CloudCanal RAG x Ollama 构建全栈私有 AI 服务
在企业级 AI 应用中,RAG(Retrieval-Augmented Generation)技术正在逐步从探索走向落地。与面向个人使用者的轻量级问答系统不同,企业对 RAG 的要求更高:它必须可靠、可控、可扩展,最重要的是——安全。许多企业对于数据上传至在线大模型或公有云向量数据库持谨慎甚至禁止态度,因为这可能导致敏感信息暴露给外部服务。
CloudCanal 近期已支持通过 Ollama 本地部署 RAG 服务,有效解决了传统方案中存在的数据安全隐患。本文将聚焦于企业级 RAG 服务,介绍如何通过本地部署实现一个不依赖公网的纯私有 RAG 构建方案。
什么是企业级 RAG 服务?
企业级 RAG 服务强调端到端的集成能力、安全可控以及对业务系统的适配性。它不仅能实现基于知识的智能问答,还能提供高可靠、高安全、高扩展的服务。在保护企业数据的前提下,真正服务于业务流程的自动化与智能化。
相比于面向个人或实验场景的轻量 RAG 项目,企业级 RAG 服务具有以下核心特征:
- 技术栈全私有,部署可控
服务能够完全运行在本地数据中心或私有云环境中,避免数据外泄风险,满足对数据合规性要求较高的行业需求。 - 数据来源多样,格式丰富
不局限于文本文件类型,还支持数据库等多种数据来源,实现真正的“全域知识接入”。 - 支持增量数据同步,确保时效性与一致性
在企业级场景中,知识信息更新频繁,服务需支持高效的增量同步能力,确保 RAG 索引内容始终与业务系统保持同步。 - 可与多种工具链协同,完成复杂任务链路
企业级 RAG 服务不仅要检索和生成,还要与函数调用(Function Calling)、工具执行(如 SQL 查询)等能力打通,构建更完整的智能任务执行流程。
那么,如何在不依赖任何在线服务的前提下,安全地构建一个完全私有的企业级 RAG 服务呢?
CloudCanal RAG
CloudCanal 推出的 RagApi 封装了向量检索与模型问答能力,并兼容 MCP 协议,让用户能快速上手搭建属于自己的 RAG 服务。
相比传统 RAG 架构手动部署流程,CloudCanal 提供的 RAG 服务具有以下独特优势:
- 双任务完成全流程:文档导入 + API 发布。
- 零代码部署:无需开发,自定义配置即可构建 API 服务。
- 参数可调:支持设置向量 Top-K 数量、匹配阈值、Prompt 模板、模型温度等核心参数。
- 多模型与平台适配:支持阿里云 DashScope、OpenAI、DeepSeek 等主流模型与 API 平台。
- OpenAI API 兼容接口:直接接入现有 Chat 应用或工具链,无需额外适配。
实例演示
下面将使用以下组件,展示如何快速搭建一个完全离线、数据可控、安全可靠的企业级 RAG 服务。
- Ollama:用于本地运行大语言模型
- PostgreSQL 向量数据库:作为本地向量检索存储引擎
- CloudCanal RagApi:用于构建本地化的 RAG 问答服务
整体工作流程如下:
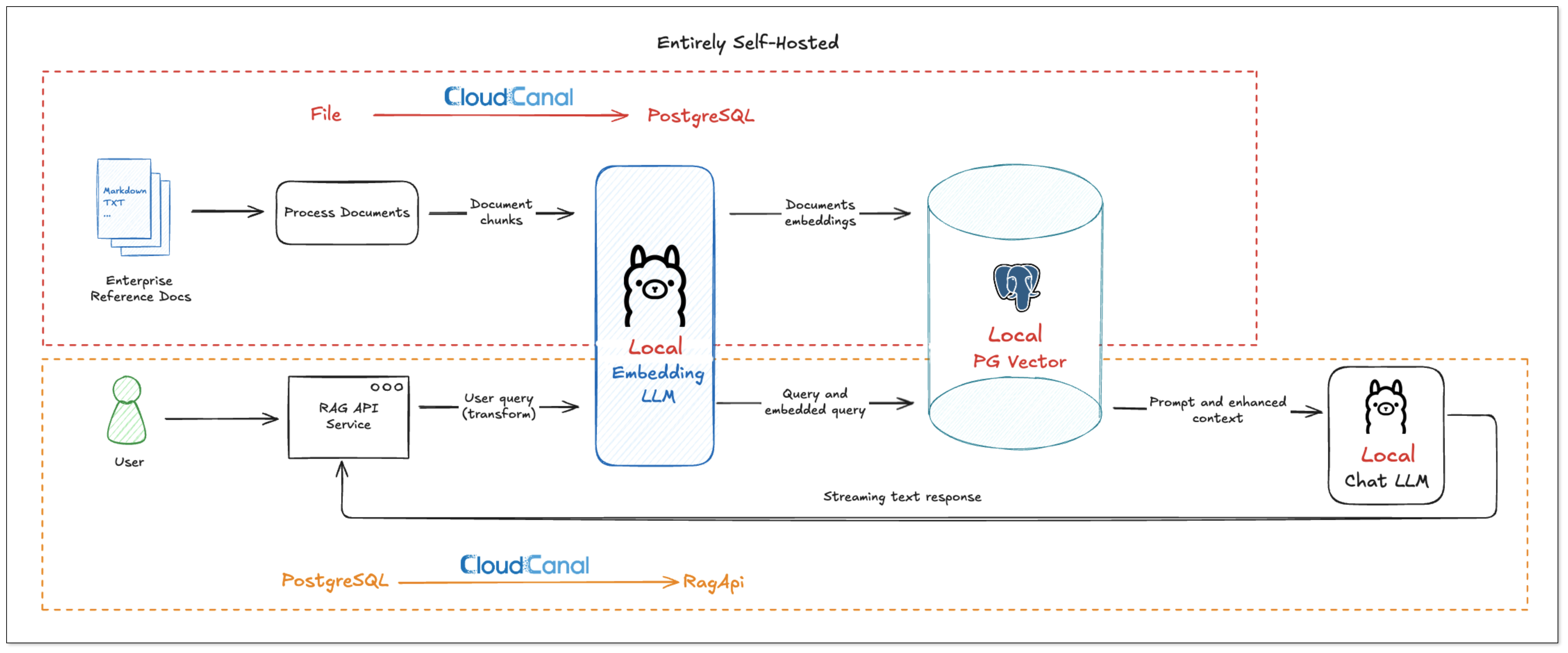
前置部署
部署本地 Ollama
Ollama 可以让你在本地轻松部署和管理大语言模型。在本方案中,Ollama 不仅用于文档向量化阶段生成嵌入向量 (Embeddings),也作为对话模型用于最终的问答交互。CloudCanal 支持通过 Ollama 提供完整的向量生成与推理能力,完美契合纯私有化 RAG 场景。
- 下载与安装 Ollama
访问 Ollama 官方网站下载对应操作系统的安装包:https://ollama.com/download
- 拉取并运行模型:
安装完成后,打开终端,执行以下命令来拉取并运行一个适合嵌入和推理的模型,例如 qwen3:8b (也可以根据硬件情况选择其他模型,如 qwen3:14b 等。请注意,部分大型模型对硬件资源要求较高):
ollama run qwen3:8b

模型下载并首次运行后,可以按 Ctrl + D 退出当前模型的交互模式。
部署本地 PostgreSQL 向量数据库
- 安装 Docker(如已安装可跳过)
不同操作系统可参考以下步骤进行安装:
- MacOS:参考官方安装文档:Docker Desktop for Mac
- CentOS / RHEL:参考下面脚本
## centos / rhel
sudo yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.reposudo yum install -y docker-ce-20.10.9-3.* docker-ce-cli-20.10.9-3.*sudo systemctl start dockersudo echo '{"exec-opts": ["native.cgroupdriver=systemd"]}' > /etc/docker/daemon.jsonsudo systemctl restart docker
- Ubuntu:参考下面脚本
## ubuntu
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -sudo add-apt-repository "deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"sudo apt-get updatesudo apt-get -y install docker-ce=5:20.10.24~3-0~ubuntu-* docker-ce-cli=5:20.10.24~3-0~ubuntu-*sudo systemctl start dockersudo echo '{"exec-opts": ["native.cgroupdriver=systemd"]}' > /etc/docker/daemon.jsonsudo systemctl restart docker
- 启动 PostgreSQL + pgvector 容器服务
打开终端,执行以下命令,一键完成 PostgreSQL 环境部署:
cat <<'EOF' > init_pgvector.sh
#!/bin/bash# 创建 docker-compose.yml 文件
cat <<YML > docker-compose.yml
version: "3"
services:db:container_name: pgvector-dbhostname: 127.0.0.1image: pgvector/pgvector:pg16ports:- 5432:5432restart: alwaysenvironment:- POSTGRES_DB=api- POSTGRES_USER=root- POSTGRES_PASSWORD=123456
YML# 启动容器服务(后台运行)
docker-compose up --build -d# 等待容器启动后,进入数据库并启用向量扩展
echo "等待容器启动中..."
