决策树引导:如何选择最适合你的机器学习算法
机器学习是构建能够从数据中学习并自主完成特定任务系统的“艺术与工艺”。它并不是人工智能的一个狭窄分支。事实上,现有的算法和方法数量繁多、种类多样,令人眼花缭乱。对于初学者或偶尔涉足机器学习的从业者来说,面对具体问题时选择何种算法常常成为难题。而这一决策恰恰是将数据与目标结合,构建正确模型的关键一步。

本文的目的正是为此而来:它通过可视化的决策树,为你提供一份指南,帮助你根据数据的性质和复杂度,选择最合适的机器学习算法。在这一过程中,文中还解释了一些与决策相关的技术与数据概念,以及你在自问自答时应关注的问题。
决策树方法
不再赘述,下面就是本文的主角:一棵为你指引正确机器学习方法的决策树。
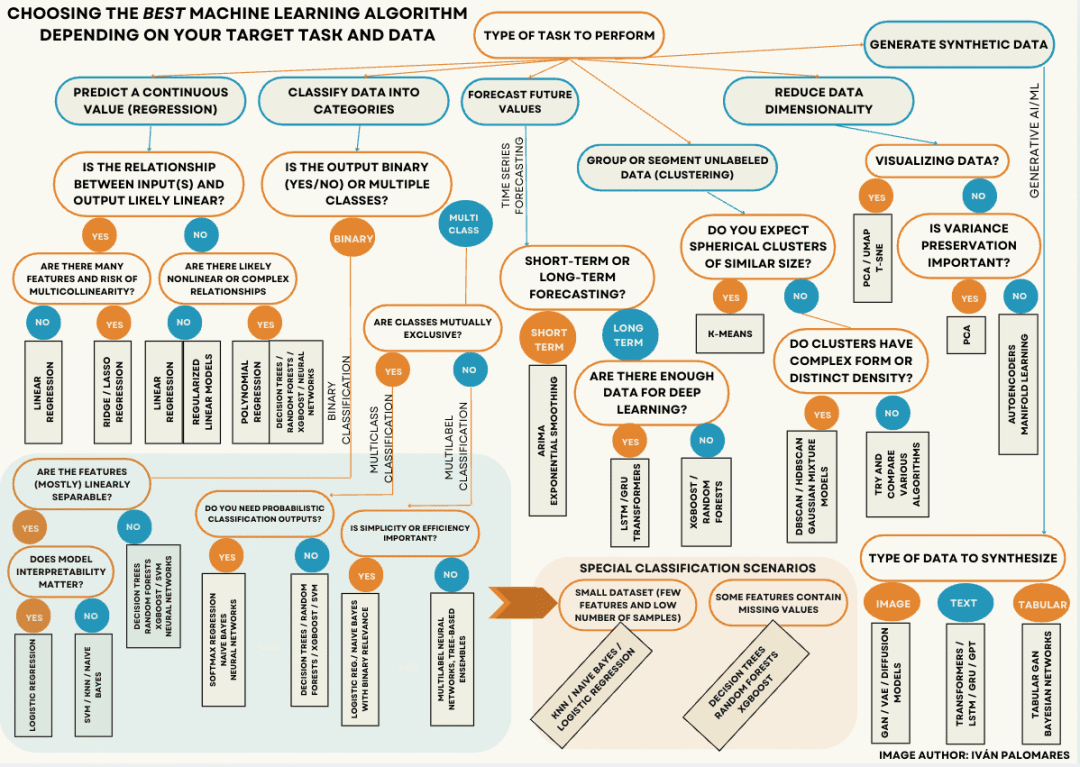
乍看之下,这棵决策树可能让人望而生畏,但好消息是:一旦你明确了要执行的任务类型,只需要关注决策树最顶端“任务类型”节点下的六个分支及其“子树”之一,其余部分可以忽略——这就是你的起点,无论遇到什么问题或场景。
接下来,我们深入分析决策树中涉及的细节和要点。以下是图表中区分的主要任务简要概述(从左到右):
预测型任务
回归(Regression):
你是否希望根据其他属性(如产品特征)预测或估算某个属性的连续值(如产品价格)?或者,你是否试图根据湿度或气压等条件来估算空气温度?如果是这样,你需要的是回归算法与模型。
分类(Classification):
你是否试图将动植物观测样本分类到不同物种,检测一封电子邮件是否为垃圾邮件,或根据图片中的物体内容对图像进行分类?那么请关注分类方法。
时间序列预测(Time Series Forecasting):
你是否拥有一组按时间顺序排列的数据(时间序列),并希望根据历史值预测某个属性或量(如温度)的未来数值?那么可以尝试时间序列预测方法。
非预测型任务
聚类(Clustering):
如果你拥有一组未标记(未分类)数据样本,并希望根据相似性将它们分为不同子组,那么聚类算法正是你需要的工具。
降维(Dimensionality Reduction):
你的数据是否过于庞大,希望在不丢失关键信息的前提下,获得更紧凑、易于管理的表达?又或是希望对复杂数据进行有意义的可视化?可以了解一下数据降维技术。
新数据生成(New Data Generation):
如果你想生成看起来类似于现有真实数据的新型合成数据(无论是结构化/表格数据、文本还是图像、视频等多媒体数据),那么前沿的生成式模型就是你的选择。
一旦确定目标任务,其余需要考虑的问题主要取决于数据的性质、特性与复杂度。以下是一些有助于你评估数据的提示:
