Kubernetes 核心原理详解
Kubernetes(简称 K8s)是一个开源的容器编排平台,用于自动化部署、扩展和管理容器化应用。其核心设计理念是通过声明式配置和自动化控制,确保系统始终处于用户期望的状态。以下从架构、组件协作、核心机制三方面详细解析其原理。
一、架构概览:控制平面与工作节点
Kubernetes 集群由 控制平面(Control Plane) 和 工作节点(Worker Nodes) 组成,两者协同完成容器化应用的管理。
1. 控制平面(大脑)
控制平面是集群的“指挥中心”,包含四大核心组件:
-
API Server:集群的“前台接待”,所有操作(如创建 Pod、查询状态)都通过它处理,并验证请求合法性。
-
etcd:分布式键值数据库,存储集群所有配置和状态数据,相当于集群的“记忆库”。
-
Scheduler:“调度员”,负责为新创建的 Pod 选择合适的工作节点,依据资源需求、亲和性规则等决策。
-
Controller Manager:“运维管家”,运行多种控制器(如 Deployment Controller、Node Controller),持续监控集群状态并确保其符合用户预期。
2. 工作节点(四肢)
工作节点是运行容器的“劳动力”,包含三个关键组件:
-
Kubelet:节点上的“监工”,与管理平面通信,确保节点上的 Pod 按预期运行。
-
Kube-Proxy:“网络管理员”,维护节点上的网络规则(如 iptables/IPVS),实现 Service 的负载均衡。
-
容器运行时:如 Docker 或 containerd,负责拉取镜像、启停容器等底层操作。
二、核心工作机制
1. Pod 生命周期管理:从创建到运行
示例:用户提交一个 Deployment
-
提交请求:用户通过
kubectl apply提交一个 Deployment 的 YAML 文件。 -
API Server 处理:API Server 接收请求,验证权限后写入 etcd。
-
Controller 响应:Deployment Controller 监听到新对象,创建对应的 ReplicaSet;ReplicaSet Controller 确保指定数量的 Pod 副本存在。
-
调度 Pod:Scheduler 发现未调度的 Pod,根据节点资源、标签等选择合适节点,更新 Pod 信息至 etcd。
-
节点执行:目标节点的 Kubelet 监听到新 Pod,调用容器运行时启动容器,并持续汇报状态给 API Server。
-
健康检查:若 Pod 崩溃,Kubelet 自动重启;若节点故障,Controller Manager 在其他节点重建 Pod。
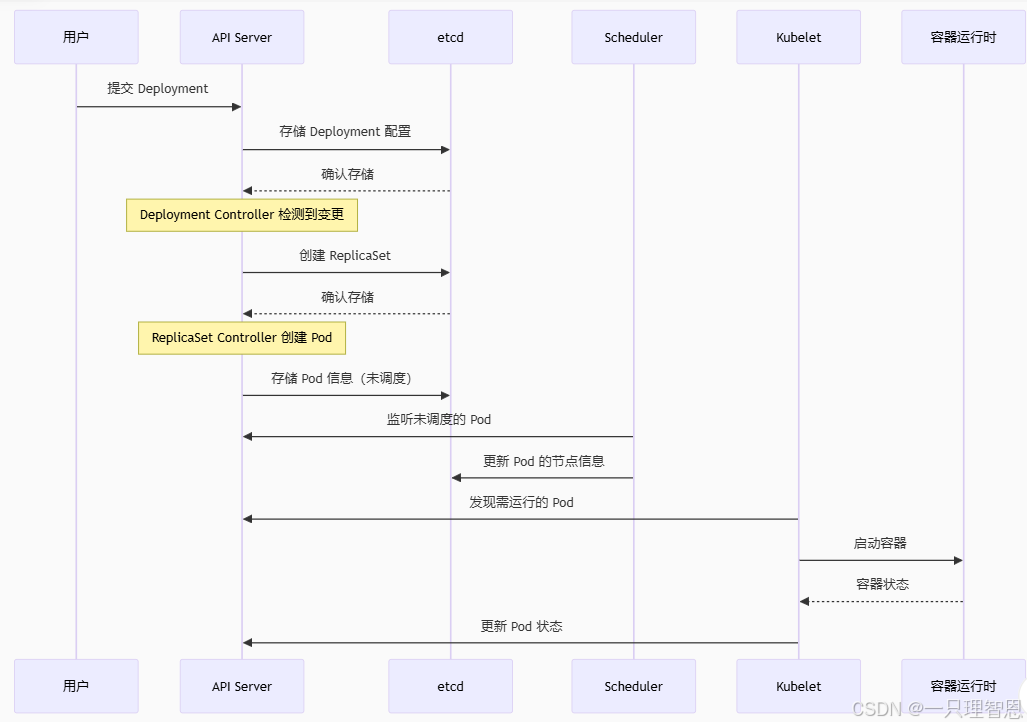
sequenceDiagramparticipant User as 用户participant API as API Serverparticipant etcd as etcdparticipant Scheduler as Schedulerparticipant Kubelet as Kubeletparticipant Container as 容器运行时User->>API: 提交 DeploymentAPI->>etcd: 存储 Deployment 配置etcd-->>API: 确认存储Note over API: Deployment Controller 检测到变更API->>etcd: 创建 ReplicaSetetcd-->>API: 确认存储Note over API: ReplicaSet Controller 创建 PodAPI->>etcd: 存储 Pod 信息(未调度)Scheduler->>API: 监听未调度的 PodScheduler->>etcd: 更新 Pod 的节点信息Kubelet->>API: 发现需运行的 PodKubelet->>Container: 启动容器Container-->>Kubelet: 容器状态Kubelet->>API: 更新 Pod 状态2. 服务发现与负载均衡:Service 的魔法