sleep 5docker exec -it pgvector-db psql -U root -d api -c "CREATE EXTENSION IF NOT EXISTS vector;"
EOF# 赋予执行权限并运行脚本
chmod +x init_pgvector.sh
./init_pgvector.sh
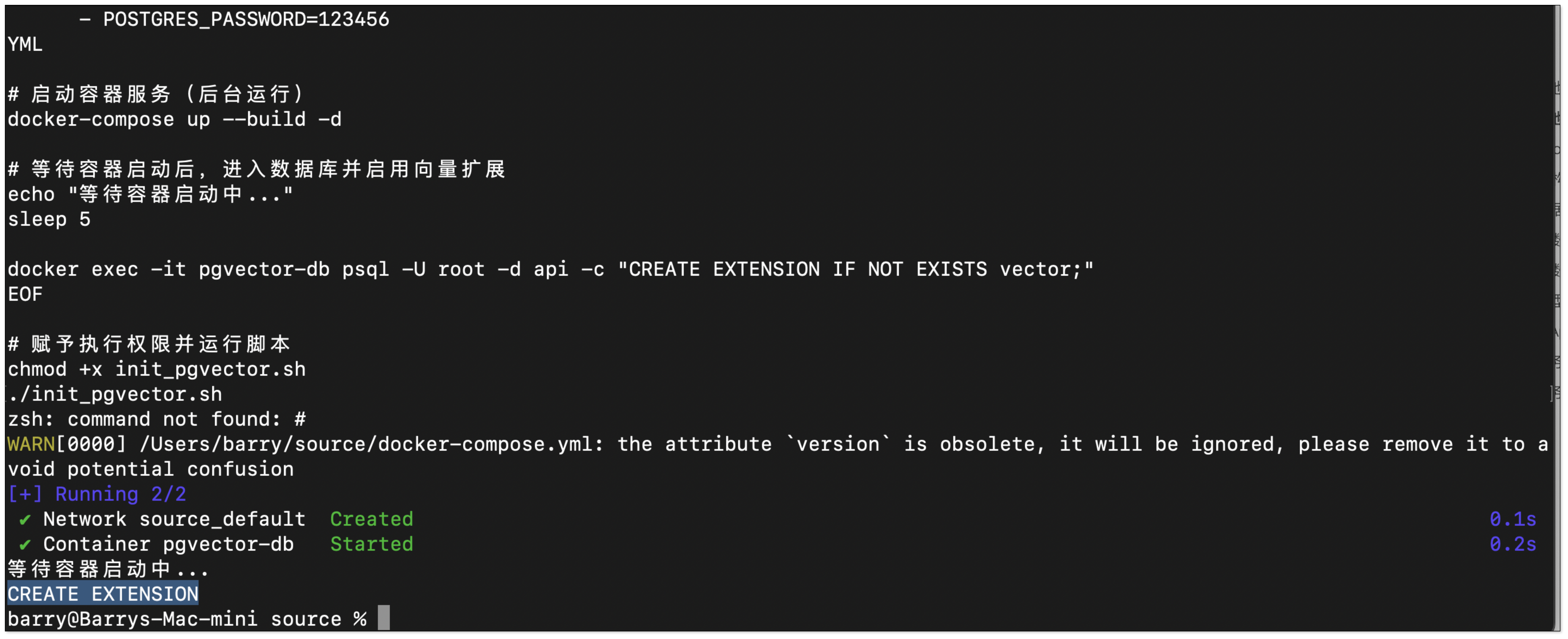
执行完毕后,本地 PostgreSQL 将自动启用 pgvector 插件,作为私有化向量检索引擎,为 CloudCanal RAG 提供底层存储支持。
部署 CloudCanal 私有化版本
- 下载并解压 CloudCanal 私有部署版本。
- 修改 install_on_docker/docker-compose.yml 文件,补充 Sidecar 端口配置:
...省略...sidecar:image: clougence/cloudcanal-sidecar:${build_version}container_name: cloudcanal-sidecardepends_on:- consolevolumes:- cloudcanal_sidecar_volume:/home/clougenceports:- "18787:8787"- "18089:18089" # 