【AI论文】KRIS-基准测试:评估下一代智能图像编辑模型的基准
摘要:多模态生成模型的最新进展使基于指令的图像编辑取得了重大进展。 然而,尽管这些模型在视觉上产生了看似合理的输出,但它们在基于知识的推理编辑任务方面的能力仍未得到充分开发。 在本文中,我们介绍了KRIS-Bench(图像编辑系统基准中的基于知识的推理),这是一个诊断基准,旨在通过认知信息透镜评估模型。 根据教育理论,KRIS-Bench将编辑任务分为三种基础知识类型:事实、概念和程序。 基于这种分类,我们设计了22个具有代表性的任务,涵盖7个推理维度,并发布了1267个高质量的带注释的编辑实例。 为了支持细粒度评估,我们提出了一种全面的协议,该协议包含一种新颖的知识合理性度量,通过知识提示进行增强,并通过人类研究进行校准。 10 个最先进的模型的实证结果表明,推理性能存在显著差距,突显出需要以知识为中心的基准来推动智能图像编辑系统的发展。Huggingface链接:Paper page,论文链接:2505.16707
研究背景和目的
研究背景
近年来,多模态生成模型在基于指令的图像编辑领域取得了显著进展。这些模型能够根据用户提供的文本指令生成视觉上连贯且语义一致的编辑结果,如对象操作、风格转换和动作模拟等。然而,尽管这些模型在视觉效果上有所提升,但它们在基于知识的推理编辑任务方面的能力仍然不足。具体来说,现有的图像编辑模型在执行需要深入理解和应用科学、文化、常识等知识的复杂编辑任务时,往往表现出局限性。
研究目的
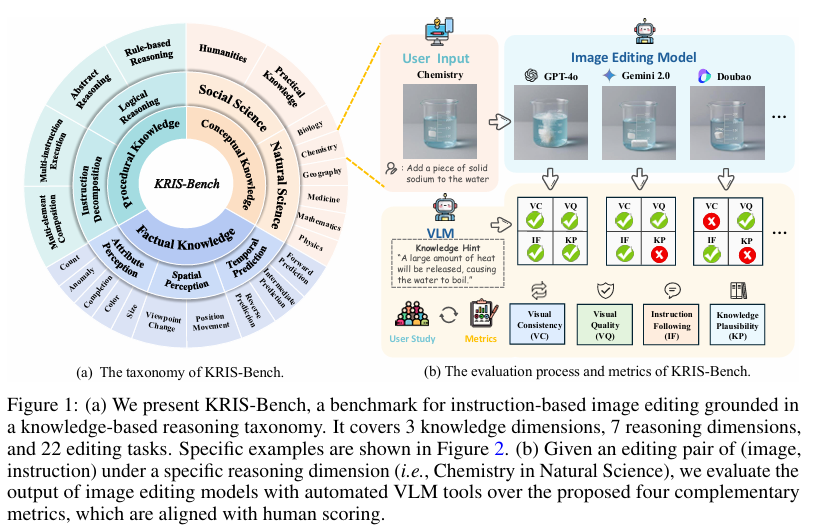
为了填补这一空白,本文提出了KRIS-Bench(Knowledge-based Reasoning in Image-editing Systems Benchmark),一个旨在通过认知信息透镜评估图像编辑模型的诊断性基准。KRIS-Bench的设计灵感来源于教育理论,它将图像编辑任务分为三种基础知识类型:事实性知识、概念性知识和程序性知识。基于这种分类,KRIS-Bench设计了22个具有代表性的任务,涵盖7个推理维度,并发布了1267个高质量的带注释编辑实例。通过引入新颖的知识合理性度量,并利用知识提示进行增强,KRIS-Bench旨在提供一个细粒度的评估框架,以推动智能图像编辑系统的发展。
研究方法
1. 任务分类与设计
KRIS-Bench根据教育理论中的知识分类,将图像编辑任务分为事实性知识、概念性知识和程序性知识三种类型。每种类型进一步细分为具体的推理维度,如事实性知识包括属性感知、空间感知和时间预测;概念性知识涵盖社会科学和自然科学;程序性知识则涉及逻辑推理和指令分解。基于这些分类,KRIS-Bench设计了22个代表性任务,每个任务都旨在评估模型在不同知识类型和推理维度上的表现。
2. 数据收集与标注
KRIS-Bench的数据集主要通过互联网收集,部分图像使用生成模型生成,或从现有数据集中获取。每个编辑任务都由训练有素的标注员创建指令,并通过ChatGPT进行指令多样性和真实性的增强。数据集由三名具有学士学位的标注员进行初步标注,并由三名具有博士学位的专家进行审核。对于需要领域专家的任务,还咨询了额外的领域特定评审员。
3. 评估协议
为了全面评估图像编辑模型的性能,KRIS-Bench提出了一个包含四个维度的评估协议:视觉一致性(VC)、视觉质量(VQ)、指令遵循(IF)和知识合理性(KP)。视觉一致性评估编辑后的图像是否忠实地保留了原始图像中与指令无关的部分;视觉质量评估生成图像的感知质量;指令遵循评估模型是否准确且完整地执行了用户提供的指令;知识合理性则评估编辑结果是否与现实世界的知识一致。为了支持知识合理性的评估,KRIS-Bench为每个需要现实世界知识的测试用例提供了手动策划的知识提示。
4. 实验设置
本文在KRIS-Bench上评估了10个最先进的图像编辑模型,包括三个闭源模型(GPT-4o、Gemini 2.0、Doubao)和七个开源模型(OmniGen、Emu2、BAGEL、Step1X-Edit、AnyEdit、MagicBrush、InstructPix2Pix)。所有模型均在H100 GPU上进行评估,使用默认的超参数设置以确保公平性和可重复性。
