to").inputs())[1]float_node = float_input.node()def patch_float(module):try:graphs = [module.graph] if hasattr(module, "graph") else []except RuntimeError:graphs = []if hasattr(module, "forward1"):graphs.append(module.forward1.graph)for graph in graphs:for node in graph.findAllNodes("aten::to"):inputs = list(node.inputs())for i in [1, 2]: # dtype can be the second or third argument to aten::to()if _node_get(inputs[i].node(), "value") == 5:inputs[i].node().copyAttributes(float_node)model.apply(patch_float)patch_float(model.encode_image)patch_float(model.encode_text)model.float()return model, _transform(model.input_resolution.item())def tokenize(texts: Union[str, List[str]], context_length: int = 77, truncate: bool = False) -> Union[torch.IntTensor, torch.LongTensor]:"""Returns the tokenized representation of given input string(s)Parameters----------texts : Union[str, List[str]]An input string or a list of input strings to tokenizecontext_length : intThe context length to use; all CLIP models use 77 as the context lengthtruncate: boolWhether to truncate the text in case its encoding is longer than the context lengthReturns-------A two-dimensional tensor containing the resulting tokens, shape = [number of input strings, context_length].We return LongTensor when torch version is <1.8.0, since older index_select requires indices to be long."""if isinstance(texts, str):texts = [texts]sot_token = _tokenizer.encoder["<|startoftext|>"]eot_token = _tokenizer.encoder["<|endoftext|>"]all_tokens = [[sot_token] + _tokenizer.encode(text) + [eot_token] for text in texts]if version.parse(torch.__version__) < version.parse("1.8.0"):result = torch.zeros(len(all_tokens), context_length, dtype=torch.long)else:result = torch.zeros(len(all_tokens), context_length, dtype=torch.int)for i, tokens in enumerate(all_tokens):if len(tokens) > context_length:if truncate:tokens = tokens[:context_length]tokens[-1] = eot_tokenelse:raise RuntimeError(f"Input {texts[i]} is too long for context length {context_length}")result[i, :len(tokens)] = torch.tensor(tokens)return resultmodel.py
from collections import OrderedDict
from typing import Tuple, Unionimport numpy as np
import torch
import torch.nn.functional as F
from torch import nnclass Bottleneck(nn.Module):expansion = 4def __init__(self, inplanes, planes, stride=1):super().__init__()# all conv layers have stride 1. an avgpool is performed after the second convolution when stride > 1self.conv1 = nn.Conv2d(inplanes, planes, 1, bias=False)self.bn1 = nn.BatchNorm2d(planes)self.relu1 = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(planes, planes, 3, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(planes)self.relu2 = nn.ReLU(inplace=True)self.avgpool = nn.AvgPool2d(stride) if stride > 1 else nn.Identity()self.conv3 = nn.Conv2d(planes, planes * self.expansion, 1, bias=False)self.bn3 = nn.BatchNorm2d(planes * self.expansion)self.relu3 = nn.ReLU(inplace=True)self.downsample = Noneself.stride = strideif stride > 1 or inplanes != planes * Bottleneck.expansion:# downsampling layer is prepended with an avgpool, and the subsequent convolution has stride 1self.downsample = nn.Sequential(OrderedDict([("-1", nn.AvgPool2d(stride)),("0", nn.Conv2d(inplanes, planes * self.expansion, 1, stride=1, bias=False)),("1", nn.BatchNorm2d(planes * self.expansion))]))def forward(self, x: torch.Tensor):identity = xout = self.relu1(self.bn1(self.conv1(x)))out = self.relu2(self.bn2(self.conv2(out)))out = self.avgpool(out)out = self.bn3(self.conv3(out))if self.downsample is not None:identity = self.downsample(x)out += identityout = self.relu3(out)return outclass AttentionPool2d(nn.Module):def __init__(self, spacial_dim: int, embed_dim: int, num_heads: int, output_dim: int = None):super().