新增端口映射networks:cloudcanal-network:ipv4_address: 172.31.238.4...省略...
- 完成全新安装。
RAG 服务构建
添加数据源
登录 CloudCanal 控制台,点击 「数据源管理」>「新增数据源」,添加以下数据源:
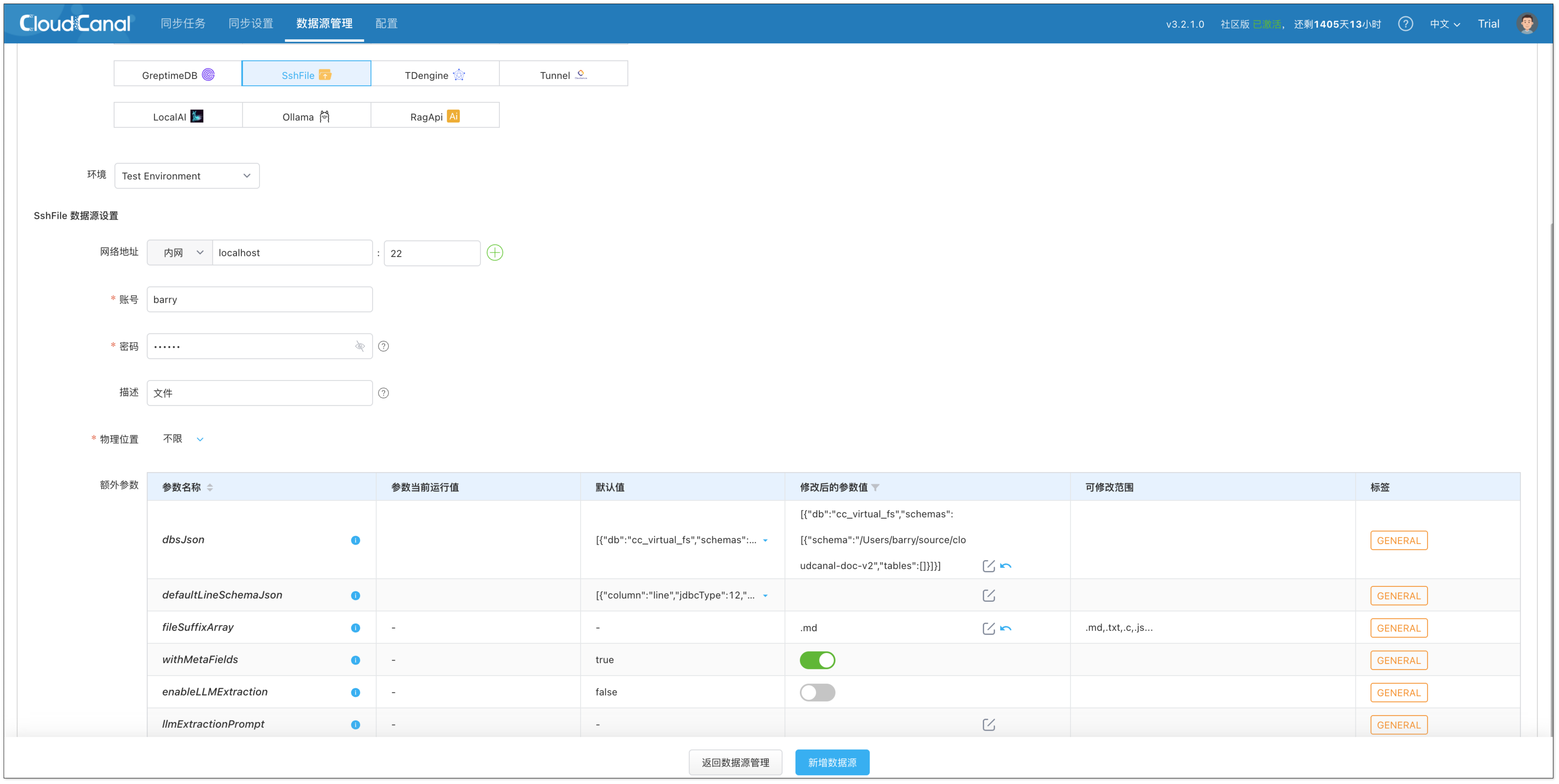
文件数据源(SshFile)
用于读取本地或远程服务器中的 Markdown 文档。添加步骤如下:
- 类型选择:自建 > SshFile
- 配置说明:
- 网络地址:填写目标服务器的 IP 地址(本机如** 127.0.0.1**)和 SSH 端口(默认端口为 22)。
- 账号密码:填写用于 SSH 登录该服务器的用户名和密码。如果在 Mac 或 Linux 上操作,可以直接填写当前用户名和本地密码即可。
- 额外参数 fileSuffixArray:填写 .md,用于筛选 Markdown 文件,避免无关文件被加载。
- 额外参数 dbsJson:用于指定要同步的文档目录。你可以复制系统提供的默认值,并将其中的 schema 字段修改为你实际存放 Markdown 文件的根目录路径。