研究结果
1. 整体性能
实验结果表明,闭源模型在KRIS-Bench上的表现显著优于开源模型。其中,GPT-4o在所有知识类型和评估维度上均取得了最高分,除了在时间预测的视觉一致性上略低于Gemini 2.0。BAGEL-Think作为BAGEL模型的推理模式版本,在开源模型中表现最佳,并开始接近闭源模型的水平。
2. 按知识类型分析
基于表2的结果,所有模型在程序性知识上的表现普遍较弱,表明当前编辑模型在多步推理和任务分解方面面临重大挑战。令人惊讶的是,模型在概念性知识上的表现并不总是比事实性知识差,尽管前者需要更高层次的抽象和泛化能力。特别是在事实性知识任务中,模型在属性感知任务上表现较好,但在空间推理任务上表现显著下降。在概念性知识任务中,模型在涉及常识或文化背景的任务上表现较好,但在需要科学原理的任务上表现挣扎。
3. 按推理维度分析
在每个知识类型内部,对推理维度的细分揭示了多样化的性能模式。在事实性知识中,模型在属性感知任务上表现较好,但在空间推理上表现较差。在概念性知识中,模型在社会科学任务上表现较好,但在自然科学任务上表现挣扎。在程序性知识中,闭源模型在指令分解任务上表现出色,但在逻辑推理任务上表现不佳。
4. 按编辑任务和指标分析
图4展示了模型在各种编辑任务和指标上的性能雷达图。结果表明,即使在相同的推理维度内,不同任务之间的性能也存在显著差异。例如,在属性感知类别中,Gemini 2.0和Doubao在计数变化和大小调整任务上的指令遵循表现明显差于颜色变化任务。此外,尽管所有模型在视觉一致性和视觉质量上取得了相对较高的分数,但它们在指令遵循和知识合理性上的表现暴露了显著不足。
研究局限
1. 数据集规模与多样性
尽管KRIS-Bench提供了迄今为止最全面的知识推理图像编辑基准,包含1267个样本和22个任务,但其规模相对较小,可能无法完全代表所有可能的编辑场景和知识类型。此外,数据集中某些知识类型的代表性可能过高,导致评估结果存在偏差。
2. 文化特异性假设
KRIS-Bench中的任务设计可能包含文化特异性假设,这可能影响模型在不同文化背景下的泛化能力。例如,某些任务可能基于西方文化背景设计,对于非西方文化背景的模型或用户来说,可能存在理解上的困难。
3. 评估指标的局限性
尽管KRIS-Bench提出了一个包含四个维度的评估协议,但知识合理性指标仍然依赖于手动策划的知识提示和VLM的评估。这可能导致评估结果受到主观因素的影响,并且可能无法完全捕捉模型在所有现实世界知识上的表现。
未来研究方向
1. 扩大数据集规模与多样性
未来的研究可以致力于扩大KRIS-Bench的数据集规模,并增加更多样化的编辑任务和知识类型。通过收集更多来自不同文化背景和领域的图像编辑实例,可以提高基准的代表性和泛化能力。
2. 改进评估指标
为了减少主观因素的影响,未来的研究可以探索更自动化的评估方法,如利用大规模预训练的语言模型或视觉语言模型进行知识合理性的自动评估。此外,还可以考虑引入更多的评估维度,如模型的创造性、可解释性和鲁棒性等,以更全面地评估图像编辑模型的性能。
3. 探索多模态融合方法
随着多模态生成模型的发展,未来的研究可以探索如何更好地融合视觉和文本信息,以提高图像编辑模型在复杂推理任务上的表现。例如,可以研究如何利用预训练的视觉语言模型作为编码器或解码器,以增强模型对视觉和文本信息的理解和生成能力。
4. 推动跨学科合作
图像编辑模型的研发不仅涉及计算机科学领域的知识,还与教育学、心理学、认知科学等多个学科密切相关。未来的研究可以推动跨学科合作,结合不同学科的理论和方法,共同推动智能图像编辑系统的发展。
5. 关注模型的可解释性与透明度
随着图像编辑模型在各个领域的应用越来越广泛,模型的可解释性和透明度变得尤为重要。未来的研究可以关注如何提高模型的可解释性,使模型在生成编辑结果时能够提供更清晰的推理路径和依据。这有助于增强用户对模型的信任度,并促进模型在更多领域的应用。
综上所述,KRIS-Bench作为一个诊断性基准,为评估下一代智能图像编辑模型提供了有力的工具。通过深入分析现有模型的性能和局限性,未来的研究可以进一步推动智能图像编辑系统的发展,使其在更多领域发挥重要作用。