-
问题:Pod 是临时的,IP 地址会变化,如何稳定访问应用?
-
解决:通过 Service 抽象。
-
Service 分配固定虚拟 IP(ClusterIP),通过标签选择器关联一组 Pod。
-
Kube-Proxy 监听 Service 和 Pod 变化,动态更新节点的 iptables/IPVS 规则,将流量转发到后端 Pod。
-
示例:用户访问
nginx-service:80,请求被均匀分发到所有标签为app=nginx的 Pod。
-
apiVersion: v1
kind: Service
metadata:name: nginx-service
spec:selector:app: nginxports:- protocol: TCPport: 80targetPort: 80type: ClusterIP3. 自我修复:保持期望状态
Kubernetes 持续对比 实际状态(etcd 中记录)与 期望状态(用户提交的 YAML)。当偏差发生时,控制器自动修复:
-
Pod 故障:Deployment 确保副本数,重新调度。
-
节点宕机:Node Controller 标记节点不可用,在其他节点启动 Pod。
-
配置错误:若新 Pod 启动失败,RollingUpdate 策略自动回滚到旧版本。
三、网络与存储:连通与持久化
1. 网络模型:Pod 间如何通信?
-
每个 Pod 拥有唯一 IP:所有容器共享网络命名空间,可直接通过 localhost 通信。
-
CNI 插件:如 Calico、Flannel,负责为 Pod 分配 IP,并配置网络路由。
-
跨节点通信:通过 Overlay 网络(如 VXLAN)或主机路由实现。
2. 存储管理:数据持久化
-
PersistentVolume (PV):集群级别的存储资源(如云磁盘、NFS)。
-
PersistentVolumeClaim (PVC):用户对存储的请求,Kubernetes 动态绑定到合适的 PV。
-
示例:数据库 Pod 通过 PVC 申请存储,即使 Pod 重启,数据仍保留在 PV 中。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:name: mysql-pvc
spec:accessModes:- ReadWriteOnceresources:requests:storage: 10Gi四、扩展机制:定制你的 Kubernetes
1. 自定义资源定义(CRD)
允许用户定义新的资源类型,扩展 Kubernetes API。例如,定义 CronJob 来管理定时任务。
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:name: cronjobs.example.com
spec:group: example.comnames:kind: CronJobplural: cronjobsscope: Namespaced2. Operator 模式
通过自定义控制器管理有状态应用(如数据库)。Operator 监听 CRD 变化,执行复杂运维操作(如备份、升级)。
-
示例:Etcd Operator 自动处理节点扩容、故障恢复。
五、总结:Kubernetes 的核心思想
-
声明式配置:用户描述“想要什么”,而非“如何操作”。
-
自动化控制:通过控制器循环确保系统状态与声明一致。
-
松散耦合:组件通过 API Server 交互,可独立升级替换。
-
可扩展性:CRD、Operator 等机制支持任意复杂场景。
Kubernetes 通过以上机制,实现了高效、弹性的容器编排,成为云原生时代的核心基础设施。