__init__()self.positional_embedding = nn.Parameter(torch.randn(spacial_dim ** 2 + 1, embed_dim) / embed_dim ** 0.5)self.k_proj = nn.Linear(embed_dim, embed_dim)self.q_proj = nn.Linear(embed_dim, embed_dim)self.v_proj = nn.Linear(embed_dim, embed_dim)self.c_proj = nn.Linear(embed_dim, output_dim or embed_dim)self.num_heads = num_headsdef forward(self, x):x = x.flatten(start_dim=2).permute(2, 0, 1) # NCHW -> (HW)NCx = torch.cat([x.mean(dim=0, keepdim=True), x], dim=0) # (HW+1)NCx = x + self.positional_embedding[:, None, :].to(x.dtype) # (HW+1)NCx, _ = F.multi_head_attention_forward(query=x[:1], key=x, value=x,embed_dim_to_check=x.shape[-1],num_heads=self.num_heads,q_proj_weight=self.q_proj.weight,k_proj_weight=self.k_proj.weight,v_proj_weight=self.v_proj.weight,in_proj_weight=None,in_proj_bias=torch.cat([self.q_proj.bias, self.k_proj.bias, self.v_proj.bias]),bias_k=None,bias_v=None,add_zero_attn=False,dropout_p=0,out_proj_weight=self.c_proj.weight,out_proj_bias=self.c_proj.bias,use_separate_proj_weight=True,training=self.training,need_weights=False)return x.squeeze(0)class ModifiedResNet(nn.Module):"""A ResNet class that is similar to torchvision's but contains the following changes:- There are now 3 "stem" convolutions as opposed to 1, with an average pool instead of a max pool.- Performs anti-aliasing strided convolutions, where an avgpool is prepended to convolutions with stride > 1- The final pooling layer is a QKV attention instead of an average pool"""def __init__(self, layers, output_dim, heads, input_resolution=224, width=64):super().__init__()self.output_dim = output_dimself.input_resolution = input_resolution# the 3-layer stemself.conv1 = nn.Conv2d(3, width // 2, kernel_size=3, stride=2, padding=1, bias=False)self.bn1 = nn.BatchNorm2d(width // 2)self.relu1 = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(width // 2, width // 2, kernel_size=3, padding=1, bias=False)self.bn2 = nn.BatchNorm2d(width // 2)self.relu2 = nn.ReLU(inplace=True)self.conv3 = nn.Conv2d(width // 2, width, kernel_size=3, padding=1, bias=False)self.bn3 = nn.BatchNorm2d(width)self.relu3 = nn.ReLU(inplace=True)self.avgpool = nn.AvgPool2d(2)# residual layersself._inplanes = width # this is a *mutable* variable used during constructionself.layer1 = self._make_layer(width, layers[0])self.layer2 = self._make_layer(width * 2, layers[1], stride=2)self.layer3 = self._make_layer(width * 4, layers[2], stride=2)self.layer4 = self._make_layer(width * 8, layers[3], stride=2)embed_dim = width * 32 # the ResNet feature dimensionself.attnpool = AttentionPool2d(input_resolution // 32, embed_dim, heads, output_dim)def _make_layer(self, planes, blocks, stride=1):layers = [Bottleneck(self._inplanes, planes, stride)]self._inplanes = planes * Bottleneck.expansionfor _ in range(1, blocks):layers.append(Bottleneck(self._inplanes, planes))return nn.Sequential(*layers)def forward(self, x):def stem(x):x = self.relu1(self.bn1(self.conv1(x)))x = self.relu2(self.bn2(self.conv2(x)))x = self.relu3(self.bn3(self.conv3(x)))x = self.avgpool(x)return xx = x.type(self.conv1.weight.dtype)x = stem(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.layer4(x)x = self.attnpool(x)return xclass LayerNorm(nn.LayerNorm):"""Subclass torch's LayerNorm to handle fp16."""def forward(self, x: torch.Tensor):orig_type = x.dtyperet = super().forward(x.type(torch.float32))return ret.type(orig_type)class QuickGELU(nn.Module):def forward(self, x: torch.Tensor):return x * torch.sigmoid(1.702 * x)class ResidualAttentionBlock(nn.Module):def __init__(self, d_model: int, n_head: int, attn_mask: torch.Tensor = None):super().__init__()self.attn = nn.MultiheadAttention(d_model, n_head)self.ln_1 = LayerNorm(d_model)self.mlp = nn.Sequential(OrderedDict([("c_fc", nn.Linear(d_model, d_model * 4)),("gelu", QuickGELU()),("c_proj", nn.Linear(d_model * 4, d_model))]))self.ln_2 = LayerNorm(d_model)self.attn_mask = attn_maskdef attention(self, x: torch.Tensor):self.attn_mask = self.attn_mask.to(dtype=x.dtype, device=x.device) if self.attn_mask is not None else Nonereturn self.attn(x, x, x, need_weights=False, attn_mask=self.attn_mask)[0]def forward(self, x: torch.Tensor):x = x + self.attention(self.ln_1(x))x = x + self.mlp(self.ln_2(x))return xclass Transformer(nn.Module):def __init__(self, width: int, layers: int, heads: int, attn_mask: torch.Tensor = None):super().