[{"db":"cc_virtual_fs","schemas":[{"schema":"/Users/barry/source/cloudcanal-doc-v2","tables":[]}]}
]
向量数据库(PostgreSQL)
用于存储通过大模型编码后的文档向量,是整个 RAG 检索流程的核心数据源。
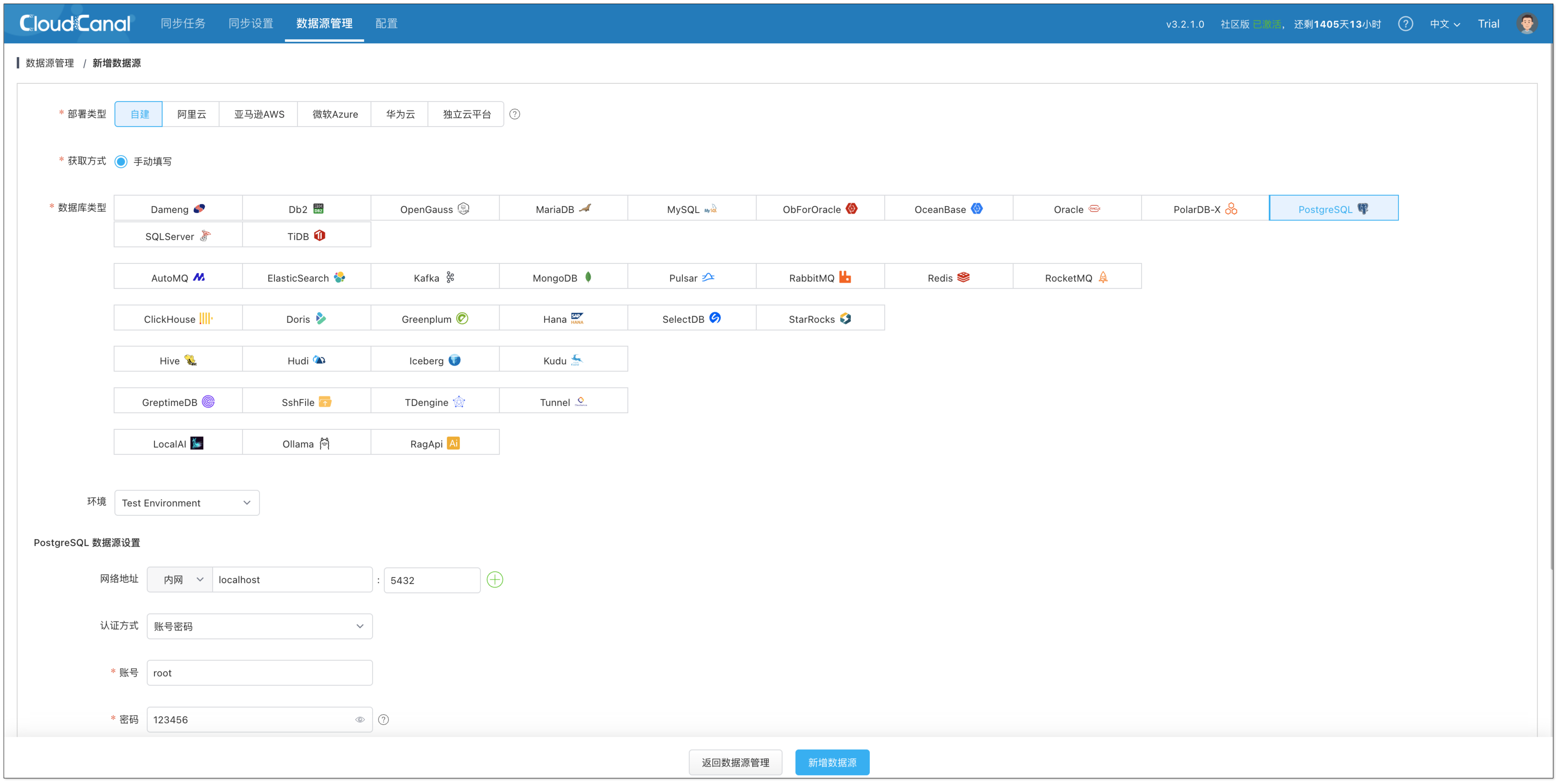
- 类型选择:自建 > PostgreSQL
- 配置说明:
- 网络地址:localhost:5432
- 用户名:root
- 密码:123456
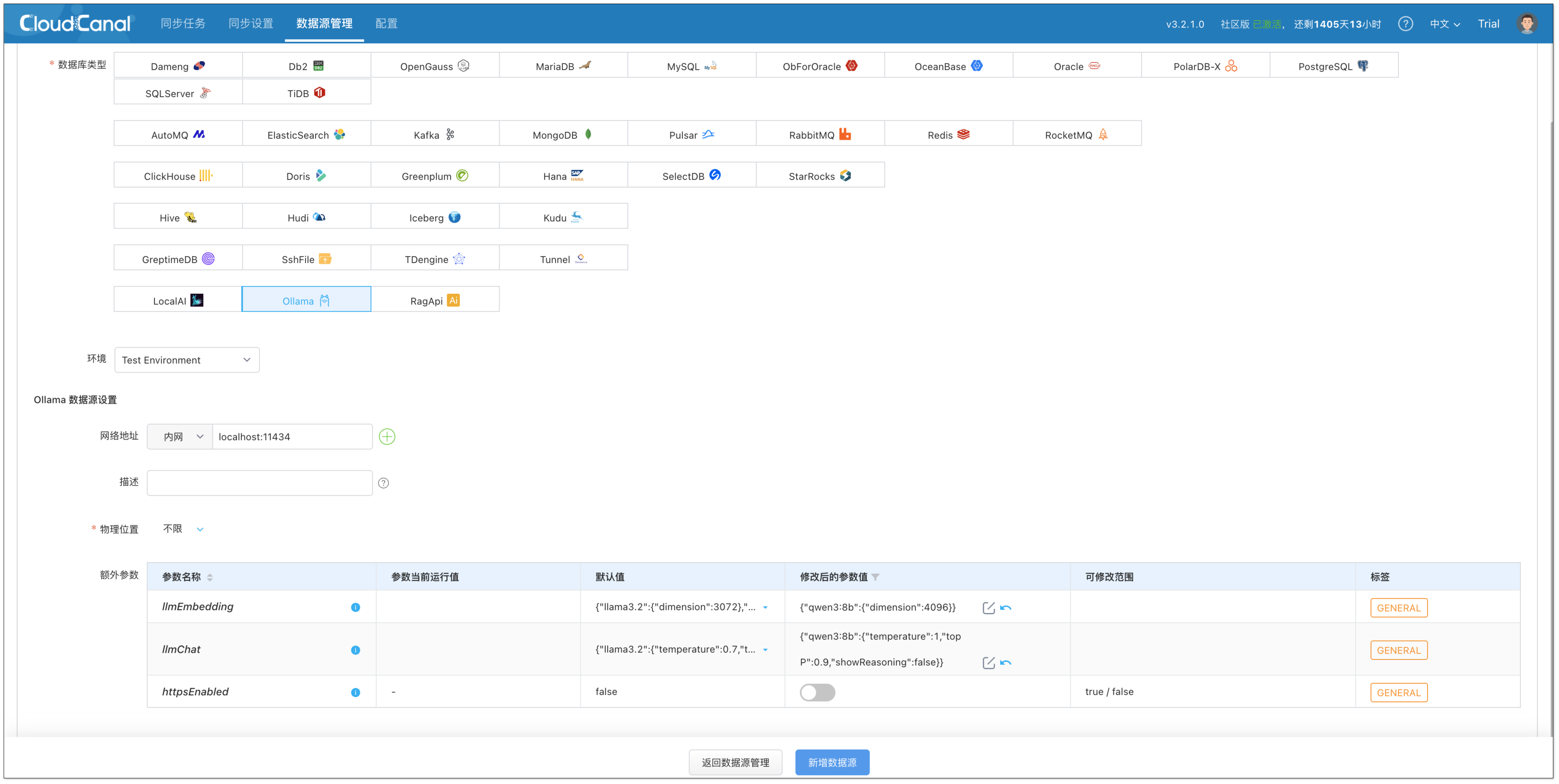
大模型平台(Ollama)
CloudCanal 支持通过 Ollama 提供完整的向量生成与推理能力,适用于完全私有化的 RAG 场景。
- 类型选择:自建 > Ollama
- 配置说明:
- 网络地址:localhost:11434
- 额外参数 llmEmbedding:
{"qwen3:8b": {"dimension": 4096}
}
- 额外参数 llmChat:
{"qwen3:8b": {"temperature": 1,"topP": 0.9,"showReasoning": false}
