Python训练营打卡 Day24
元组
——————————————————————————————————————————
一、元组
1、元组的概念
在 Python 中,元组(tuple)是一种序列类型的数据结构。元组使用圆括号()来创建,可存储一组不允许修改的数据;可用于函数返回多个值、在字典中作为键、用于数据交换等。
2、元组的特点
元组是不可变的,一旦创建,其元素的值就不能被修改。这意味着不能对元组的元素进行赋值操作。(需要注意的是,如果元组中的元素本身是可变对象(如列表),那么可以对这些可变对象的内容进行修改。)
元组是有序的,并且可重复,这一点和列表一样。
二、元组操作
1、元组的创建
①常规
my_tuple1 = (1, 2, 3)
my_tuple2 = ('a', 'b', 'c')
my_tuple3 = (1, 'hello', 3.14, [4, 5]) # 可以包含不同类型的元素
print(f'my_tuple1为:{my_tuple1}')
print(f'my_tuple2为:{my_tuple2}')
print(f'my_tuple3为:{my_tuple3}')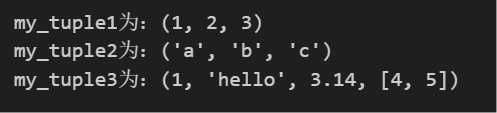
②省略括号
my_tuple4 = 10, 20, 'thirty' # 逗号是关键
print(f'my_tuple4为:{my_tuple4}')
print(f'my_tuple4的类型为:{type(my_tuple4)}') 
③空元组:两种方法
empty_tuple = ()empty_tuple2 = tuple()2、元组的常见用法
① 元组的索引
# 元组的索引
my_tuple = ('P', 'y', 't', 'h', 'o', 'n')
print(my_tuple[0]) # 第一个元素
print(my_tuple[2]) # 第三个元素
print(my_tuple[-1]) # 最后一个元素② 元组的切片
# 元组的切片
my_tuple = (0, 1, 2, 3, 4, 5)
print(my_tuple[1:4]) # 从索引 1 到 3 (不包括 4)
print(my_tuple[:3]) # 从开头到索引 2
print(my_tuple[3:]) # 从索引 3 到结尾
print(my_tuple[::2]) # 每隔一个元素取一个③ 元组的长度获取
# 元组的长度获取
my_tuple = (1, 2, 3)
print(len(my_tuple))3、元组+管道
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_score# 1. 加载数据
iris = load_iris()
X = iris.data
y = iris.target# 2. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 3. 构建管道
# 管道按顺序执行以下步骤:
# - StandardScaler(): 标准化数据(移除均值并缩放到单位方差)
# - LogisticRegression(): 逻辑回归分类器
pipeline = Pipeline([('scaler', StandardScaler()),('logreg', LogisticRegression())
])# 4. 训练模型
pipeline.fit(X_train, y_train)# 5. 预测
y_pred = pipeline.predict(X_test)# 6. 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"模型在测试集上的准确率: {accuracy:.2f}")注释:
iris:鸢尾花(Iris)数据集。这个数据集常用的是一个分类问题数据集,它包含了鸢尾花的四种花的样本,分为三个类别(每类 50 个样本),每个样本都有四个特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度。
三、可迭代对象
1、定义
在 Python 中,可迭代对象(iterable)是指可以直接用于 for 循环的对象。更具体地说,可迭代对象是实现了 __iter__ 方法或者 __getitem__ 方法(支持按索引获取元素)的对象。__iter__ 方法会返回一个迭代器对象。
2、常见的可迭代对象
①. 序列类型 Sequence Types
列表list
元组tuple
字符串str
范围range
②. 集合类型 Set Types
集合set
③. 字典类型 Mapping Types
字典dict
④. 文件对象 File objects
⑤. 生成器 Generators
⑥. 迭代器本身 Iterators
# 列表 (list)
print("迭代列表:")
my_list = [1, 2, 3, 4, 5]
for item in my_list:print(item)# 元组 (tuple)
print("迭代元组:")
my_tuple = ('a', 'b', 'c')
for item in my_tuple:print(item)# 字符串 (str)
print("迭代字符串:")
my_string = "hello"
for char in my_string:print(char)# range (范围)
print("迭代 range:")
for number in range(5): # 生成 0, 1, 2, 3, 4print(number)# 集合类型 (Set Types)
# 集合 (set) - 注意集合是无序的,所以每次迭代的顺序可能不同
print("迭代集合:")
my_set = {3, 1, 4, 1, 5, 9}
for item in my_set:print(item)# 字典 (dict) - 默认迭代时返回键 (keys)
print("迭代字典 (默认迭代键):")
my_dict = {'name': 'Alice', 'age': 30, 'city': 'Singapore'}
for key in my_dict:print(key)# 迭代字典的值 (values)
print("迭代字典的值:")
for value in my_dict.values():print(value)# 迭代字典的键值对 (items)
print("迭代字典的键值对:")
for key, value in my_dict.items(): # items方法很好用print(f"Key: {key}, Value: {value}")

四、OS模块
1、导入模块(内置):import os
2、获取当前工作目录:os,getcwd()
3、获取当前工作目录下的文件列表:os.listdir()
4、拼接获取工作目录:
# 使用 r'' 原始字符串,这样就不需要写双反斜杠 \\,因为\会涉及到转义问题
path_a = r'C:\Users\YourUsername\Documents' # r''这个写法是写给python解释器看,他只会读取引号内的内容,不用在意r的存在会不会影响拼接
path_b = 'MyProjectData'
file = 'results.csv'# 使用 os.path.join 将它们安全地拼接起来,os.path.join 会自动使用 Windows 的反斜杠 '\' 作为分隔符
file_path = os.path.join(path_a , path_b, file)file_path
5、环境变量方法:os.environ
使用 .items() 方法可以方便地同时获取变量名(键)和变量值:
for variable_name, value in os.environ.items():
print(f"{variable_name}={value}")
6、目录树: os.walk()
import osstart_directory = os.getcwd() # 假设这个目录在当前工作目录下print(f"--- 开始遍历目录: {start_directory} ---")for dirpath, dirnames, filenames in os.walk(start_directory):print(f" 当前访问目录 (dirpath): {dirpath}")print(f" 子目录列表 (dirnames): {dirnames}")print(f" 文件列表 (filenames): {filenames}")# # 你可以在这里对文件进行操作,比如打印完整路径# print(" 文件完整路径:")# for filename in filenames:# full_path = os.path.join(dirpath, filename)# print(f" - {full_path}")

@浙大疏锦行