__init__()self.width = widthself.layers = layersself.resblocks = nn.Sequential(*[ResidualAttentionBlock(width, heads, attn_mask) for _ in range(layers)])def forward(self, x: torch.Tensor):return self.resblocks(x)class VisionTransformer(nn.Module):def __init__(self, input_resolution: int, patch_size: int, width: int, layers: int, heads: int, output_dim: int):super().__init__()self.input_resolution = input_resolutionself.output_dim = output_dimself.conv1 = nn.Conv2d(in_channels=3, out_channels=width, kernel_size=patch_size, stride=patch_size, bias=False)scale = width ** -0.5self.class_embedding = nn.Parameter(scale * torch.randn(width))self.positional_embedding = nn.Parameter(scale * torch.randn((input_resolution // patch_size) ** 2 + 1, width))self.ln_pre = LayerNorm(width)self.transformer = Transformer(width, layers, heads)self.ln_post = LayerNorm(width)self.proj = nn.Parameter(scale * torch.randn(width, output_dim))def forward(self, x: torch.Tensor):x = self.conv1(x) # shape = [*, width, grid, grid]x = x.reshape(x.shape[0], x.shape[1], -1) # shape = [*, width, grid ** 2]x = x.permute(0, 2, 1) # shape = [*, grid ** 2, width]x = torch.cat([self.class_embedding.to(x.dtype) + torch.zeros(x.shape[0], 1, x.shape[-1], dtype=x.dtype, device=x.device), x], dim=1) # shape = [*, grid ** 2 + 1, width]x = x + self.positional_embedding.to(x.dtype)x = self.ln_pre(x)x = x.permute(1, 0, 2) # NLD -> LNDx = self.transformer(x)x = x.permute(1, 0, 2) # LND -> NLDx = self.ln_post(x[:, 0, :])if self.proj is not None:x = x @ self.projreturn xclass CLIP(nn.Module):def __init__(self,embed_dim: int,# visionimage_resolution: int,vision_layers: Union[Tuple[int, int, int, int], int],vision_width: int,vision_patch_size: int,# textcontext_length: int,vocab_size: int,transformer_width: int,transformer_heads: int,transformer_layers: int):super().__init__()self.context_length = context_lengthif isinstance(vision_layers, (tuple, list)):vision_heads = vision_width * 32 // 64self.visual = ModifiedResNet(layers=vision_layers,output_dim=embed_dim,heads=vision_heads,input_resolution=image_resolution,width=vision_width)else:vision_heads = vision_width // 64self.visual = VisionTransformer(input_resolution=image_resolution,patch_size=vision_patch_size,width=vision_width,layers=vision_layers,heads=vision_heads,output_dim=embed_dim)self.transformer = Transformer(width=transformer_width,layers=transformer_layers,heads=transformer_heads,attn_mask=self.build_attention_mask())self.vocab_size = vocab_sizeself.token_embedding = nn.Embedding(vocab_size, transformer_width)self.positional_embedding = nn.Parameter(torch.empty(self.context_length, transformer_width))self.ln_final = LayerNorm(transformer_width)self.text_projection = nn.Parameter(torch.empty(transformer_width, embed_dim))self.logit_scale = nn.Parameter(torch.ones([]) * np.log(1 / 0.07))self.initialize_parameters()def initialize_parameters(self):nn.init.normal_(self.token_embedding.weight, std=0.02)nn.init.normal_(self.positional_embedding, std=0.01)if isinstance(self.visual, ModifiedResNet):if self.visual.attnpool is not None:std = self.visual.attnpool.c_proj.in_features ** -0.5nn.init.normal_(self.visual.attnpool.q_proj.weight, std=std)nn.init.normal_(self.visual.attnpool.k_proj.weight, std=std)nn.init.normal_(self.visual.attnpool.v_proj.weight, std=std)nn.init.normal_(self.visual.attnpool.c_proj.weight, std=std)for resnet_block in [self.visual.layer1, self.visual.layer2, self.visual.layer3, self.visual.layer4]:for name, param in resnet_block.named_parameters():if name.endswith("bn3.weight"):nn.init.zeros_(param)proj_std = (self.transformer.width ** -0.5) * ((2 * self.transformer.layers) ** -0.5)attn_std = self.transformer.width ** -0.5fc_std = (2 * self.transformer.width) ** -0.5for block in self.transformer.resblocks:nn.init.normal_(block.attn.in_proj_weight, std=attn_std)nn.init.normal_(block.attn.out_proj.weight, std=proj_std)nn.init.normal_(block.mlp.c_fc.weight, std=fc_std)nn.init.normal_(block.mlp.c_proj.weight, std=proj_std)if