}
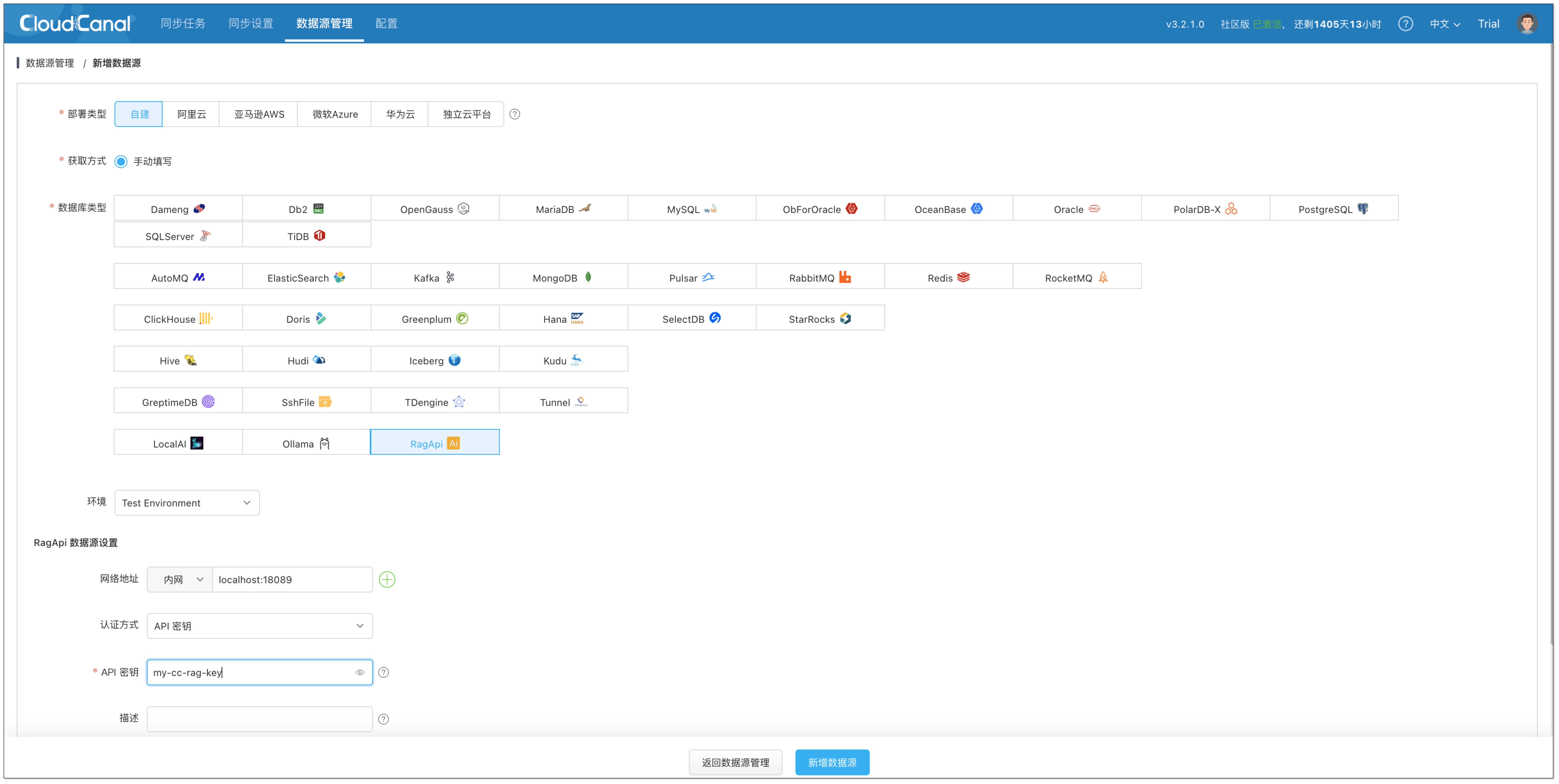
RagApi 服务(CloudCanal)
RagApi 是最终面向用户提供问答接口的服务模块,用于对接 Chat 界面或上层应用。
- 类型选择:自建 > RagApi
- 配置说明:
- 网络地址:localhost:18089
- API 密钥:自定义一个字符串(例如 my-cc-rag-key),用于后续调用 RagApi 接口时进行身份验证。
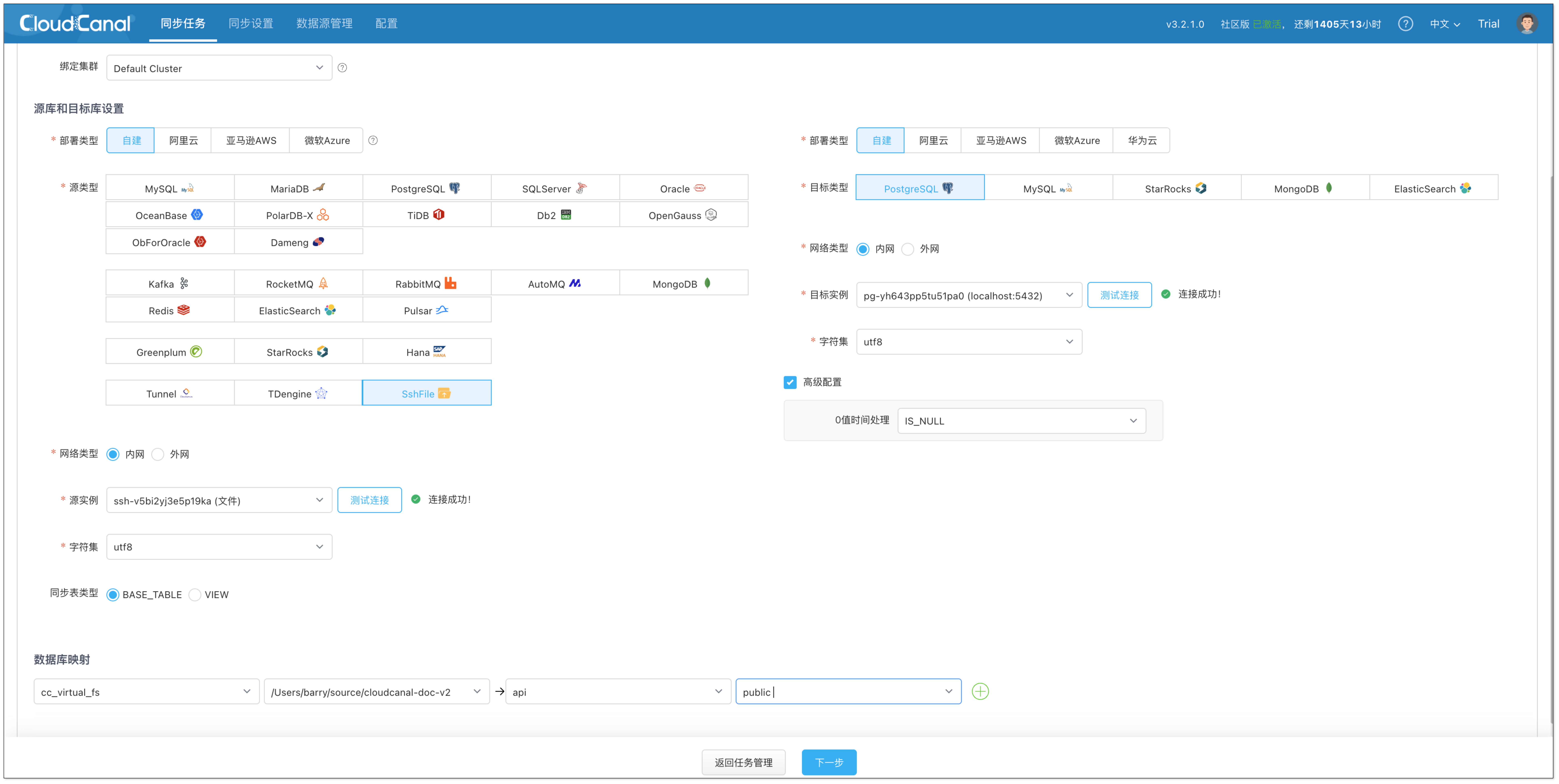
创建任务 1:数据向量化
- 点击 同步任务 > 创建任务。
- 选择以下数据源,并点击 测试连接 确认网络与权限正常。
- 源端:SshFile
- 目标端:PostgreSQL
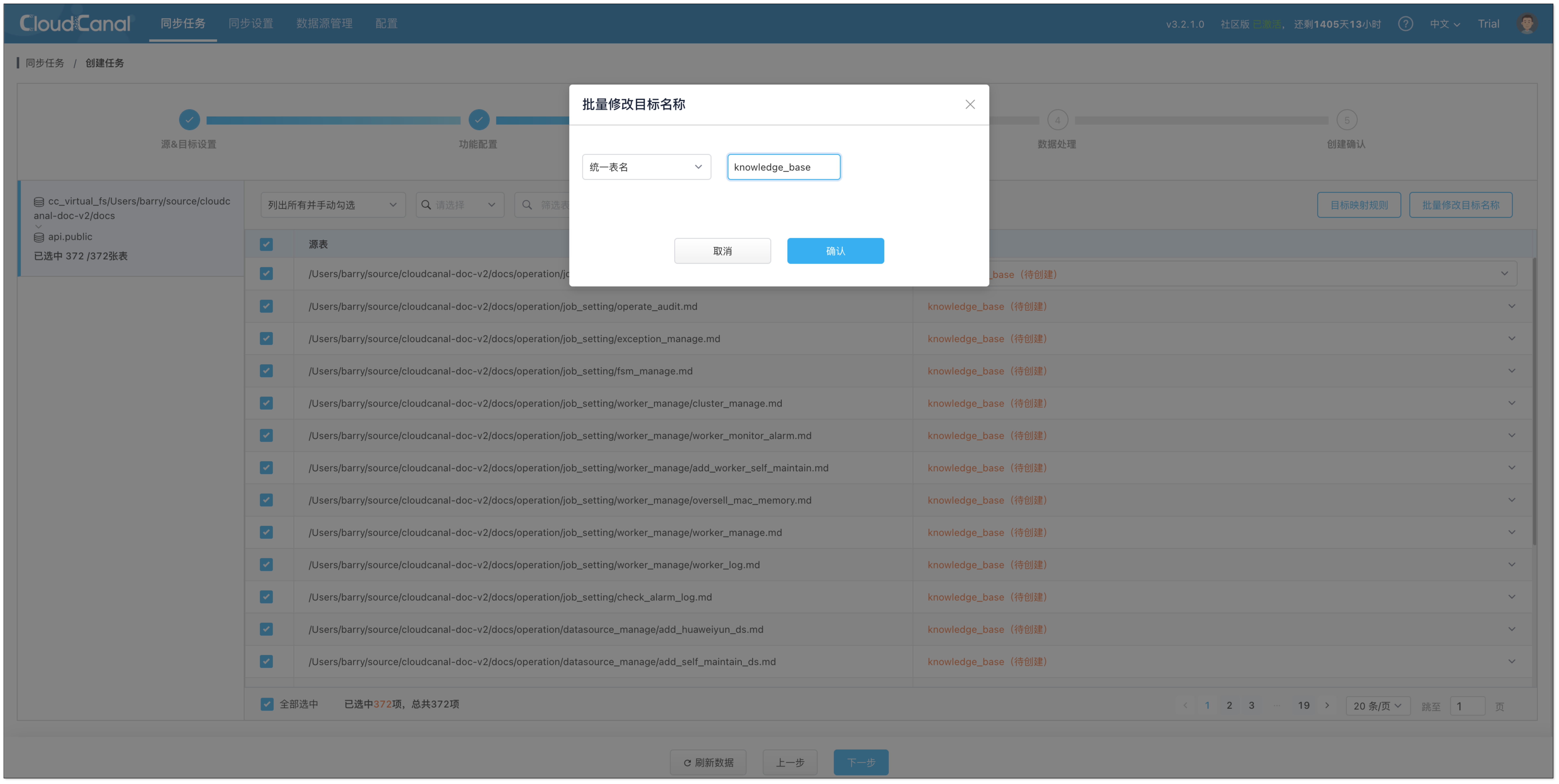
- 在 功能配置 页面,任务类型选择 全量迁移,任务规格选择默认 2 GB 即可。
- 在 表&action过滤 页面,进行以下配置:
- 选择需要定时数据迁移的文件,可同时选择多个。
- 点击 批量修改目标名称 > 统一表名 > 填写表名(如 knowledge_base),并确认,方便将不同文件向量化并写入同一个表。