数据输入与输出的线性与非线性关系:
选择合适的回归算法,很大程度上取决于预测变量(输入)与目标变量(输出)之间关系是否为线性。例如,根据房屋面积预测房价属于线性关系;而根据多种生活习惯和病史预测个人健康状况,可能呈现更复杂的非线性模式。
多重共线性(Multicollinearity):
当两个或多个输入特征高度相关时,就会出现多重共线性现象,这暗示着可能存在冗余的线性关系。这种信息冗余会干扰基于线性回归技术的精确估算,此时像岭回归(ridge regression)或套索回归(lasso regression)等替代方法可以降低多重共线性的影响。
特征线性可分(Linearly Separable Features):
在分类问题中,理想(但实际较少见)的情况是,每个类别的数据点都可以通过一条直线或超平面完全分开,这时基本的分类技术如逻辑回归(logistic regression)或线性支持向量机(linear SVM)即可胜任。而当类别重叠或边界远非线性时,基于树的模型、神经网络和非线性SVM通常表现更佳。
概率分类输出(Probabilistic Classification Outputs):
如果你需要的是某个实例属于每个可能类别的概率(而不是单一类别的预测),那么带有softmax输出层的回归模型、朴素贝叶斯(naive Bayes)或专为输出归一化类别概率设计的神经网络更为适合。
聚类形状与密度(Cluster Shape and Density):
对于聚类算法的选择,关于要识别的数据子组的形状和密度的假设也很重要。聚类形状指子组是球状还是不规则,密度描述各聚类内点的稠密程度。K-means算法简单易用,但前提是假定子组为球状且大小均匀;而DBSCAN或HDBSCAN更适合发现形状任意且密度不均的数据聚类。
方差保留(Variance Preservation):
在降维任务中,通常需要在最大限度简化数据和保留重要信息之间权衡。当你希望在降维的同时保留数据的主要特性和结构时,保留大部分数据方差尤为重要,这正是主成分分析(PCA)等技术的设计目标。
神经网络与深度学习架构的多面角色:
无论是“较简单”的神经网络还是更深层的结构如LSTM、GRU和Transformer,它们都可广泛应用于回归、分类、图像目标检测、复杂长期时间序列预测以及数据生成等多种任务。这也是为什么当数据特别庞大、复杂且具挑战性时,各类机器学习任务都可以考虑这些方法。
总结
本文为如何根据不同类型的数据解决多样化问题,提供了选择合适机器学习算法的指南。希望通过决策树的方法,能够帮助你一步步走向最理想的算法选择。