self.text_projection is not None:nn.init.normal_(self.text_projection, std=self.transformer.width ** -0.5)def build_attention_mask(self):# lazily create causal attention mask, with full attention between the vision tokens# pytorch uses additive attention mask; fill with -infmask = torch.empty(self.context_length, self.context_length)mask.fill_(float("-inf"))mask.triu_(1) # zero out the lower diagonalreturn mask@propertydef dtype(self):return self.visual.conv1.weight.dtypedef encode_image(self, image):return self.visual(image.type(self.dtype))def encode_text(self, text):x = self.token_embedding(text).type(self.dtype) # [batch_size, n_ctx, d_model]x = x + self.positional_embedding.type(self.dtype)x = x.permute(1, 0, 2) # NLD -> LNDx = self.transformer(x)x = x.permute(1, 0, 2) # LND -> NLDx = self.ln_final(x).type(self.dtype)# x.shape = [batch_size, n_ctx, transformer.width]# take features from the eot embedding (eot_token is the highest number in each sequence)x = x[torch.arange(x.shape[0]), text.argmax(dim=-1)] @ self.text_projectionreturn xdef forward(self, image, text):image_features = self.encode_image(image)text_features = self.encode_text(text)# normalized featuresimage_features = image_features / image_features.norm(dim=1, keepdim=True)text_features = text_features / text_features.norm(dim=1, keepdim=True)# cosine similarity as logitslogit_scale = self.logit_scale.exp()logits_per_image = logit_scale * image_features @ text_features.t()logits_per_text = logits_per_image.t()# shape = [global_batch_size, global_batch_size]return logits_per_image, logits_per_textdef convert_weights(model: nn.Module):"""Convert applicable model parameters to fp16"""def _convert_weights_to_fp16(l):if isinstance(l, (nn.Conv1d, nn.Conv2d, nn.Linear)):l.weight.data = l.weight.data.half()if l.bias is not None:l.bias.data = l.bias.data.half()if isinstance(l, nn.MultiheadAttention):for attr in [*[f"{s}_proj_weight" for s in ["in", "q", "k", "v"]], "in_proj_bias", "bias_k", "bias_v"]:tensor = getattr(l, attr)if tensor is not None:tensor.data = tensor.data.half()for name in ["text_projection", "proj"]:if hasattr(l, name):attr = getattr(l, name)if attr is not None:attr.data = attr.data.half()model.apply(_convert_weights_to_fp16)def build_model(state_dict: dict):vit = "visual.proj" in state_dictif vit:vision_width = state_dict["visual.conv1.weight"].shape[0]vision_layers = len([k for k in state_dict.keys() if k.startswith("visual.") and k.endswith(".attn.in_proj_weight")])vision_patch_size = state_dict["visual.conv1.weight"].shape[-1]grid_size = round((state_dict["visual.positional_embedding"].shape[0] - 1) ** 0.5)image_resolution = vision_patch_size * grid_sizeelse:counts: list = [len(set(k.split(".")[2] for k in state_dict if k.startswith(f"visual.layer{b}"))) for b in [1, 2, 3, 4]]vision_layers = tuple(counts)vision_width = state_dict["visual.layer1.0.conv1.weight"].shape[0]output_width = round((state_dict["visual.attnpool.positional_embedding"].shape[0] - 1) ** 0.5)vision_patch_size = Noneassert output_width ** 2 + 1 == state_dict["visual.attnpool.positional_embedding"].shape[0]image_resolution = output_width * 32embed_dim = state_dict["text_projection"].shape[1]context_length = state_dict["positional_embedding"].shape[0]vocab_size = state_dict["token_embedding.weight"].shape[0]transformer_width = state_dict["ln_final.weight"].shape[0]transformer_heads = transformer_width // 64transformer_layers = len(set(k.split(".")[2] for k in state_dict if k.startswith("transformer.resblocks")))model = CLIP(embed_dim,image_resolution, vision_layers, vision_width, vision_patch_size,context_length, vocab_size, transformer_width, transformer_heads, transformer_layers)for key in ["input_resolution", "context_length", "vocab_size"]:if key in state_dict:del state_dict[key]convert_weights(model)model.load_state_dict(state_dict)return model.eval()
总结
CLIP通过自然语言监督与对比学习,革新了视觉表征学习范式,实现了“以文搜图、以图搜文”的跨模态理解,成为多模态领域的里程碑。其核心价值在于证明从开放语义中学习视觉概念的可行性,为零样本推理、少样本学习提供了新思路。尽管存在成本与细粒度局限,但其开创性框架持续推动AI向更通用、更人类化的多模态智能演进。