- 在 数据处理 页面,进行以下配置:
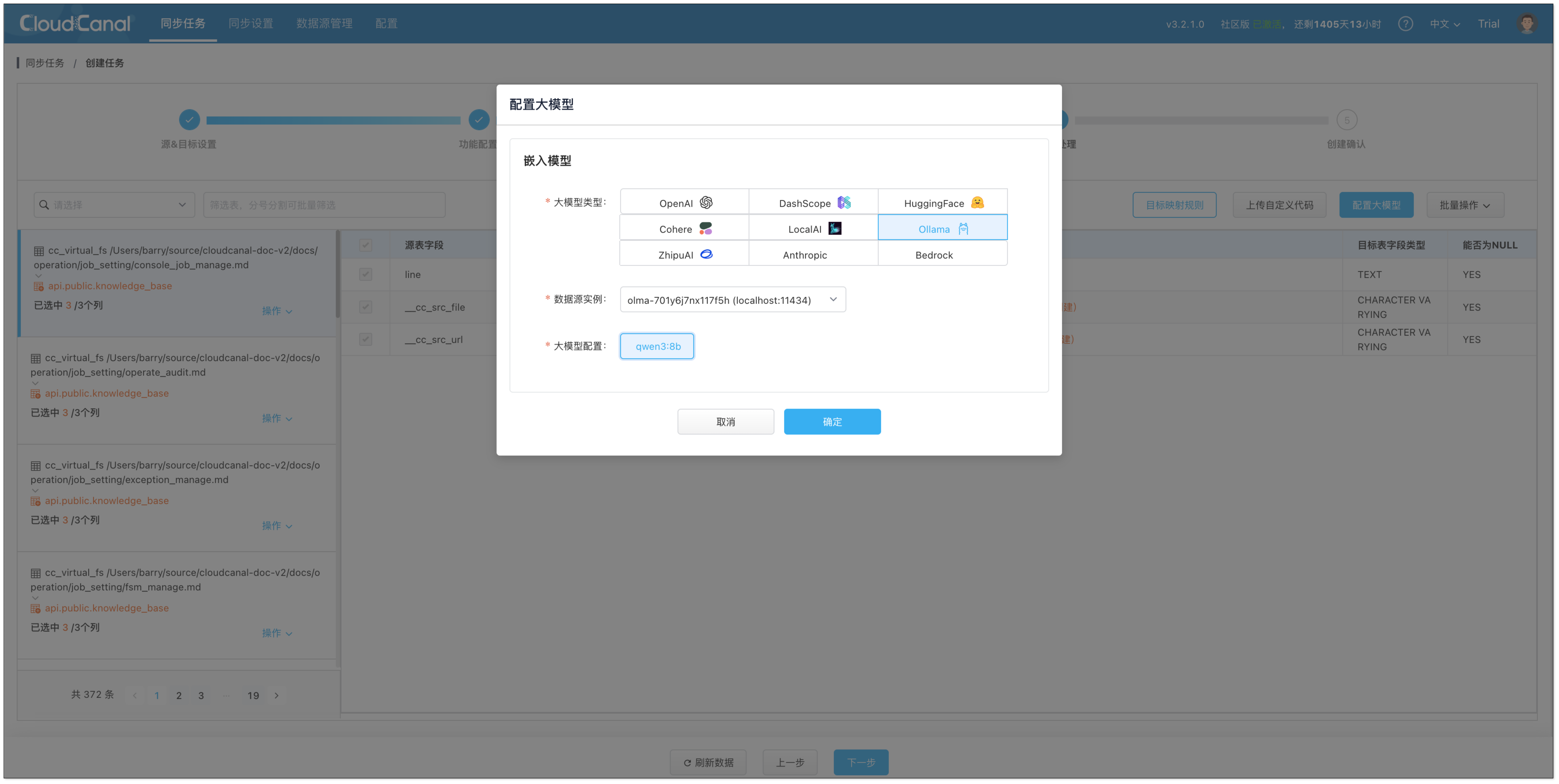
- 点击 配置大模型 > Ollama,选择刚添加的大模型实例,并选择
qwen3:8b。
- 点击 配置大模型 > Ollama,选择刚添加的大模型实例,并选择
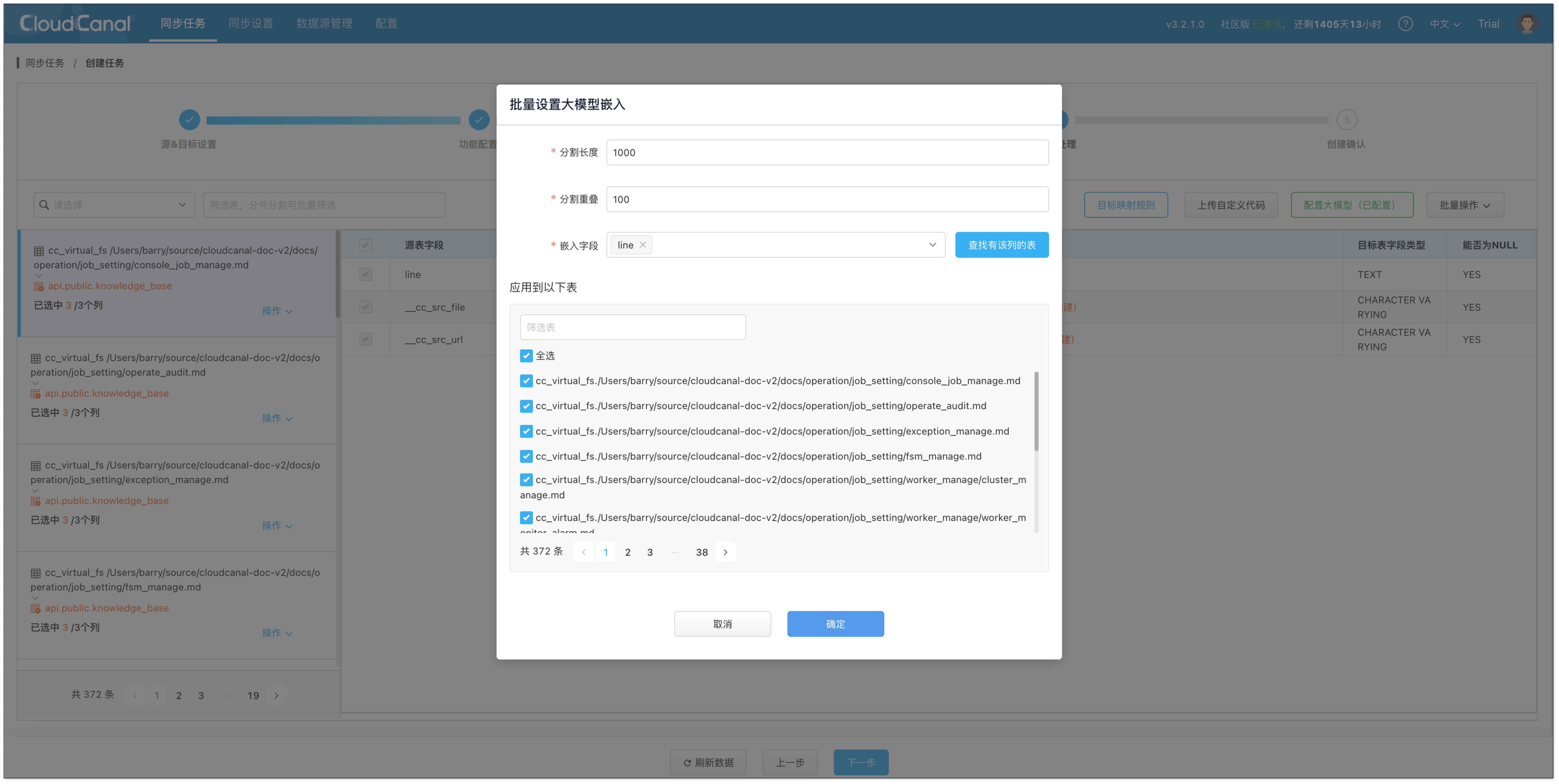
2. 点击 批量操作 > 大模型嵌入,选择需要嵌入的字段,并全选表。
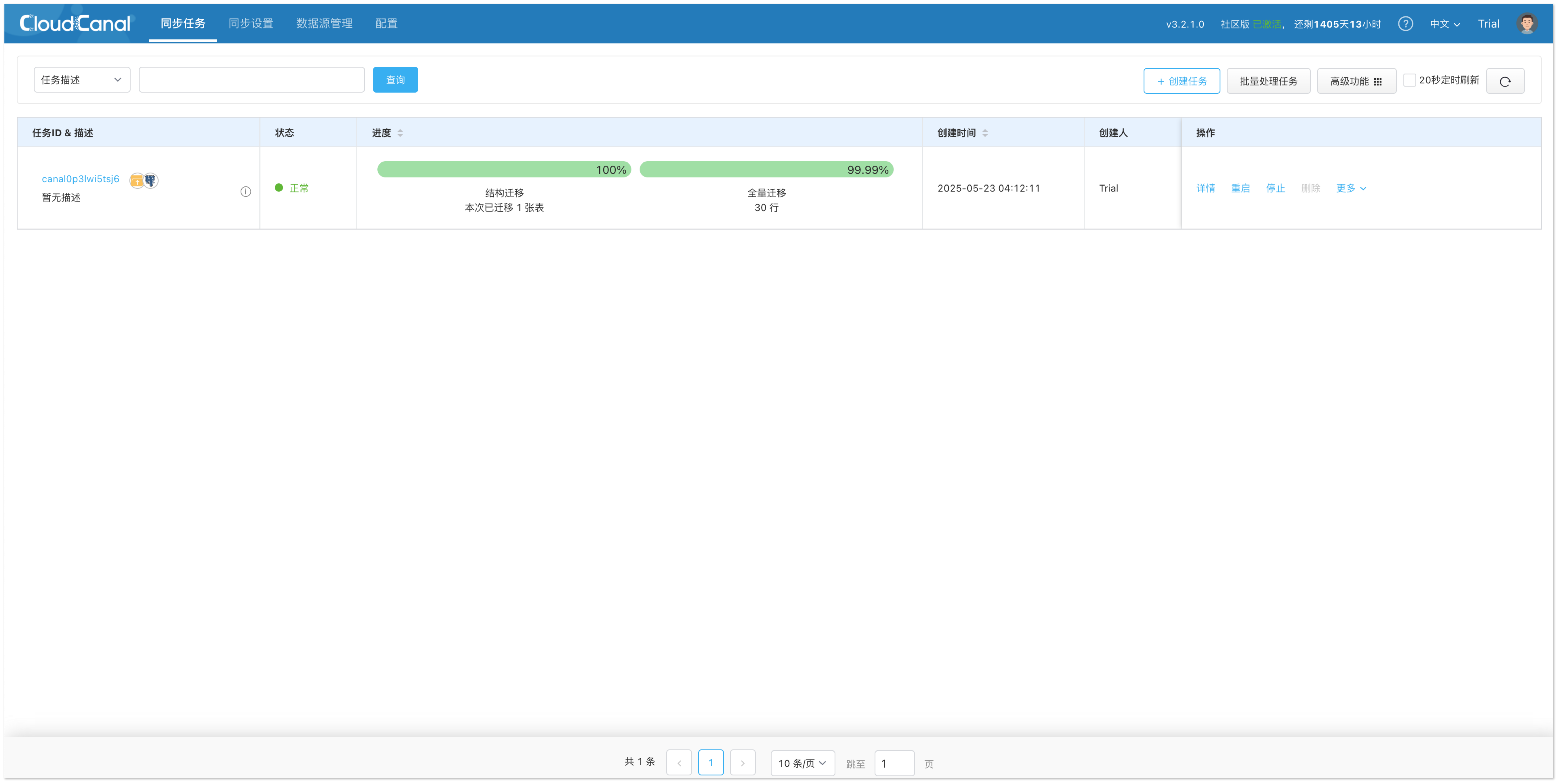
- 在 创建确认 页面,点击 创建任务,开始运行。
创建任务 2:RagApi 服务
- 点击 同步任务 > 创建任务。
- 选择以下数据源,并点击 测试连接 确认网络与权限正常。
- 源端:已配置的 PostgreSQL(向量表所在库)
- 目标端:RagApi
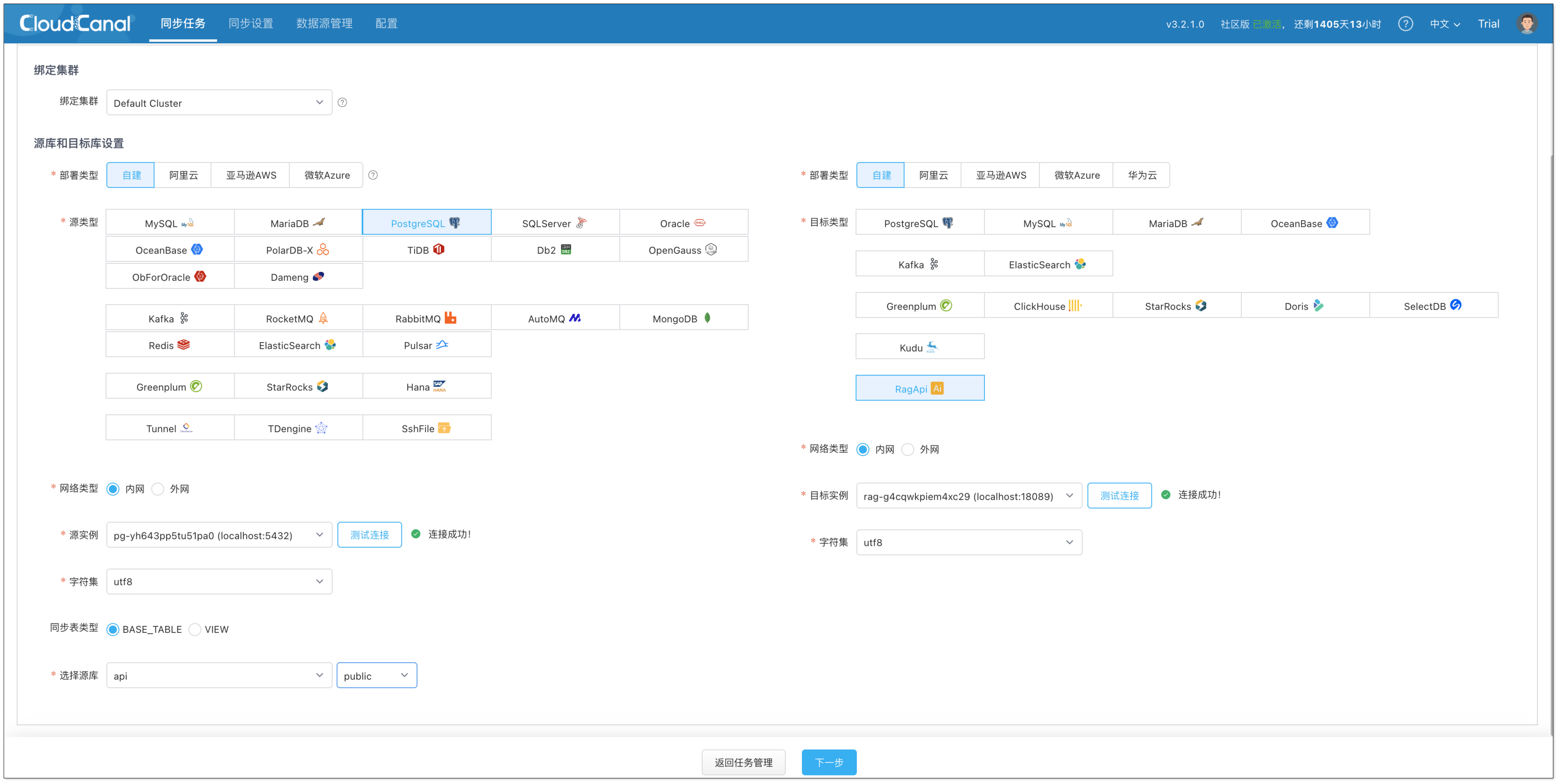
- 在 功能配置 页面,任务类型选择 全量迁移,任务规格选择默认 2 GB 即可。
- 在 表&action过滤 页面,选择要使用的向量表(可多选)。
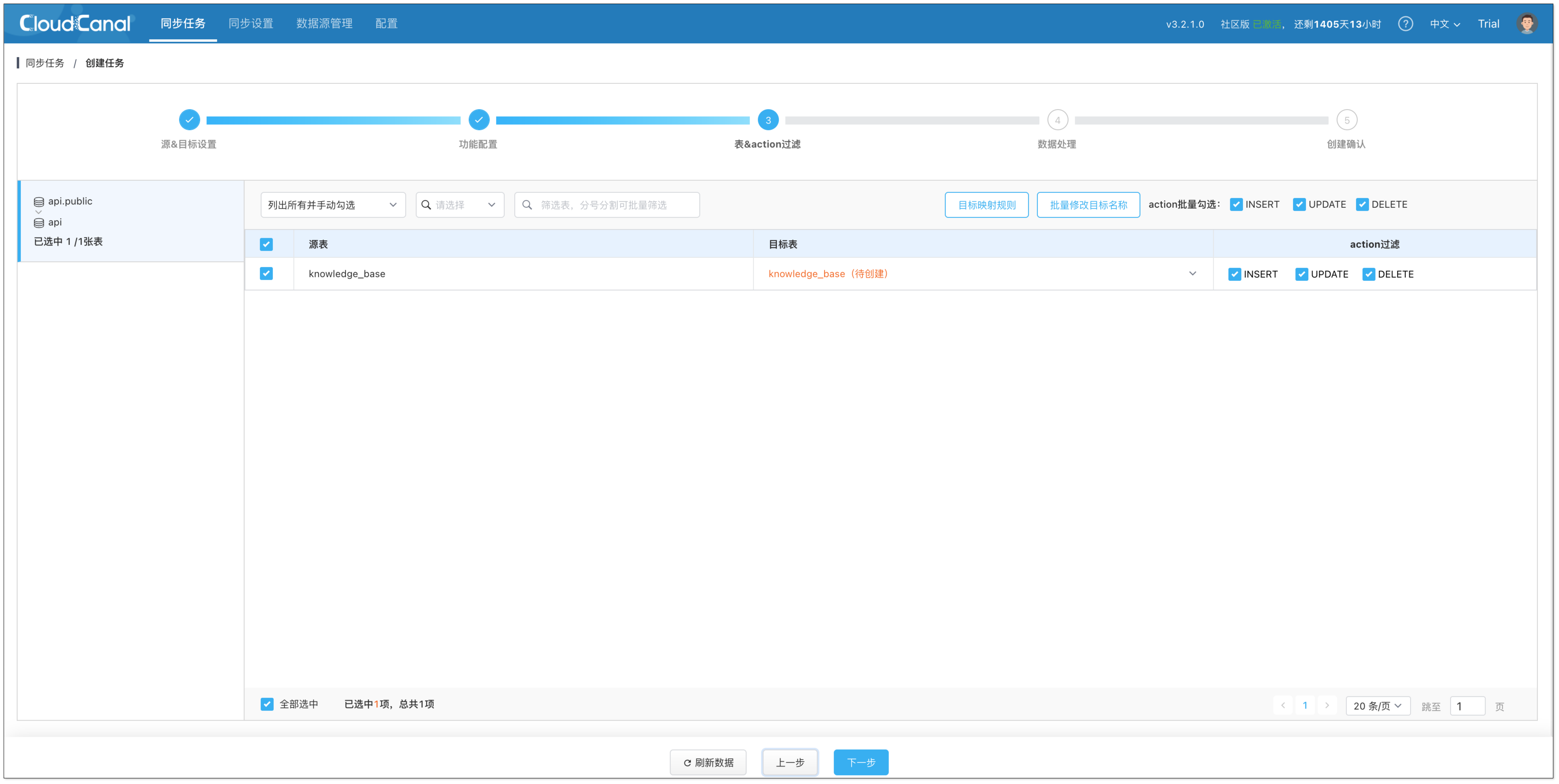
- 在 数据处理 页面,配置大模型:
-
嵌入模型:选择 Ollama。注意:PostgreSQL 中的向量维度需与选定嵌入模型一致。
-
聊天模型:选择 Ollama。
-
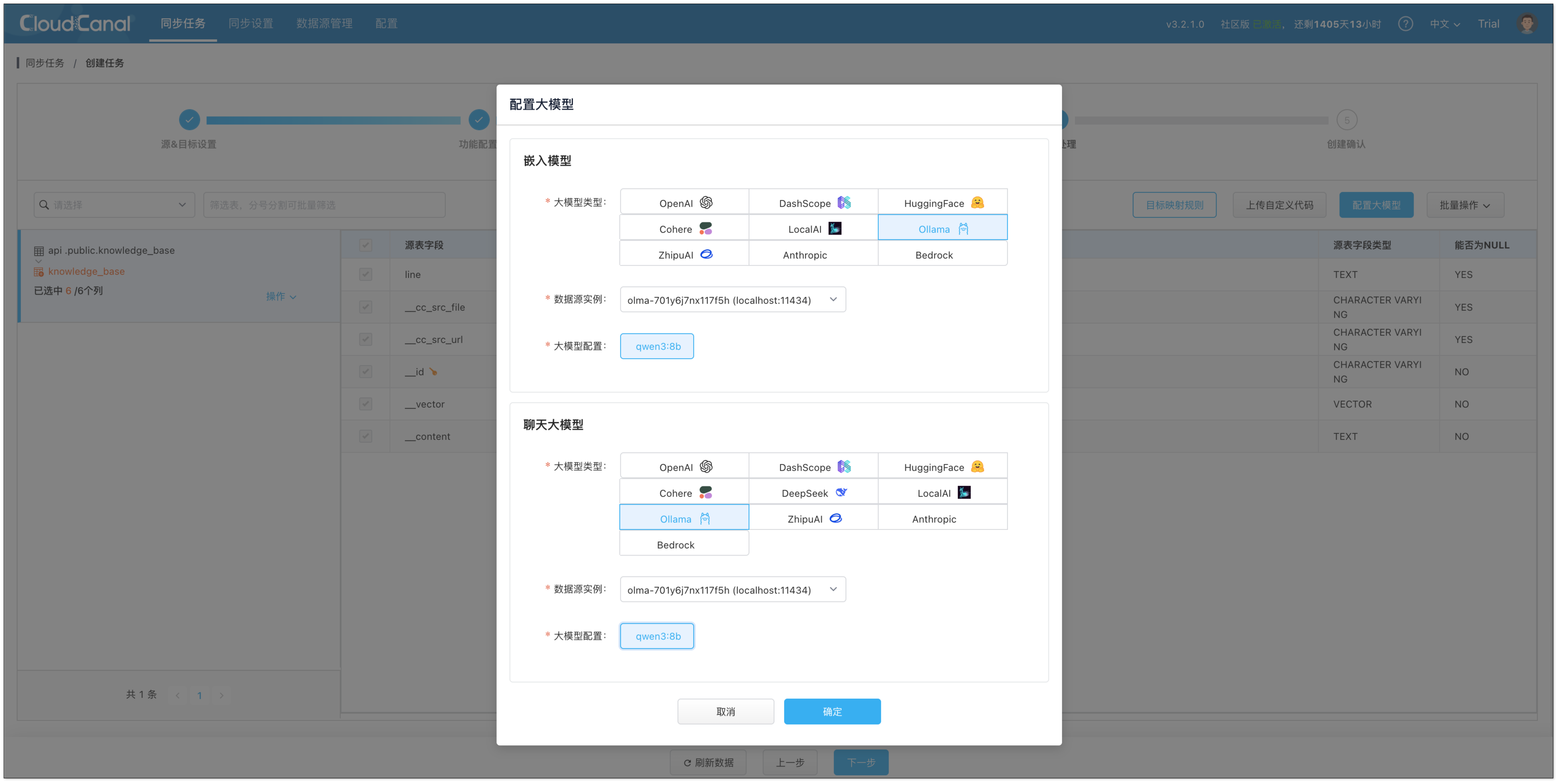
- 在 创建确认 页面,点击 创建任务,系统将自动完成 RagApi 服务构建。
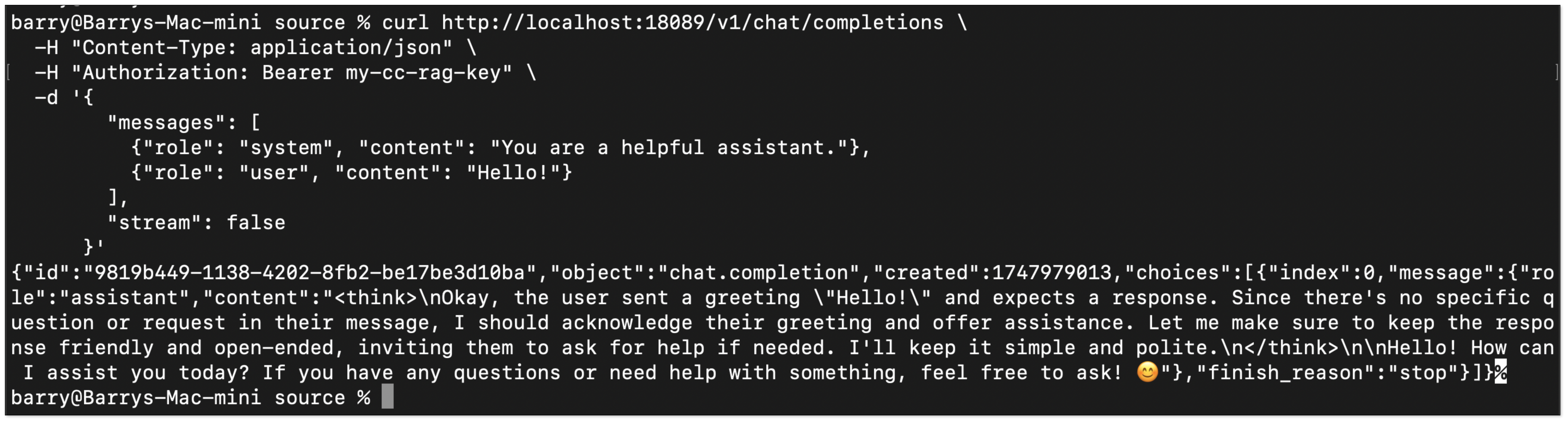
- 构建完成后,可使用以下命令进行简单测试:
curl http://localhost:18089/v1/chat/completions \-H "Content-Type: application/json" \-H "Authorization: Bearer my-cc-rag-key" \-d '{"messages": [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": "Hello!"}],"stream": false}'
效果测试
RagApi 支持通过可视化工具 CherryStudio 进行交互测试。CherryStudio 兼容 OpenAI 接口标准,适合用于接口联调、上下文调试和模型效果验证。
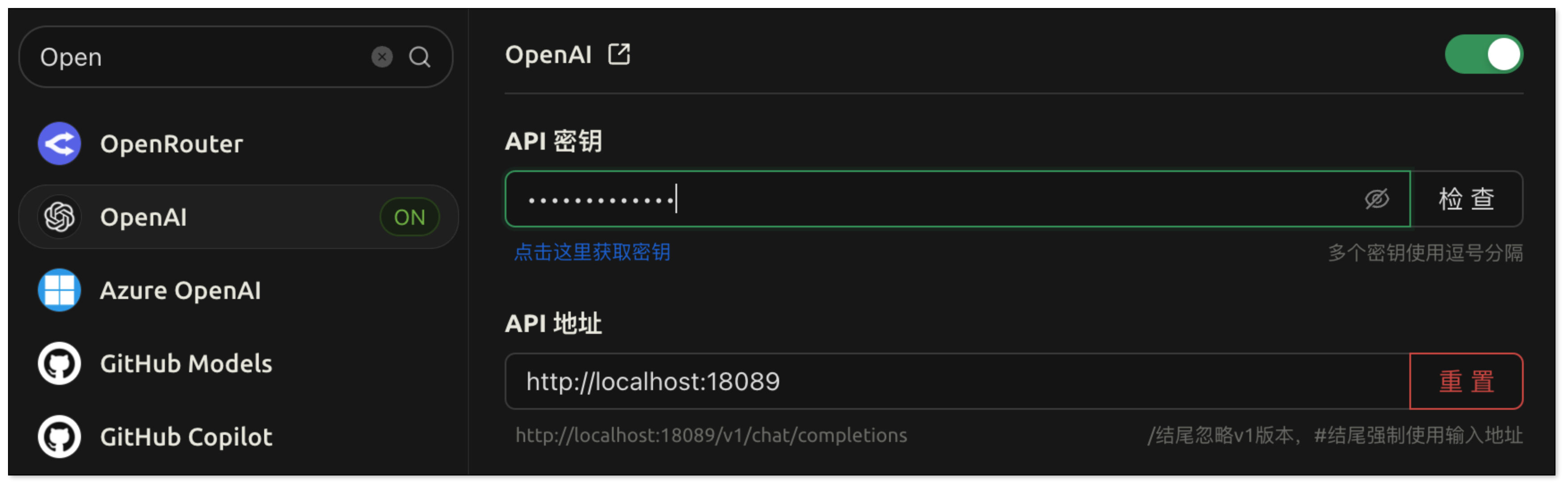
- 打开 CherryStudio,点击左下角 设置图标。
- 在 模型服务 中搜索
OpenAI,并配置如下参数:- API 密钥:填写在 CloudCanal 中 RagApi 设置的密钥:my-cc-rag-key
- API 地址:http://localhost:18089
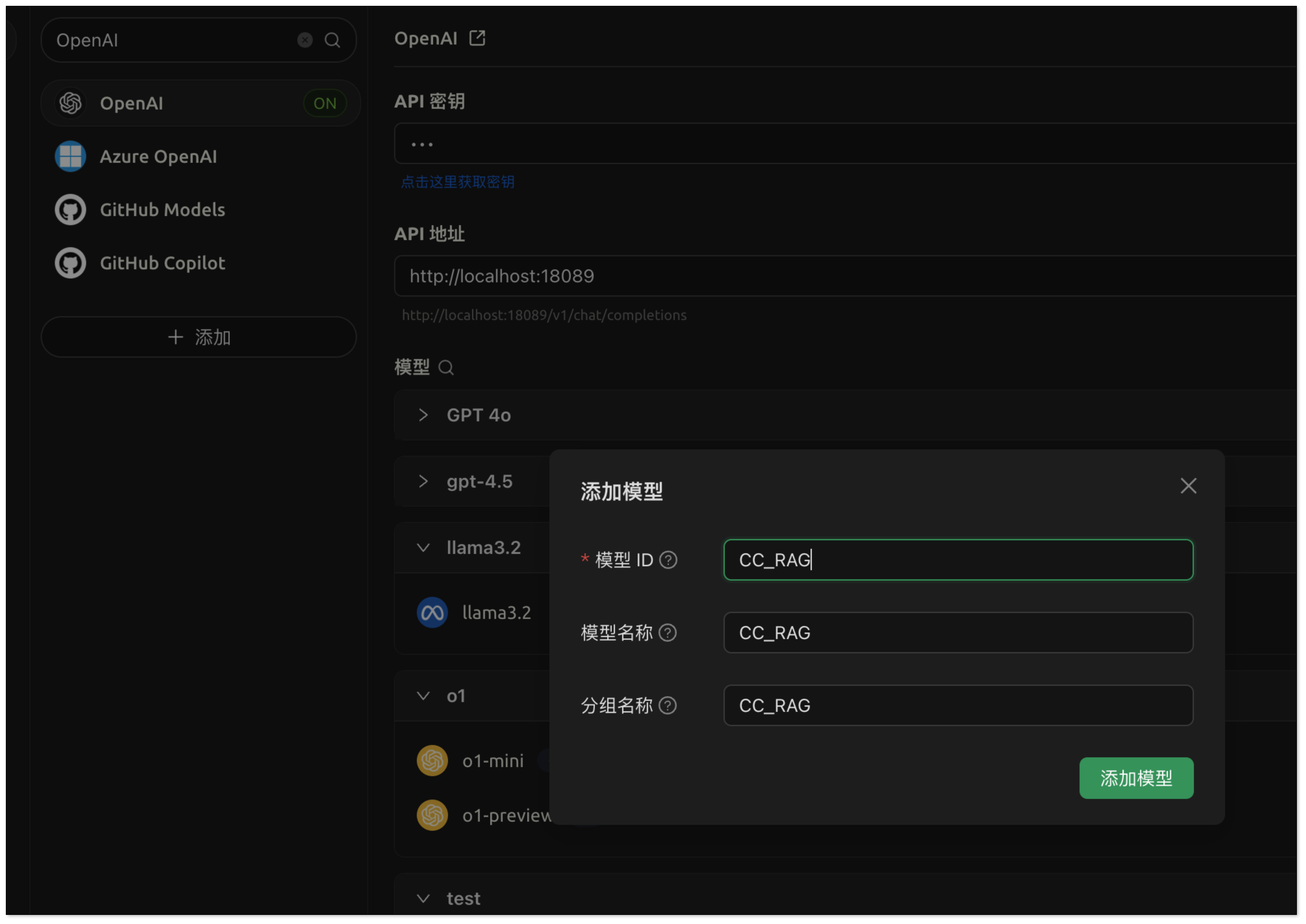
- 模型名称:CC_RAG
- 回到对话页面:
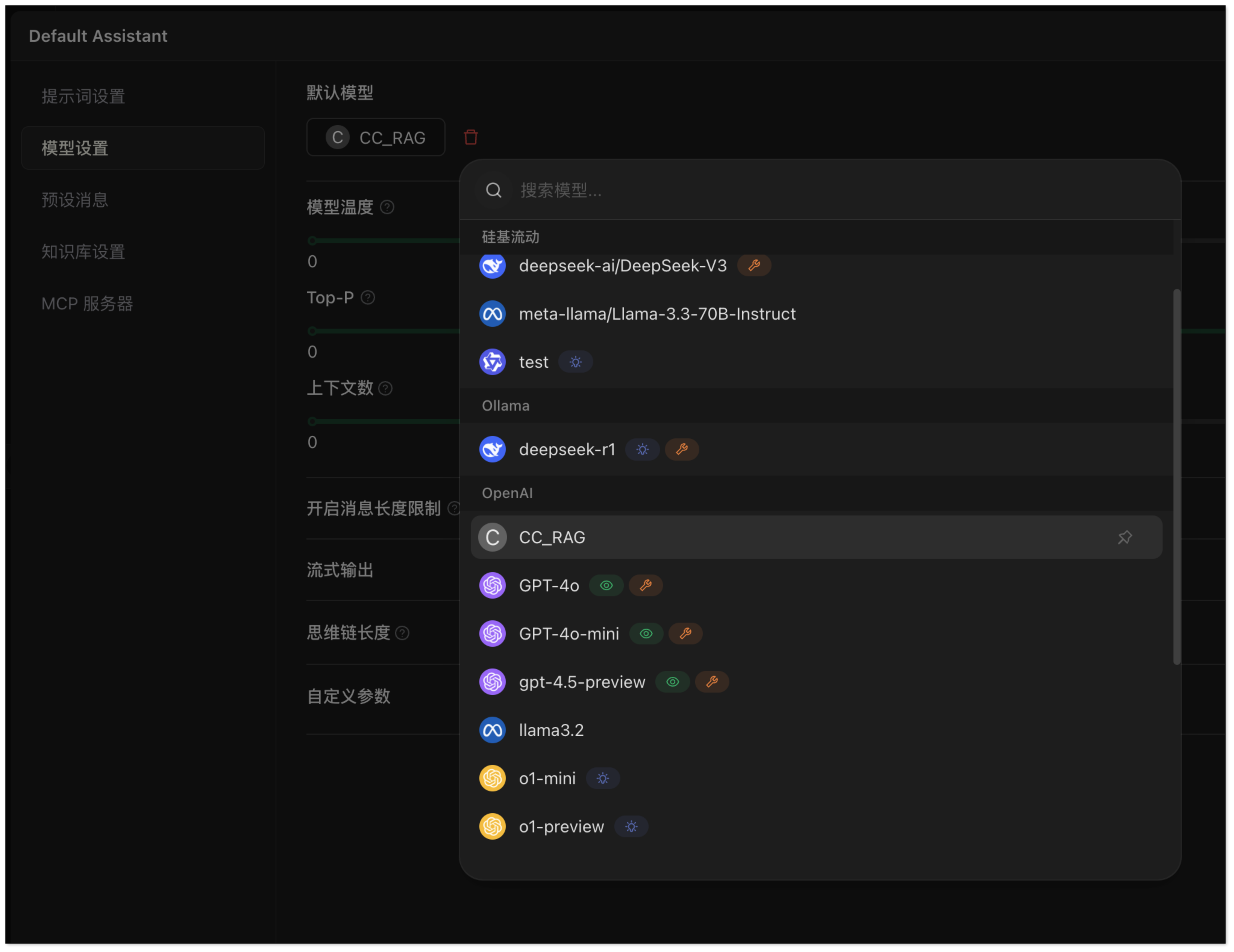
- 点击 添加助手 > Default Assistant。
- 右键点击 Default Assistant > 编辑助手 > 模型设置,绑定上一步添加的模型。
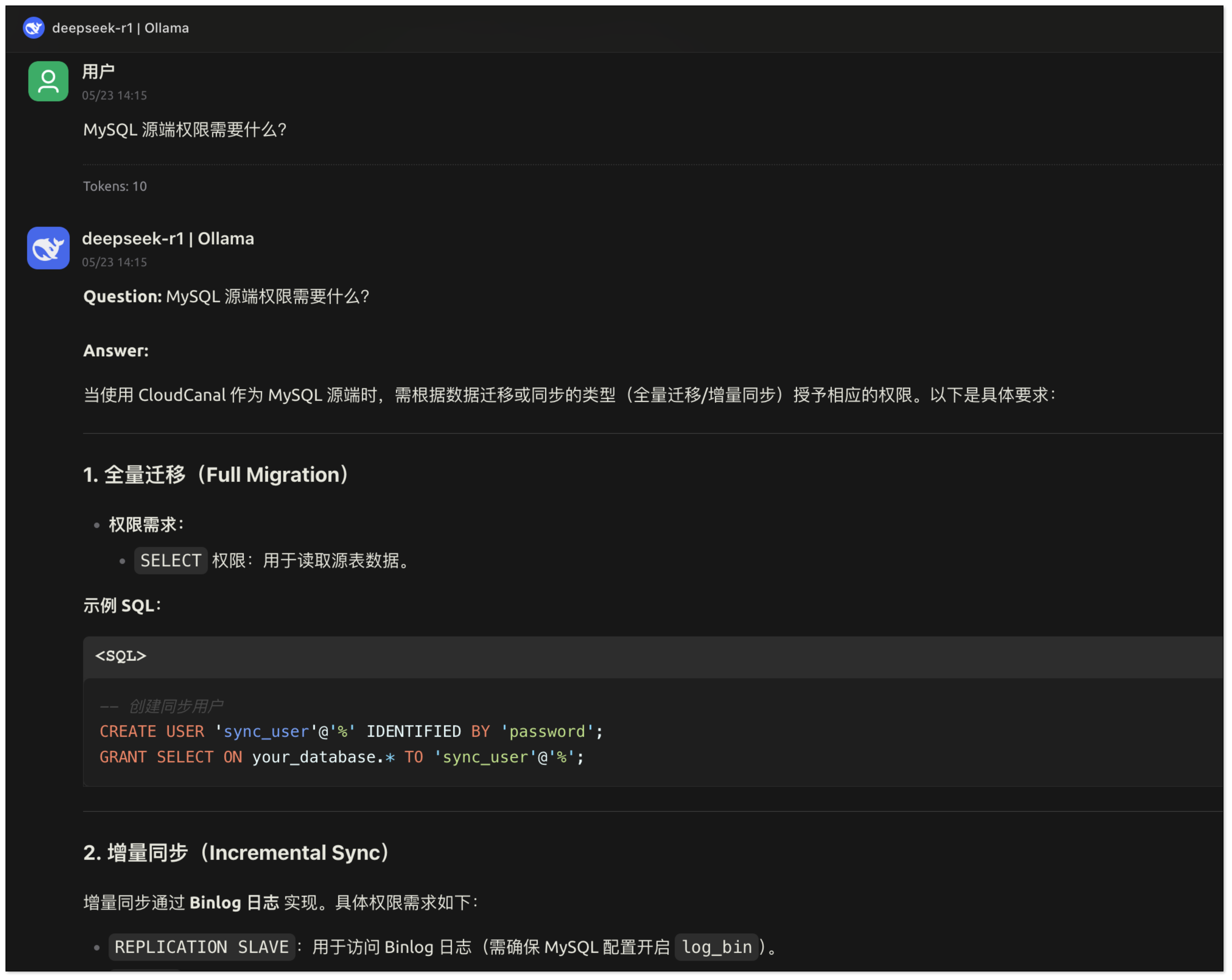
- 在对话框输入:
MySQL 源端权限需要什么?,RagApi 将根据向量数据检索相关内容,并通过对话模型生成响应。
总结
企业级 AI 服务对数据安全有极高的要求。通过 CloudCanal 与 Ollama 的组合,可以轻松实现全私有部署 RAG 服务,打造一个真正不依赖公网、稳定可靠的企业级 RAG 解决方案。